Section1 再帰型ニューラルネットワークの概念
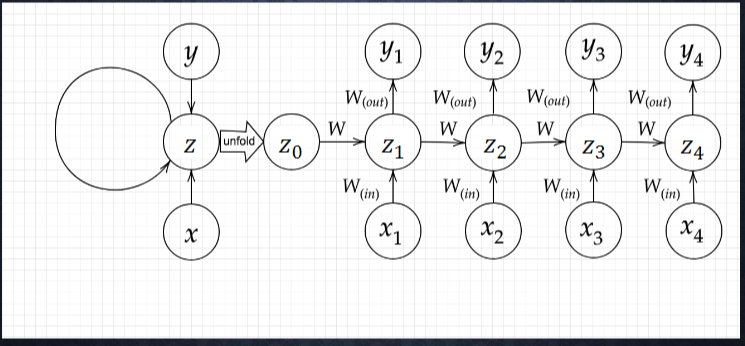
RNN の全体像
RNN とは
時系列データに対応可能なニューラルネットワーク
時系列データ
時間的順序を追って一定間隔ごとに観察され,しかも相互に統計的依存関係が認められるようなデータの系列
- 音声データ
- テキストデータ
- 株価データ
RNN について
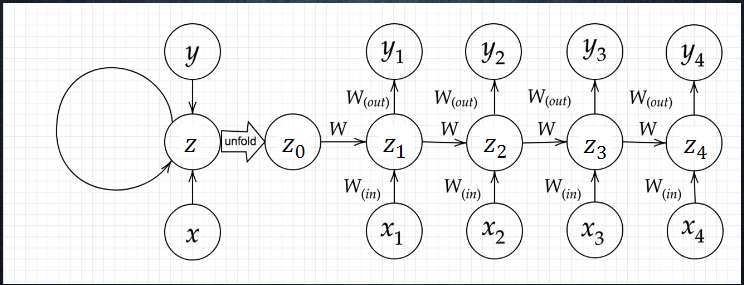
順伝播において、前の中間層の計算結果を重みとバイアスで処理をした上で、中間層への入力の一部とする。
時系列モデルを扱うには、初期の状態と過去の時間 t-1 の状態を保持し、そこから次の時間での t を再帰的に求める再帰構造が必要になる。
BPTT
BPTT とは
Backpropagation Through Time
誤差逆伝播法の一種
RNN におけるパラメータ調整方法
誤差逆伝播法を時系列の流れを含めて実施する形
長期間の利用には計算量が大きくなり不向きである
BPTT の数学的記法
$\frac{\partial E}{\partial W_{(in)}} = \frac{\partial E}{\partial u^t} \big[ \frac{\partial u^t}{\partial W_{(in)}} \big]^T = \delta ^t[x^t]^T$
np.dot(X.T, delta[:,t].reshape(1,-1))
$ \frac{\partial E }{\partial W*{in}} = \frac{ \partial E}{ \partial v^t} \big[ \frac{ \partial u^t}{ \partial W*{(out)}}\big] ^t = \delta ^{out,t} [ z^t] ^T$
np.dot(z[:,t+1].reshape(-1,1), delta_out[:,t].reshape(-1,1))
$\frac{ \partial E }{\partial W} = \frac{\partial E}{\partial u^t} \big[ \frac {\partial u^t}{\partial W} \big] ^t = \delta ^t [z^{t-1}]^T$
np.dot(z[:,t].reshape(-1,1), delta[:,t].reshape(1,-1))
$ \frac{ \partial E}{ \partial u^t} = \frac{\partial E}{ \partial v^t} \frac{\partial v^t}{\partial i^t} = f'(u^t)W_{out}^T \delta^{out,t} = \delta ^t$
delta[:,t] = (np.dot(delta[:,t+1].T, W.T) + np.dot(delta_out[:,t].T, W_out.T)) * functions.d_sigmoid(u[:,t+1])
パラメータの更新
$ W*{(in)}^{t+1} = W*{(in)}^t - \epsilon \frac {\partial E}{ \partial W*{(in)}} = W*{(in)}^t - \epsilon \sum_{z=0}^{T_t} \delta ^{t-z} \big[ x^{t-z} \big] ^T$
W_in -= learning_rate * W_in_grad
$ W*{(out)}^{t+1} = W*{(out)}^t - \epsilon \frac {\partial E}{ \partial W*{(out)}} = W*{(out)}^t - \epsilon \delta ^{out,t} \big[ z^t \big] ^T$
W_out -= learning_rate * W_out_grad
$ W^{t+1} = W^t - \frac{\partial E}{ \partial W} = W*{(in)}^t - \epsilon \sum*{z=0}^{T_t} \delta ^{t-z} \big[ x^{t-z-1} \big] $
W -= learning_rate * W_grad
BPTT の全体像
E^t = loss(y^t,d^t) \\
= loss(g(w_{(out)}z^t + c),d^t) \\
= loss(g(W_{(out)}f(W_{(in)}x^t + Wz^{t-1} + b)+c),d^t)
Section2 LSTM
RNN の課題
時系列を遡れば遡るほど、勾配が消失していく → 長い時系列の学習が困難
解決策
構造を変えることでその問題を解決したものを LSTM と呼ぶ
LSTM の全体像

CEC
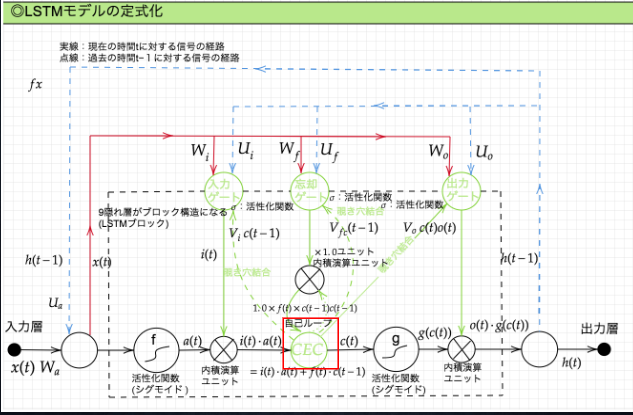
勾配消失および勾配爆発の解決方法として、勾配が 1 であれば解決できる
課題
入力データについて、時間依存度に関係なく重みが一律である
→ ニューラルネットワークの学習特性がそもそも失われてしまう
解決策
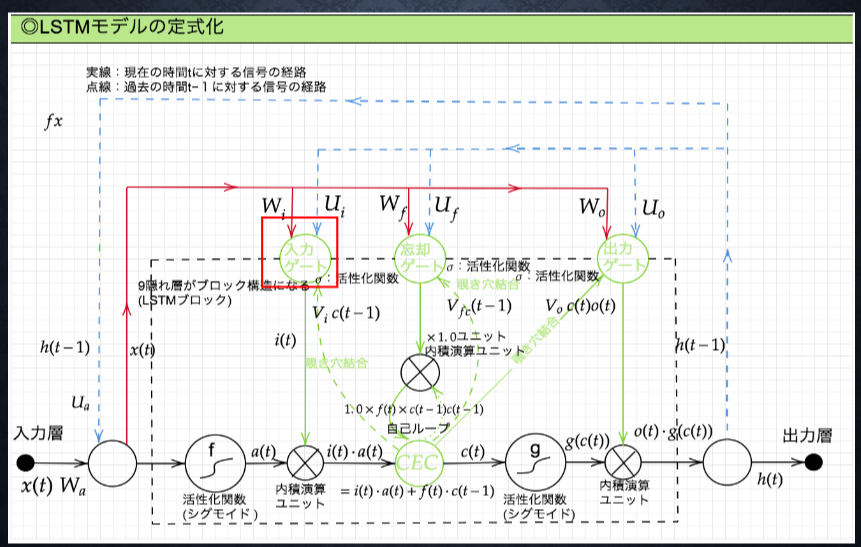
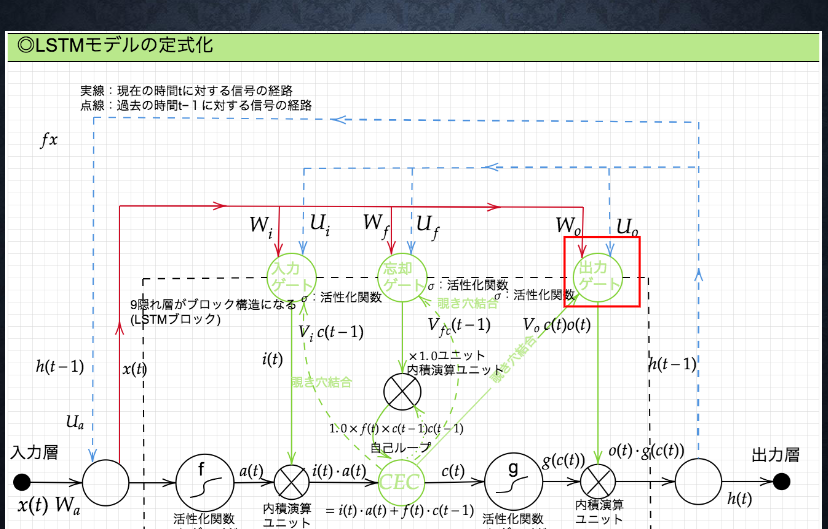
入力ゲートと出力ゲート
入力ゲートと出力ゲート
入力ゲートと出力ゲートを追加することで
それぞれのゲートへの入力値の重みを重み行列 W,U で可変可能とする
→CEC の問題を解決
入力ゲート
出力ゲート
現状
すべての過去の情報をすべての情報が保管される
課題
過去の情報がいらなくなった場合削除できない
常に過去の情報に引っ張られている
解決策
忘却ゲート
忘却ゲート
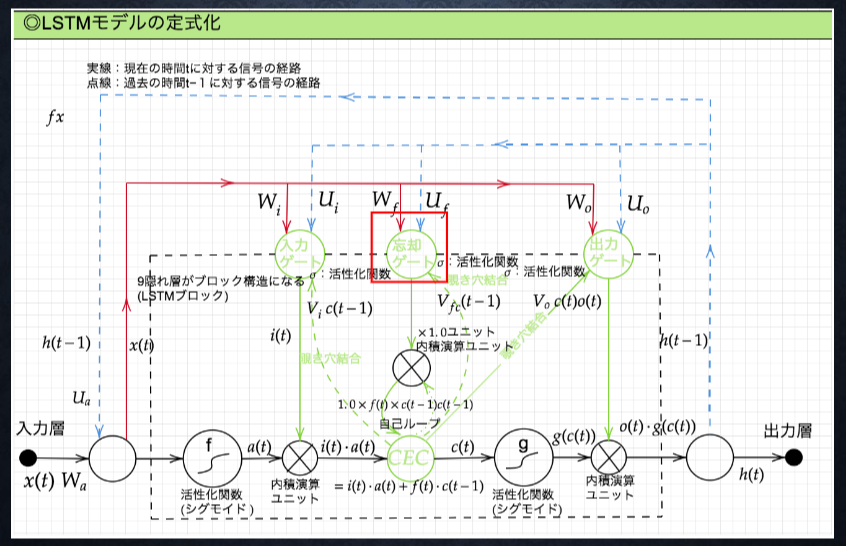
不要になった CEC の情報を削除するためのゲート
課題
CEC の保存されている過去の情報を、任意のタイミングで他のノードに伝播させたり、あるいは任意のタイミングで忘却させたい。CEC 自身の値は、ゲート制御に影響を与えていない。
解決策
のぞき穴結合
除き穴結合
CEC 自身の値に、重み行列を介して伝播可能にした構造。
GRU
LSTM では、パラメータが多く計算負荷が高くなる問題があった
→GRU
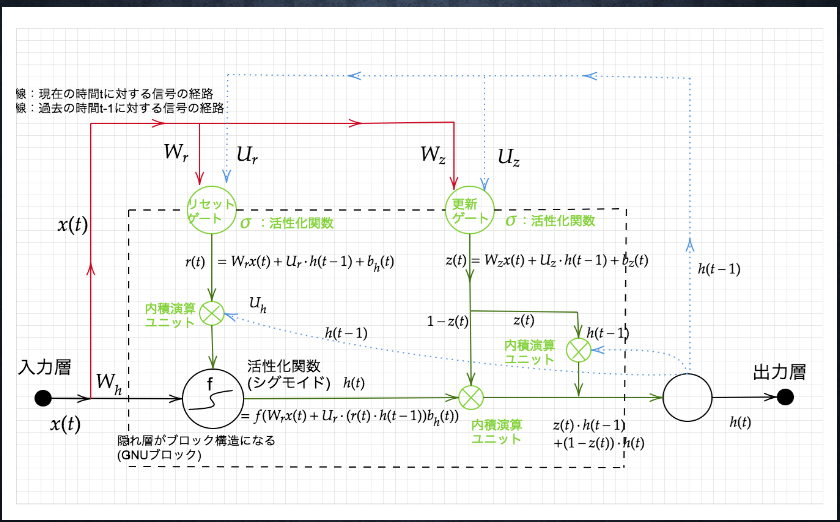
GRU ではそのパラメータが削減されていることが画像からわかる
Section4 双方向 RNN
時系列データにおいて、過去の情報だけでなく、未来の情報も使用する

Section5 Seq2Seq
Encoder-Decoder モデルの一種
機械翻訳や対話のためのモデルとして利用される。
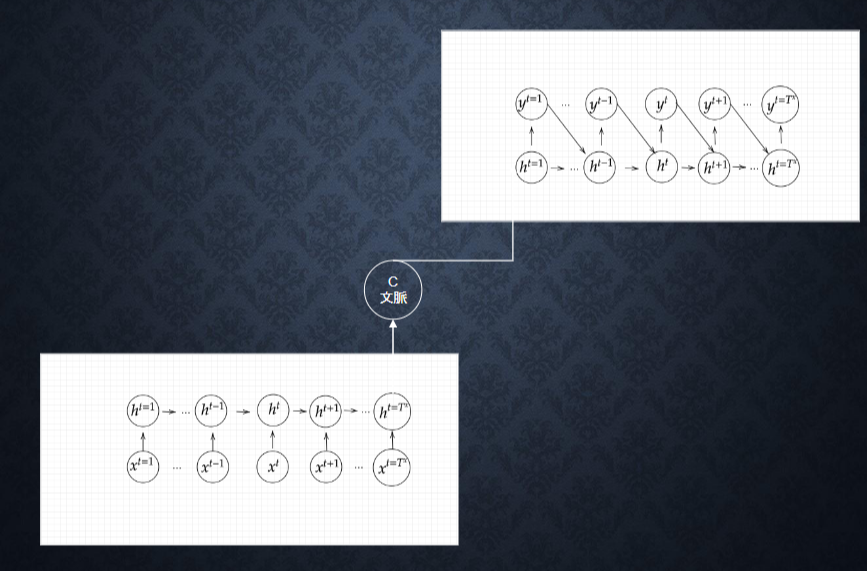
Encoder RNN
ユーザーがインプットしたテキストデータを、単語等のトークンに区切って渡す構造。
Taking:形態素解析などで文章を単語などのトークンに分解し、トークンごとの ID に変換する
Embedding:ID をもとに、分散表現ベクトルに変換
Encoder RNN:ベクトルを順番に RNN に入力しておく
vec1 を RNN に入力し、hidden state を出力。これと次の入力 vec2 をまた RNN に入力...という風に繰り返す
最後の vec を入れた時の hidden state を final state としてとっておく。これが入力した分の意味を表すベクトルとなる

Decoder RNN
システムがアウトプットデータを、単語等のトークンごとに生成する構造。
1.Decoder RNN: Encoder RNN の final state (thought vector) から、各 token の生成確率を出力 final state を Decoder RNN の initial state ととして設定し、Embedding を入力
2.Sampling: 生成確率にもとづいて token をランダムに選択
3.Embedding: token を Embedding して Decoder RNN への次の入力とする
4.Detokenize: 1-3 を繰り返し、2 で得られた token を文字列に直す。
HRED
seq2seq は一問一答しかできない
→ 問に対して文脈も何もなく、ただ応答が行われる続ける
解決策として →HRED
HRED とは
過去の n−1 個の発話から次の発話を生成
より人間らしい応答
Seq2Seq + Context RNN(Context RNN: これまでの会話コンテキストをベクトルに変換する構造。)
HERD の課題
会話の流れの多様性がない
短いよくある答えを学ぶ傾向がある
VHRED
HREAD に、VAE の潜在変数の概念を追加して HREAD の課題の解決を解決したもの
VAE
オートエンコーダー
教師なし学習の一つ。
教師データは利用しない。
入力データから潜在変数 z に変換するネットワーク が Encoder
潜在変数 z をインプットとして元画像を復元するニューラルネットワークが Decoder
メリット
次元削減を行うことができる。
VAE
通常のオートエンコーダーの場合は潜在変数 z にデータを押し込めているものの、その構造がどのような状態かわからない。
VAE の場合は潜在変数 z に確率分布 z∼N(0,1)を仮定したもの
データを潜在変数 z の確率分布という構造に押し込めることを可能にする
Section6 Word2Vec
RNN の課題
単語のような可変長の文字列を NN に与えることはできない
→ 固定長でしか学習できない
解決策
Word2Vec
Word2vec
可変長の文字列を固定長の形式に変換するためもの。
学習データからボキャブラリを作成
ボキャブラリを次元として、入力データを one-hot-vector を作成する → 分散表現
メリット
大規模データの分散表現の学習が、現実的な計算速度とメモリ量で実現可能にした。
今までは、「ボキャブラリ × ボキャブラリ」だけの重み行列が誕生
Word2vec は「ボキャブラリ × 任意の単語ベクトル次元」で重み行列が誕生。
Section7 AttentionMechanism
seq2seq の課題
長い文章への対応が難しい。
文章が長くなるほど、入力の内部表現の次元も大きくなっていく。
解決策
「入力と出力のどの単語が関連しているのか」を学習する
→Attention Mechanism
確認テスト
サイズ 5×5 の入力画像を、サイズ 3×3 のフィルタで 畳み込んだ時の出力画像のサイズを答えよ。 なおストライドは 2、パディングは 1 とする。
解答
3×3
RNN のネットワークには大きくわけて 3 つの重みがある。1 つは入力から現在の中間層を定義する際にかけられる重み、1 つは中間層から出力を定義する際にかけられる重みである。 残り 1 つの重みについて説明せよ。
解答
中間層から次の中間層に対する重み
連鎖律の原理を使い、dz/dx を求めよ。
$ z=t^2$
$t=x+y$
解答
$ dz/dt = 2t$
$\frac{dt}{dx} = \frac{dz}{dt} \frac{dt}{dx} = 2t *1 = 2(x+y)$
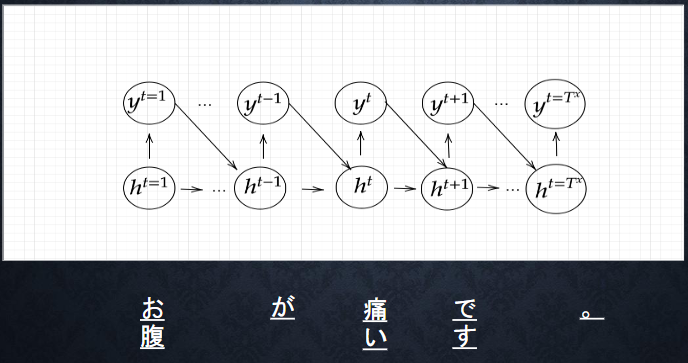
下図を y1 を数式で表せ
$x・s_0:s_1・w_{in}・w・w_{out}$を用いる
※バイアスは任意の文字で定義せよ
※中間層の出力にシグモイド関数 g(x)を作用させよ。
解答
$ z1 = sigmoid(S_0 w + x_1 w{(in)} + b)$
$ y1= sigmoid(z_1 W{(out)} + c)$
シグモイド関数を微分した時、入力値が 0 の時に最大値 をとる。その値として正しいものを選択肢から選べ。
(1)0.15 (2)0.25 (3)0.35 (4)0.45
解答
(2)
以下の文章を LSTM に入力し空欄に当てはまる単語を予測したいとする。 文中の「とても」という言葉は空欄の予測において なくなっても影響を及ぼさないと考えられる。 このような場合、どのゲートが作用すると考えられるか。
「映画おもしろかったね。ところで、とてもお腹が空いたから何か__。」
解答
忘却ゲート
LSTM と CEC が抱える課題について、それぞれ簡潔に述べよ。
解答
LSTM
パラメータ数が多く、計算負荷がかかる。
CEC
勾配が 1 で渡され続け重みがなくなる
学習という概念が損なわれる
LSTM と GRU の違いを簡潔に述べよ。
解答
GRU よりも、LSTM のほうパラメータ数が多い
下記の選択肢から、seq2seq について説明しているものを選べ。
(1)時刻に関して順方向と逆方向の RNN を構成し、それら 2 つの中間層表現を特徴量として利用 するものである。
(2)RNN を用いた Encoder-Decoder モデルの一種であり、機械翻訳などのモデルに使われる。
(3)構文木などの木構造に対して、隣接単語から表現ベクトル(フレーズ)を作るという演算を再 帰的に行い(重みは共通)、文全体の表現ベクトルを得るニューラルネットワークである。
(4)RNN の一種であり、単純な RNN において問題となる勾配消失問題を CEC とゲートの概念を 導入することで解決したものである。
解答
(2)
(1)双方向 RNN
(2)seq2seq
(3)RNN
(4)LSTM
seq2seq と HRED、HRED と VHRED の違いを簡潔に述べよ。
解答
ses2seq
一問一答しかできない
HRED
文脈に即して回答ができる
VHRED
文脈に即して回答ができて、多様がある回答ができる
VAE に関する下記の説明文中の空欄に当てはまる言葉を答えよ。
自己符号化器の潜 在変数に____を導入したもの。
解答
確率分布
RNN と word2vec、seq2seq と Attention の違いを簡潔に述べよ。
解答
RNN と word2vec
RNN と比較して word2vec は現実的なリソース量で計算できるようになった
seq2se1 と seq2se1+Attention
seq2se1 は固定長のものしか学習できなかったものに対し
seq2se1+Attention は長い文章の翻訳が成り立つ
演習結果
考察
simple_RNN 中間層のノード数を 64 あたりが精度がよくなる。
学習率を大きくすると勾配爆発が起きる
シグモイド関数を ReLU 関数に変更すると、勾配爆発が発生し、全く学習が進まない
tanh に変更すると学習が進まない
隠れ層を多くすると精度は向上するが、学習の初期は誤差が大きい、
重みを大きくすると学習の初期は誤差が少ないが、そこから勾配爆発してしまう
既存の問題がありそれを解決するために新しいモデルが作られていき学習の精度が高まっていっている