はじめに
Document型DBといえばMongoDBが定番ですが、ReplicationやShardingの構築かなり複雑です。一方RethinkDBはこれらがとても簡単にでき、私も徐々にMongoDBからRethinkDBにシフトしています。今回はDockerを使用してRethinkDBのクラスタ機能を構築して試してみます。
環境の準備
Dockerの環境を各自構築してください。私は普段はUbuntuを使用しているのでそのままインストールしました。
- OS: Ubuntu 14.04
- Docker: 1.9.1
- Dokcer Compose: 1.5.1
WindowsやMac等を使用している方はVirtualBox(+Vagrant)等でCoreOSを立ちあげればすぐにDockerの環境が整います。もちろんUbuntu 14.04やCentos 7などのVMを作って自分でDockerを入れてもOKです。あとは公式の手順などを参考にDocker Composeをインストールしてください。
クラスタの起動
構成
次のようにdocker-compose.ymlを準備します。
seed:
image: rethinkdb:2
ports:
- 8081:8080
command: rethinkdb -n rethink_seed --bind all
worker:
image: rethinkdb:2
links:
- seed:seed
command: rethinkdb --bind all -j seed:29015
proxy:
image: rethinkdb:2
ports:
- 8080:8080
links:
- worker:worker
command: rethinkdb proxy --bind all -j worker:29015
seedは種となるノードでこれにworkerノードがつながってRethinkDBのクラスタを形成します。-jオプションで接続する他のRethinkDBのアドレスとポートを指定します。ここではDockerのlink機能を使用してseed:29015のように指定しています。workerはDocker Composeのscaleを使用すれば複数のコンテナをすぐに起動できます。proxyというのは自身はデータを保存せず、クエリの転送や処理のみを行うノードです。こちらはworkerに接続します。あとでブラウザから操作するのでseedとproxyはそれぞれhttpのポートをホストにマッピングしています。
起動
以下のコマンドでseedのRethinkDBコンテナが立ち上がります。
$ docker-compose up -d seed
ブラウザでhttp://host:8081にアクセスしてください。hostはDockerのホストのIPアドレスです。直接Ubuntuなどにインストールしている場合は127.0.0.1になり、VirtualBoxを使用している場合はゲストVMのIPアドレスです。
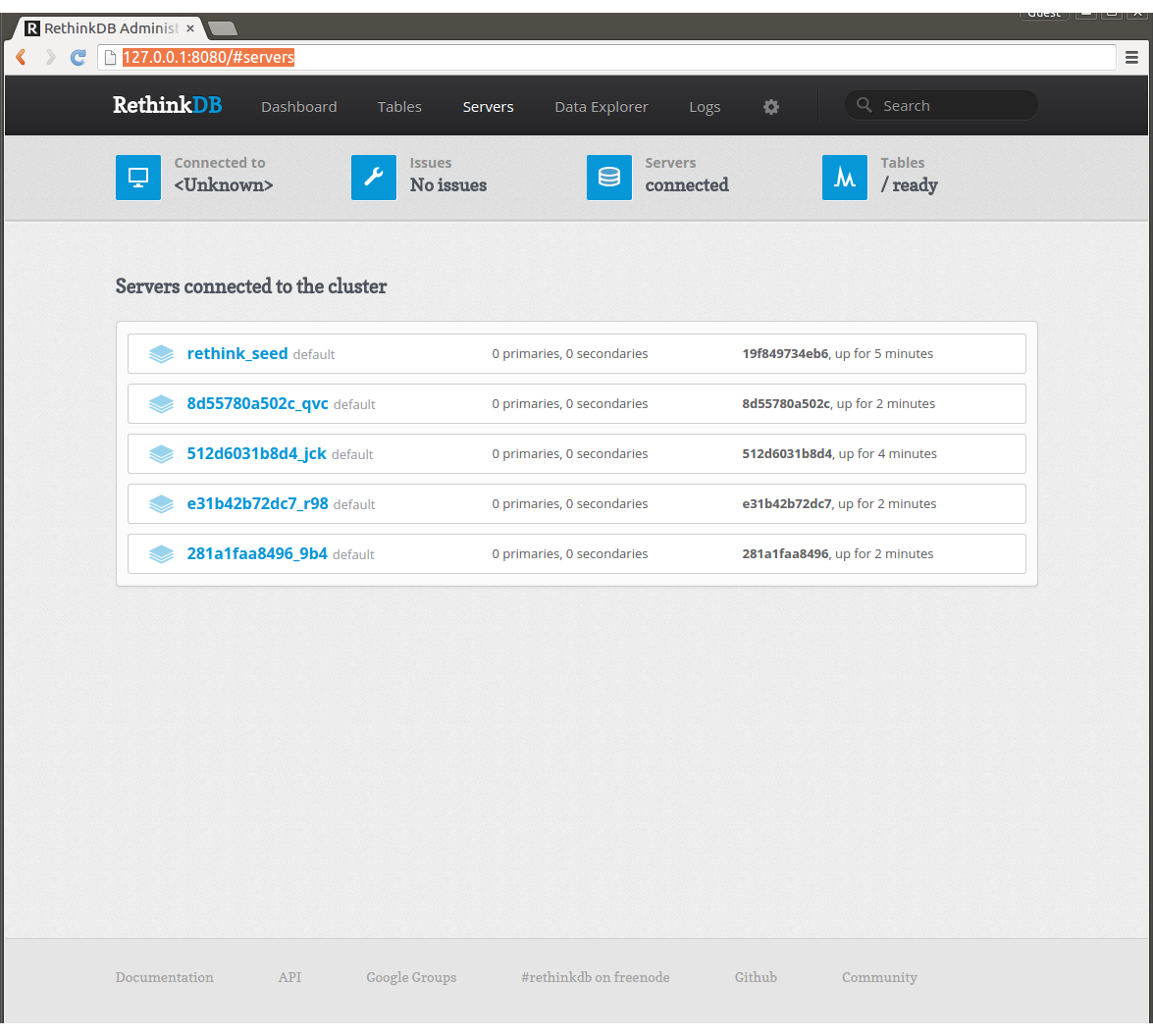
管理画面が表示されました。
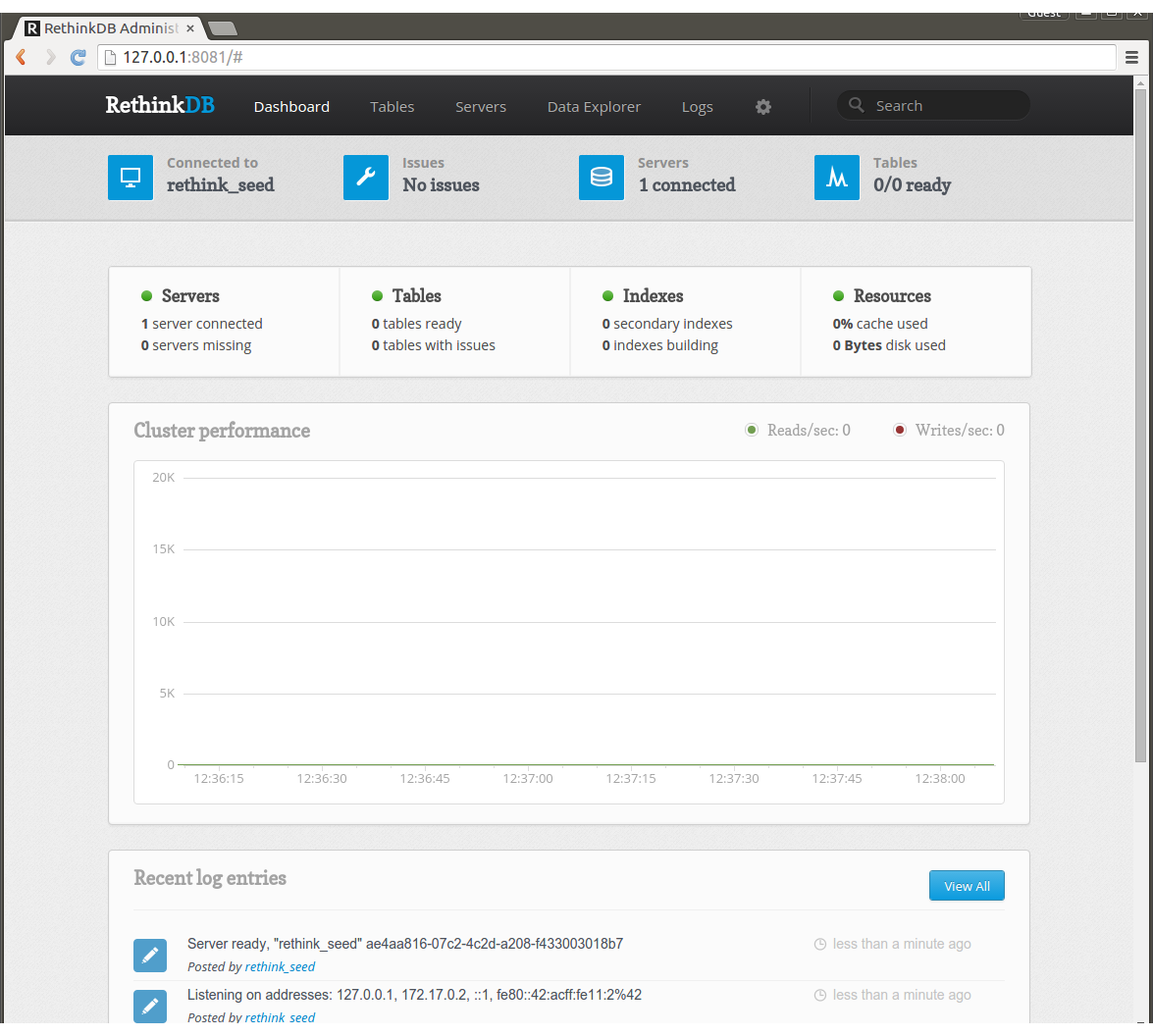
Serversを見るとrethink_seedの1ノードだけいます。
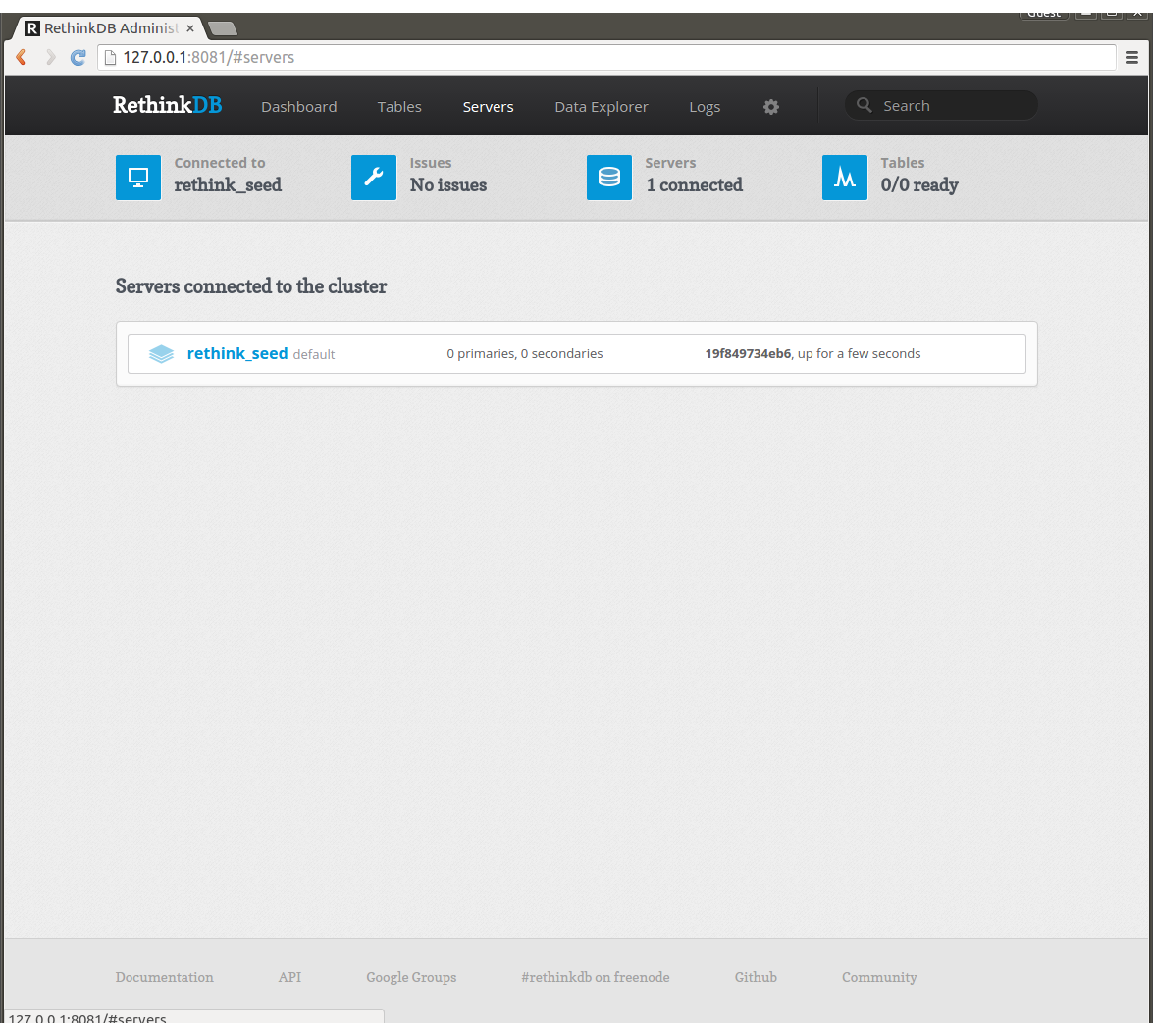
次にworkerも立ち上げます。
$ docker-compose up -d worker
すぐにノードが1つ増えます。今度はserver nameを指定していないのでランダムに名前がついています。
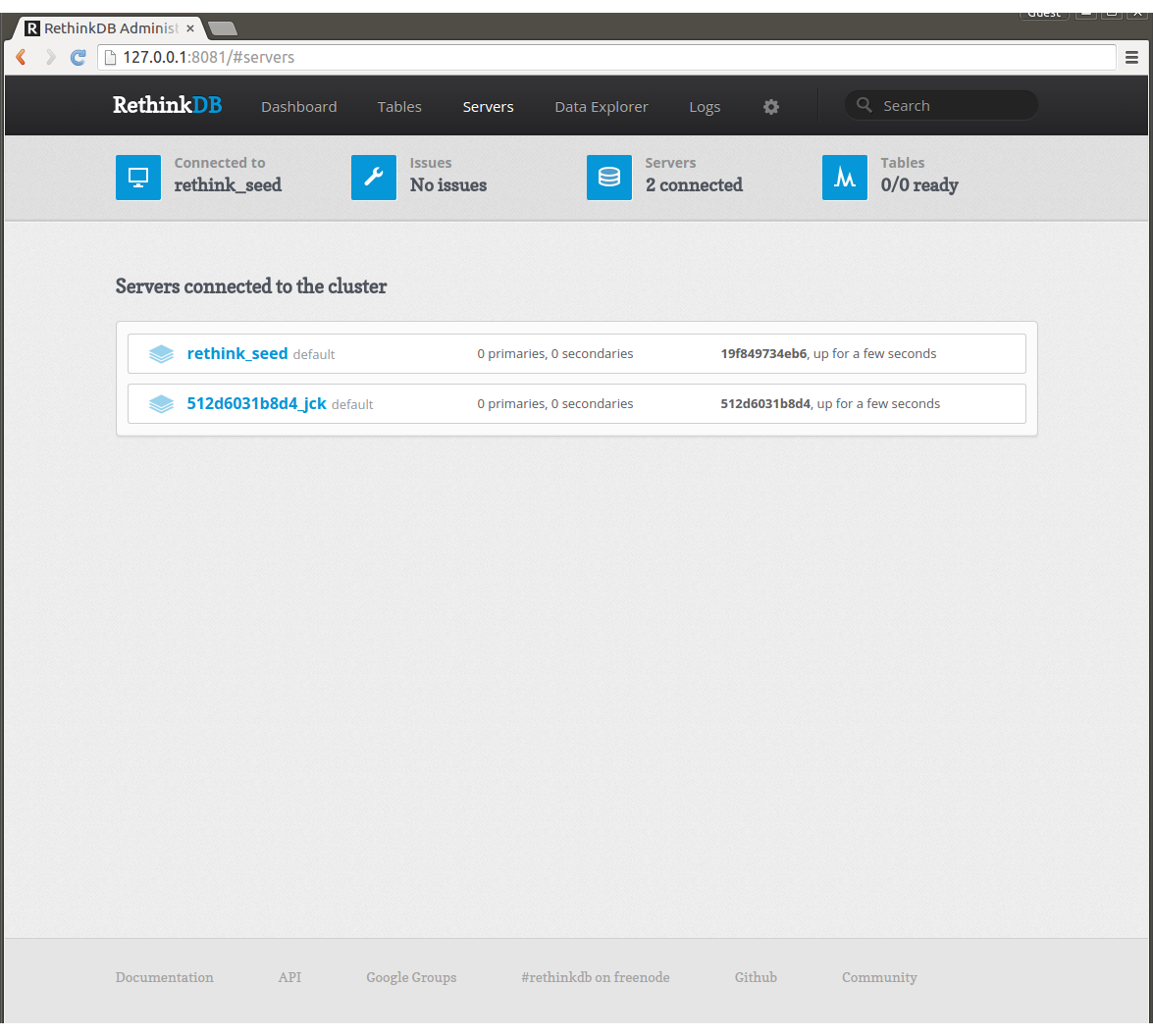
workerを4つに増やしてみましょう。
$ docker-compose scale worker=4
一瞬で5ノードのクラスタが出来ました。
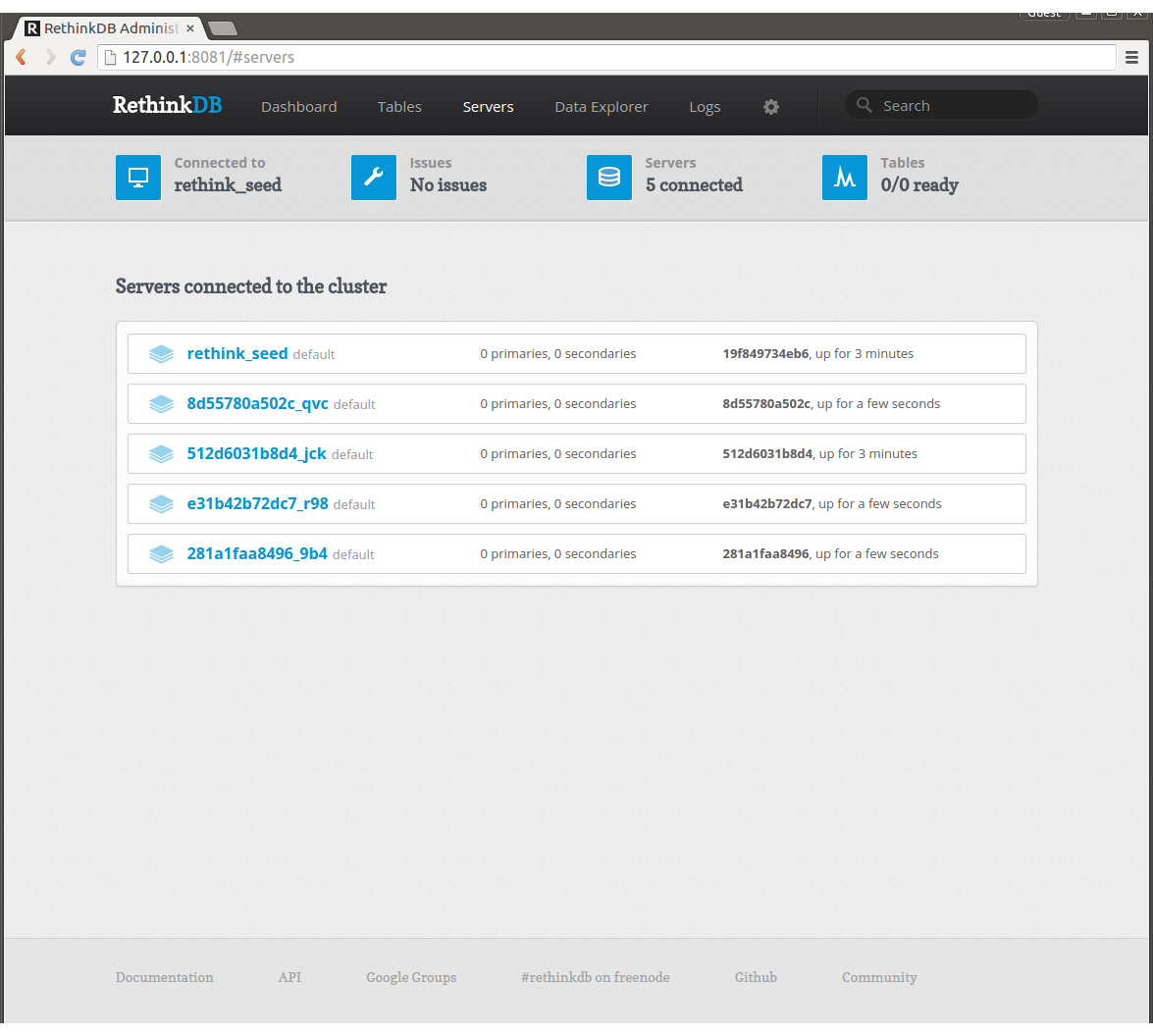
最後にproxyを立ち上げ、ブラウザで8080ポートにアクセスします。
$ docker-compose up -d proxy
proxyは4つのworkerのうちのどれかにつながっておりますが、proxyからも5ノードが見えているのがわかります。ただしproxy自身はデータを持たないノードなのでノードは6つには増えません。
DB,テーブル、データ
DBとテーブルの作成
proxyの管理画面をブラウザで開き、Tablesのタブを開いてください。はじめはtestというDBのみが存在しています。
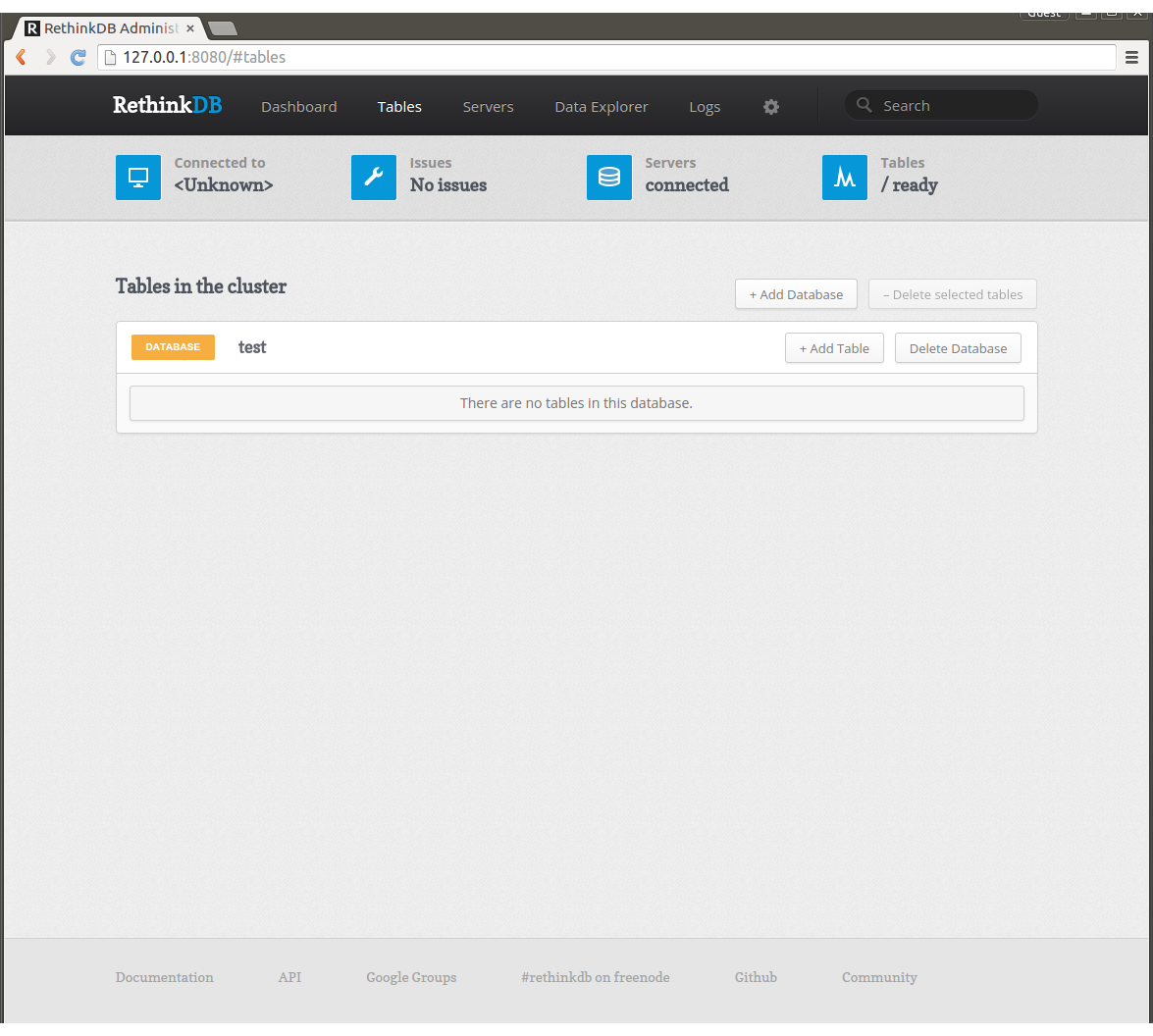
RethinkDBはブラウザからDBやテーブルを作成することができ、冗長化の設定もできます。+Add Databaseと書いてあるボタンを押し、marvelというDBを作成します。つぎにmarvelの*+Add Table*をクリックしてheroesというテーブルを作ります。作成が完了するとheroesをクリックしてテーブルの管理画面に進めます。
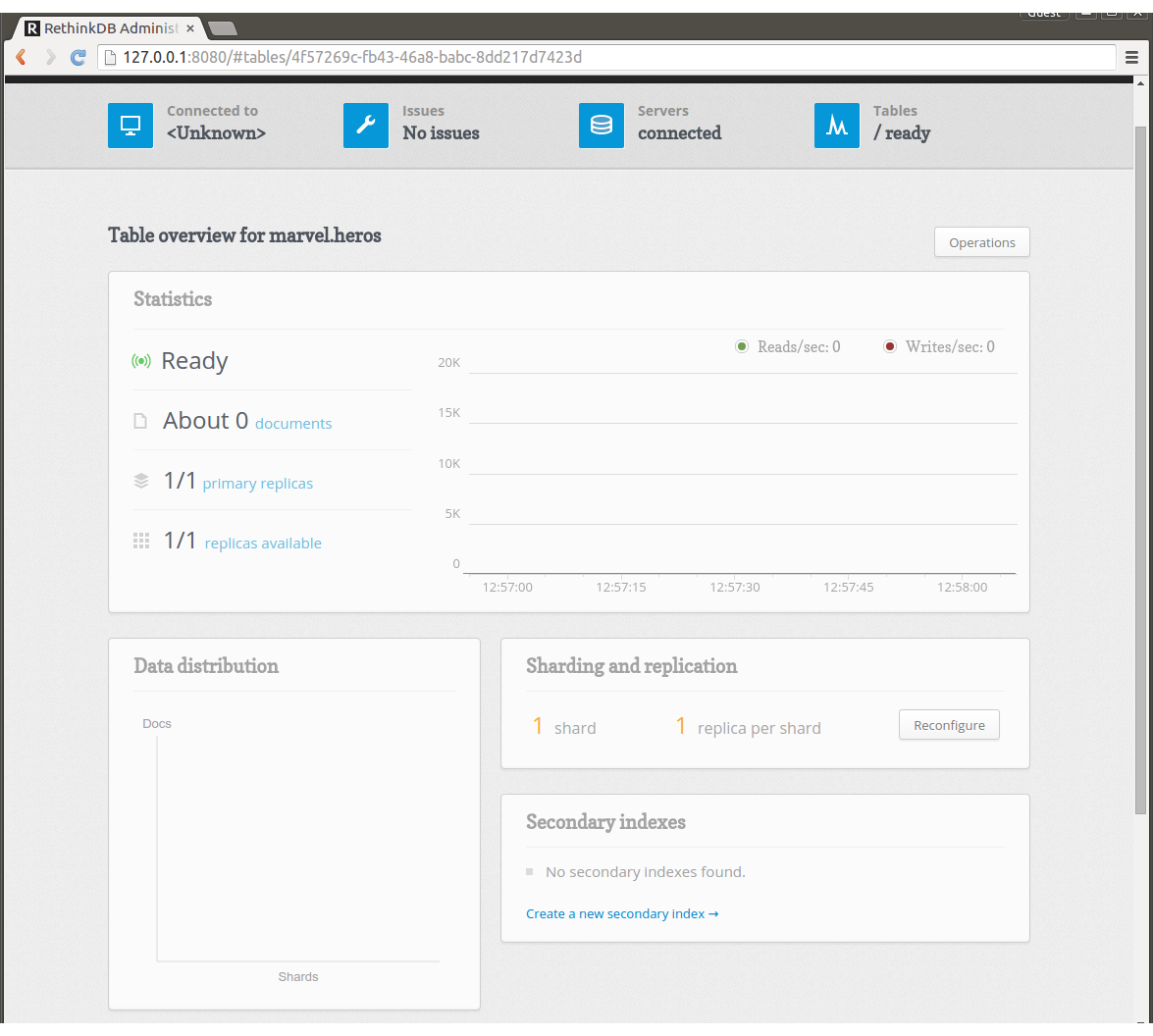
最初はrethink_seedのみにデータが保存されるのでSharding and replicationにあるReconfigureのボタンをクリックし、replicaとshardの数を設定します。例えばreplica=3, shard=2という設定にします。
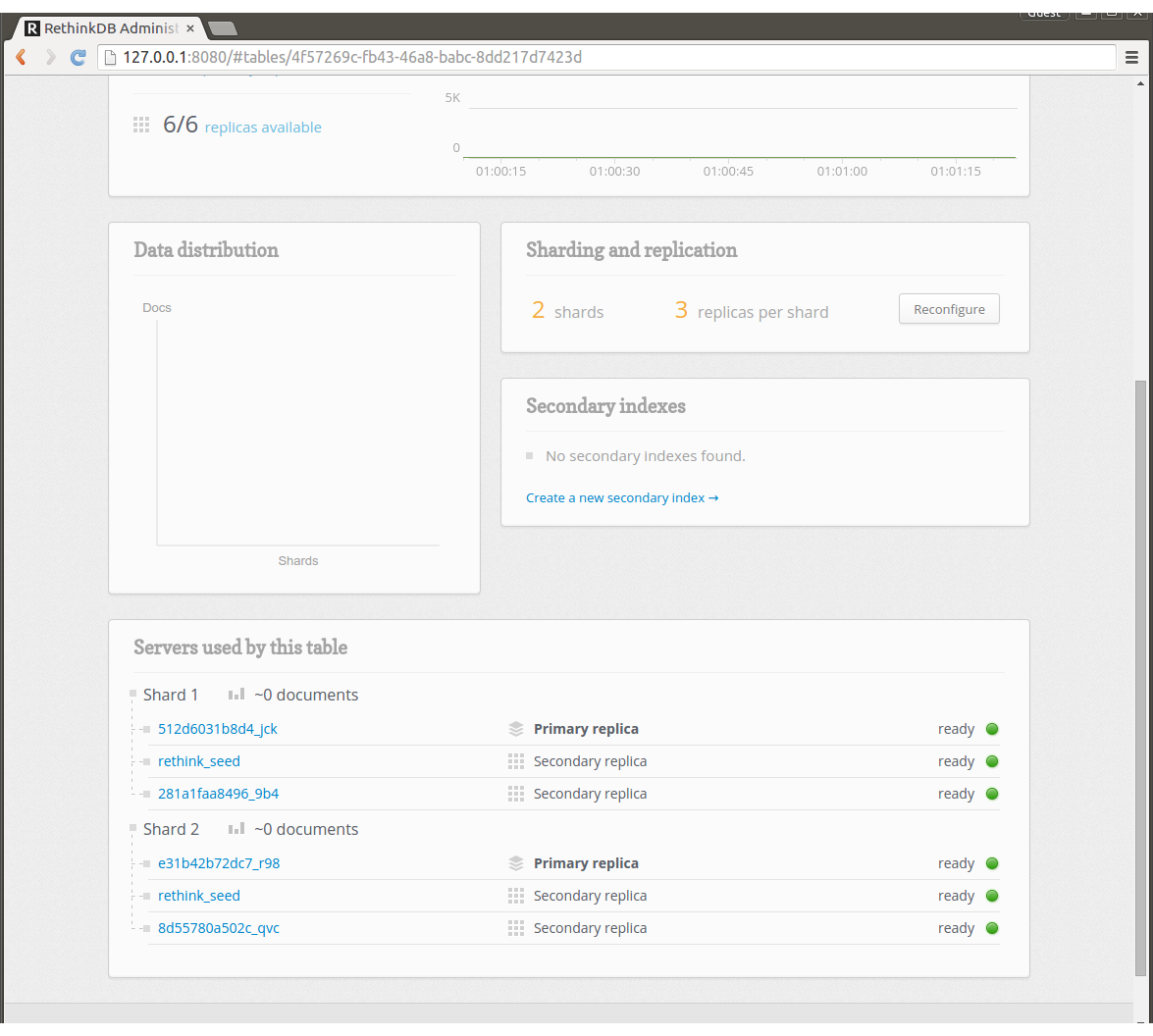
これでDBとテーブルの準備が完了しました。
データ投入
Data Explorerタブをクリックし、テキストエリアに次のコマンドを入力してRUNボタンを押します。
r.db("marvel").table("heroes").insert([
{
"name": "Steve Rogers",
"alias": "Captain America",
"species": "Human",
"affiliations": ["Avengers", "S.H.I.E.L.D"]
},
{
"name": "Tony Stark",
"alias": "Iron Man",
"species": "Human",
"affiliations": ["Avengers", "Stark Industries", "Illuminati"]
},
{ "name": "Matthew Murdock",
"alias": "Daredevil",
"species": "Human",
"affiliations": ["Defenders", "Heroes for Hire"]
},
{ "name": "Thor Ordinson",
"species": "Asgardian",
"affiliations": ["Avengers"]
}
])
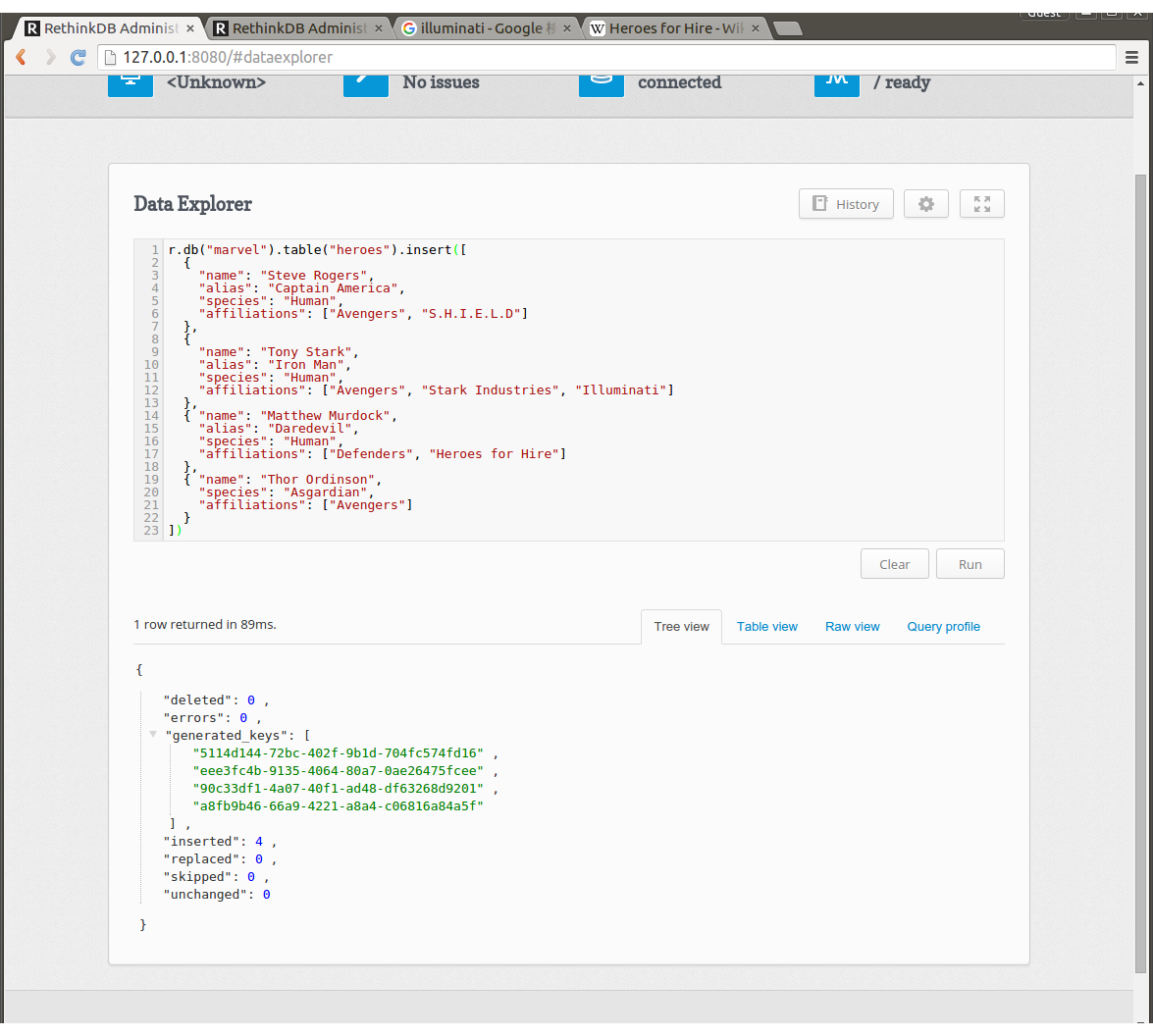
結果のJSONで**"inserted":4**となっていれば成功です。
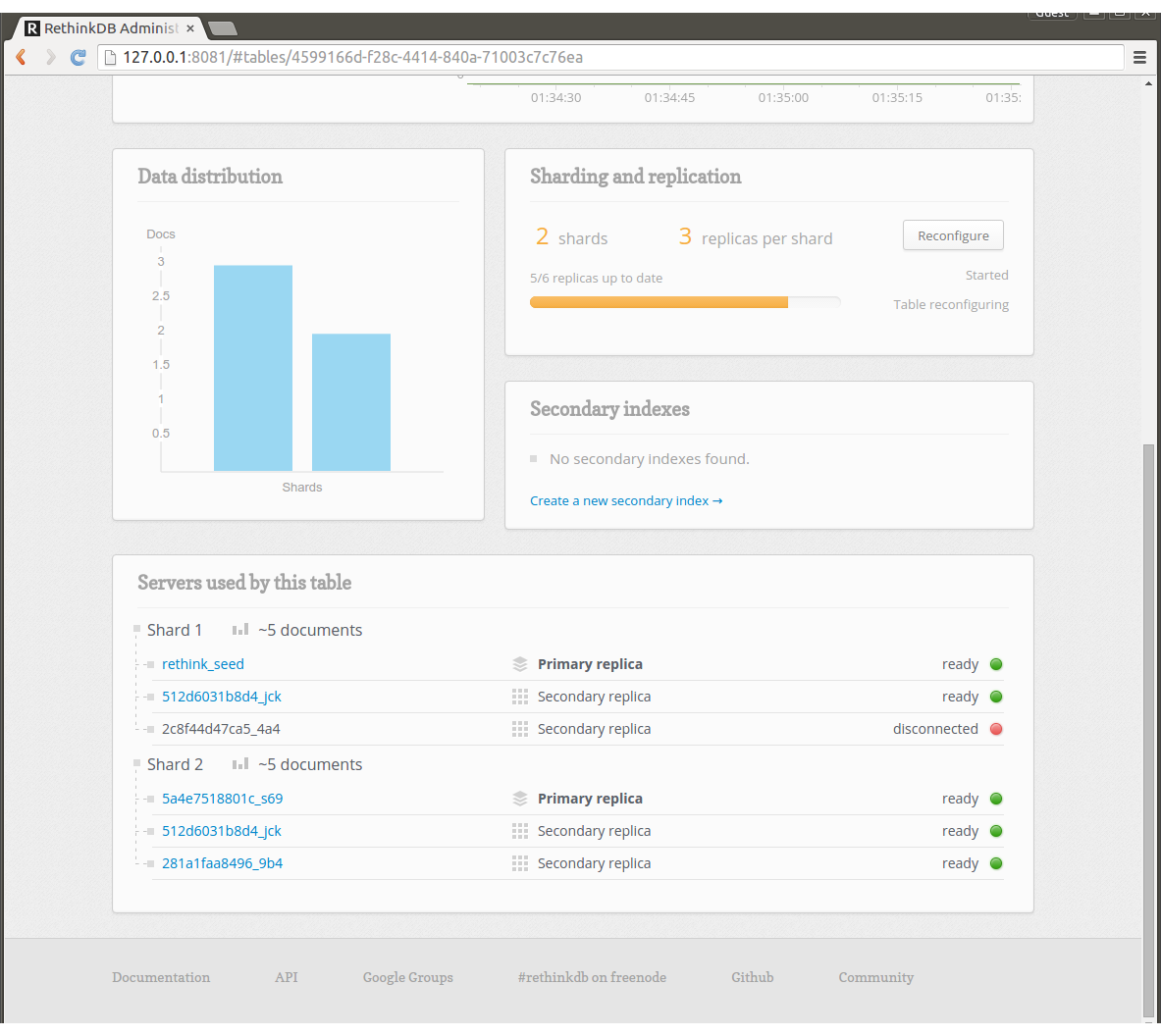
最後にseedのノードからデータが入ったことと冗長性を確認します。以下のコマンドで4つ目のworkerを壊します。
$ docker-compose scale worker=3
Tableの状態を見るとshard1のreplicaが1つdisconnectedになってしまいました。
この状態でData Explorerのテキストエリアに以下のクエリを入力し、RUNを押します。
r.db("marvel").table("heroes")
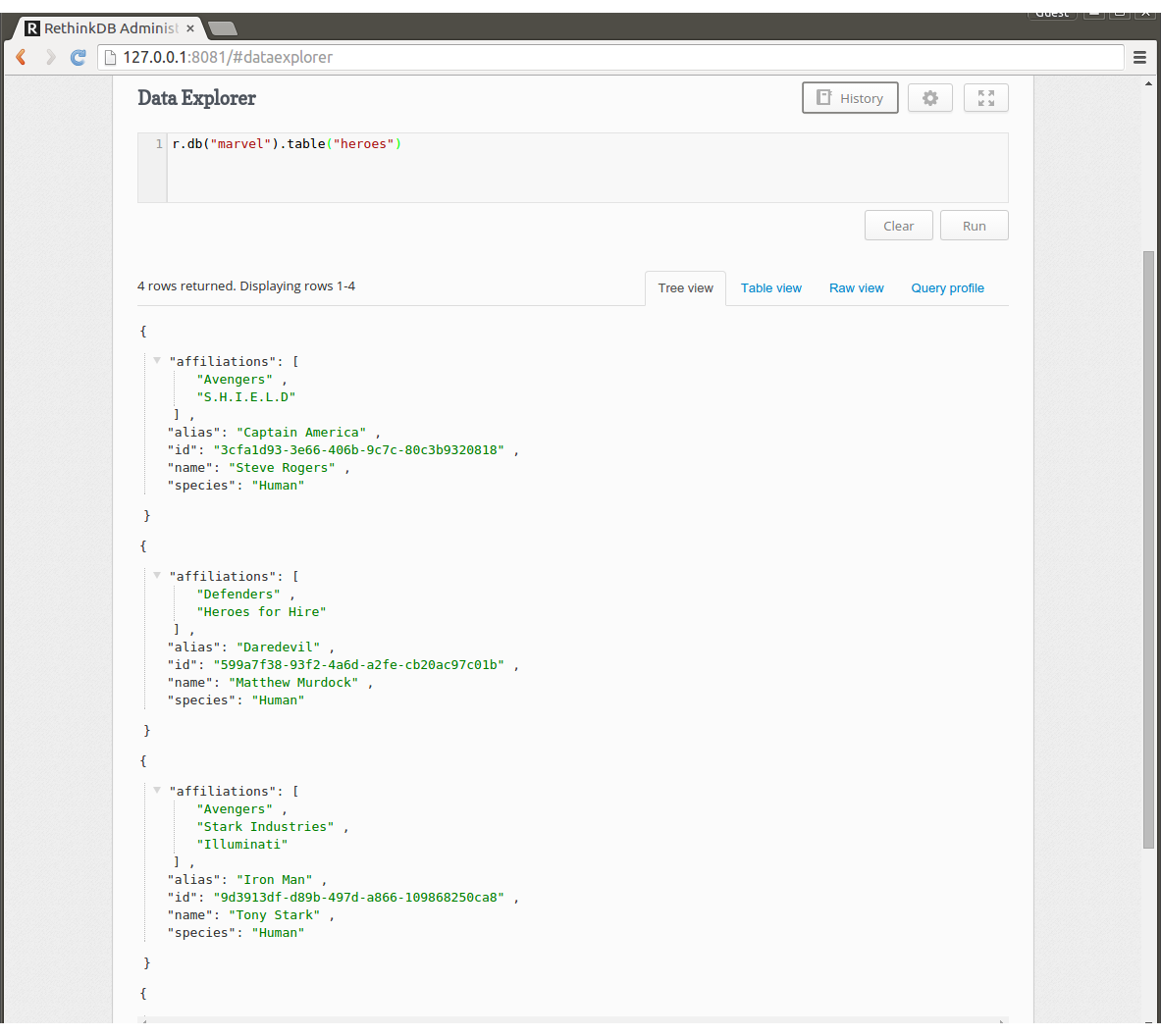
1つノードが欠損しても先ほど挿入した4つのデータが入っていることが確認できました。
まとめ
RethinkDBを使えば非常に簡単にクラスタを組むことができます。MongoDBのクラスタを組むのに疲れてしまった人はぜひお試しください。