本記事は,DSL Advent Calendar 2019の9日目の記事です.
8日目の記事に引き続き弊学での講義「プログラミング入門」についてのお話です.
私はその講義でTAをやっているのですが,受講者は毎週課題を与えられて次の週の講義までに終わらせてくるといった,要するに宿題があります.TAにはその課題を毎週採点するといった業務が課せられます.初めの方は簡単なプログラムばかりで課題の内容も簡単なのですが,回を重ねる毎に内容も出力との照らし合せもより複雑になってくるのでPythonで動く採点システムを作りました.
「退屈なことはPythonにやらせよう」ってやつです.
課題
課題はjupyter notebookで解答できる.ipynb形式で配布され,中に問題と解答用のセルが用意されているのでそこにコードを記述し出力があっているか確かめる形式になっています.基本的にはコードセルの中身だけ編集して結果を確かめるように伝えてあるので,常に特定のセルの出力をチェックするだけで点数は付けられるようになっています.
以下にイメージを持っていただくために,簡単に課題を再現した画像を載せておきます.
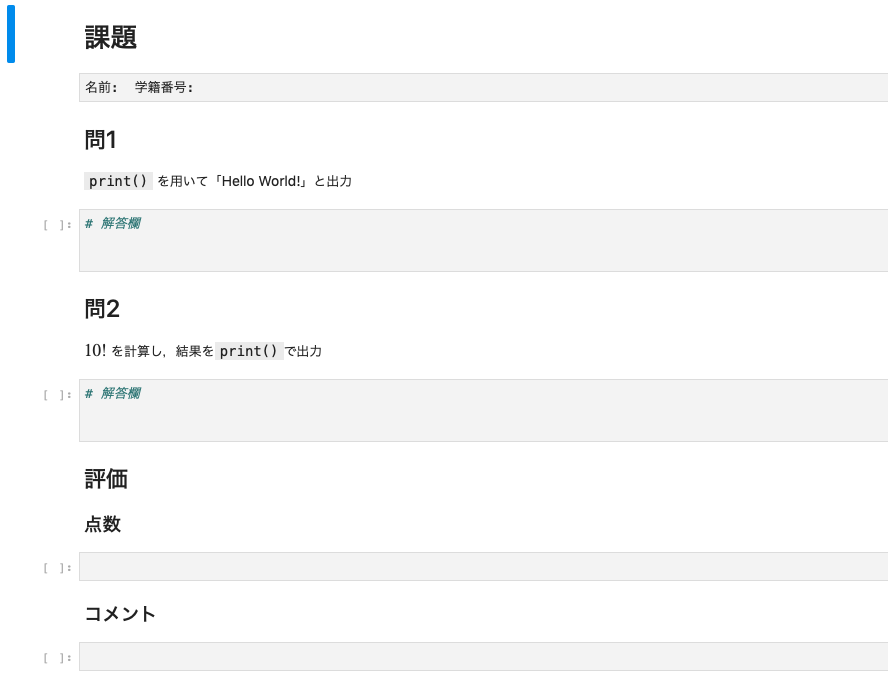
問題はとても簡単なものにしましたが,おおよそこんな感じです.
採点について
採点基準
まずは採点基準についてです.毎回の課題や問題でそれぞれ変わってきますが,大まかな基準としては下の3つです.
- プログラムがエラーを起こさない
- 出力結果が正しい
- 指定された文法や構文が使われている
1,2番目基準はそのままですが,3つ目の「指定された文法や構文」というのはその週に習ったforやifの事です.
(毎回プログラムの構造に指定があるわけではないです)
採点方法
予めTAには課題の答えと採点基準が配布されます.各TAはおおよそ20人ぐらいの解答済みのipynbが配布され,それをjupyter notebook上で開いて一つ一つのソースコードや出力結果や再実行を確かめて採点結果を評価欄に書き込みます.現在は満点が4点で一つにつきおおよそ4つ確かめれば良いものの,私はこの作業がやってられなかったのでスクリプト化してみました.(某IIのシステムがlabじゃなくてnotebookなおかげで大量にタブ開いて通信待ってさらにセルを評価し直すというのは辛かった)
採点システム
やることは以下の通り
- 全員分のipynbをリスト化
- ipynbをparse
- 解答用セルを特定
- 正規表現
reや 評価exec()でソースコードや出力を正答と比較 - 満点の場合 ipynb に点数を書き込み
それぞれについてソースコードを載せながら解説していきます.
全員分のipynbをリスト化
Python標準モジュールの pathlib を使います.
import pathlib
# path to notebook(.ipynb)
p_nb = pathlib.Path("../path/to/notebook/")
ipynb を parse
ipynbの中身はjsonなので json.load() でparseできます.
また,ipynbの全てでループを回すときに,pathlibをうまく扱える glob メソッドを使っています.
import json
# notebooks(.ipynb)
for _nb in p_nb.glob("*.ipynb"):
# load json (*.ipynb)
with open(_nb, "r")as f:
nb = json.load(f)
cells = nb["cells"]
ipynbの詳しい構造の解説は省略しますが,セルの情報は {"cell": [cell1, cell2, cell3], ...} のようになっているので,nb["cells"]でそのリストが取得可能です.
これ以降のソースコードは一段インデント下がっている状態ですが省略しますのでご注意ください.
解答用セルを特定
cellの中身は大まかには以下の通りです.
- cell_type: 'markdown' や 'code' など
- source: マークダウンテキストやソースコードなど (1行ずつのリスト)
- outputs: ソースコードの出力結果 (エラーなども含まれる)
その他にも情報は含まれますが,今回のシステムで使うのは上記の3つです.
では,解答用のセルを特定します.
今回は上で例として挙げたipynbに対等するようにソースコードを書いています.
一回の採点で最高でも4回は使うので関数化しています.
def identify_cell(sentence, cells, cell_type='markdown'):
"""全てのセルから条件に一致するセルの番号をreturn"""
for i,_cell in enumerate(cells):
if _cell['cell_type'] == cell_type \
and _cell['source'][0] == sentence:
_cell_num = i
break
return _cell_num
# identify cell
_cn = identify_cell(sentence="## 問1\n",
cells=cells)
ans_cell = cells[_cn + 1]
identify_cell()でチェックしているのは,
cell_typeがmarkdownであること,またsourceの1行目が"## 問1\n"であることです.
上記の条件に一致したセルの番号をreturnで返しています.
ここからはpprint()などを使いながらセルの中身をチェックしていくと良いです.
注意しなければいけないのは,答えを確認したいのはソースコードやその出力結果なので,次のセルである_cn + 1番目のセルを解答用セルとして変数に格納しておきます.
ソースコードや出力を正答と比較
1問目の「Hello World!」を出力せよ.という問題の正否をチェックしてみます.
今回は出力結果があっているかどうかだけ確かめれば良いので以下の通り.
try:
result = ans_cell['outputs'][0]["text"][0]
if result == "Hello World!":
score += 1
except:
pass
ちなみに,try-exceptを用いているのは課題が無回答だった場合に対応しているためです.(outputsの中身が無かったりする)
ifで対応しても良かったのですが,多くの解答を見ていると本当に様々な場所でエラー吐かれるのでこれで妥協しました.
現在の実際に運用しているソースコードでは,毎週pathとこの部分を変えるだけで動くようになっています.
解答のパターンや注意事項は別途記事下部に載せておきます.
満点の場合 ipynb に点数を書き込み
本来なら満点以外でも書き込んでも良いのですが,念のための解答ipynbのチェックと間違っている問題があった人には別途コメントをしているので現在のような仕様にしております.
if score == 2: # 満点=2点の場合
# identify cell
_cn = identify_cell(sentence="## 評価\n",
cells=cells)
# score cellの上書き
cells[_cn + 1] = {'cell_type': 'code',
'execution_count': None,
'metadata': {},
'outputs': [],
'source': [str(2)]}
# 解答用のipynbにdump (上書き)
json.dump(nb, _nb.open("w"))
こちらは弊研究室の同じくTAをやっている方(@y_k)に提供してもらいました.
プログラムの中身としては,scoreが満点の場合のみ評価結果を入力するセルに満点の数字を記入したものを上書きし,ipynbを保存しています.ただ誤ったものを上書きしてしまうと面倒くさいことになってしまうので,本番環境ではこちらとは別に元のipynbのバックアップは取るスクリプトも用意しています.
注意事項
解答のチェックをする際に気をつけなければいけない部分を多少並べておきます.
挙げたもの以外にもプログラミング初心者だと本当に様々な変化球を投げてくるので割と大変です.
print()での出力とipythonで使える変数のみでの出力は出力のパターンが異なる
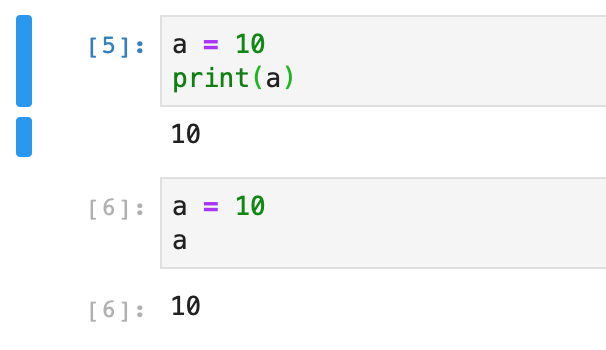
これだけでも"outputs"の中身が違うためプログラムが大きく変わったりするので結構大変.
プログラムを評価しなければいけない時,簡単はexec(script)としても出力結果が得られない.
これも結構大変で,評価基準に評価し直さなければいけないものがあるとき,
exec(script)(scriptはstrのソースコード)を用いて結果を確かめるのですが,scriptにあるprint()はjupyter notebook上でも表示されないどころか出力を得るのがかなり大変です.私は,標準出力を上書きするプログラムを書いて対応しましたがあまりオススメできないかもしれません(通常時のprint()も表示されなくなるため).一応ソースコード載せておきます.
import sys
import io
import contextlib
@contextlib.contextmanager
def stdoutIO(stdout=None):
old = sys.stdout
if stdout is None:
stdout = io.StringIO()
sys.stdout = stdout
yield stdout
sys.stdout = old
# 実行
try:
with stdoutIO() as s:
exec(script)
# 以下でprint()の出力を取得
output = s.getvalue().split()
except:
# script Errorの場合except
pass
全角半角問題
答えに記号や数字で全角になるものがあると,正答と一致しなくなるので間違っている扱いになってしまいます.ですので出力結果を予め半角に変換しておくと多少楽になります.
def trans_hankaku(sentence: str) -> str:
"""全角文字を半角文字に変換する関数"""
return sentence.translate(
str.maketrans(
{chr(0xFF01 + i): chr(0x21 + i) for i in range(94)}
))
上記のように半角に変換する関数を定義しておくと楽かもしれません.
まとめ
今回は「退屈なことはPythonにやらせよう」を実践することができました!(読んだことない)
本日分の記事も昨日のDSLアドベントカレンダー8日目の記事 同様,誰かの助けになればと思います.
ソースコードや今回用いたipynbはこちらにおいておきます.
https://github.com/liseos-x140/scoring_ipynb
あとがき
jupyterのバージョンや種類によって生成されるipynbの構造が違う可能性があるので,あくまで参考程度にしてもらえると嬉しいです.
またソースコードについては,まだまだ開発段階なのである程度まとまり次第また更新できればと思っています.
参考