はじめに
最近、よくHTM Forumで議論されている「グリッドセル」についてそろそろ調査すべきだと思ったので和訳してみました。
和訳は今話題のDeepLにぶっこんでコピペしてます。ファイル翻訳だとレイアウトずれそうだったので、手作業でポチポチやりました。
概要
(原タイトル)"A Framework for Intelligence and Cortical Function Based on Grid Cells in the Neocortex"
(直訳) 新皮質のグリッド細胞に基づく知能と皮質機能の枠組み
海馬と隣接している嗅内皮質に、自分のいる場所に依存して反応するグリッドセルと呼ばれる細胞があることが知られている。この論文では、グリッドセルと同様のニューロンが新皮質のすべての領域にも存在していることを提唱する。
そしてこのグリッドセルが、新皮質が物体の構成と挙動を学習する際に使用されていることを説明する。
グリッドセルはどうやって位置を表しているのか?
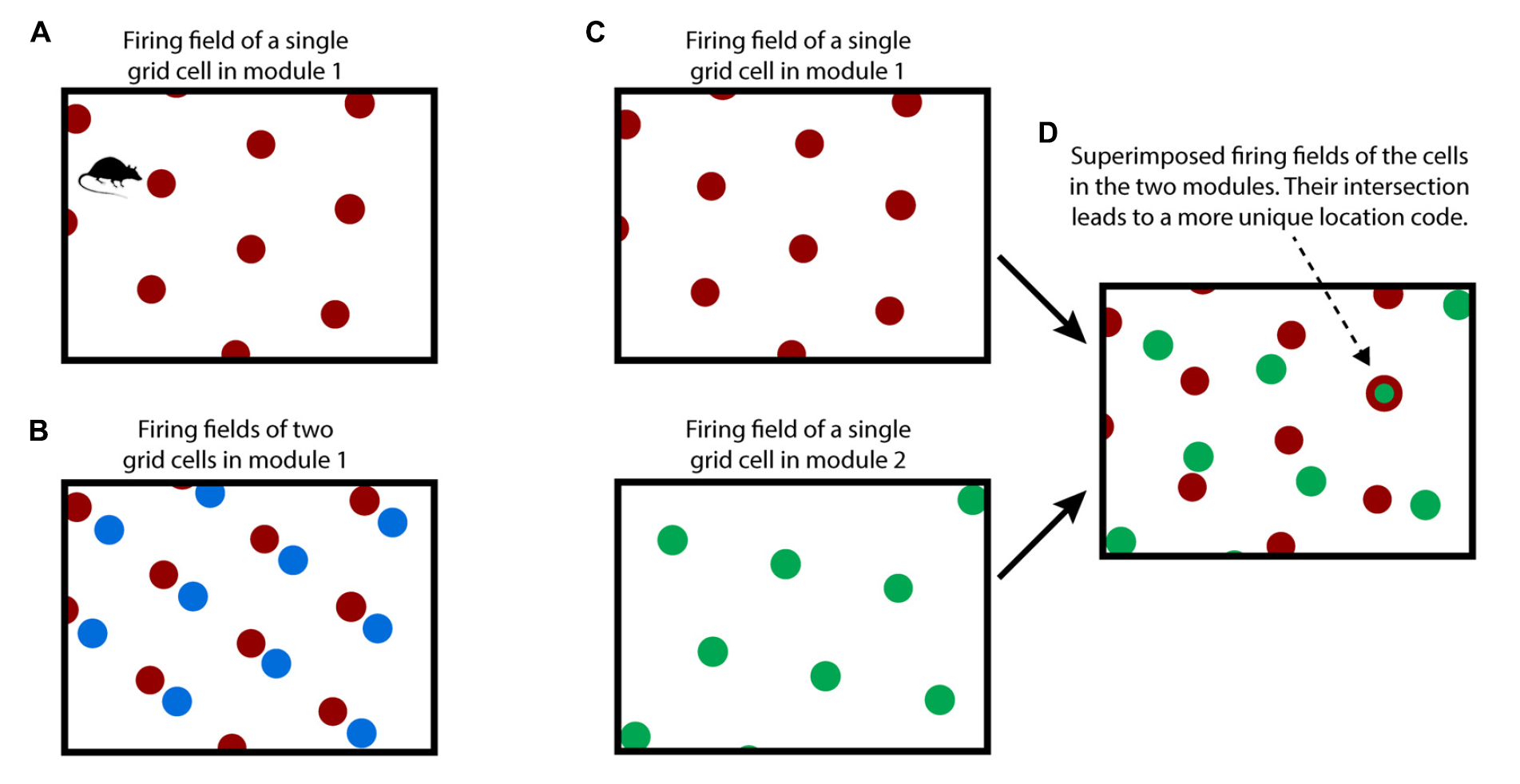
ある領域にある単一のグリッドセルは、自分が六角形の**格子(グリッド)**上にいるときに反応する(図中A)。単一のグリッドセルだけでは空間内のどの格子点上にいるのかはわからない。同じ領域にあるグリッドセルは同じ周期性で別の位置に対して反応する(図中B)。異なる領域のグリッドセルは同じ空間に対して異なる向き・間隔で格子を作っているため(図中C)、これらの重なりによって現在の位置が一意に定まる(図中D)。
大脳皮質にあるグリッドセルは物体の構造を学習する
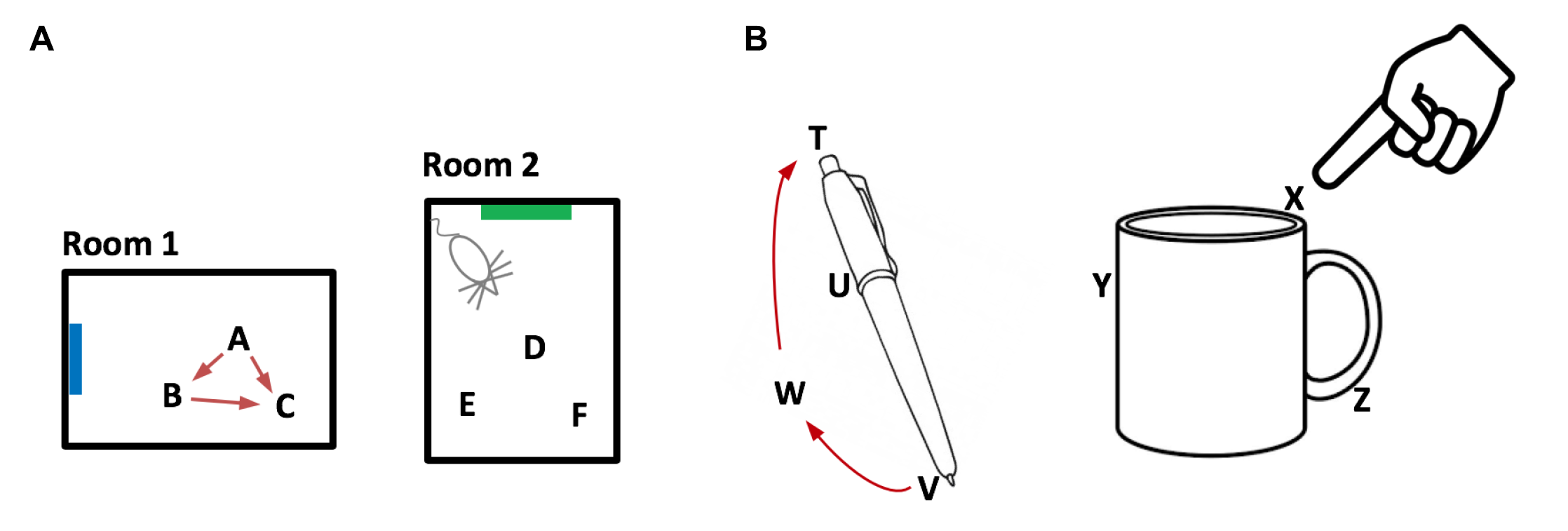
新皮質が物体の構造を学習する方法は、内嗅野・海馬が環境の構造を学習する方法と同じであると提唱する。ネズミが二つの部屋の構造を学習するとき、位置の表現(A, B, CとD, E, F)は両方の部屋に存在するが、別の目印(青と緑)があることによって別の部屋として区別できる。
これと同様に、ペンやコーヒーカップも位置情報の集合として定義できる。物体の空間内の位置(T, U, VとX, Y, Z)は固有のものであり、物体内を移動して探索することで新皮質は物体の位置に関する特徴を学習する。
変位セル
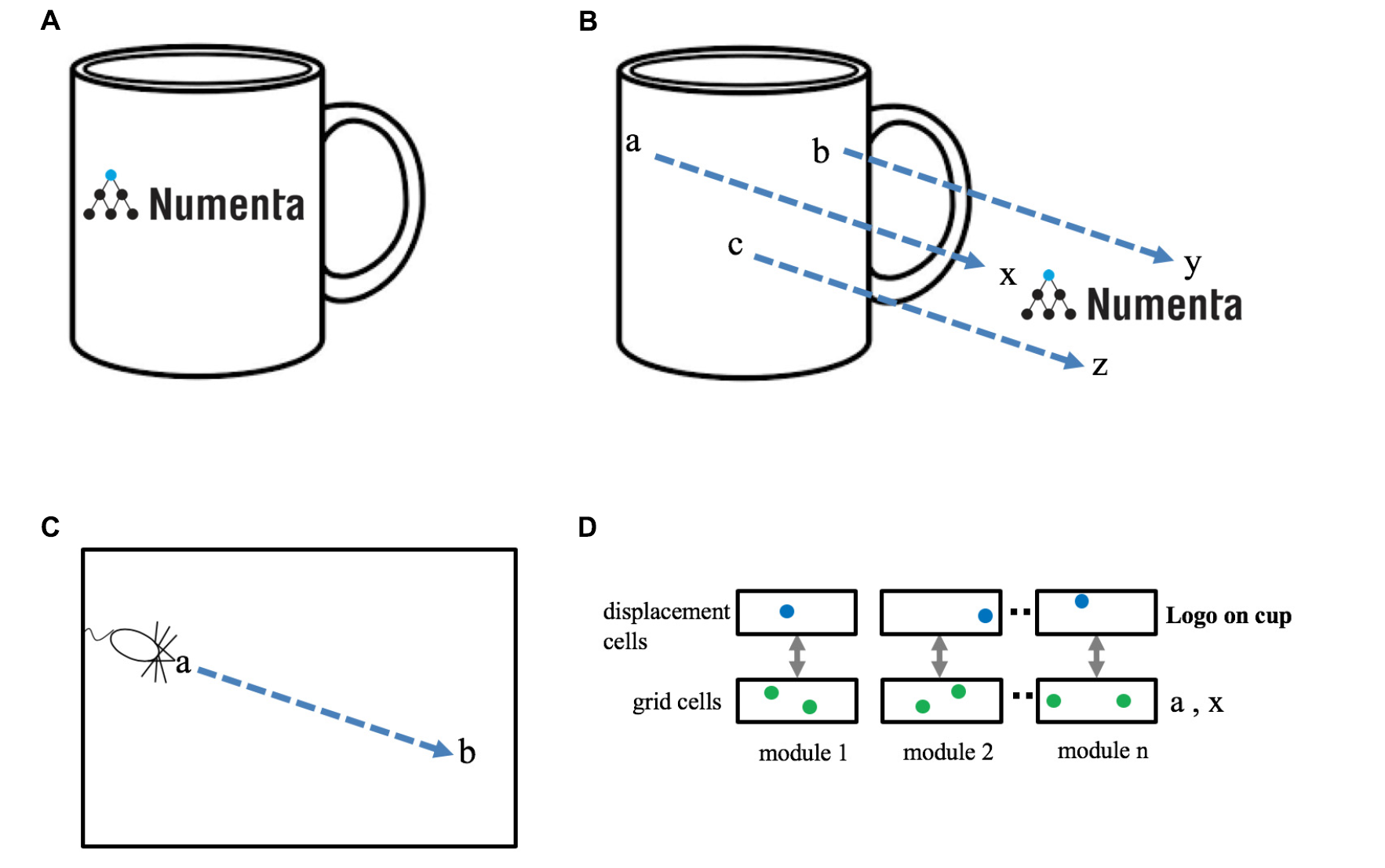
新しい物体の構造を学習する際、各位置を1から学習するのは非効率的である。例えば、コーヒーカップの構造を学習するときには、取っ手と円柱のように以前学習した物体の集合として学習した方が効率的だろう。
図Aのようなロゴ入りのコーヒーカップは「カップ」と「ロゴ」の集合として学習することができる。このような学習をするためには、「ロゴ」と「カップ」を相対的な位置で関連づける方法が必要である。カップ上にロゴを表現するためには、カップ空間内の点をロゴ空間内の等価な点に変換する変位ベクトルを作成する必要がある。これを可能にするのが、変位セルである。
同一空間内の2つの位置間の変位(Cのaからb)を決定することは、別々の空間内の2つの位置間の変位(Bのaからx)を決定することと等価である。図Dは2つの位置間の変位を決定する方法を示している。
各グリッドセルのモジュール(領域)は変位セルモジュールと対になっており、変位セルモジュール内のセル(青のドット)は、グリッドセルの対(緑のドット)の間の特定の変位に反応する。
物理的な空間で同じ変位を持つ2つのグリッドセルのペアは、同じ変位セルをアクティブにする。グリッドセルが固有の位置を表すことができないのと同じように、変位セルは固有の変位を表すことができない。しかし、複数の変位セルモジュール(図では3つ)のアクティブなセルのセットは、ユニークな変位を表す。
複数のグリッドセルモジュール内のアクティブなグリッドセルのセットは、物体(カップとロゴ)に固有のものであるため、アクティブな変位セルのセットもまた、(カップとロゴの両方に)固有のものとなる。したがって、アクティブな変位セルのセットは、2つの特定のオブジェクトの相対的な配置(カップ上のロゴの位置)を表すことができる。
物体の挙動
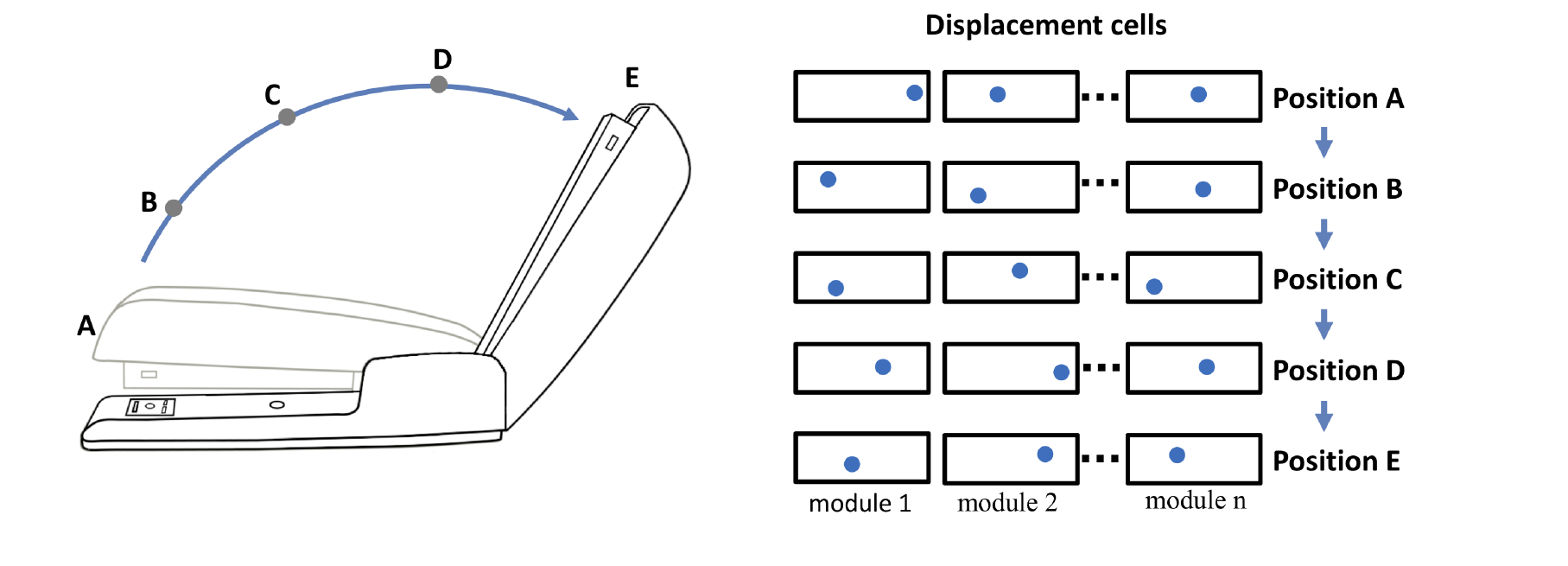
物体には「挙動」があり、時間の経過とともに形や特徴が変化する。新皮質はこれらの変化を学習することができるが、どのようにして学習するのだろうか?
例えば、ホッチキスにはいくつかの動作があるが、そのうちの一つは、ホッチキスの上部を基部に対して相対的に回転させることである。ホッチキスの上部がホッチキスの構成オブジェクトであり、それ自身の位置空間を持つとすると、ホッチキスの基部に対するその位置は、上図に示すように変位ベクトルで表される(ホッチキスの上部と基部は、ロゴとカップに類似している)。カップのロゴとは異なり、ホッチキスの上部と基部の相対的な位置は変化する可能性がある)。
閉じた位置は変位Aで表され、完全に開いた位置は変位Eで表されます。ホッチキストップが閉じた位置から開いた位置にヒンジすると、変位ベクトルは絶えず変化します。(5 つの位置、A から E、および対応する変位ベクトルが示されている。) この動作を学習するために、大脳新皮質は、上部が回転するときに変位ベクトルのシーケンスを学習するだけでよい。
脳の異なる領域での位置情報処理
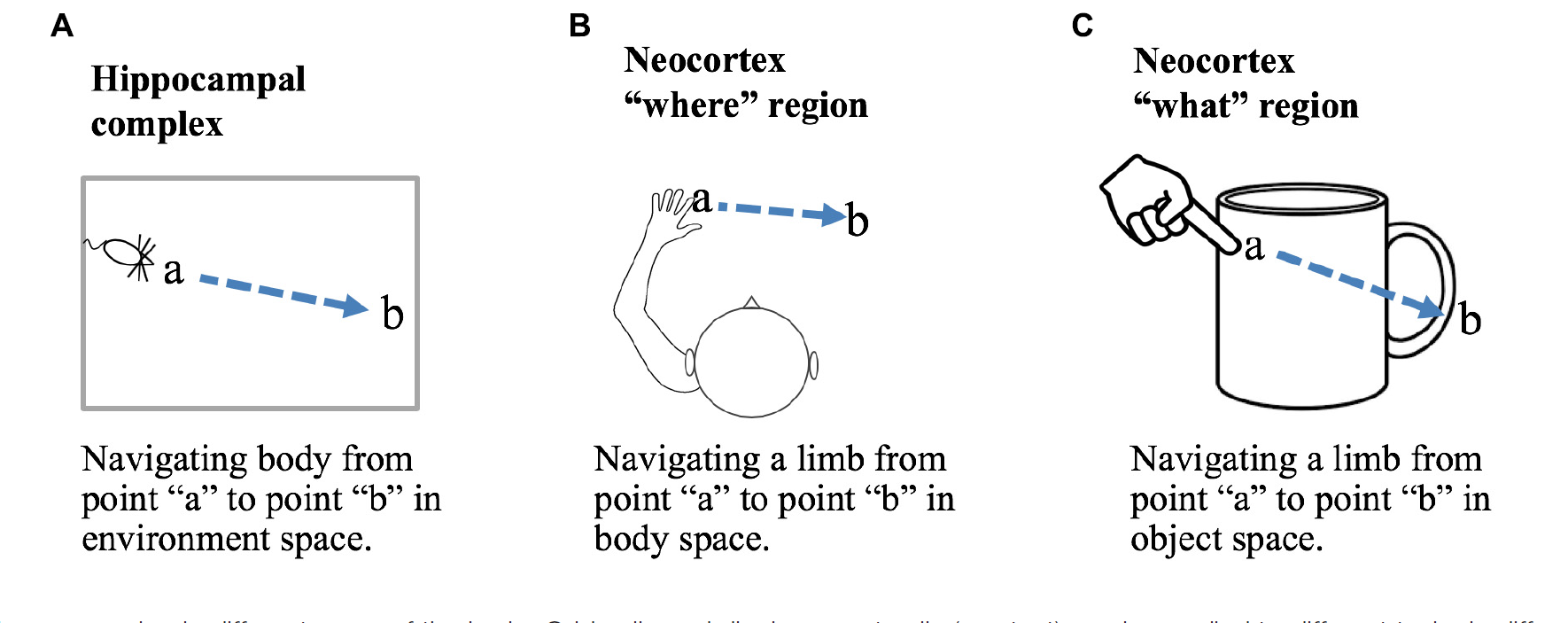
グリッドセルと変位セルは、脳の異なる領域の異なるタスクに適用することができる。
(A) 海馬複合体のグリッドセルモジュールが環境の合図によって固定されている場合、グリッドセルの活性化パターンは、その環境からの相対的な位置を表す。
(B)皮質のグリッド細胞モジュールが身体に対して相対的に固定されている場合、それは身体空間の位置を表す。つの位置が与えられると、変位セルは、身体の一部をその現在の位置から身体に対して相対的に所望の新しい位置に移動させるのに必要な運動ベクトルを計算する。
(C)皮質グリッドセルモジュールが物体に対する合図によって固定されている場合、それらは物体の空間内の位置を表すことになる。変位セルは、四肢または感覚器官をその現在の位置から物体に相対する新しい位置に移動させるのに必要な移動ベクトルを計算する。
大脳皮質の階層構造
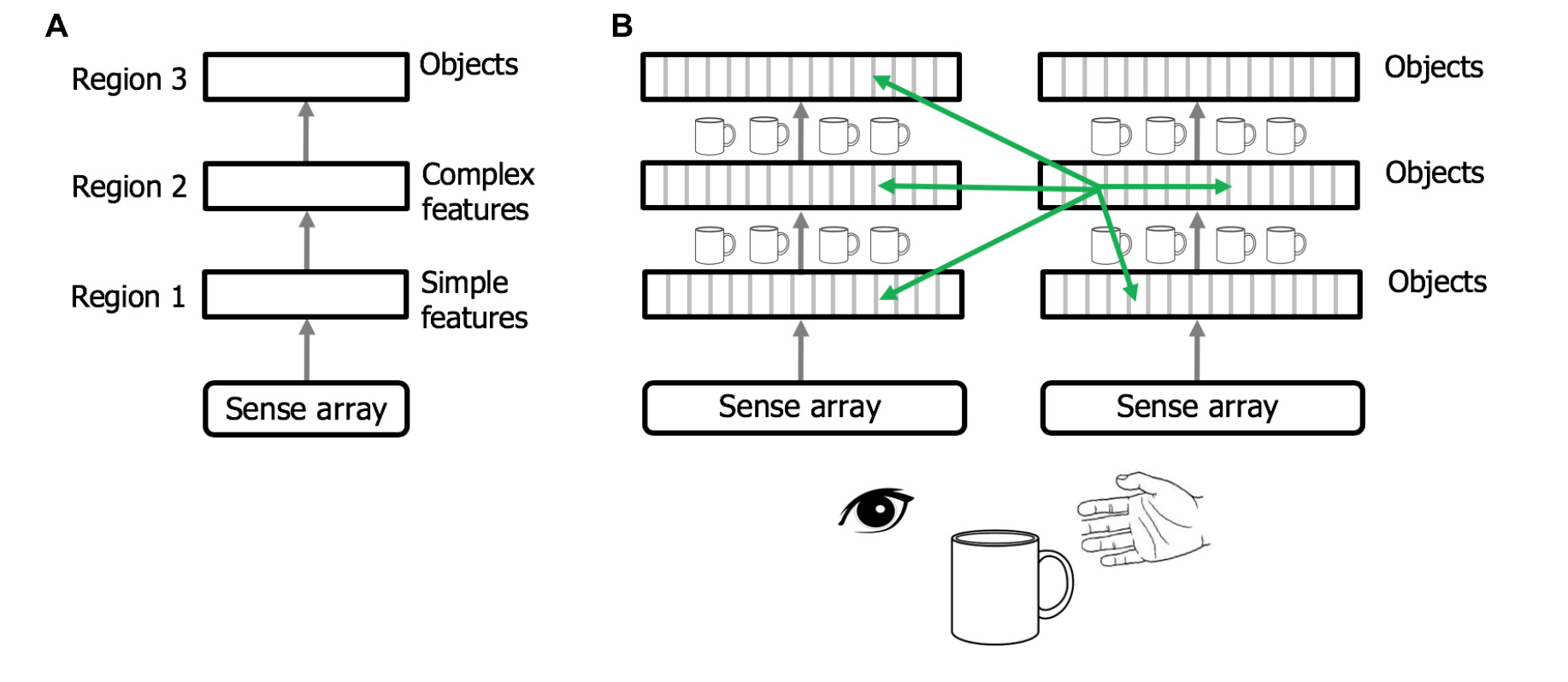
(A)大脳皮質階層についての一般的なイメージ図
感覚入力は皮質領域の階層で処理される。感覚入力は皮質領域の階層構造で処理される。このようにして、最初の領域は単純な特徴を検出し、次の領域は単純な特徴をより複雑な特徴に結合していく。これは、階層の一番上にある領域が完全な物体の表現を形成するまで繰り返される。
(B)大脳皮質階層の修正図
各領域の各カラム(灰色の線で区切られた部屋の一つ一つ)はオブジェクトの完全なモデルを学習する。このようにして得られた情報を基にして、各カラムは物体の完全なモデルを学習する(カラムは、感覚的な入力とその入力の物体中心の位置を組み合わせてセンサーの動きを統合することで、完全なモデルを学習する)。
視覚と触覚の2つの感覚階層があり、どちらも同じ物体であるコップを感知しています。感覚モダリティの中の異なる領域、異なる感覚モダリティの中で、それぞれの領域内に複数の物体のモデルが存在する。同じ物体のモデルは多数存在しますが(小さなカップの画像)、各モデルは感覚アレイの異なるサブセットを介して学習されるため、モデルは同一ではない。
緑の矢印は、自然界では階層的ではない数値的に大きな皮質-皮質接続を示している。多くのカラムが同時に同じオブジェクトを観測しており、カラム間の非階層的な接続により、カラムは正しい物体を迅速に推論することができる。物体の学習にはセンサーの動きが必要であるが、推論は非階層的な接続のために動きなしで行われることが多い。
新皮質におけるグリッド細胞と変位細胞の位置
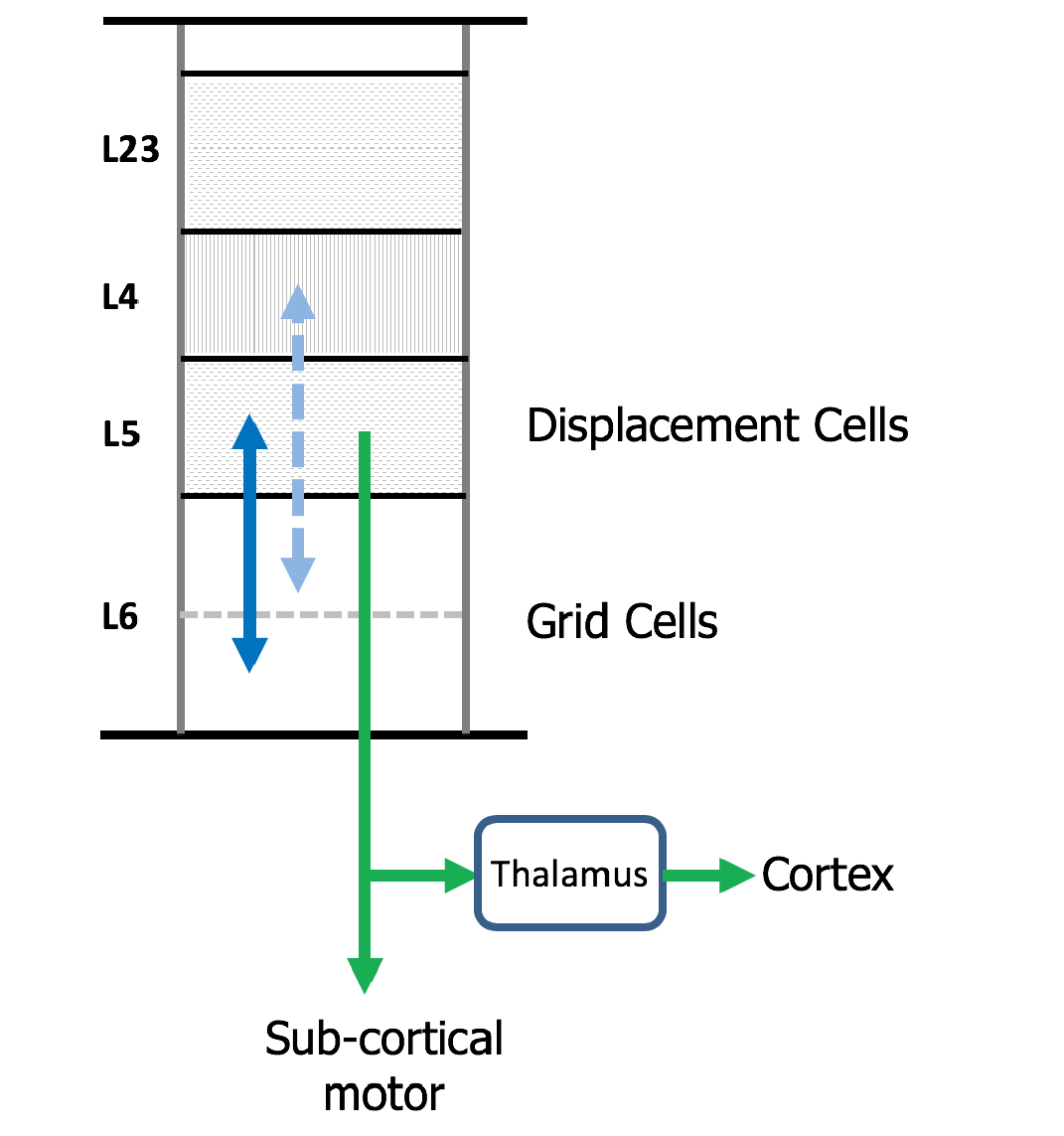
大脳新皮質は、一般的に6つの細胞層に組織された数十種類の細胞を含んでいる。ここでは、大脳皮質の列の簡単な図を示す。
筆者らは、大脳皮質のグリッドセルが6層に、変位セルが5層にあると提唱している。提唱の要件は、皮質グリッドセルが変位セルと双方向の接続を行うことである(青の実線)。
もう一つの要件は、方位の表現と組み合わせることで、レイヤー4の細胞と双方向の接続を行うことである(青の破線)。このようにして、カラムはレイヤー4への次の入力を予測する。
これらのニューロンは、軸索が分岐する白質に軸索を送り込む(緑の矢印)。1つの枝は、運動行動を司る皮質下の構造物で終末する。第二の軸索分岐は、視床の中継細胞で終端し、階層的に高い皮質領域へのフィードフォワード入力となる。変位セルは、運動を表現することと、複数の物体の構成を表現することとを交互に行うことができる。筆者らは、L5の太い房状細胞がこの2つの機能を交互に果たすことを提案している。
結論
本論文では、大脳新皮質の働きを理解するための新しい枠組み(大脳新皮質のいたるところにグリッドセルが存在すること)を提案する。
皮質のグリッドセルは、観察対象の大脳皮質への入力の位置を追跡する。筆者らは、グリッドセルを補完する新しいタイプのニューロン、変位セルの存在を提案する。
この枠組みは、大脳皮質の小さなパッチが、物体の形態(物体が他の物体とどのように構成されているか)、物体の挙動を表現し学習することが可能であることを示している。
この枠組みはまた、新皮質が全体的にどのように機能するかについての新しい解釈を導く。新皮質は、階層の一番上で物体認識につながる一連の特徴抽出ステップで入力を処理するのではなく、階層的にだけでなく並列的に動作する1000個のモデルで構成されています。
私たちが連続して対象物に注目している間に、脳が対象物の位置と対象物間の距離の神経表現を持たなければならないことは自明である。
我々の主張の新しさは、これらの位置と距離が大脳皮質のいたるところで計算されており、それらが皮質機能、知覚、知性の主要なデータ型であるということである。
まとめ
自分の位置を推定するためにあると考えられているグリッドセルが、あらゆるオブジェクトの構造を学習するのに使用されているということらしい。
論文中では自然言語などの構造も同様に学習されていると主張されていたが、実際に実装されてたりするんだろうか。気になる。
あと、DeepL確かにすごい。
和訳論文
語調統一されてなかったりガタガタですが、参考までに和訳版のGoogle Driveリンクを貼っておきます。