tl;dr
Visual Studio 2019がリリースになった。そこで、3x3フィルタを題材として読みやすいコード、処理時間が短いコード、いろいろ書いて処理時間を計測してみる。今回は、intrinsics(直接的にSIMD命令を記述可能)は使わない。基本的な説明は省略してるので中上級者向けの記事。簡単なフィルタでOpenCVが使えるなら~~素直に用意されたフィルタ関数をコールしたほうが速く、~~そちらを勧める。今回の記事は、よりカスタムなフィルタ処理を実装するときのための備忘録も兼ねているので、自作クラス、関数を多用しているのは了解してほしい。長い記事なので考察+対応コードだけ読めば十分。
本当は、vs2019はclangに対応するとのこでclangでの検討もしたかったのだが、2019/4/29現在、
https://devblogs.microsoft.com/cppblog/clang-llvm-support-in-visual-studio/
によれば、MSBuildでのclangは利用不可だがすぐに実装される予定とのことで、clang版は後日。
基本のコード
コードは、以下のカーネルを使う3x3のガウシアンフィルタを書く場合を例にする。
| 1 | 2 | 1 |
|---|---|---|
| 2 | 4 | 2 |
| 1 | 2 | 1 |
画面端の処理はいろいろ考えられるが入力と出力の画像サイズを変えないために、ボーダーをコピーする処理とする。まずはセットアップのコード。Mtx1bはMtx_のこと。Mtx_の詳細な説明はココとココを参照。まあ、Mat_を拡張したものでMat1bと同じようなものと考えてもらえばよい。Mtx_など、ユーティリティ的なクラスや関数は、cvx.hやstx.hに実装。ファイルの内容はは最後に記載。
# include <iostream>
# include <iomanip>
# include <execution>
# include <algorithm>
# include <amp.h>
# include <amp_graphics.h>
# include "cvx.h"
# include "stx.h"
# include "amp_utils.h"
using namespace cvx;
using namespace stx;
void print_time(const std::string label, double time, const std::string& note = "")
{
using namespace std;
cout << "|" << label << "|" << note << "|" << fixed << setprecision(2) << time << "|" << endl;
}
int main()
{
using namespace std;
auto src = Mtx1b::createWithBorder(1080, 1920, 1);
auto ref = Mtx1b::createWithBorder(src.size(), 1);
Mtx1b dst(src.size());
fill_test_value(src);
int h = src.rows;
int w = src.cols;
int loop_count = 1000;
f0(src, ref, loop_count);
f1(src, ref, loop_count);
f2(src, dst, loop_count);
//以下続く
}
結果
| case | 処理概要 | 種別 | 時間(ms) |
|---|---|---|---|
| 0 | cv::GausianBlur | 1.43 | |
| 1 | 画面外座標値をclamp | 25.35 | |
| 2 | border付き画像の利用 | b | 7.57 |
| 3 | case2+二次元アクセス可能な画素値用ポインタークラスの利用 | b | 3.82 |
| 4 | case3でループを展開 | b | 3.84 |
| 5 | case4でopenmpをさらに利用 | bp | 0.75 |
| 6 | 自作Kernelクラスの利用 | bp | 1.82 |
| 7 | case5をベースにでauto vectrizationしやすいループにする | bp | 0.57 |
| 7.1 | case7をベースに少し読みやすくする | bp | 0.59 |
| 7.2 | case7をベースに自作カーネルクラスの利用をやめる,auto vectrizationしやすいループをやめる | bp | 2.56 |
| 7.3 | case7で自作カーネルクラスの利用をやめる | bp | 0.53 |
| 7.4 | case7.1をベースにループの書き方をかえる | bp | 0.50 |
| 9 | 分離型フィルタ | bp | 3.34 |
| 10 | 分離型フィルタで auto vectorizationしやすいループ | bp | 3.05 |
| 10.1 | 分離型フィルタで auto vectorizationしやすいループ、さらに最適化 | bp | 0.71 |
| 10.2 | 分離型フィルタで auto vectorizationしやすいループ、さらにさらに最適化 | bp | 0.51 |
| 10.3 | case10.2でループの書き方を少し変える(32pix単位) | bp | 0.48 |
| 10.4 | case10.3で64pix単位にする | bp | 0.46 |
| 10.5 | case10.3で16pix単位にする | bp | 0.61 |
| 11 | C++AMP byte | 2.81 | |
| 12 | C++AMP int | 4.96 | |
| 13 | C++AMP texture_view | 5.06 | |
| 13.1 | C++AMP array_view | 6.55 | |
| 13.2 | C++AMP texture_view using sample | 5.14 | |
| 14 | C++AMP texture_view | 3.82 | |
| 14.1 | C++AMP array_view | 4.73 | |
| 14.2 | C++AMP texture_view using sample | 3.84 | |
| 15 | Cベースの記述 | bp | 0.79 |
| 16 | Cベースの記述 | bp | 0.75 |
| 17 | Cベースの記述 (auto vectorizationねらい) | bp | 0.86 |
| 18 | Cベースの記述 (auto vectorizationねらい) | bp | 0.86 |
| b:border付き(画面外参照) | |||
| p:OpenMPによるスレッド並列処理 |
考察
高速化のポイントは
1)実装の工夫(画面外参照の許可,Mtx_の機能,case2の説明を参照)
2)スレッド並列化可能なオリジナルループ関数の利用
3)アルゴリズムの工夫(分離型フィルタ)
4)Auto Vectrization(SIMD化)可能なオリジナルループ関数の利用
今回は、試作目的で、可読性を落とさず、上記が実装できるように、自作のクラスや関数を用意した。やはり1,2は大事で高速化に効く。3は可読性の低下に繋がりやすいが、アルゴリズム開発そのものが目的なら大事可。今回はまったがんばったのは、4で、以下のような関数を用意することで、intrinsics関数を使わなくても、強制的に32や64単位(UNITで指定)でSIMD化を促進できた。使い方はcase7.4や10.4を参照。icc,clang、gccが扱えるOpenMP4.0以降のSIMD化pragmaなどを使えば、より積極的にチューニングできると思う。
template<int UNIT, class T, class TD, class FUNC>
inline void for_s_d(const T* ps, TD* pd, int n, FUNC func)
{
const int nUNIT = n / UNIT * UNIT;
const int n8 = n / 8 * 8;
int i = 0;
const T* pst = ps;
TD* pdt = pd;
for(; i < nUNIT; i += UNIT) {
for(int j = 0; j < UNIT; j++) {
func(pst[j], pdt[j]);
}
pst += UNIT;
pdt += UNIT;
}
if constexpr(UNIT > 8) {
for(; i < n8; i += 8) {
for(int j = 0; j < 8; j++) {
func(pst[j], pdt[j]);
}
pst += 8;
pdt += 8;
}
}
int j = 0;
for(; i < n; i++) {
func(pst[j], pdt[j]);
j++;
}
}
具体的な事例では、case5がそこそこ速くて読みやすい。case7.4が比較的速いが多少可読性が犠牲になっている。最速はcase10.4だが、分離型フィルタを使うためさらに可読性が低い。C++AMPの場合VRAMの転送のオーバヘッドのために処理時間がかかるが、3x3より大ききなフィルタの場合には、使用検討の余地がありそう。ちなみに、どんどんループのための関数を作ってしまったが、適切な名前をつけて整理したい。使用頻度の高いものを作っておけば、再利用が楽なので。
case0: cv::GaussianFilter
これが基準。当初測定ミスをしていた。すごく速いわけではなかった。
void f0(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
StopWatch sw;
std::string label = "0|cv::GausianBlur ";
for(int z = 0; z < loop_count; z++) {
GaussianBlur(src, dst, cv::Size(3, 3), 0);
}
print_time(label, sw.lap() / loop_count);
}
case1:画面外座標値をclamp
(x,y)でしているので都度アドレスを計算することになる。座標値をclampすることで、ボーダーをコピーする処理を再現。clampはstd::clampのこと。ちなみに、OpenCVのコードの結果と一致するようには書いていない。
void f1(Mtx1b& src, Mtx1b& ref, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
std::string label = "1|画面外座標値をclamp";
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
for(int y = 0; y < h; y++) {
for(int x = 0; x < w; x++) {
int v = (4 * src(clamp(y, 0, h - 1), clamp(x, 0, w - 1)) +
2 *
(src(clamp(y, 0, h - 1), clamp(x - 1, 0, w - 1)) +
src(clamp(y - 1, 0, h - 1), clamp(x, 0, w - 1)) +
src(clamp(y, 0, h - 1), clamp(x + 1, 0, w - 1)) +
src(clamp(y + 1, 0, h - 1), clamp(x, 0, w - 1))) +
(src(clamp(y - 1, 0, h - 1), clamp(x - 1, 0, w - 1)) +
src(clamp(y - 1, 0, h - 1), clamp(x + 1, 0, w - 1)) +
src(clamp(y + 1, 0, h - 1), clamp(x - 1, 0, w - 1)) +
src(clamp(y + 1, 0, h - 1), clamp(x + 1, 0, w - 1)))) /
16;
ref(y, x) = v;
}
}
}
print_time(label, sw.lap() / loop_count);
}
case2:border付き画像の利用
clampを外してみる。cv::Mat_では不可能だが、Mtx_には画面外参照機能があるのでOK。詳細な解説はココを参照。
void f2(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
std::string label = "2|border付き画像の利用";
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
for(int y = 0; y < h; y++) {
for(int x = 0; x < w; x++) {
dst(y, x) =
(4 * src(y, x) + 2 * (src(y, x - 1) + src(y - 1, x) + src(y, x + 1) + src(y + 1, x)) +
(src(y - 1, x - 1) + src(y - 1, x + 1) + src(y + 1, x + 1) + src(y + 1, x - 1))) /
16;
}
}
}
print_time(label, sw.lap() / loop_count);
}
case3:case2+二次元アクセス可能な画素値用ポインタークラス
二次元アクセス可能な画素値用ポインタークラスPixPtrを使ってみる。詳細な説明はココを参照。インライン展開されると変数の乗算がないことになるので速い。コードが比較的すっきりした。
void f3(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
std::string label = "3|case2+二次元アクセス可能な画素値用ポインタークラスの利用 ";
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
for(int y = 0; y < h; y++) {
auto pp = src.createPixPtr(y, 0);
for(int x = 0; x < w; x++) {
dst(y, x) = (4 * pp(0, 0) + 2 * (pp(0, -1) + pp(-1, 0) + pp(0, 1) + pp(1, 0)) +
(pp(-1, -1) + pp(-1, 1) + pp(1, 1) + pp(1, -1))) /
16;
pp++;
}
}
}
print_time(label, sw.lap() / loop_count, "b");
}
case4:case3でループを展開
参照順をできるだけシーケンシャルになるよう変えてみる。速度はあまり変わらないかぁ。
void f4(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
std::string label = "4|case3でループを展開";
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
for(int y = 0; y < h; y++) {
auto pp = src.createPixPtr(y, 0);
for(int x = 0; x < w; x++) {
dst(y, x) = (pp(-1, -1) + 2 * pp(-1, 0) + pp(-1, 1) + 2 * pp(0, -1) + 4 * pp(0, 0) +
2 * pp(0, 1) + pp(1, -1) + 2 * pp(1, 0) + pp(1, 1)) /
16;
pp++;
}
}
}
print_time(label, sw.lap() / loop_count, "b");
}
case5:case4でopenmpをさらに利用
OpenMPを使う。ただ、OpenMPプラグマを隠蔽した自作のparal_for_pp_rにラムダ式を渡す形で書いてみる。cv::parallel_for_に似ているが自作することでほしい引数うけとれるので、可読性が向上。詳細な説明はココを参照。流石に一気に速くなる。
void f5(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
std::string label = "5|case4でopenmpをさらに利用";
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
paral_for_pp_r(src, dst, [](const auto& pp) { //OpenMP利用
return (pp(-1, -1) + 2 * pp(-1, 0) + pp(-1, 1) + 2 * pp(0, -1) + 4 * pp(0, 0) + 2 * pp(0, 1) +
pp(1, -1) + 2 * pp(1, 0) + pp(1, 1)) /
16;
});
}
print_time(label, sw.lap() / loop_count, "bp");
}
case6:自作Kernelクラスの利用
読みやすくするためにKernelクラスを定義して使ってみた。畳み込み積分の部分が読みやすいが少し遅い。
void f6(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
Kernel<int, 1> ker(1, 2, 1, 2, 4, 2, 1, 2, 1);
std::string label = "6|自作Kernelクラスの利用";
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
paral_for_pp_r(src, dst, [&](const auto& pp) {
# if 1
int sum = 0;
for_dy_dx(ker.radius, ker.radius, [&](int dy, int dx) { sum += pp(dy, dx) * ker(dy, dx); });
return sum / 16;
# else
return ker.convolute(pp) / 16;
# endif
});
}
print_time(label, sw.lap() / loop_count, "bp");
}
case7
auto vectorizationさせるために、for文の回し方をいろいろ工夫してみる。casef7.4について説明するとfor_s_dでUNIT=64とすることで64画素単位のループを作っている。(実際には、32単位や16単位のSIMD命令が生成される。)
void f7(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
Kernel<int, 1> ker(1, 2, 1, 2, 4, 2, 1, 2, 1);
std::string label = "7|case5をベースにでauto vectrizationしやすいループにする";
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
# pragma omp parallel for
for(int y = 0; y < h; y++) {
auto pd = dst[y];
int sum[4096] = {};
//for(int i=0;i<sum.size();i++) sum[i] = 0;
for_dy_dx(ker.radius, ker.radius, [&](int dy, int dx) {
int k = ker(dy, dx);
auto ps = src[0] + src.stepT() * (dy + y) + dx;
for_ps_pd_idx_old<32>(ps, sum, w,
[&](auto& ps, auto& psum, int d) { psum[d] += k * ps[d]; });
});
for_ps_pd_idx_old<32>(sum, pd, w, [&](auto& psum, auto& pd, int d) { pd[d] = psum[d] / 16; });
}
}
print_time(label, sw.lap() / loop_count, "bp");
}
void f7_1(Mtx1b& src, Mtx1b& dst, int loop_count)
{
std::string label = "7.1|case7をベースに少し読みやすくする";
using namespace std;
int h = src.rows;
int w = src.cols;
const Kernel<int, 1> ker(1, 2, 1, 2, 4, 2, 1, 2, 1);
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
# pragma omp parallel for
for(int y = 0; y < h; y++) {
auto pd = dst[y];
auto pp = src.createPixPtr(y, 0);
int sum[4096] = {};
for_dy_dx(ker.radius, ker.radius, [&](int dy, int dx) {
int k = ker(dy, dx);
auto ps = pp.ptr(dy, dx);
for_ps_pd_idx_old<32>(ps, sum, w,
[&](auto& ps, auto& psum, int d) { psum[d] += k * ps[d]; });
});
for_ps_pd_idx_old<32>(sum, pd, w, [&](auto& psum, auto& pd, int d) { pd[d] = psum[d] / 16; });
}
}
print_time(label, sw.lap() / loop_count, "bp");
}
void f7_2(Mtx1b& src, Mtx1b& dst, int loop_count)
{
std::string label =
"7.2|case7をベースに自作カーネルクラスの利用をやめる,auto vectrizationしやすいループをやめる";
using namespace std;
int h = src.rows;
int w = src.cols;
// const Kernel<int, 1> ker(1, 2, 1, 2, 4, 2, 1, 2, 1);
static const int ker[] = {1, 2, 1, 2, 4, 2, 1, 2, 1};
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
# pragma omp parallel for
for(int y = 0; y < h; y++) {
auto pd = dst[y];
auto pp = src.createPixPtr(y, 0);
int sum[4096] = {};
int j = 0;
for_dy_dx(1, 1, [&](int dy, int dx) {
//int k = ker(dy, dx);
int k = ker[j];
auto ps = pp.ptr(dy, dx);
for(int x = 0; x < w; x++) {
sum[x] += k * ps[x];
}
j++;
});
for(int x = 0; x < w; x++) {
pd[x] = sum[x] / 16;
}
}
}
print_time(label, sw.lap() / loop_count, "bp");
// print(dst);
}
void f7_3(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
static const int ker[9] = {1, 2, 1, 2, 4, 2, 1, 2, 1};
std::string label = "7.3|case7で自作カーネルクラスの利用をやめる";
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
# pragma omp parallel for
for(int y = 0; y < h; y++) {
auto pd = dst[y];
int sum[4096] = {};
int j = 0;
for_dy_dx(1, 1, [&](int dy, int dx) {
int k = ker[j];
auto ps = src[0] + src.stepT() * (dy + y) + dx;
for_ps_pd_idx_old<32>(ps, sum, w,
[&](auto& ps, auto& psum, int d) { psum[d] += k * ps[d]; });
j++;
});
for_ps_pd_idx_old<32>(sum, pd, w, [&](auto& psum, auto& pd, int d) { pd[d] = psum[d] / 16; });
}
}
print_time(label, sw.lap() / loop_count, "bp");
}
void f7_4(Mtx1b& src, Mtx1b& dst, int loop_count)
{
std::string label =
"7.4|case7.1をベースにループをかけかたをかえる";
using namespace std;
int h = src.rows;
int w = src.cols;
static constexpr int UNIT = 64;
const Kernel<int, 1> ker(1, 2, 1, 2, 4, 2, 1, 2, 1);
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
# pragma omp parallel for
for(int y = 0; y < h; y++) {
auto pd = dst[y];
auto pp = src.createPixPtr(y, 0);
alignas(32) int sum[4096] = {};
for_dy_dx(1, 1, [&](int dy, int dx) {
const int k = ker(dy, dx);
const auto ps = pp.ptr(dy, dx);
//kは参照キャプチャでないと遅い
for_s_d<UNIT>(ps, sum, w, [&k](const auto& s, auto& d) { d += k * s; });
});
for_s_d<UNIT>(sum, pd, w, [](const auto& s, auto& d) { d = s / 16; });
}
}
print_time(label, sw.lap() / loop_count, "bp");
}
case9:分離型フィルタ
実装が悪いのかあまり速くない。
void f9(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
SepKernel<int, 1> sker(2, 1);
StopWatch sw;
std::string label = "9|分離型フィルタ";
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
auto tmp = Mtx1i::createWithBorder(src.size(), sker.radius);
paral_for_pp_r(src, tmp, [&](const auto& pp) { return sker.convolute(pp, false); });
tmp.extrapolate();
paral_for_pp_r(tmp, dst, [&](const auto& pp) { return sker.convolute(pp, true) / 16; });
}
print_time(label, sw.lap() / loop_count, "bp");
}
case10:分離型フィルタでSIMD化しやすいループ
10はループを二回まわることになるのでキャッシュ効率が遅い。そこで、ラインバッファを利用する10.1を作った。最終的に10.4が最速を記録。casef7.4でも説明したが、for_s_dでUNIT=64とすることで64画素単位のループを作っている。(実際には、32単位や16単位のSIMD命令が生成される。)
void f10(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
SepKernel<int, 1> sker(2, 1);
std::string label = "10|分離型フィルタで auto vectorizationしやすいループ ";
StopWatch sw;
//SepKernel<int, 1> sker(2, 1);
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
auto tmp = Mtx1i::createWithBorder(src.size(), sker.radius);
# pragma omp parallel for
for(int y = 0; y < h; y++) {
auto ptl = tmp[y];
for_p_idx<32>(w, ptl, [&](auto& pt, int d) { pt[d] = 0; });
for(int dy = -sker.radius; dy <= sker.radius; dy++) {
auto k = sker(dy);
auto psl = src[0] + src.stepT() * (dy + y);
for_ps_pd_idx_old<32>(psl, ptl, w, [&](auto& ps, auto& pt, int d) { pt[d] += k * ps[d]; });
}
}
tmp.extrapolate();
# pragma omp parallel for
for(int y = 0; y < h; y++) {
int sum[4096] = {0};
for(int dx = -sker.radius; dx <= sker.radius; dx++) {
auto k = sker(dx);
auto ptl = tmp[y] + dx;
for_ps_pd_idx_old<32>(ptl, sum, w, [&](auto& pt, auto& pd, int d) { pd[d] += k * pt[d]; });
}
for_ps_pd_idx_old<32>(sum, dst[y], w, [&](auto& pt, auto& pd, int d) { pd[d] = pt[d] / 16; });
}
}
print_time(label, sw.lap() / loop_count, "bp");
}
void f10_1(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
SepKernel<int, 1> sker(2, 1);
std::string label = "10.1|分離型フィルタで auto vectorizationしやすいループ、さらに最適化";
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
# pragma omp parallel for
for(int y = 0; y < h; y++) {
auto pps = src.createPixPtr(y, 0);
alignas(32) int vbuf_entity[4096] = {}; //cv::AutoBufferにすべきか?
int* vbuf = vbuf_entity + 32;
//for_p_idx<32>(w, ptl, [&](auto& pt, int d) { pt[d] = 0; });
for(int dy = -sker.radius; dy <= sker.radius; dy++) {
const auto k = sker(dy);
const auto psl = pps.ptr(dy, 0);
for_ps_pd_idx_old<32>(psl, vbuf, w,
[k](const auto& ps, const auto& pt, int d) { pt[d] += k * ps[d]; });
}
vbuf[-1] = vbuf[0];
vbuf[w] = vbuf[w - 1];
alignas(32) int bufh[4096] = {}; //cv::AutoBufferにすべきか?
for(int dx = -sker.radius; dx <= sker.radius; dx++) {
const auto k = sker(dx);
const auto ptl = vbuf + dx;
for_ps_pd_idx_old<32>(ptl, bufh, w,
[&](const auto& pt, auto& pd, int d) { pd[d] += k * pt[d]; });
}
for_ps_pd_idx_old<32>(bufh, dst[y], w,
[](const auto& pt, auto& pd, int d) { pd[d] = pt[d] / 16; });
}
}
print_time(label, sw.lap() / loop_count, "bp");
}
void f10_2(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
constexpr int UNIT = 64;
SepKernel<int, 1> sker(2, 1);
std::string label = "10.2|分離型フィルタで auto vectorizationしやすいループ、さらにさらに最適化";
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
//auto tmp = Mtx1i::createWithBorder(src.size(), sker.radius);
# pragma omp parallel for
for(int y = 0; y < h; y++) {
auto pps = src.createPixPtr(y, 0);
alignas(32) int vbuf_entity[4096] = {}; //cv::AutoBufferにすべきか?
int* vbuf = vbuf_entity + 32;
for(int dy = -sker.radius; dy <= sker.radius; dy++) {
const auto k = sker(dy);
const auto psl = pps.ptr(dy, 0);
//参照キャプチャ[&k]でなく、コピーキャプチャ[k]にすると遅い、SIMD化されな?
for_ps_pd_idx<UNIT>(psl, vbuf, w,
[&k](const auto& ps, auto& pt, int d) { pt[d] += k * ps[d]; });
}
vbuf[-1] = vbuf[0];
vbuf[w] = vbuf[w - 1];
alignas(32) int bufh[4096] = {}; //cv::AutoBufferにすべきか?
for(int dx = -sker.radius; dx <= sker.radius; dx++) {
const auto k = sker(dx);
const auto ptl = vbuf + dx;
for_ps_pd_idx<UNIT>(ptl, bufh, w,
[&k](const auto& pt, auto& pd, int d) { pd[d] += k * pt[d]; });
}
for_ps_pd_idx<UNIT>(bufh, dst[y], w,
[](const auto& pt, auto& pd, int d) { pd[d] = pt[d] / 16; });
}
}
print_time(label, sw.lap() / loop_count, "bp");
}
void f10_3(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
constexpr int UNIT = 32;
SepKernel<int, 1> sker(2, 1);
std::string label = "10.3|case10.2でループの書き方を少し変える(32pix単位)";
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
//auto tmp = Mtx1i::createWithBorder(src.size(), sker.radius);
# pragma omp parallel for
for(int y = 0; y < h; y++) {
auto pps = src.createPixPtr(y, 0);
alignas(32) int vbuf_entity[4096] = {}; //cv::AutoBufferにすべきか?
int* vbuf = vbuf_entity + 32;
for(int dy = -sker.radius; dy <= sker.radius; dy++) {
const auto k = sker(dy);
const auto psl = pps.ptr(dy, 0);
for_s_d<UNIT>(psl, vbuf, w, [&k](const auto& s, auto& d) { d += k * s; });
}
vbuf[-1] = vbuf[0];
vbuf[w] = vbuf[w - 1];
alignas(32) int bufh[4096] = {}; //cv::AutoBufferにすべきか?
for(int dx = -sker.radius; dx <= sker.radius; dx++) {
const auto k = sker(dx);
const auto ptl = vbuf + dx;
for_s_d<UNIT>(ptl, bufh, w, [&k](const auto& s, auto& d) { d += k * s; });
}
for_s_d<UNIT>(bufh, dst[y], w, [&](const auto& s, auto& d) { d = s / 16; });
}
}
print_time(label, sw.lap() / loop_count, "bp");
}
void f10_4(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
constexpr int UNIT = 64;
SepKernel<int, 1> sker(2, 1);
std::string label = "10.4|case10.3で64pix単位にする";
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
//auto tmp = Mtx1i::createWithBorder(src.size(), sker.radius);
# pragma omp parallel for
for(int y = 0; y < h; y++) {
auto pps = src.createPixPtr(y, 0);
alignas(32) int vbuf_entity[4096] = {}; //cv::AutoBufferにすべきか?
int* vbuf = vbuf_entity + 32;
for(int dy = -sker.radius; dy <= sker.radius; dy++) {
const auto k = sker(dy);
const auto psl = pps.ptr(dy, 0);
for_s_d<UNIT>(psl, vbuf, w, [&k](const auto& s, auto& d) { d += k * s; });
}
vbuf[-1] = vbuf[0];
vbuf[w] = vbuf[w - 1];
alignas(32) int bufh[4096] = {}; //cv::AutoBufferにすべきか?
for(int dx = -sker.radius; dx <= sker.radius; dx++) {
const auto k = sker(dx);
const auto ptl = vbuf + dx;
for_s_d<UNIT>(ptl, bufh, w, [&k](const auto& s, auto& d) { d += k * s; });
}
for_s_d<UNIT>(bufh, dst[y], w, [&](const auto& s, auto& d) { d = s / 16; });
}
}
print_time(label, sw.lap() / loop_count, "bp");
}
void f10_5(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
constexpr int UNIT = 16;
SepKernel<int, 1> sker(2, 1);
std::string label = "10.5|case10.3で16pix単位にする";
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
# pragma omp parallel for
for(int y = 0; y < h; y++) {
auto pps = src.createPixPtr(y, 0);
alignas(32) int vbuf_entity[4096] = {}; //cv::AutoBufferにすべきか?
int* vbuf = vbuf_entity + 32;
for(int dy = -sker.radius; dy <= sker.radius; dy++) {
const auto k = sker(dy);
const auto psl = pps.ptr(dy, 0);
for_s_d<UNIT>(psl, vbuf, w, [&k](const auto& s, auto& d) { d += k * s; });
}
vbuf[-1] = vbuf[0];
vbuf[w] = vbuf[w - 1];
alignas(32) int bufh[4096] = {}; //cv::AutoBufferにすべきか?
for(int dx = -sker.radius; dx <= sker.radius; dx++) {
const auto k = sker(dx);
const auto ptl = vbuf + dx;
for_s_d<UNIT>(ptl, bufh, w, [&k](const auto& s, auto& d) { d += k * s; });
}
for_s_d<UNIT>(bufh, dst[y], w, [&](const auto& s, auto& d) { d = s / 16; });
}
}
print_time(label, sw.lap() / loop_count, "bp");
}
case11:C++AMP byte
textureにbyteデータをバインド。遅い!!
void f11(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
using namespace Concurrency;
using namespace Concurrency::graphics;
namespace cc = Concurrency;
namespace cg = Concurrency::graphics;
int h = src.rows;
int w = src.cols;
std::string label = "11|C++AMP byte ";
//わかりやすさのためにborder抜きの画像を作る、時間計測からは除外
Mtx1b tmp(h, w);
paral_for_pp(src, tmp, [&](const auto& pp) { return pp(0, 0); });
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
cc::extent<2> ext(h, w);
texture<uint, 2> stex(ext, tmp[0], h * w, 8U);
texture_view<const uint, 2> sview(stex);
texture<uint, 2> dtex(ext, 8U);
parallel_for_each(ext, [&, sview, h, w](cc::index<2> idx) restrict(amp) {
int sum = 0;
int j = 0;
int karr[] = {1, 2, 1, 2, 4, 2, 1, 2, 1};
for(int dy = -1; dy <= 1; dy++) {
for(int dx = -1; dx <= 1; dx++) {
cc::index<2> idx1;
idx1[0] = cc::clamp(idx[0] + dy, 0, h - 1);
idx1[1] = cc::clamp(idx[1] + dx, 0, w - 1);
sum += karr[j] * sview[idx1];
j++;
}
}
dtex.set(idx, sum / 16);
});
cg::copy(dtex, dst[0], h * w);
}
print_time(label, sw.lap() / loop_count);
}
case12:C++AMP int
一度intデータにしてから、texureにintデータをバインド。速くなった。
void f12(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
int h = src.rows;
int w = src.cols;
std::string label = "12|C++AMP int";
using namespace Concurrency;
using namespace Concurrency::graphics;
namespace cc = Concurrency;
namespace cg = Concurrency::graphics;
Mtx1i tmp(h, w);
Mtx1i tmp2(h, w);
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
paral_for_pp(src, tmp, [&](const auto& pp) { return pp(0, 0); });
cc::extent<2> ext(h, w);
texture<uint, 2> stex(ext, tmp[0], h * w * 4, 32);
texture_view<const uint, 2> sview(stex);
texture<uint, 2> dtex(ext, 32);
parallel_for_each(ext, [&, sview, h, w](cc::index<2> idx) restrict(amp) {
int sum = 0;
int j = 0;
int karr[] = {1, 2, 1, 2, 4, 2, 1, 2, 1};
for(int dy = -1; dy <= 1; dy++) {
for(int dx = -1; dx <= 1; dx++) {
cc::index<2> idx1;
idx1[0] = cc::clamp(idx[0] + dy, 0, h - 1);
idx1[1] = cc::clamp(idx[1] + dx, 0, w - 1);
sum += karr[j] * sview[idx1];
j++;
}
}
dtex.set(idx, sum / 16);
});
cg::copy(dtex, tmp2[0], h * w * 4);
paral_for_pp(tmp2, dst, [&](const auto& pp) { return pp(0, 0); });
}
print_time(label, sw.lap() / loop_count);
}
case13:C++AMP float
floatデータに変換して、texuterにfloatデータをバインド。intよりも速い。
texture.sampleを使ってもそれほど速くないがarray_viewよりは速い?
void f13(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
using namespace Concurrency;
using namespace Concurrency::graphics;
namespace cc = Concurrency;
namespace cg = Concurrency::graphics;
int h = src.rows;
int w = src.cols;
std::string label = "13|C++AMP texture_view<const float, 2>";
StopWatch sw;
Mtx1f tmp(h, w);
Mtx1f tmp2(h, w);
for(int z = 0; z < loop_count; z++) {
paral_for_pp(src, tmp, [&](const auto& pp) { return pp(0, 0); });
cc::extent<2> ext(h, w);
texture<float, 2> stex(ext, tmp[0], h * w * 4, 32);
texture_view<const float, 2> sview(stex);
texture<float, 2> dtex(ext, 32);
parallel_for_each(ext, [&, sview, h, w](cc::index<2> idx) restrict(amp) {
float sum = 0;
int j = 0;
const int karr[] = {1, 2, 1, 2, 4, 2, 1, 2, 1};
for(int dy = -1; dy <= 1; dy++) {
for(int dx = -1; dx <= 1; dx++) {
cc::index<2> idx1;
idx1[0] = cc::clamp(idx[0] + dy, 0, h - 1);
idx1[1] = cc::clamp(idx[1] + dx, 0, w - 1);
sum += karr[j] * sview[idx1];
j++;
}
}
dtex.set(idx, sum / 16);
});
cg::copy(dtex, tmp2[0], h * w * 4);
paral_for_pp(tmp2, dst, [&](const auto& pp) { return pp(0, 0); });
}
print_time(label, sw.lap() / loop_count);
}
void f13_1(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
using namespace Concurrency;
using namespace Concurrency::graphics;
namespace cc = Concurrency;
namespace cg = Concurrency::graphics;
int h = src.rows;
int w = src.cols;
std::string label = "13.1|C++AMP array_view<float,2>";
StopWatch sw;
Mtx1f tmp(h, w);
Mtx1f tmp2(h, w);
for(int z = 0; z < loop_count; z++) {
paral_for_pp(src, tmp, [&](const auto& pp) { return pp(0, 0); });
cc::extent<2> ext(h, w);
array_view<float, 2> sview(ext, tmp[0]);
array_view<float, 2> dview(ext, tmp2[0]);
parallel_for_each(ext, [&, sview, dview, h, w](cc::index<2> idx) restrict(amp) {
float sum = 0;
int j = 0;
const int karr[] = {1, 2, 1, 2, 4, 2, 1, 2, 1};
for(int dy = -1; dy <= 1; dy++) {
for(int dx = -1; dx <= 1; dx++) {
cc::index<2> idx1;
idx1[0] = cc::clamp(idx[0] + dy, 0, h - 1);
idx1[1] = cc::clamp(idx[1] + dx, 0, w - 1);
sum += karr[j] * sview[idx1];
j++;
}
}
dview[idx] = sum / 16;
});
paral_for_pp(tmp2, dst, [&](const auto& pp) { return pp(0, 0); });
}
print_time(label, sw.lap() / loop_count);
}
void f13_2(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
using namespace Concurrency;
using namespace Concurrency::graphics;
namespace cc = Concurrency;
namespace cg = Concurrency::graphics;
int h = src.rows;
int w = src.cols;
std::string label = "13.2|C++AMP texture_view<const float, 2> using sample";
StopWatch sw;
Mtx1f tmp(h, w);
Mtx1f tmp2(h, w);
for(int z = 0; z < loop_count; z++) {
paral_for_pp(src, tmp, [&](const auto& pp) { return pp(0, 0); });
cc::extent<2> ext(h, w);
texture<float, 2> stex(ext, tmp[0], h * w * 4, 32);
const texture_view<const float, 2> sview(stex);
texture<float, 2> dtex(ext, 32);
parallel_for_each(ext, [&, sview, h, w, ext](cc::index<2> idx) restrict(amp) {
float sum = 0;
int j = 0;
const int karr[] = {1, 2, 1, 2, 4, 2, 1, 2, 1};
for(int dy = -1; dy <= 1; dy++) {
for(int dx = -1; dx <= 1; dx++) {
sum += karr[j] * sview.sample(coord(idx[0] + dx, idx[1] + dy, ext));
j++;
}
}
dtex.set(idx, sum / 16);
});
cg::copy(dtex, tmp2[0], h * w * 4);
paral_for_pp(tmp2, dst, [&](const auto& pp) { return uchar(pp(0, 0)); });
}
print_time(label, sw.lap() / loop_count);
}
case14:C++AMP float(byteからfloatの変換を除外して計測)
13のケースでbyteからfloatの変換を除外して計測。オーバヘッドがなくなる分時間は短い。
void f14(Mtx1b& src, Mtx1b& dst, int loop_count)
{
using namespace std;
using namespace Concurrency;
using namespace Concurrency::graphics;
namespace cc = Concurrency;
namespace cg = Concurrency::graphics;
int h = src.rows;
int w = src.cols;
std::string label = "14|C++AMP texture_view<const float, 2>";
Mtx1f tmp(h, w);
Mtx1f tmp2(h, w);
paral_for_pp(src, tmp, [&](const auto& pp) { return pp(0, 0); });
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
cc::extent<2> ext(h, w);
texture<float, 2> stex(ext, tmp[0], h * w * 4, 32);
texture_view<const float, 2> sview(stex);
texture<float, 2> dtex(ext, 32);
parallel_for_each(ext, [&, sview, h, w](cc::index<2> idx) restrict(amp) {
float sum = 0;
int j = 0;
const int karr[] = {1, 2, 1, 2, 4, 2, 1, 2, 1};
for(int dy = -1; dy <= 1; dy++) {
for(int dx = -1; dx <= 1; dx++) {
cc::index<2> idx1;
idx1[0] = cc::clamp(idx[0] + dy, 0, h - 1);
idx1[1] = cc::clamp(idx[1] + dx, 0, w - 1);
sum += karr[j] * sview[idx1];
j++;
}
}
dtex.set(idx, sum / 16);
});
cg::copy(dtex, tmp2[0], h * w * 4);
}
print_time(label, sw.lap() / loop_count);
paral_for_pp(tmp2, dst, [&](const auto& pp) { return pp(0, 0); });
}
void f14_1(Mtx1b& src, Mtx1b& dst, int loop_count)
{
std::string label = "14.1|C++AMP array_view<float, 2>";
using namespace std;
using namespace Concurrency;
using namespace Concurrency::graphics;
namespace cc = Concurrency;
namespace cg = Concurrency::graphics;
int h = src.rows;
int w = src.cols;
Mtx1f tmp(h, w);
Mtx1f tmp2(h, w);
paral_for_pp(src, tmp, [&](const auto& pp) { return pp(0, 0); });
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
cc::extent<2> ext(h, w);
array_view<float, 2> sview(ext, tmp[0]);
array_view<float, 2> dview(ext, tmp2[0]);
parallel_for_each(ext, [&, sview, dview, h, w](cc::index<2> idx) restrict(amp) {
float sum = 0;
int j = 0;
const int karr[] = {1, 2, 1, 2, 4, 2, 1, 2, 1};
for(int dy = -1; dy <= 1; dy++) {
for(int dx = -1; dx <= 1; dx++) {
cc::index<2> idx1;
idx1[0] = cc::clamp(idx[0] + dy, 0, h - 1);
idx1[1] = cc::clamp(idx[1] + dx, 0, w - 1);
sum += karr[j] * sview[idx1];
j++;
}
}
dview[idx] = sum / 16;
});
}
paral_for_pp(tmp2, dst, [&](const auto& pp) { return pp(0, 0); });
print_time(label, sw.lap() / loop_count);
}
void f14_2(Mtx1b& src, Mtx1b& dst, int loop_count)
{
std::string label = "14.2|C++AMP texture_view<const float, 2> using sample";
using namespace std;
using namespace Concurrency;
using namespace Concurrency::graphics;
namespace cc = Concurrency;
namespace cg = Concurrency::graphics;
int h = src.rows;
int w = src.cols;
Mtx1f tmp(h, w);
Mtx1f tmp2(h, w);
paral_for_pp(src, tmp, [&](const auto& pp) { return pp(0, 0); });
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
cc::extent<2> ext(h, w);
texture<float, 2> stex(ext, tmp[0], h * w * 4, 32);
const texture_view<const float, 2> sview(stex);
texture<float, 2> dtex(ext, 32);
parallel_for_each(ext, [&, sview, h, w, ext](cc::index<2> idx) restrict(amp) {
float sum = 0;
int j = 0;
const int karr[] = {1, 2, 1, 2, 4, 2, 1, 2, 1};
for(int dy = -1; dy <= 1; dy++) {
for(int dx = -1; dx <= 1; dx++) {
sum += karr[j] * sview.sample(coord(idx[0] + dx, idx[1] + dy, ext));
j++;
}
}
dtex.set(idx, sum / 16);
});
cg::copy(dtex, tmp2[0], h * w * 4);
}
print_time(label, sw.lap() / loop_count);
paral_for_pp(tmp2, dst, [&](const auto& pp) { return uchar(pp(0, 0)); });
}
case15:Cベースの記述
コア部分をCコード風に書いた。border付きにしているのでそこそこ速い。
void f15(Mtx1b& src, Mtx1b& dst, int loop_count)
{
std::string label = "15|Cベースの記述 ";
using namespace std;
int h = src.rows;
int w = src.cols;
int sstep = src.stepT();
int dstep = dst.stepT();
const uchar* psrc = src[0];
uchar* pdst = dst[0];
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
#pragma omp parallel for
for(int y = 0; y < h; y++) {
const uchar* ps = psrc + y * sstep;
uchar* pd = pdst + y * dstep;
for(int x = 0; x < w; x++) {
*pd = (ps[-sstep - 1] + 2 * ps[-sstep] + ps[-sstep + 1] + 2 * ps[-1] + 4 * ps[0] +
2 * ps[1] + ps[sstep - 1] + 2 * ps[sstep] + ps[sstep + 1]) /
16;
pd++;
ps++;
}
}
}
print_time(label, sw.lap() / loop_count, "bp");
// print(dst);
}
case16:Cベースの記述
コア部分をCコード風に別な書き方で書いた。都度、アドレスを計算することになるが、思ったよりも遅くない。
void f16(Mtx1b& src, Mtx1b& dst, int loop_count)
{
std::string label = "16|Cベースの記述 ";
using namespace std;
int h = src.rows;
int w = src.cols;
int sstep = src.stepT();
int dstep = dst.stepT();
const uchar* psrc = src[0];
uchar* pdst = dst[0];
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate();
#pragma omp parallel for
for(int y = 0; y < h; y++) {
const uchar* ps = psrc + y * sstep;
uchar* pd = pdst + y * dstep;
for(int x = 0; x < w; x++) {
pd[x] =
(ps[x - sstep - 1] + 2 * ps[x - sstep] + ps[x - sstep + 1] + 2 * ps[x - 1] + 4 * ps[x] +
2 * ps[x + 1] + ps[x + sstep - 1] + 2 * ps[x + sstep] + ps[x + sstep + 1]) /
16;
}
}
}
print_time(label, sw.lap() / loop_count, "bp");
// print(dst);
}
case17:Cベースの記述 (auto vectorizationねらい)
auto vectorizationをねらったつもりだが、うまくできていない。
C++だった強制的な32画素単位のループを比較的簡単に作れたが、
やっぱり、OpenMP4.0以降の機能を使ってSIMD化可能なことを指定する必要があるかもしれない。
void f17(Mtx1b& src, Mtx1b& dst, int loop_count)
{
std::string label = "17|Cベースの記述 (auto vectorizationねらい)";
using namespace std;
int h = src.rows;
int w = src.cols;
int sstep = src.stepT();
int dstep = dst.stepT();
uchar* psrc = src[0];
uchar* pdst = dst[0];
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate(); //c++のコードだが、計測をフェアにするため
#pragma omp parallel for
for(int y = 0; y < h; y++) {
uchar* ps = psrc + y * sstep;
uchar* pd = pdst + y * dstep;
uchar* ps1 = ps - sstep - 1;
uchar* ps2 = ps - sstep;
uchar* ps3 = ps - sstep + 1;
uchar* ps4 = ps - 1;
uchar* ps5 = ps + 1;
uchar* ps6 = ps + sstep - 1;
uchar* ps7 = ps + sstep;
uchar* ps8 = ps + sstep + 1;
for(int x = 0; x < w; x++) {
pd[x] = (ps1[x] + 2 * ps2[x] + ps3[x] + 2 * ps4[x] + 4 * ps[x] + 2 * ps5[x] + ps6[x] +
2 * ps7[x] + ps8[x]) /
16;
}
}
}
print_time(label, sw.lap() / loop_count, "bp");
// print(dst);
}
case18:Cベースの記述 (auto vectorizationねらい)
auto vectorizationをねらった別な書き方。やはり、うまくauto vectorizationできていない。
void f18(Mtx1b& src, Mtx1b& dst, int loop_count)
{
std::string label = "18|Cベースの記述 (auto vectorizationねらい)";
using namespace std;
int h = src.rows;
int w = src.cols;
int sstep = src.stepT();
int dstep = dst.stepT();
uchar* psrc = src[0];
uchar* pdst = dst[0];
static const int ker[9] = {1, 2, 1, 2, 4, 2, 1, 2, 1};
StopWatch sw;
for(int z = 0; z < loop_count; z++) {
src.extrapolate(); //c++のコードだが、計測をフェアにするため
#pragma omp parallel for
for(int y = 0; y < h; y++) {
uchar* pd = pdst + y * dstep;
uchar* ps[9];
ps[4] = psrc + y * sstep;
ps[0] = ps[4] - sstep - 1;
ps[1] = ps[4] - sstep;
ps[2] = ps[4] - sstep + 1;
ps[3] = ps[4] - 1;
ps[5] = ps[4] + 1;
ps[6] = ps[4] + sstep - 1;
ps[7] = ps[4] + sstep;
ps[8] = ps[4] + sstep + 1;
int sum[4096] = {0};
for(int j = 0; j < 9; j++) {
for(int x = 0; x < w; x++) {
sum[x] += ker[j] * ps[j][x];
}
}
for(int x = 0; x < w; x++) {
pd[x] = sum[x] / 16;
}
}
}
print_time(label, sw.lap() / loop_count, "bp");
}
開発/実行環境
Visual Studio 2019 Community ver 16.0.3
Intel Core i7-8750H @2.2GHz 6CPU HTあり
NVIDIA GeForce GTX 1060 with Max-Q Design
Windows10 Pro 64bit
コンパイラ設定

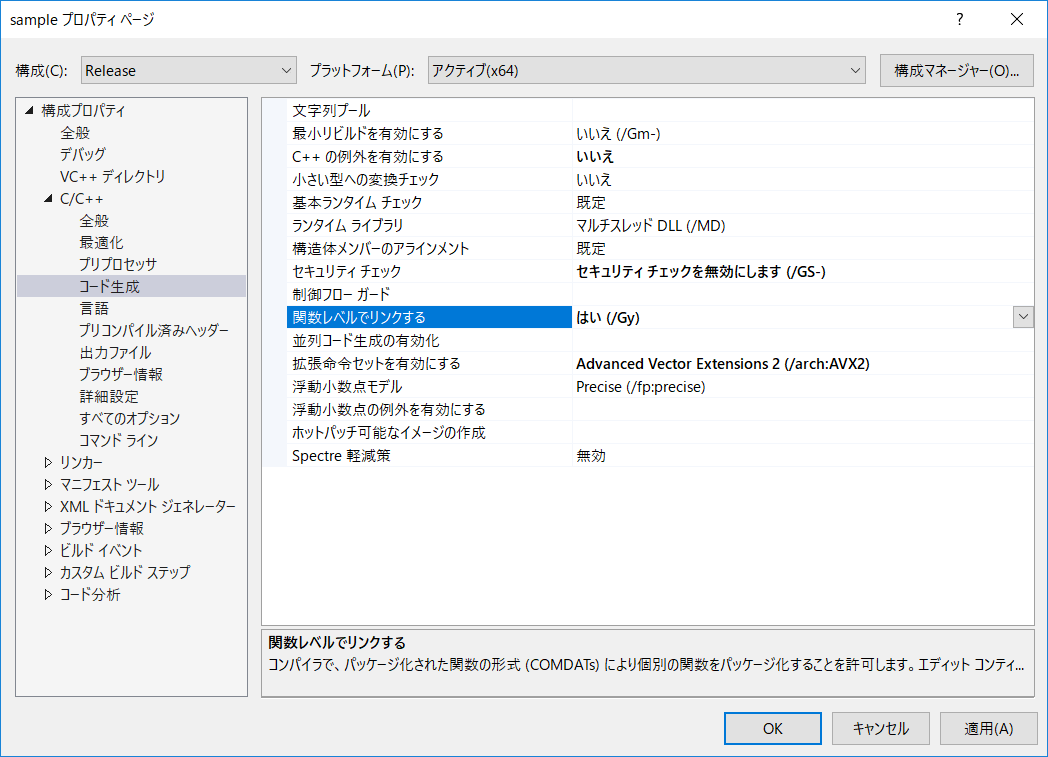

*C++AMPを使う場合、ここの「準拠モード」を「いいえ」にしないと、以下のエラーをだして、コンパイルできない!!!ハマった。
C2614 'Concurrency::graphics::texture<float,2>': イニシャライズ リスト内のクラス '_Texture_base' が基底クラスでもメンバーでもありません。 <br>
コード その2
# if !defined(CVX_H)
# define CVX_H
# include <opencv2/opencv.hpp>
# include <opencv2/highgui/highgui.hpp>
# include <chrono>
# include <thread>
# include <mutex>
# include <valarray>
namespace cvx {
struct Offset
{
Offset(size_t _offset)
: offset(_offset)
{
}
//誤った利用を抑制するためにあえて戻り値はvoidにする
void operator++() { ++offset; }
void operator++(int) { offset++; }
void operator+=(size_t v) { offset += v; }
void operator-=(size_t v) { offset -= v; }
Offset operator+(size_t v) { return Offset(offset + v); }
Offset operator-(size_t v) { return Offset(offset - v); }
size_t offset;
};
//二次元アクセス可能な画素値用ポインタークラス
template<class T>
struct PixPtr
{
public:
PixPtr(T* ptr, size_t step)
: ptr_(ptr)
, step_(step)
{
}
const T* ptr() const { return ptr_; }
T* ptr() { return ptr_; }
inline T* ptr(int dy, int dx) { return ptr_ + step_ * dy + dx; }
inline const T* ptr(int dy, int dx) const { return ptr_ + step_ * dy + dx; }
inline T& operator()(int dy, int dx) { return *ptr(dy, dx); }
inline const T& operator()(int dy, int dx) const { return *ptr(dy, dx); }
void operator++() { ++ptr_; }
void operator++(int) { ptr_++; }
void operator+=(size_t v) { ptr_ += v; }
void operator-=(size_t v) { ptr_ -= v; }
void moveLine(int dy) { ptr += dy * step_; }
PixPtr copyPixPtr(int dy, int dx) { return PixPtr(ptr + dy * step_ + dx, step); }
const PixPtr copyPixPtr(int dy, int dx) const { return PixPtr(ptr + dy * step_ + dx, step); }
private:
size_t step_;
T* ptr_;
};
template<class T>
class Mtx_ : public cv::Mat_<T>
{
public:
using cv::Mat_<T>::Mat_;
using cv::Mat_<T>::operator(); //overloadしているので必要
using cv::Mat_<T>::stepT;
using cv::Mat_<T>::rows;
using cv::Mat_<T>::cols;
Offset calcOffset(int y, int x) const { return Offset(stepT(0) * y + x); }
T& operator()(const Offset& offset) { return dataT()[offset.offset]; }
const T& operator()(const Offset& offset) const { return dataT()[offset.offset]; }
const T& operator()(int y, int x) const { return dataT()[y * stepT() + x]; }
T& operator()(int y, int x) { return dataT()[y * stepT() + x]; }
T* operator[](int y) { return dataT() + y * stepT(); }
const T* operator[](int y) const { return dataT() + y * stepT(); }
T operator()(float y, float x)
{
float fx0 = std::floor(x);
float fy0 = std::floor(y);
float fx1 = fx0 + 1.f;
float fy1 = fy0 + 1.f;
int hb = horzBorder();
int vb = vertBorder();
int x0 = static_cast<int>(fx0);
if(x0 < -hb) x0 = -hb;
if(x0 > cols + hb - 2) x0 = cols + hb - 2;
int y0 = static_cast<int>(fy0);
if(y0 < -vb) y0 = -vb;
if(y0 > rows + vb - 2) y0 = rows + vb - 2;
int x1 = x0 + 1;
int y1 = y0 + 1;
auto p = (*this)[y0] + x0;
T v00 = p[0];
T v10 = p[stepT()];
T v01 = p[1];
T v11 = p[stepT() + 1];
float v0 = v00 * (fx1 - x) + v01 * (x - fx0);
float v1 = v10 * (fx1 - x) + v11 * (x - fx0);
return static_cast<T>(v0 * (fy1 - y) + v1 * (y - fy0));
}
T operator()(cv::Point2f pt) { return (*this)(pt.y, pt.x); }
static Mtx_<T> createWithBorder(int _rows, int _cols, int vborder, int hborder = -1)
{
if(hborder < 0) hborder = vborder;
cv::Mat_<T> mat(_rows + vborder * 2, _cols + hborder * 2);
Mtx_<T> mtx2 = mat(cv::Rect(hborder, vborder, _cols, _rows));
return mtx2;
}
static Mtx_<T> createWithBorder(cv::Size sz, int vborder, int hborder = -1)
{
if(hborder < 0) hborder = vborder;
return createWithBorder(sz.height, sz.width, vborder, hborder);
}
int horzBorder() const
{
cv::Size sz;
cv::Point pt;
this->locateROI(sz, pt);
return pt.x;
};
int vertBorder() const
{
cv::Size sz;
cv::Point pt;
this->locateROI(sz, pt);
return pt.y;
};
void extrapolate()
{
const auto vborder = vertBorder();
const auto hborder = horzBorder();
# if 0
# else
//Left
for(int y = 0; y < rows; y++) {
auto pix = (*this)(y, 0);
auto offset = calcOffset(y, -hborder);
for(int dx = 0; dx < hborder; dx++) {
(*this)(offset) = pix;
offset++;
}
}
//Right
for(int y = 0; y < rows; y++) {
auto pix = (*this)(y, cols - 1);
auto offset = calcOffset(y, cols);
for(int dx = 0; dx < hborder; dx++) {
(*this)(offset) = pix;
offset++;
}
}
//Top
# if 1
for(int y = -1; y >= -vborder; y--) {
std::copy_n(&datacT()[-hborder], stepT(), &dataT()[-hborder + y * stepT()]);
}
# else
for(int y = 0; y < vborder; y++) {
auto offset_s = calcOffset(0, -hborder);
auto offset_d = calcOffset(-y - 1, -hborder);
for(int dx = 0; dx < this->cols + hborder * 2; dx++) {
(*this)(offset_d) = (*this)(offset_s);
offset_d++;
offset_s++;
}
}
# endif
//Bottom
# if 1
for(int y = rows; y < rows + vborder; y++) {
std::copy_n(&datacT()[-hborder + (rows - 1) * stepT()], stepT(),
&dataT()[-hborder + y * stepT()]);
}
# else
for(int y = 0; y < vborder; y++) {
auto offset_s = calcOffset(rows - 1, -hborder);
auto offset_d = calcOffset(rows, -hborder);
for(int dx = 0; dx < cols + hborder * 2; dx++) {
(*this)(offset_d) = (*this)(offset_s);
offset_d++;
offset_s++;
}
}
# endif
# endif
}
const PixPtr<const T> createPixPtr(int y, int x) const
{
return PixPtr<const T>(dataT() + y * stepT() + x, stepT());
}
PixPtr<T> createPixPtr(int y, int x) { return PixPtr<T>(dataT() + y * stepT() + x, stepT()); }
private:
const T* dataT() const { return reinterpret_cast<const T*>(this->data); }
const T* datacT() const { return reinterpret_cast<const T*>(this->data); }
T* dataT() { return reinterpret_cast<T*>(this->data); }
};
using Mtx1b = Mtx_<uchar>;
using Mtx2b = Mtx_<cv::Vec2b>;
using Mtx3b = Mtx_<cv::Vec3b>;
using Mtx4b = Mtx_<cv::Vec4b>;
using Mtx1i = Mtx_<int>;
using Mtx1w = Mtx_<unsigned short>;
using Mtx1f = Mtx_<float>;
using Mtx2f = Mtx_<cv::Vec2f>;
using Mtx3f = Mtx_<cv::Vec3f>;
using Mtx4f = Mtx_<cv::Vec4f>;
template<class T>
void print(const Mtx_<T>& m)
{
int vborder = m.vertBorder();
int hborder = m.horzBorder();
for(int y = -vborder; y < m.rows + vborder; y++) {
for(int x = -hborder; x < m.cols + hborder; x++) {
std::cout << (int)m(y, x) << " ";
}
std::cout << std::endl;
}
}
template<class T, class FUNC, class TD = T>
inline void paral_for_pp_r(const Mtx_<T>& src, Mtx_<TD>& dst, FUNC func)
{
# pragma omp parallel for
for(int y = 0; y < src.rows; y++) {
auto ps = src.createPixPtr(y, 0);
auto pd = dst.createPixPtr(y, 0);
for(int x = 0; x < src.cols; x++) {
pd(0, 0) = func(ps);
ps++;
pd++;
}
}
}
template<int UNIT, class T, class TD, class FUNC>
inline void for_ps_pd_idx_old(const T* ps, TD* pd, int n, FUNC func)
{
int nUNIT = n / UNIT * UNIT;
int i = 0;
const T* pst = ps;
TD* pdt = pd;
for(; i < nUNIT; i += UNIT) {
for(int j = 0; j < UNIT; j++) {
func(pst, pdt, j);
}
pst += UNIT;
pdt += UNIT;
}
int j = 0;
for(; i < n; i++) {
func(pst, pdt, j);
j++;
}
}
template<int UNIT, class T, class TD, class FUNC>
inline void for_ps_pd_idx(const T* ps, TD* pd, int n, FUNC func)
{
const int nUNIT = n / UNIT * UNIT;
int i = 0;
const T* pst = ps;
TD* pdt = pd;
for(; i < nUNIT; i += UNIT) {
for(int j = 0; j < UNIT; j++) {
func(pst, pdt, j);
}
pst += UNIT;
pdt += UNIT;
}
if constexpr(UNIT > 8) {
const int n8 = n / 8 * 8;
for(; i < n8; i += 8) {
for(int j = 0; j < 8; j++) {
func(pst, pdt, j);
}
pst += 8;
pdt += 8;
}
}
int j = 0;
for(; i < n; i++) {
func(pst, pdt, j);
j++;
}
}
template<int UNIT, class T, class TD, class FUNC>
inline void for_v_r_old(const T* ps, TD* pd, int n, FUNC func)
{
const int nUNIT = n / UNIT * UNIT;
int i = 0;
const T* pst = ps;
TD* pdt = pd;
for(; i < nUNIT; i += UNIT) {
for(int j = 0; j < UNIT; j++) {
pdt[j] = func(pst[j]);
}
pst += UNIT;
pdt += UNIT;
}
int j = 0;
for(; i < n; i++) {
pdt[j] = func(pst[j]);
j++;
}
}
template<int UNIT, class T, class TD, class FUNC>
inline void for_v_r(const T* ps, TD* pd, int n, FUNC func)
{
const int nUNIT = n / UNIT * UNIT;
const int n8 = n / 8 * 8;
int i = 0;
const T* pst = ps;
TD* pdt = pd;
for(; i < nUNIT; i += UNIT) {
for(int j = 0; j < UNIT; j++) {
pdt[j] = func(pst[j]);
}
pst += UNIT;
pdt += UNIT;
}
for(; i < n8; i += 8) {
for(int j = 0; j < 8; j++) {
pdt[j] = func(pst[j]);
}
pst += 8;
pdt += 8;
}
int j = 0;
for(; i < n; i++) {
pdt[j] = func(pst[j]);
j++;
}
}
template<int UNIT, class T, class TD, FUNC func)
{
const int nUNIT = n / UNIT * UNIT;
const int n8 = n / 8 * 8;
int i = 0;
const T* pst = ps;
TD* pdt = pd;
for(; i < nUNIT; i += UNIT) {
for(int j = 0; j < UNIT; j++) {
func(pst[j], pdt[j]);
}
pst += UNIT;
pdt += UNIT;
}
if constexpr(UNIT > 8) {
for(; i < n8; i += 8) {
for(int j = 0; j < 8; j++) {
func(pst[j], pdt[j]);
}
pst += 8;
pdt += 8;
}
}
int j = 0;
for(; i < n; i++) {
func(pst[j], pdt[j]);
j++;
}
}
template<int UNIT, class TD, class FUNC>
inline void for_p_idx(int n, TD* p, FUNC func)
{
int nn = n / UNIT * UNIT;
int i = 0;
TD* pdt = p;
for(; i < nn; i += UNIT) {
for(int j = 0; j < UNIT; j++) {
func(pdt, j);
}
pdt += UNIT;
}
int j = 0;
for(; i < n; i++) {
func(pdt, j);
j++;
}
}
template<class FUNC>
inline void for_dy_dx(int vr, int hr, FUNC func)
{
for(int dy = -vr; dy <= vr; dy++) {
for(int dx = -hr; dx <= hr; dx++) {
func(dy, dx);
}
}
}
template<class FUNC>
inline void for_dydx(int vr, int hr, FUNC func)
{
for_dy_dx(vr, hr, func);
}
template<class MAT>
void fill_test_value(MAT& m)
{
int i = 0;
for(int y = 0; y < m.rows; y++) {
for(int x = 0; x < m.cols; x++) {
m(y, x) = i % 255;
i++;
}
}
}
template<class MAT, class T>
void fill_all(MAT& m, T v)
{
# pragma omp parallel for
for(int y = 0; y < m.rows; y++) {
for(int x = 0; x < m.cols; x++) {
m(y, x) = v;
}
}
}
template<class T>
bool check_value(const Mtx_<T>& src, const Mtx_<T>& ref, int border = 0)
{
for(int y = -border; y < src.rows + border; y++) {
auto ps = src.createPixPtr(y, 0);
auto pr = ref.createPixPtr(y, 0);
for(int x = -border; x < src.cols + border; x++) {
if(pr(0, 0) != ps(0, 0)) goto ERROR_EIXT;
ps++;
pr++;
}
}
return true;
ERROR_EIXT:
std::cout << std::endl;
print(ref);
print(src);
std::cout << "failed." << std::endl;
return false;
}
template<class T, int RSZ>
struct Kernel
{
static constexpr int SZ = RSZ * 2 + 1;
inline T operator()(int dy, int dx) { return data[SZ * (dy + RSZ) + (dx + RSZ)]; }
inline T operator()(int dy, int dx) const { return data[SZ * (dy + RSZ) + (dx + RSZ)]; }
void copy(T* p) { std::memcpy(data, p, SZ * SZ * sizeof(T)); }
T data[SZ * SZ];
static constexpr int radius = RSZ;
template<class FUNC>
inline void for_(FUNC func)
{
for_dydx(radius, radius, [&](int dy, int dx) { func((*this)(dy, dx), dy, dx); });
}
template<class TP>
T convolute(const PixPtr<TP>& pp) const
{
T sum = 0;
for_dydx(radius, radius, [&](int dy, int dx) { sum += (*this)(dy, dx) * pp(dy, dx); });
return sum;
}
Kernel() = default;
template<class... A>
Kernel(A... args)
{
int j = 0;
for(int i : std::initializer_list<int>{args...}) {
data[j] = i;
// if(j == ) break;
j++;
}
}
};
template<class T, int RSZ>
struct SepKernel
{
T operator()(int d) { return data[std::abs(d)]; }
void copy(T* p) { std::memcpy(data, p, (RSZ + 1) * sizeof(T)); }
T data[RSZ + 1];
static constexpr int radius = RSZ;
template<class TP>
T convolute(const PixPtr<TP>& pp, bool horz)
{
// std::vector<T> lines((2 * RSZ + 1) * pp.step_);
T sum = data[0] * pp(0, 0);
if(horz) {
for(int d = 1; d <= RSZ; d++) {
sum += data[d] * (pp(0, d) + pp(0, -d));
}
} else {
for(int d = 1; d <= RSZ; d++) {
sum += data[d] * (pp(d, 0) + pp(-d, 0));
}
}
return sum;
}
template<class... A>
SepKernel(A... args)
{
int j = 0;
for(T i : std::initializer_list<int>{args...}) {
data[j] = i;
if(j == RSZ) break;
j++;
}
j++;
for(; j <= RSZ; j++) {
data[j] = 0;
}
}
};
} //namespace cvx
# endif //#if !defined(CVX_H)```
```c++:amp_utils.h
# if !defined(AMP_UTILS_H)
# define AMP_UTILS_H
# include <amp.h>
namespace Concurrency {
template<class FUNC>
void for_dy_dx(int vr, int hr, FUNC func) __GPU
{
for(int dy = -vr; dy <= vr; dy++) {
for(int dx = -hr; dx <= hr; dx++) {
func(dy, dx);
}
}
}
template<class T>
T clamp(T v, T l, T u) __GPU
{
return v > u ? u : (v < l ? l : v);
}
graphics::float_2 coord(const index<2>& idx, const extent<2>& ext) restrict(amp)
{
return graphics::float_2((idx[1] + 0.5f) / (float)ext[1], (idx[0] + 0.5f) / (float)ext[0]);
}
graphics::float_2 coord(float x, float y, const extent<2>& ext) restrict(amp)
{
return graphics::float_2((y+ 0.5f) / (float)ext[1], (x + 0.5f) / (float)ext[0]);
}
} // namespace Concurrency
# endif //#if !defined(AMP_UTILS_H)
# if !defined(STX_H)
# define STX_H
# include <chrono>
# include <thread>
# include <mutex>
# include <valarray>
namespace stx {
///StopWath class
struct StopWatch
{
public:
StopWatch()
: susupending_duration_(0)
, suspending_(false)
{
pre_ = std::chrono::high_resolution_clock::now();
}
///returns lap time in ms.
double lap()
{
auto tmp = std::chrono::high_resolution_clock::now(); //sotres time.
auto dur = tmp - pre_;
if(!suspending_) dur += susupending_duration_;
pre_ = tmp;
return std::chrono::duration_cast<std::chrono::nanoseconds>(dur).count() / 1000000.0;
}
///suspends time count
void suspend()
{
susupended_time_ = std::chrono::high_resolution_clock::now();
suspending_ = true;
}
///resumues time count
void resumue()
{
auto tmp = std::chrono::high_resolution_clock::now(); //sotres time.
susupending_duration_ = tmp - susupended_time_;
suspending_ = false;
}
private:
std::chrono::high_resolution_clock::time_point pre_;
std::chrono::high_resolution_clock::time_point susupended_time_;
std::chrono::high_resolution_clock::duration susupending_duration_;
bool suspending_;
};
template<class INTEGRAL_TYPE>
constexpr int iround(INTEGRAL_TYPE v)
{
return static_cast<int>(v);
}
constexpr int iround(float v)
{
if(v >= 0) {
return static_cast<int>(v + 0.5f);
} else {
return -static_cast<int>(-v + 0.5f);
}
}
constexpr int iround(double v)
{
if(v >= 0) {
return static_cast<int>(v + 0.5);
} else {
return -static_cast<int>(-v + 0.5);
}
}
constexpr int iround(long double v)
{
if(v >= 0) {
return static_cast<int>(v + 0.5l);
} else {
return -static_cast<int>(-v + 0.5l);
}
}
template<class INTEGRAL_TYPE>
constexpr int itrunc(INTEGRAL_TYPE v)
{
return static_cast<int>(v);
}
constexpr int itrunc(float v)
{
if(v >= 0) {
return static_cast<int>(v);
} else {
return -static_cast<int>(-v);
}
}
constexpr int itrunc(double v)
{
if(v >= 0) {
return static_cast<int>(v);
} else {
return -static_cast<int>(-v);
}
}
constexpr int itrunc(long double v)
{
if(v >= 0) {
return static_cast<int>(v);
} else {
return -static_cast<int>(-v);
}
}
} // namespace stx
# endif //#if !defined(STX_H)
履歴
2019/4/28 初版
2019/5/10 rev2
- ケースを追加、case0がloopしておらず速すぎた問題を修正
2019/5/12 rev2.1
- ケースを追加
- 計測方法を変更(回数を増やして、結果は一回あたりの時間にした)
- コンパイラオプション変更
- C++AMPで結果が他と不一致になっていた問題の修正
2019/5/15 rev3
- Cベースのコードを追加
- 最速コードを追加
*誤字脱字等は適宜修正