はじめに
声優さんは世に大勢いらっしゃいますが、声質がどの程度似ているのかを自動的に数値化・可視化できると面白いのではないかと唐突に思い立ちました。
100名の日本人のプロ声優さんの音声データであるJVSコーパスを以前使ったことがあるのですが、そこにsimilarity_matrix.csvなるデータを発見。
コーパスに付属している論文を調べてみたところ、こちらの論文にたどり着きました。
「DNN音声合成に向けた主観的話者間類似度を考慮したDNN話者埋め込み」
◎齋藤佑樹,高道慎之介,猿渡洋(東大院・情報理工)
http://sython.org/papers/ASJ/saito2019asjs.pdf
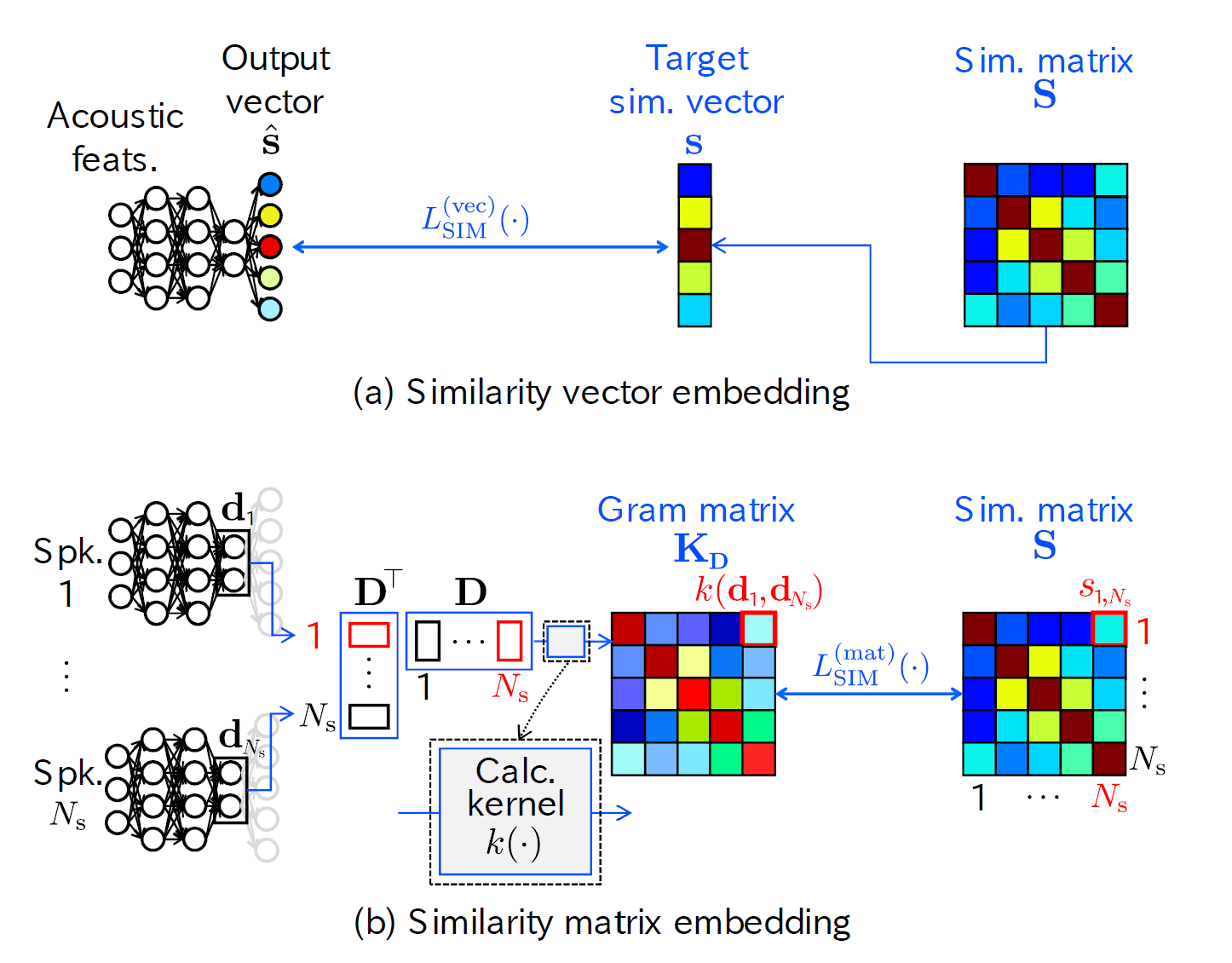
論文の概要
まず、複数話者の音響特徴量を入力したニューラルネットワークに、各話者の類似度を収めた行列を出力させます。そして、この出力が人間が評価した類似度と近づくように学習をすすめていくと、ニューラルネットワークの中間表現が主観評価を反映したベクトルとなるということのようです。
モデルの学習
元論文ではJNASコーパスを学習させていましたが、こちらは有料でしたので今回はJVSコーパスを用いて類似度出力モデルを学習させました。
学習にはnonpara30(発話内容がそれぞれの声優さんでバラバラ)を使用しています。これは、テキスト非依存で類似度がだせるようにという意図からです。
テストデータでの評価
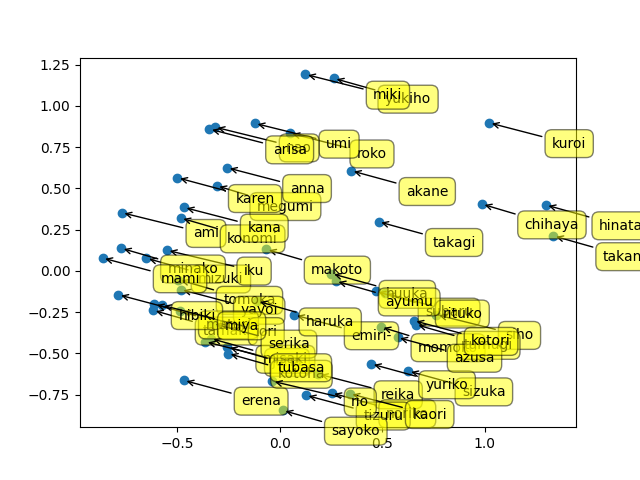
知人からいただいたミリシタのタイトルコール50数人分(抜けあり)で類似度行列を出してみました。下の画像はPCA(主成分分析)を用いて各話者を2次元でプロットしてみた結果です。
感想
うーん...全然一致してない気がする(笑)
パラメータ探索等はこれからなので、いろいろ試していこうと思います。
実装