lower_bound, upper_bound、結局どっちを使えばいいの?ってなる場面が多かったので、メモがてらに書いてみる。この記事では直感的にlower_boundやupper_boundが使いこなせるようになることを目指す。例えば、
vector<int> v = {40, 20, 20, 19, 1};
と降順に並ぶ配列に対して41, 40, 39, 21, 20, 19, 18, 2, 1, 0などをkeyとしたとき、lower_bound, upper_boundをどう使えばいいのか、そしてそれがどこのイテレータを返すのかがすぐ分からない人に向けての記事になる。あくまで一つの覚え方であることには留意してほしい。
注意事項(よまなくてもいい)
前提として、今回使うコンテナはvectorである。また、配列はすでにsort済みであるとする。C++11からsort済みでなくてもある基準を満たしていればlower_boundやupper_boundを使うことはできる( 参考:https://cpprefjp.github.io/reference/algorithm/lower_bound.html )が、今回は無視する。
昇順の配列に対する使い方
vector<int> v = {1, 1, 1, 2, 2, 3, 3, 3, 5};
に対して使ってみる。例えば2をkeyとして二分探索するには、単純に
lower_bound(v.begin(), v.end(), 2);
upper_bound(v.begin(), v.end(), 2);
とかけばよい。そして、これらは何を返すだろうか。次のように考えるとわかりやすい:
keyを割り込ませて、残りを右にずらしたとき、配列はsortされたままであるような位置のイテレータを返す。そして、lower_boundはそのような位置の中で一番左(ゆえにlower)、upper_boundは一番右(ゆえにupper)の位置を返す。
次の図をみればわかると思う(key = 0, 1, 2, 3, 4, 5, 6)。
key = 0のとき
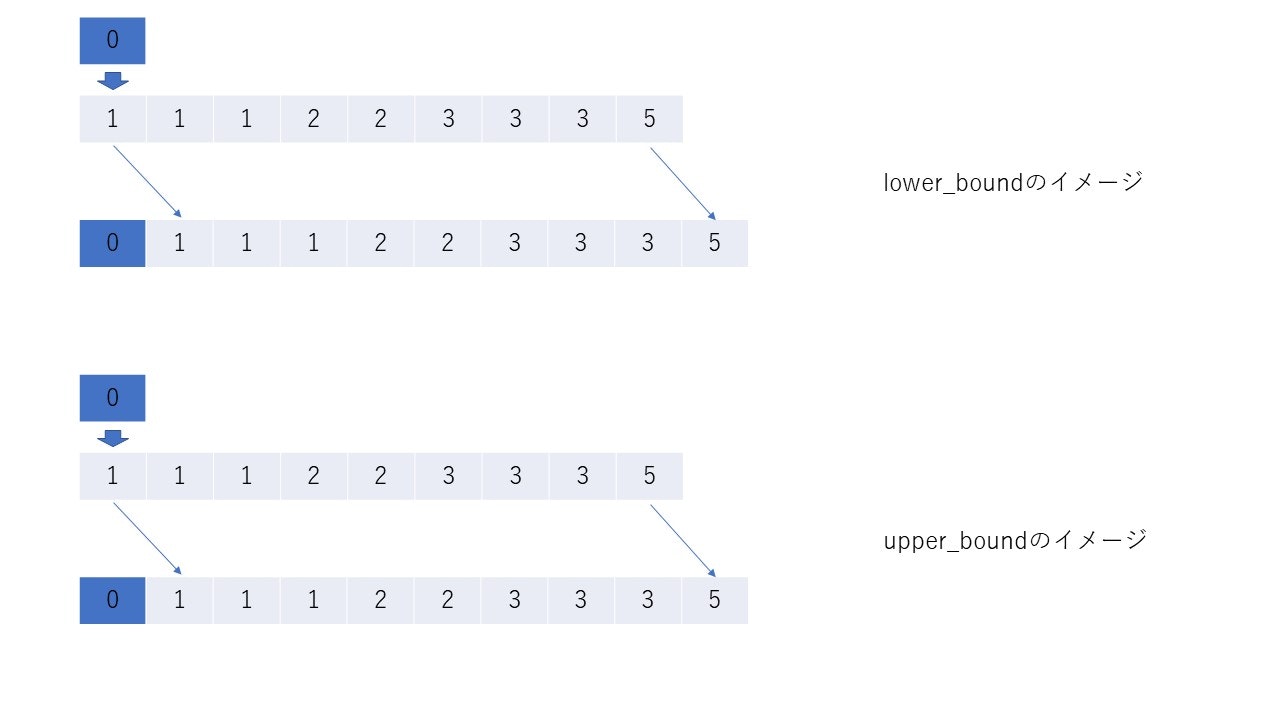
key = 1のとき
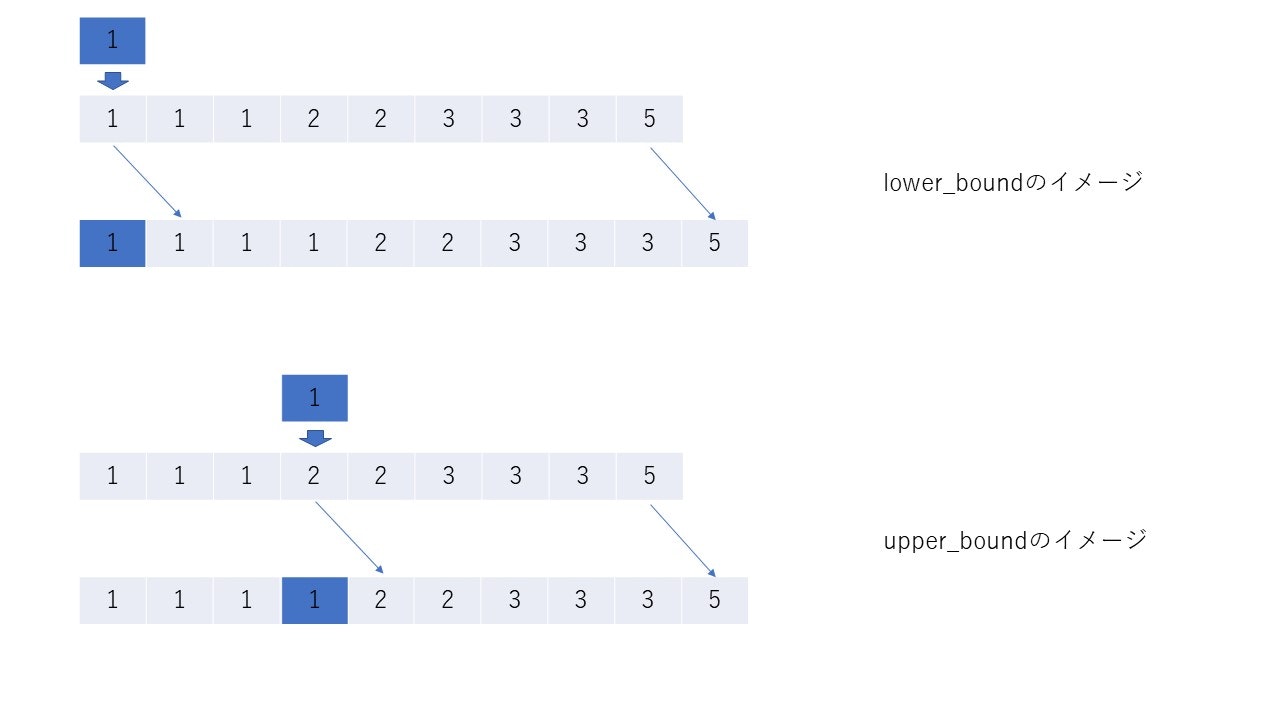
key = 2のとき
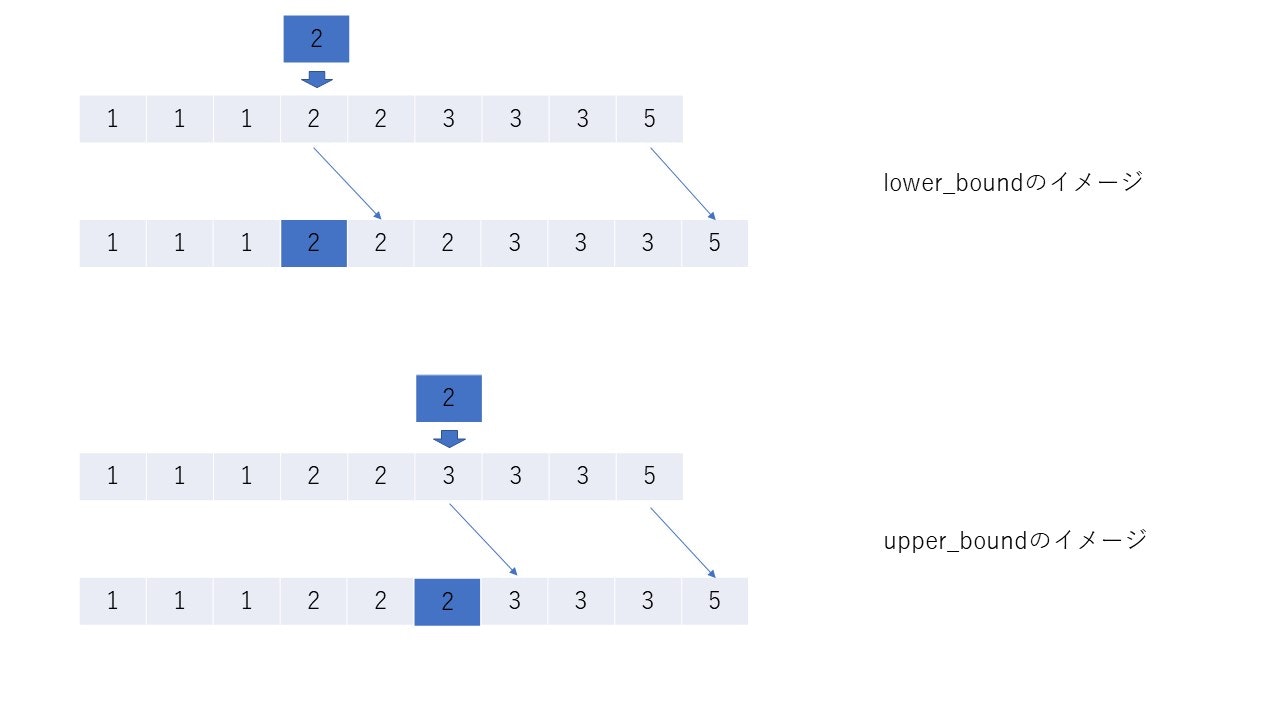
key = 3のとき
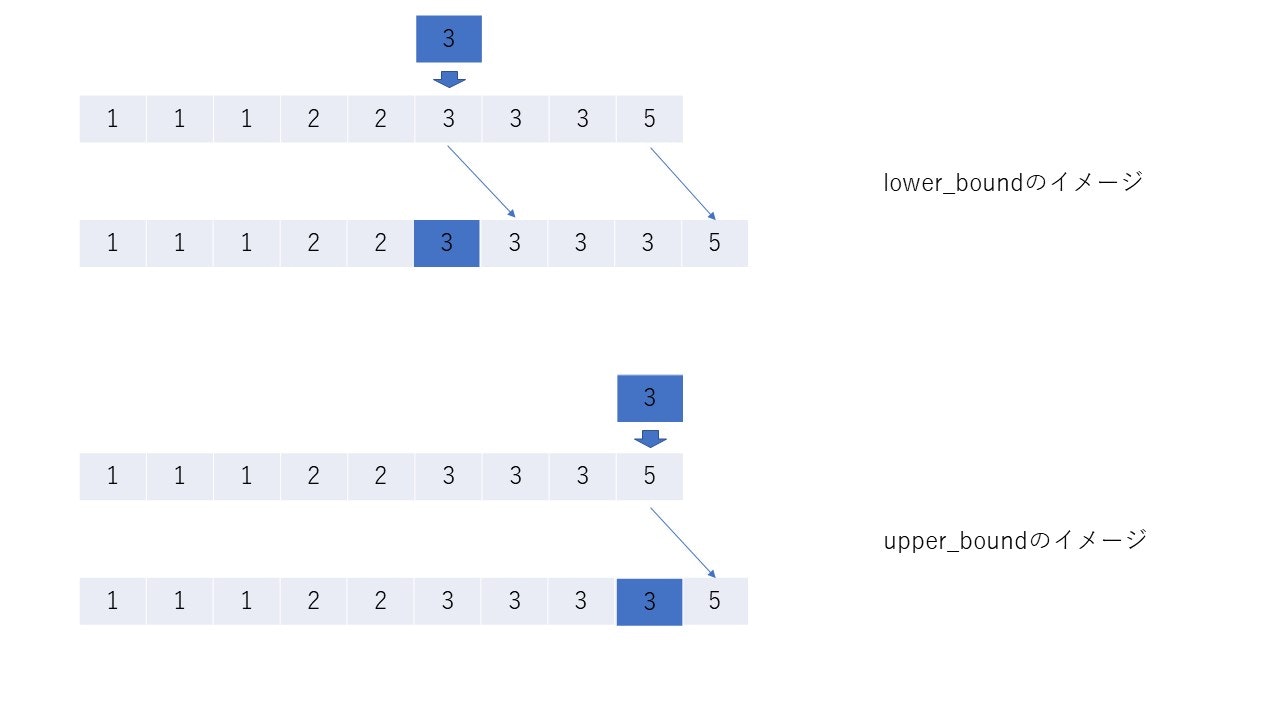
key = 4のとき
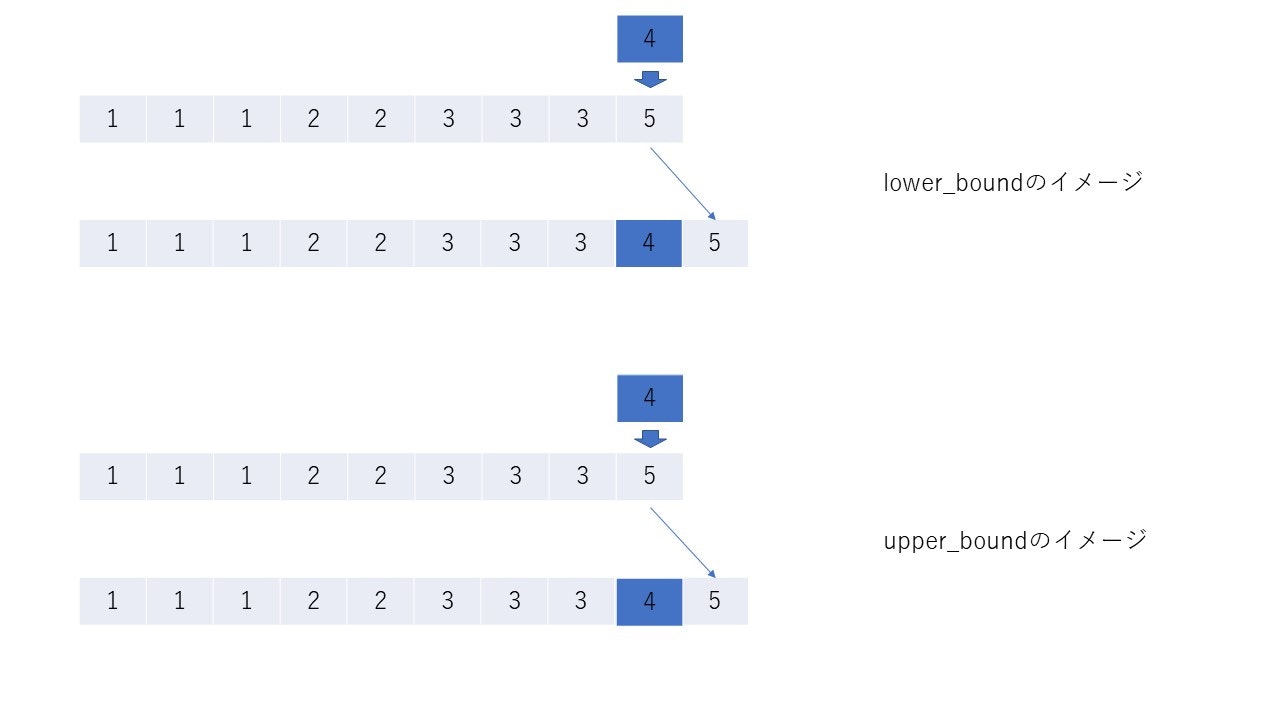
key = 5のとき
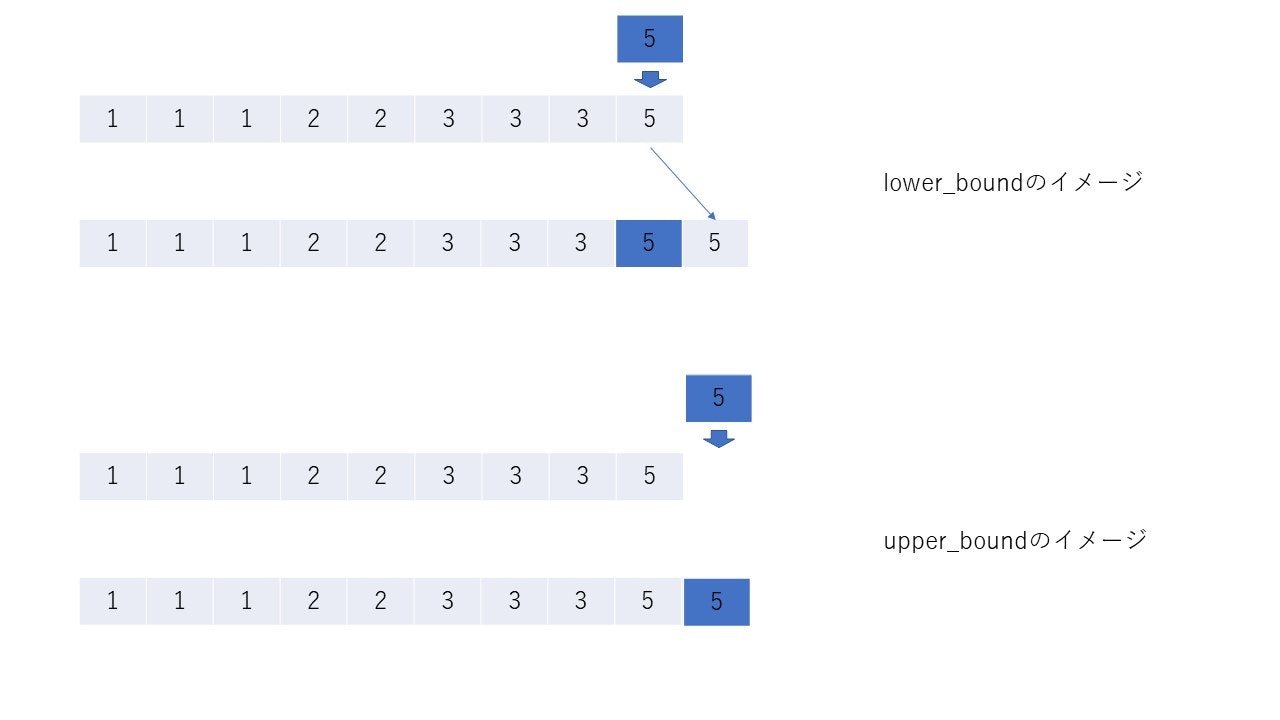
key = 6のとき

gif
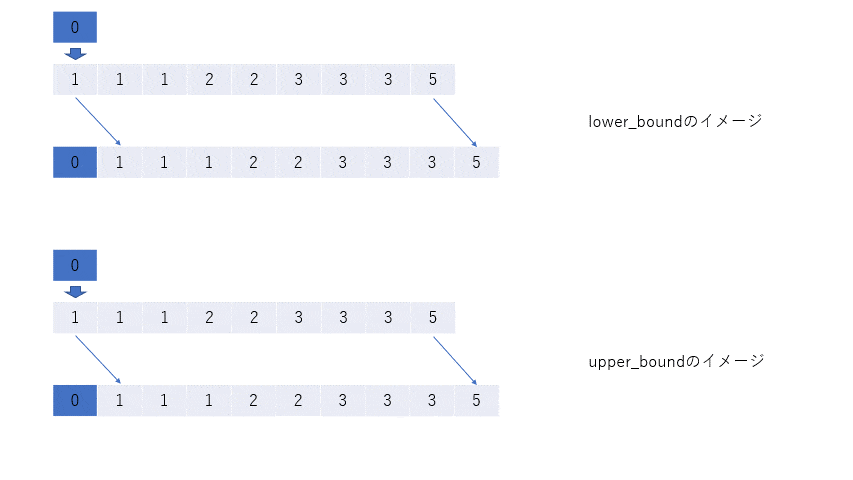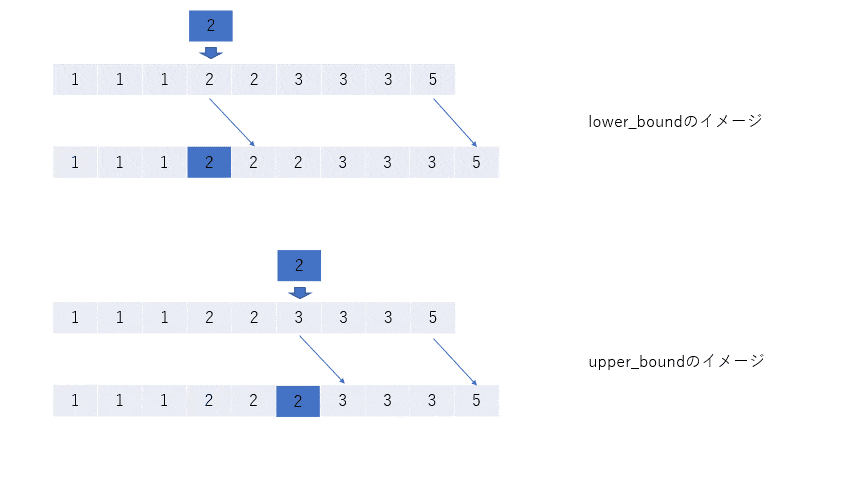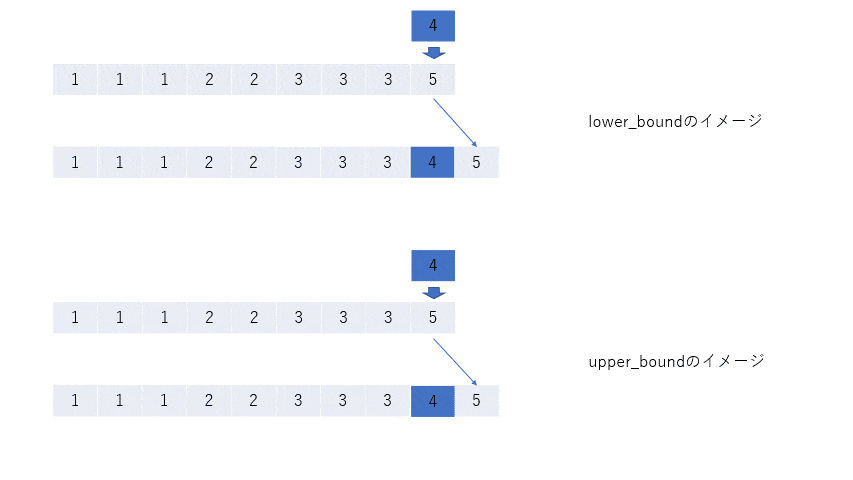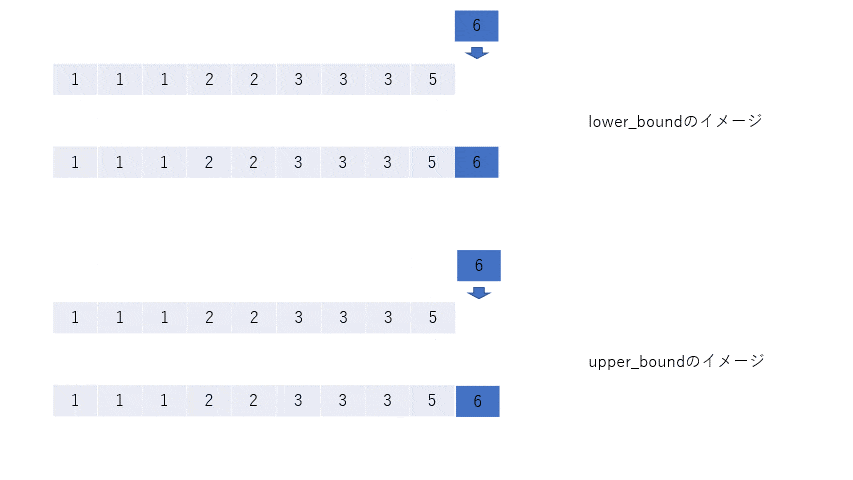
言い方を簡潔にすれば、sort済みの配列の順序を崩さないようにkeyを入れるとき、最左(または最右)でどこに入れられるかを返すということである。
この覚え方の利点は、「以上」「より大きい」といった言葉に頼らずにすむのでv.end()がいつかえってくるか?など直感的にわかり、しかもlowerやupperという名前も理解に結びつく。更に、降順の配列にもlower_boundやupper_boundを使うことができるようになる。
降順の配列に対する使い方
vector<int> v = {5, 3, 3, 3, 2, 2, 1};
に対して使ってみる。例えば2をkeyとして二分探索するには、
lower_bound(v.begin(), v.end(), 2, greater<int>());
upper_bound(v.begin(), v.end(), 2, greater<int>());
とかけばよい。第四引数は、「配列がどのようにsortされているか?」をlower_bound, upper_boundに伝える役目を果たしている(ここでは、greater、つまり>なので降順)。デフォルトでは昇順であることを想定している。前章を踏まえれば、降順の配列の順序を崩さないようにkeyを入れるとき、最左(または最右)でどこに入れられるかを返すのがわかる。とすれば、key=2のときはlower_boundはv[4]のイテレータを返し、upper_boundはv[6]のイテレータを返す、ということが容易にわかる。