1. はじめに
stable diffusionにおいて、語順によって生成される画像に違いが生じることが指摘されています。生成画像の質や内容に影響を与える可能性があるため、語順が生成画像にどのような影響を与えるのか理解することが重要です。
DAAM(Diffusion Attentive Attribution Maps)などもありますが、今回はあえて色に着目して影響度を確認していきます。色は、他の呪文に使用される単語(beautiful、perfect faceなど)とは異なり、定量的(RGB値など)に判断することが可能です。(ある程度)
そこで、今回はプロンプトにおける語順が与える影響を、色のキーワード”red”という単語をベースとして確認していきます。
この実験を通じて、プロンプトにおける位置と、画像における色の含有率の変化を捉えることで、影響を確認します。
なんとなく気になったので調べてみた程度です。コードは感覚的には80%くらいをGPT4に生成してもらっています。少しのアイディアを簡単に試せるのがすごく良いです。感動しています。🚀
個人的には、下記画像のように、語順による影響がしっかり確認できたら良かったのですが、思ったより明確に判定することができませんでした。有意な結果は出ていませんが、アイディアとして供養しています。

2. 基本設定
語順が生成される画像に与える影響を調査するために、以下の手順で実験を行いました。
2.1 環境
Core ML Stable Diffusion 1を使ってStable diffusion v2.1を使用しています。
Hugging Faceでappleが提供しているmodel 2を使用しています。
2.2 実験データ
以下のプロンプトをベースに画像生成を行います。
the Babel tower, digital Illustration, detailed, fantasy
コアプロンプトとしてバベルの塔を設定し、スタイル(digital Illustration)、品質(detailed)、キーワード(fantasy)としています。
今回は、1つのプロンプトに対し、200枚生成しています。(シード値を使用しています。)
生成コード
from diffusers import StableDiffusionPipeline
import torch
pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1-base")
pipe = pipe.to("mps")
pipe.enable_attention_slicing()
prompt = "the Babel tower, digital Illustration, detailed, fantasy"
_ = pipe(prompt, num_inference_steps=1)
for i in range(200):
generator = torch.Generator(device="cpu").manual_seed(i)
image = pipe(prompt, generator=generator).images[0]
image.save(f"out/{i:03}.png")
以下に出力例を並べます。

作風を絞っていないので、振れ幅が結構あります。そのため、RGBのカラー分布は以下のようになり、画像ごとにかなりバラバラです。
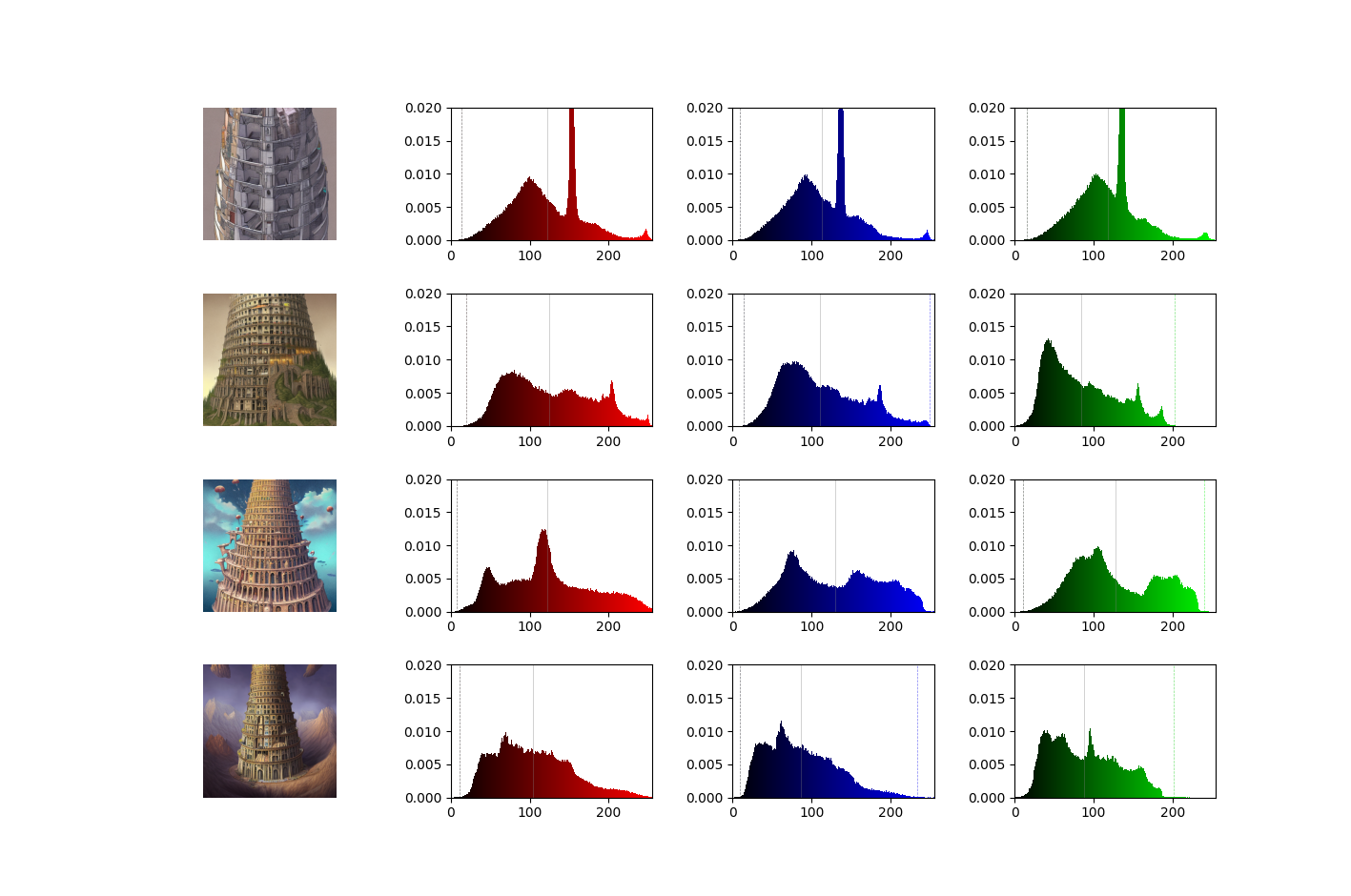
2.3 色の評価
赤色を抽出する方法はいくつか考えられます。上記のように、RGBを使用しての含有率も考えられますが、他の色との混合割合によるため切り分けが難しいです。
今回はHSV空間における切り分けを行います。以下のフィルターを使用することとします。
- 赤色フィルター: 0° ≤ H ≤ 10°, 100 ≤ S ≤ 255, 100 ≤ V ≤ 255
- 緑色フィルター: 35° ≤ H ≤ 90°, 40 ≤ S ≤ 255, 40 ≤ V ≤ 255
- 青色フィルター: 90° ≤ H ≤ 130°, 100 ≤ S ≤ 255, 100 ≤ V ≤ 255
フィルターを使用し、抽出した場合は以下のようになります。画像に対する赤、緑、青の抽出した部分をプロットしています。タイトルに、画像に占める色の割合(以降、含有率と表記)が示されています。
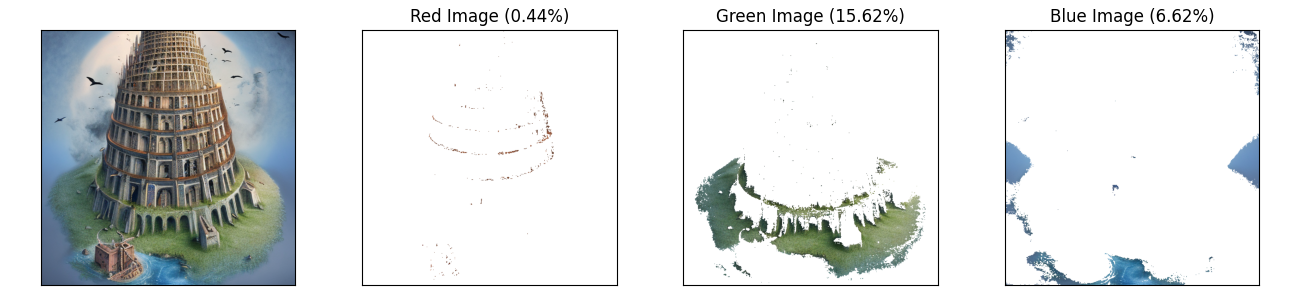
結構恣意的はありますが、今回はこのフィルター設定で計算を行います。
抽出用コード
import cv2
import numpy as np
import matplotlib.pyplot as plt
def extract_color(image_path, lower_bound, upper_bound, cmap=None):
image = cv2.imread(image_path)
hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv_image, lower_bound, upper_bound)
colored_image = cv2.bitwise_and(image, image, mask=mask)
colored_image[mask == 0] = (255, 255, 255)
if cmap is not None:
colored_image = cv2.applyColorMap(colored_image, cmap)
return colored_image, mask
def calculate_pixel_ratio(mask):
colored_pixel_count = np.sum(mask > 0)
total_pixel_count = mask.shape[0] * mask.shape[1]
pixel_ratio = colored_pixel_count / total_pixel_count * 100
return pixel_ratio
def plot_images(image_paths, output_path, ylabels, plot=False):
num_images = len(image_paths)
fig, axes = plt.subplots(num_images, 4, figsize=(13, 3 * num_images))
axes = np.atleast_2d(axes)
for i, image_path in enumerate(image_paths):
# Read and convert the image to RGB
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Define color ranges
red_lower = np.array([0, 100, 100])
red_upper = np.array([10, 255, 255])
green_lower = np.array([35, 40, 40])
green_upper = np.array([90, 255, 255])
blue_lower = np.array([90, 100, 100])
blue_upper = np.array([130, 255, 255])
# Extract colors
red_image, red_mask = extract_color(image_path, red_lower, red_upper)
green_image, green_mask = extract_color(image_path, green_lower,
green_upper)
blue_image, blue_mask = extract_color(image_path, blue_lower,
blue_upper)
# Calculate pixel ratios
red_ratio = calculate_pixel_ratio(red_mask)
green_ratio = calculate_pixel_ratio(green_mask)
blue_ratio = calculate_pixel_ratio(blue_mask)
# Plot images
axes[i][0].imshow(image_rgb)
axes[i][0].set_ylabel(ylabels[i])
axes[i][1].imshow(cv2.cvtColor(red_image, cv2.COLOR_BGR2RGB))
axes[i][1].set_title(f'Red Image ({red_ratio:.2f}%)')
axes[i][2].imshow(cv2.cvtColor(green_image, cv2.COLOR_BGR2RGB))
axes[i][2].set_title(f'Green Image ({green_ratio:.2f}%)')
axes[i][3].imshow(cv2.cvtColor(blue_image, cv2.COLOR_BGR2RGB))
axes[i][3].set_title(f'Blue Image ({blue_ratio:.2f}%)')
for ax in axes.ravel():
ax.set_xticks([])
ax.set_yticks([])
plt.tight_layout()
plt.savefig(output_path)
if plot:
plt.show()
if __name__ == '__main__':
plot_images(['in.png'], 'out.png', [''])
2.4 実験の目的
主に確認したいことは2つです。
- “red”というキーワードを加えることによる影響
- 語順による生成画像への影響
3. “red”というキーワードの与える影響
章題の通り、”red”というキーワードが画像に与える影響を確認します。今回は、安直に”赤色”が増加したかどうかを確認していきます。また、”red”の位置が、”赤色”の増減に寄与しているかを確認します。
3.1 実験概要
プロンプト内の位置、headとtailを以下のように設定します。
the Babel tower, (head), digital Illustration, detailed, fantasy, (tail)
”red”を配置するとプロンプトは以下のようになります。
- the Babel tower, red, digital Illustration, detailed, fantasy
- the Babel tower, digital Illustration, detailed, fantasy, red
2つのプロンプトにより生成された画像と、元のプロンプトの画像をビジュアル的・数値的に比較します。
本実験の目的は、キーワード“red”による影響の確認と、headとtailの差が存在しそうかどうかの確認になります。
3.2 結果
3.2.1 視覚的な確認
出力結果を元画像、head、tailで比較します。例として、出力結果を2つ見てみます。
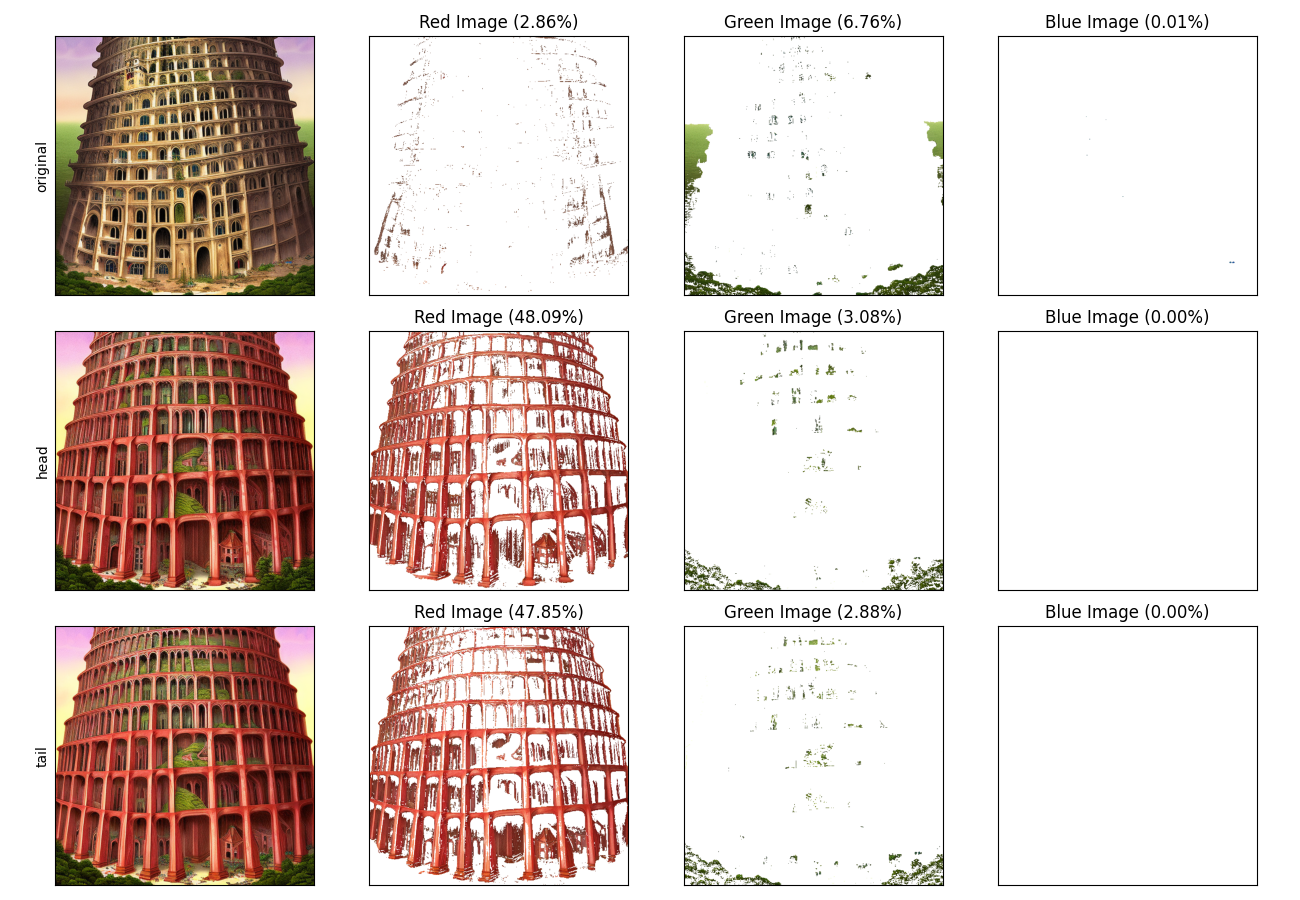
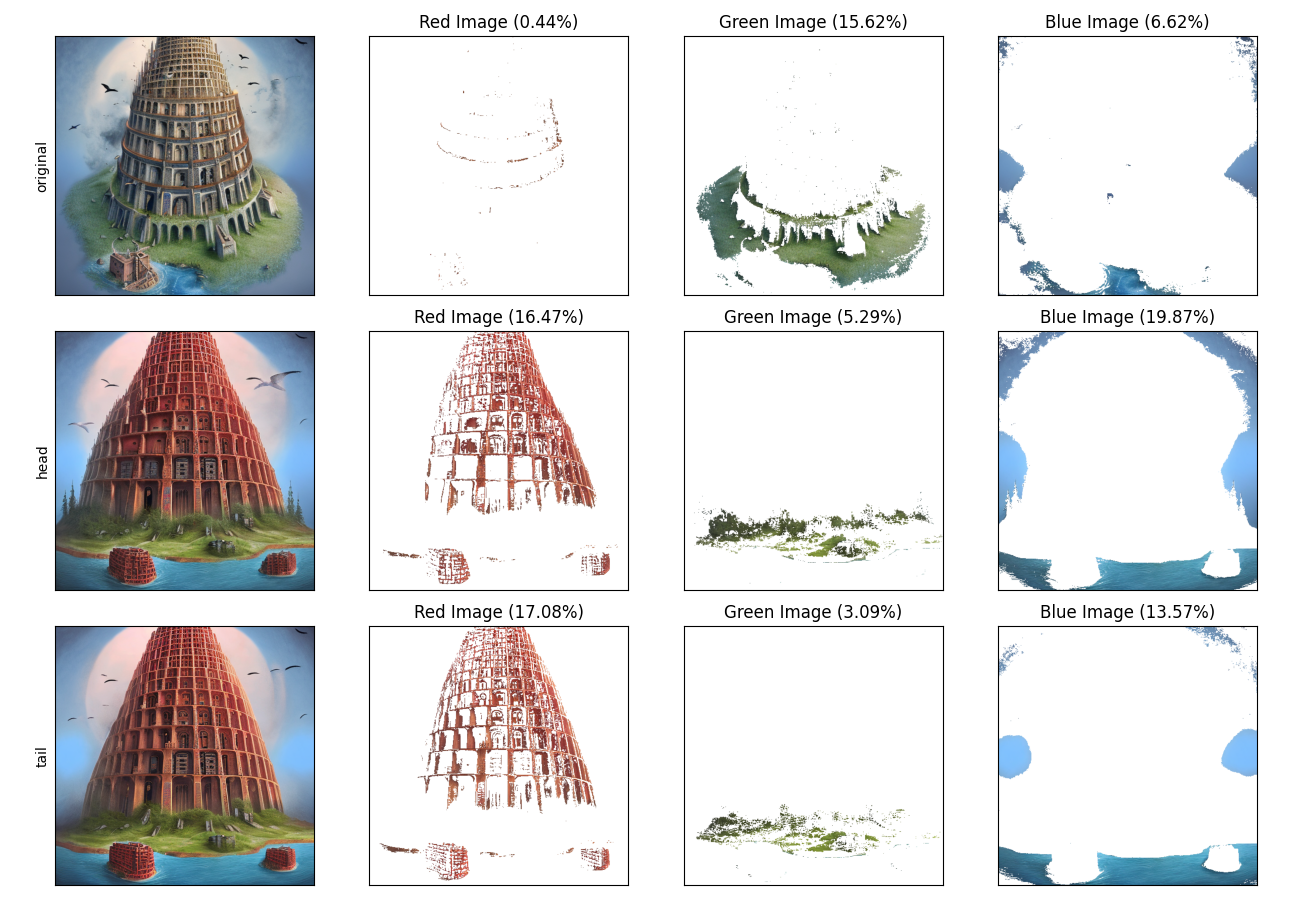
赤色の列を確認します。赤色の要素が増加していることを確認できます。
また、塔の形状への影響もあることが確認できます。
3.2.2 数値的な確認
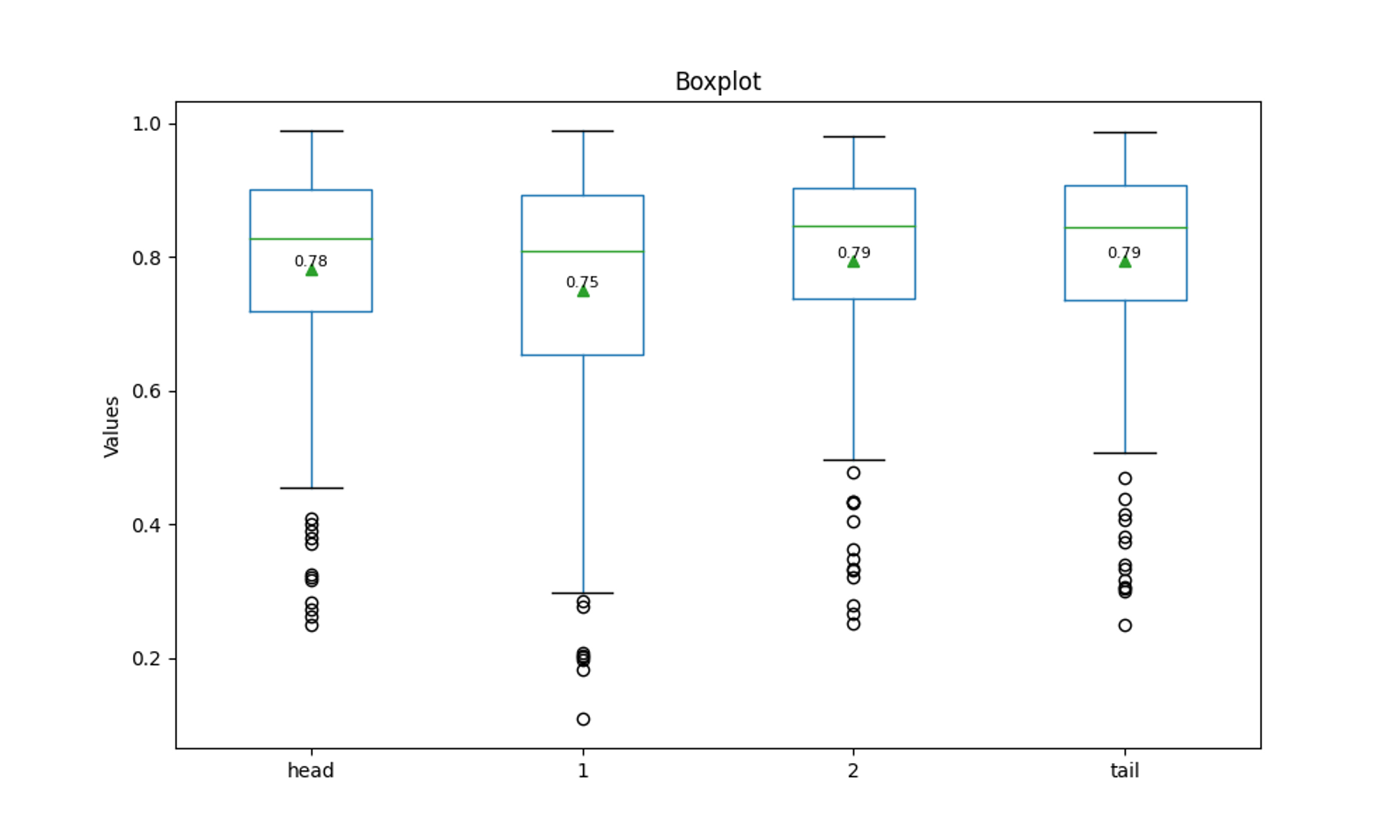
数値的に、反映を確認します。200枚の各画像における赤、緑、青の含有率を箱ひげ図で出力します。左から、元画像、head、tailです。平均値をテキストと三角形で出力してあります。
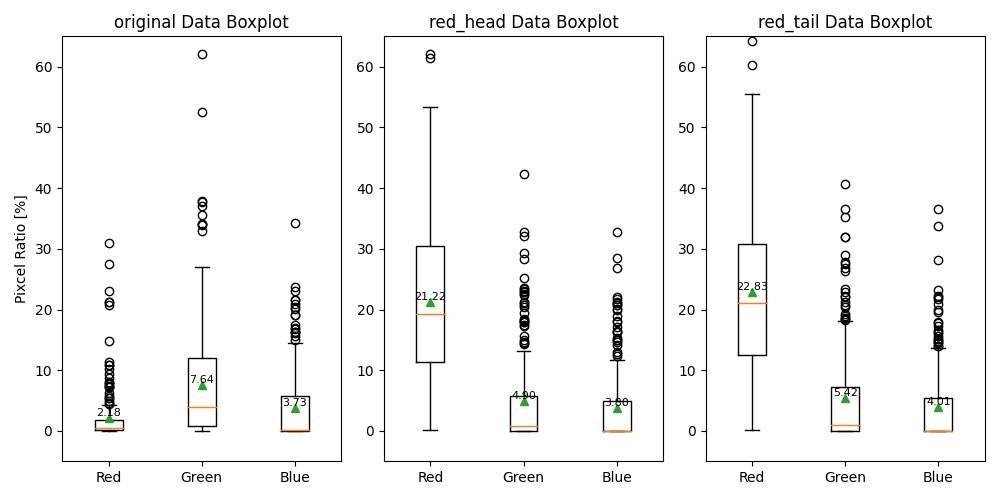
元画像では、赤色の含有率は2%程度でしたが、20%程度まで上昇していることが確認できます。
しっかりと”red”が反映できていることは確認できました。赤に着目すると、大体headとtailでは2%程度の差が確認できます。
これだと、画像の平均的な情報しか取れません。そこで、元画像に対しての増減を計算してみました。赤色だけ確認した結果を示します。
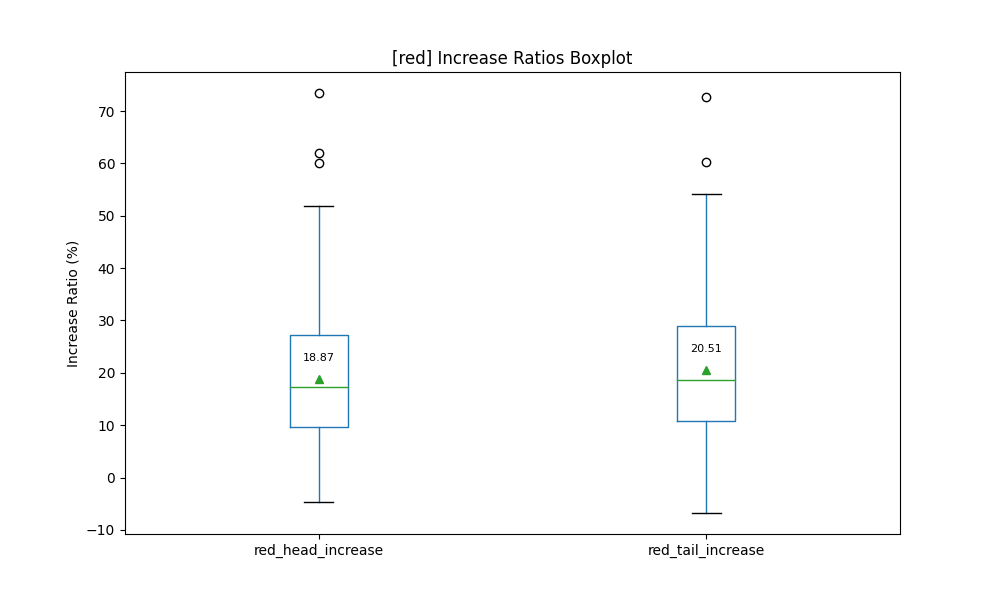
平均とほぼ同じ傾向でした。🙁
結局のところ”red”のキーワードで赤色の含有率が20%程度増加するという結果を確認できました。また、最大では50%程度増加しています。ただし、若干の減少も確認できます。
3.3 discussion
“red”というキーワードに対する赤色の含有率の増加が確認できました。それに伴い、いくつかの疑問・問題点を確認します。
3.3.1 tailとheadの差
headとtailの優位な差が確認できませんでした。 現状、tail側の方が少し強そうであることから、
”head側ではオブジェクトである塔に対して影響を与え、tail側では画像全体へ影響を与える。”
というパターンが考えられます。
しかし、この差だけでは”head側の方が影響度が大きく、tail側へ近づくほど影響度が小さくなる。”というパターンは捨てきれません。というか何もわかりません。そこで、headとtail以外にも位置を追加し、実験を行う必要があります。
3.3.2 減少に関して
赤色の含有率の減少が確認できました。これはフィルターの境界付近により生じていると考えられます。赤の範囲の検討は重要な課題です。

4. 語順の与える影響
3章より、”red”というキーワードが赤色の含有率を増加させることを確認しました。次に、色を挿入する位置を新しく追加し、段階的な結果により、考察しやすくして実験を行います。
4.1 実験概要
プロンプトの(head)と(tail)に加えて、2箇所を追加します。
the Babel tower, (head), digital Illustration, (1), detailed, (2), fantasy, (tail)
どこかの位置一箇所に“red”を追加して、画像を生成していきます。
本実験の目的は、段階的な結果による語順の与える影響の確認になります。
4.1.1 画像の類似度
今回の実験では出力結果への影響として、画像間の類似度を使用します。
2つの画像をグレースケールへ変換し、画像の色のヒストグラムをとります。2つのヒストグラムを比較することで類似度を計算します。
ヒストグラムを用いた画像の類似度計算
def calculate_image_similarity(image1_path, image2_path, method=cv2.HISTCMP_CORREL):
# 画像を読み込む
image1 = cv2.imread(image1_path, cv2.IMREAD_GRAYSCALE)
image2 = cv2.imread(image2_path, cv2.IMREAD_GRAYSCALE)
# ヒストグラムを計算する
hist1 = cv2.calcHist([image1], [0], None, [256], [0, 256])
hist2 = cv2.calcHist([image2], [0], None, [256], [0, 256])
# ヒストグラムを正規化する
cv2.normalize(hist1, hist1, alpha=0, beta=1, norm_type=cv2.NORM_MINMAX)
cv2.normalize(hist2, hist2, alpha=0, beta=1, norm_type=cv2.NORM_MINMAX)
# 類似度を計算する
similarity = cv2.compareHist(hist1, hist2, method)
return similarity
(画像をグレースケールへ変換した後に、特徴検出を行い、k近傍法によるマッチングを行いスコアの計算を方法も行いました。主観的ですが、パッとみた際にあまり指標として機能していなさそうな値に見えてしまいました。ただし、以下で述べている平均的な結果の傾向とほぼ同じでした。)
特徴検出をもちいた類似度計算
def calculate_image_similarity_akaze(image_path1, image_path2):
# 画像を読み込み、グレースケールに変換
image1 = cv2.imread(image_path1, cv2.IMREAD_GRAYSCALE)
image2 = cv2.imread(image_path2, cv2.IMREAD_GRAYSCALE)
# AKAZE特徴量抽出器を作成
akaze = cv2.AKAZE_create()
# 画像から特徴量を抽出
keypoints1, descriptors1 = akaze.detectAndCompute(image1, None)
keypoints2, descriptors2 = akaze.detectAndCompute(image2, None)
# マッチング器を作成
bf = cv2.BFMatcher(cv2.NORM_HAMMING)
# 特徴量をマッチング
matches = bf.knnMatch(descriptors1, descriptors2, k=2)
# 良いマッチングの数を数える
good_matches_count = 0
ratio = 0.7
for m, n in matches:
if m.distance < ratio * n.distance:
good_matches_count += 1
# 総特徴点数
total_keypoints = min(len(keypoints1), len(keypoints2))
# 類似度スコアを計算
similarity_score = good_matches_count / total_keypoints
return similarity_score
4.2 結果
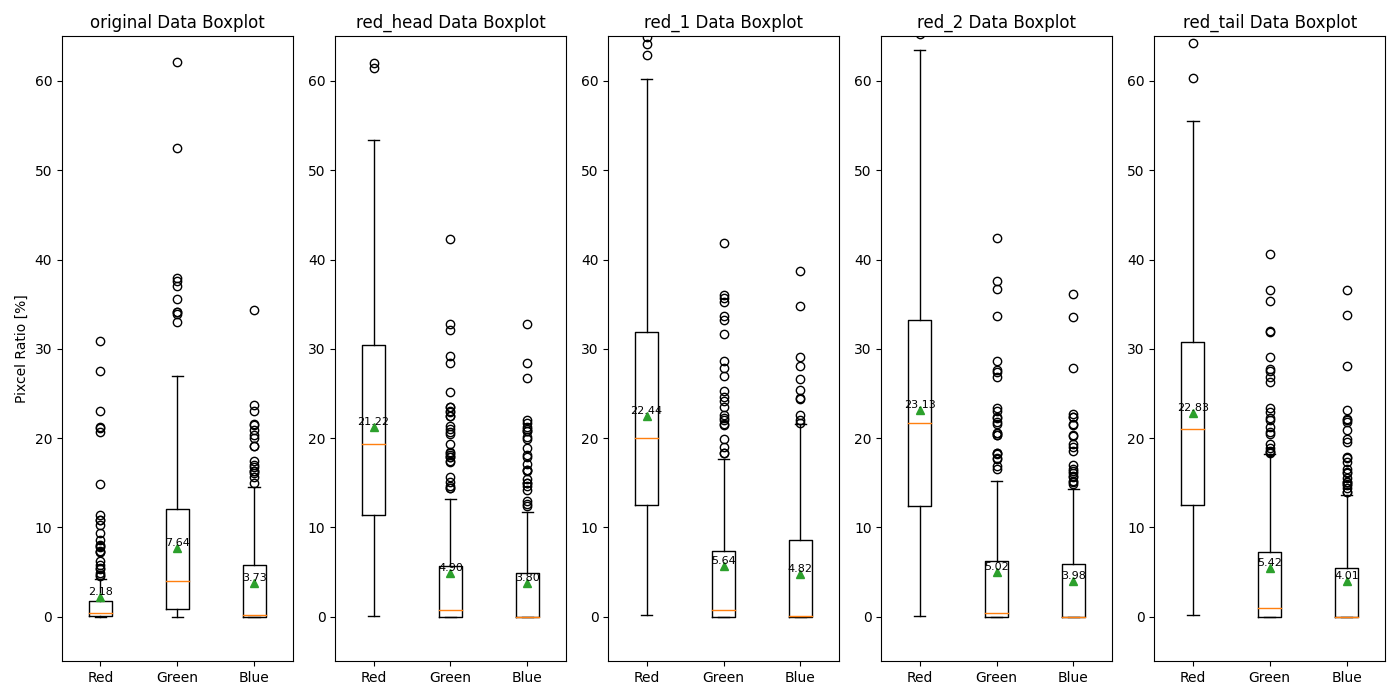
4.2.1 含有率
いきなりですが、数値を確認します。左から、元画像、(head)、(1)、(2)、(tail)です。
加えて、増減の出力結果も示します。
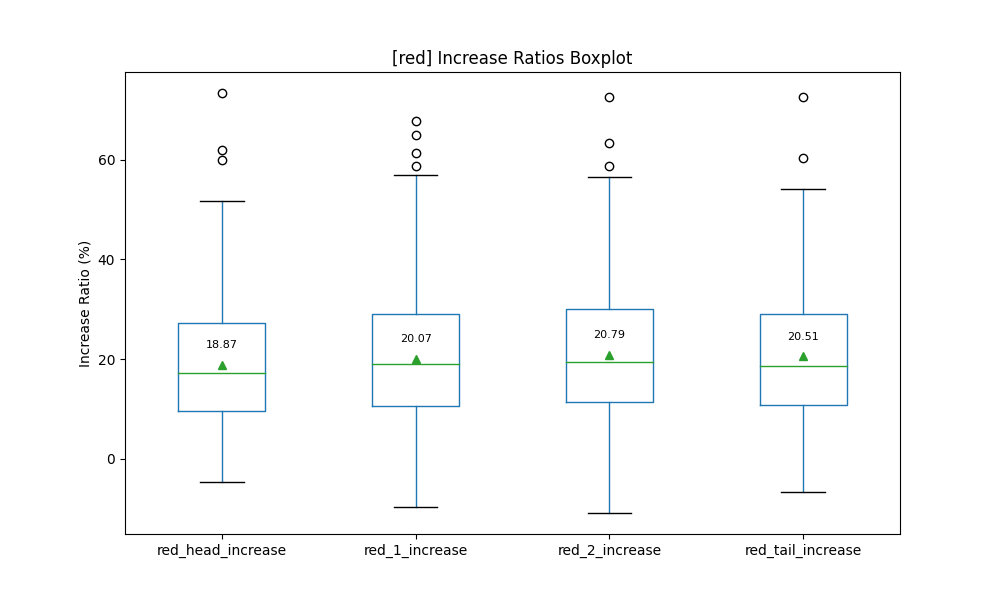
含有率また、含有率の増減の差はあまり確認することができていません。スタイルの”digital Illustration”以降、つまり(1)以降は、1~2%程度上昇していると捉えることもできます。
4.2.2 視覚的な確認
次に、出力の一例を示します。一番左がオリジナル画像で、一番右がtailになります。タイトルにオリジナルとの類似度を載せています。
出力の一例です。基本的には元画像に近い形で出力されるパターンがほとんどでした。


また、元画像とは異なりながらも、”red”を加えた4枚がほぼ同じ形状になるパターンも多かったです。


”red”の位置によって画像の雰囲気が変化していくパターンも多く確認できました。


少ないですが、かなり表現が揺れている画像が確認できました。


“red”というキーワードがオブジェクトに対して作用していることを確認できました。色的なアクセントを加えるだけのパターンが多かったですが、形状自体への関与も確認できました。
加えて、位置によって何かしらの影響を与えていることは確認できました。しかしながら、どのように作用しているかは明確に確認することはできません。
4.2.3 類似度
類似度の平均値を確認してみます。
類似度は若干ですが、位置(1)で減少していることが確認できます。
4.3 discussion
4.3.1 含有率と類似度から考える閾値
含有率では位置(1)以降に若干ですが、値が上昇しています。また、類似度では位置(1)にて減少していることが確認できます。可能性としては”red”というキーワードの影響を反映する閾値的な部分が存在するのかもしれません。使用しているキーワードである”digital Illustration”と”detailed”を入れ替えることで傾向をより掴めるかもしれません。
the Babel tower, (head), digital Illustration, (1), detailed, (2), fantasy, (tail)
4.3.2 コントロールできない領域
どこに、どのように作用するかの閾値が存在した場合、これは元画像によると考えられます。
プロンプトにより生成された画像に対し、閾値的な何かが複数設定され、その値によって、「オブジェクトの色だけを変える。」、「オブジェクトの形を変える。」または、「全く違う画像になる。」など、決定されていると考えると楽です。一定の操作は可能ですが、結局のところ運に身を任せるしかないです。

5. 結論と課題
”red”のキーワードによる、赤色の含有率への影響、語順による生成画像への影響はあることが確認できました。ただし、本質的にどのように作用しているかを特定することはできませんでした。
プロンプトのキーワードを増やすことでもう少し影響度を絞り込むことができる可能性fがありすが、要因が増え、作用範囲が絞れなくなりす。他にも”red”のような色以外のキーワードとの関連性を調べざるを得なくなってしまいます。以下では”緑”を加えてみていますが、キーワード同士の関連性は、取り上げれば取り上げるほど条件が絡み合い、複雑になってしまいます。呪文と称されることがよくわかります。
結局のところ、我々にはコントロールできないので、ガチャポンだと思って、祈り、待つしかないのかもしれません。
6 おまけ: 赤vs緑
画像生成が面倒だったので50枚での確認になります。headに”red”、tailに”green”みたいにして、赤と緑どっちが多いかと位置が紐づいているかをみてみました。

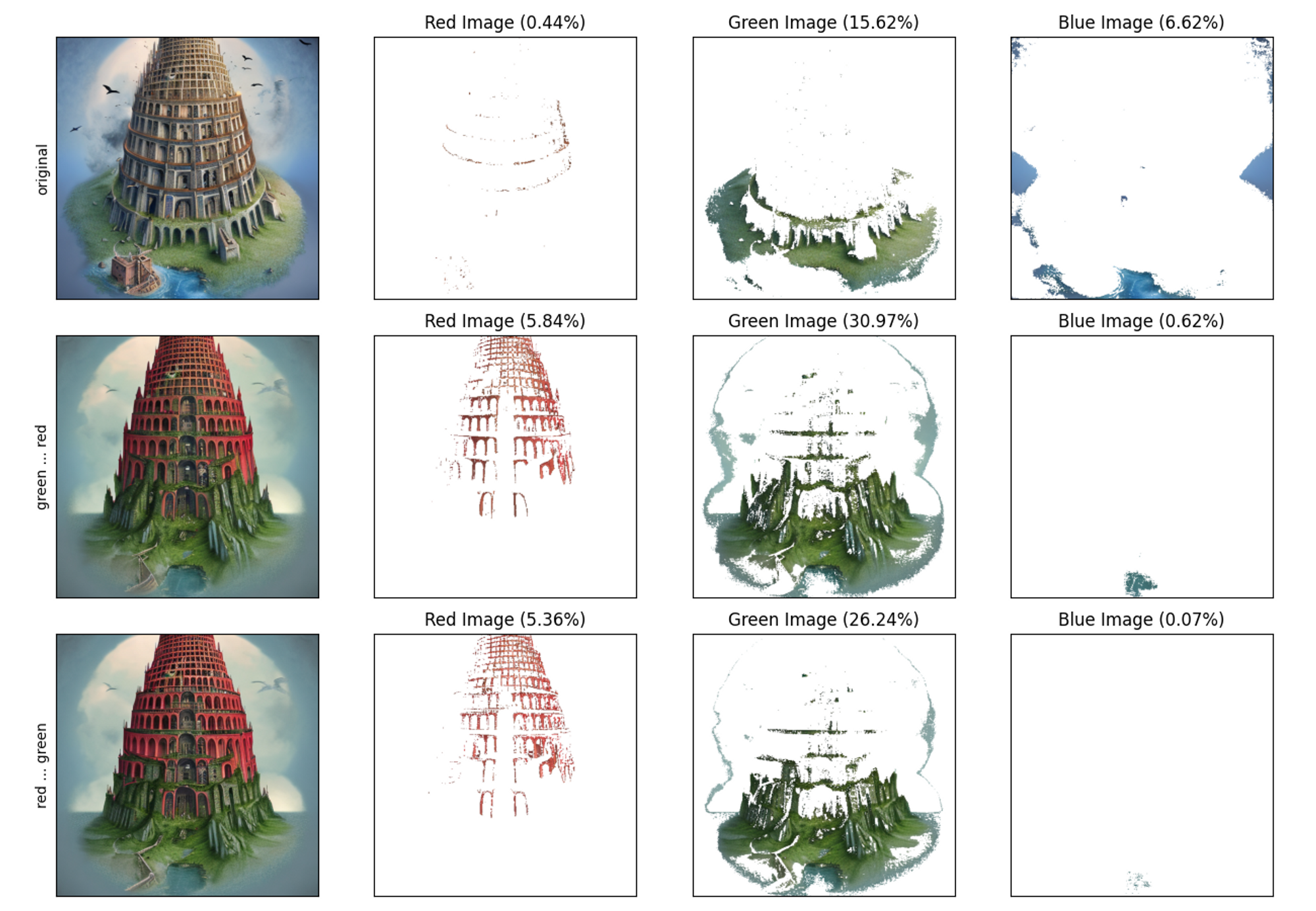
green”の方はhead側が強そうです。というか、赤よりも上昇率が大きめです。緑はやはり、自然的な要素を増やすことができるので、塔以外のオブジェクトとして作用できてしまうことで少し、赤よりも強いかもしれないです。
次に、red→greenとgreen→redにおける赤色の含有率です。
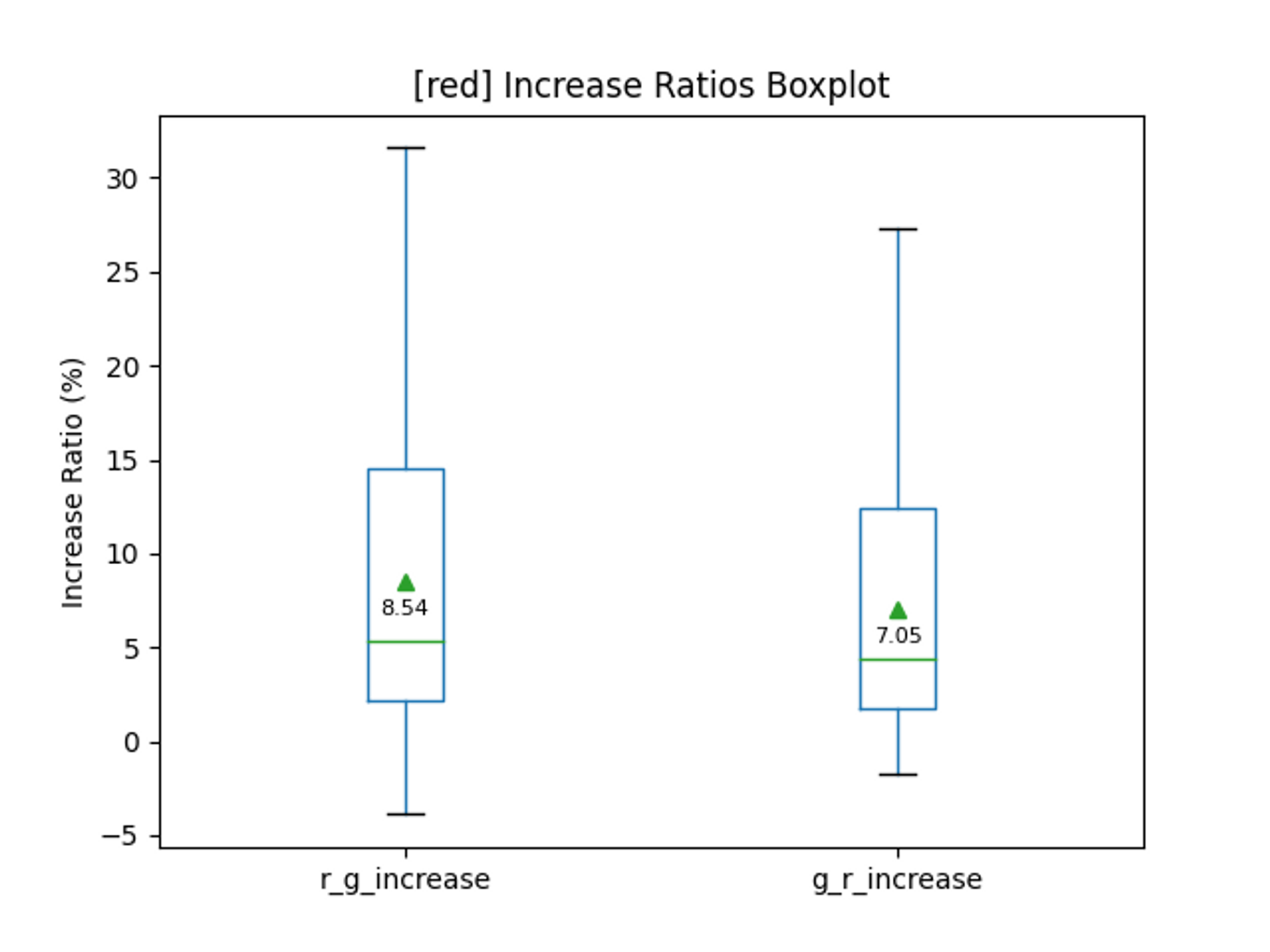
こちらは、緑の含有率です。
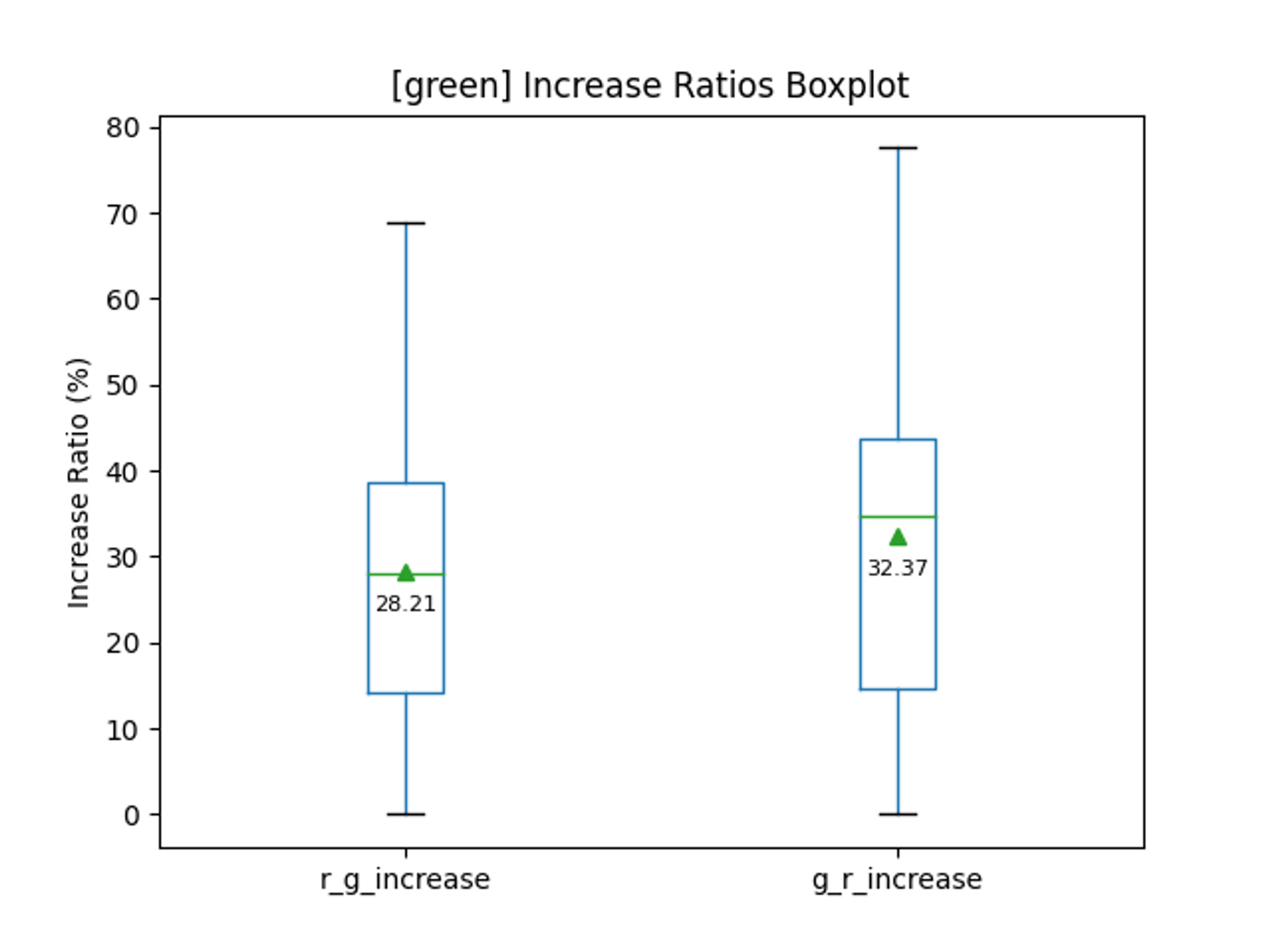
少ないですが、head側の影響度の方が大きそうではあります。
4箇所の位置の仕様、青色の追加を行うことで、もしかするともう少し影響度を絞り込めるかもしれませんが、これ以上はめんどくさいので一旦諦めます。