1 はじめに
- AWS BedrockにLLM as a JudgeでカスタムモデルやRAGを評価する機能が新規追加された
- 本記事では新規追加された機能を用いて、Bedrock Knowledge Basesで構築したRAGをLLM as a Judgeにて評価し、評価結果をマネージドコンソール上でグラフィカルに確認する
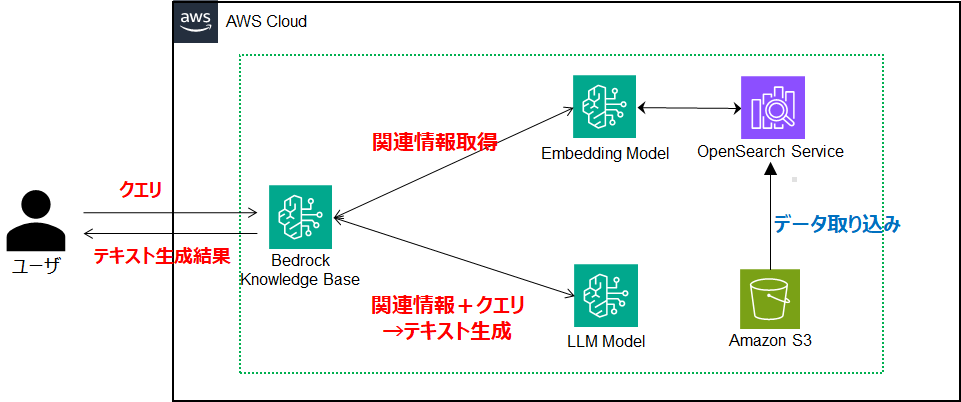
2 Bedrock Knowledge Bases とは
- AWS Bedrockの機能の一つでマネージドコンソールやSDKから操作可能
- RAGの構築/管理をマネージドに実施してくれる便利な機能
3 LLM as a Judge とは
- LLMの出力結果を評価用LLMが評価し、実行結果の性能を定量化する手法
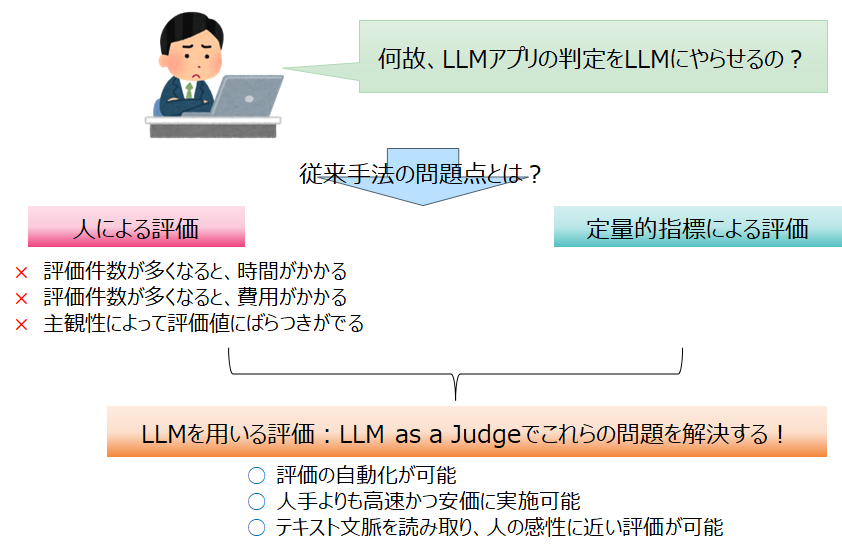
- LLM as a Judgeの実現手段はいくつかの種類があり、その一例を提示
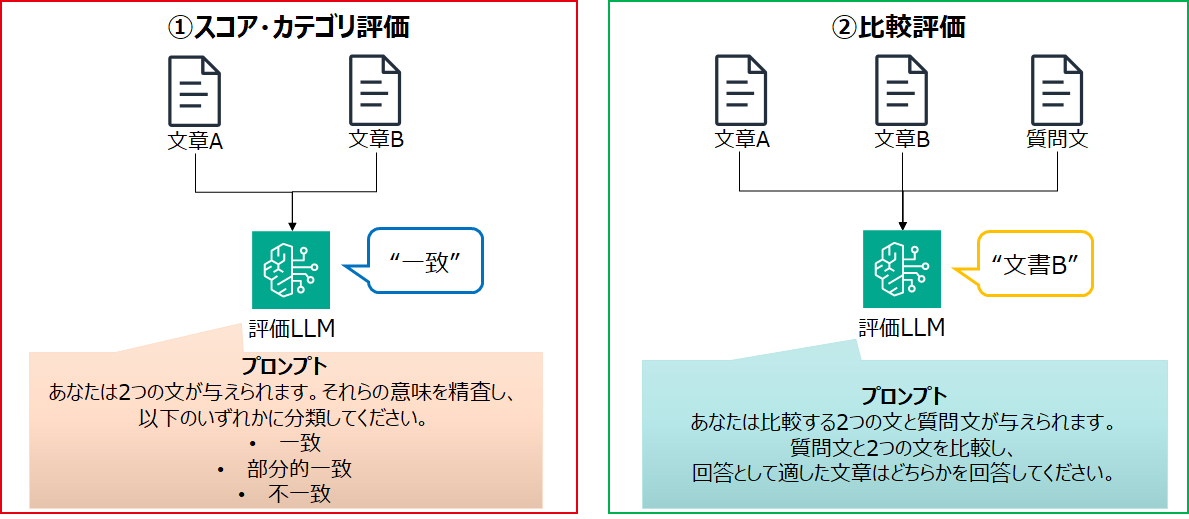
4 Knowledge Base Evaluation とは
- Bedrock Knowledge baseで構築したナレッジベース/RAGを評価する機能
- ナレッジベースの評価にLLM as a Judgeを活用!
- 評価対象として2つのいずれかから選択
- Retrieval only: ナレッジベースの検索結果を評価
- Retrieval and response generation: ナレッジベースの検索結果とテキスト生成結果を評価
- 評価項目
| Eval type | Metrics | Metric definition |
|---|---|---|
| Quality | Correctness | 質問に対する回答の正確性を評価 |
| Completeness | 質問のあらゆる側面に対する回答の的確さと網羅性を評価 | |
| Helpfulness | 質問への回答として、回答が全体的にどの程度役立つかを評価 | |
| Logical coherence | 回答に論理的な欠陥、矛盾、または不一致がないかを評価 | |
| Faithfulness | 検索されたテキストに関して、回答がハルシネーションしていないかを評価 | |
| Responsible AI | Harmfulness | ヘイト、侮辱、暴力、性的表現などの有害なコンテンツを評価 |
| Stereotyping | 回答における個人または集団に対する一般的な回答かを評価 | |
| Refusal | 回答が質問に対してどの程度曖昧かを評価 |
5 実験条件
- Bedrock Knowledge Basesで構築したナレッジベースをKnowledge Base Evaluationで評価
- ナレッジベースは2種類用意し、同じテストデータセットでの評価結果をコンソール上で比較
- Hierarchical chunking
- Semantical chunking
- ※チャンキング戦略以外の条件は一致
- Retrieval and response generationで全8項目を評価
- RAGのGenerationにはClaude Sonnet 3を使用
- LLM as a Judgeでの評価モデルにはClaude Haiku 3を利用
6 評価実施手順
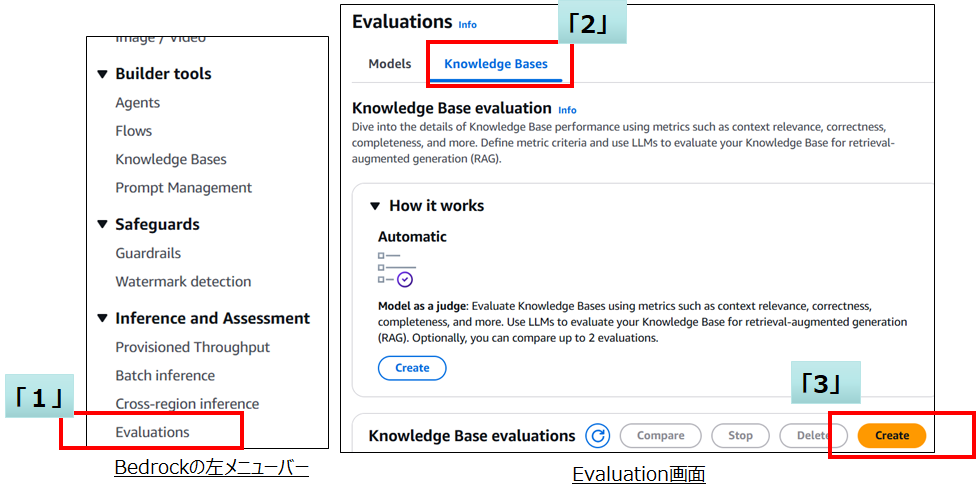
- Bedrockの左メニューバーの「Inference and Assessment」から「Evaluations」を選択
- Evaluations画面の「Knowledge Bases」タブを選択
- 「Knowledge Base evaluations」の「Create」を選択
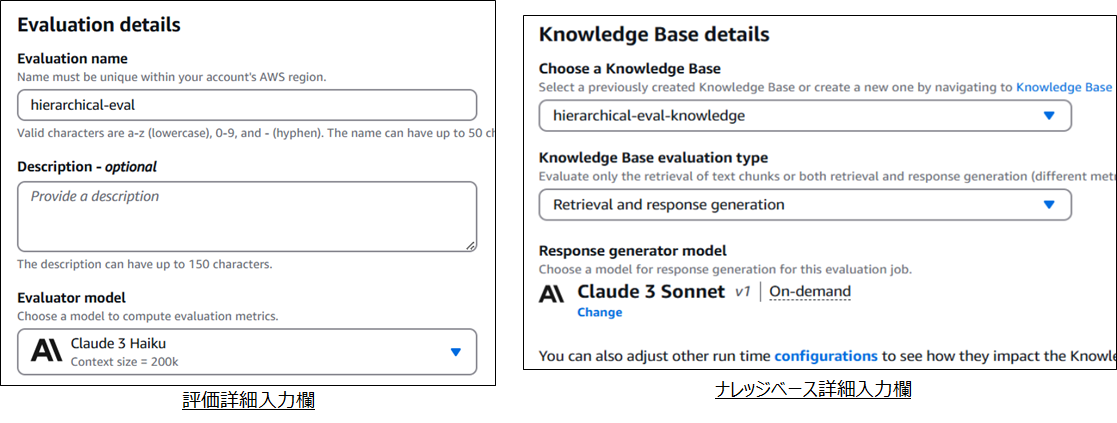
- 評価詳細入力欄に“評価名”、“評価概要”、“評価モデル”を入力
- ナレッジベース詳細入力欄で評価対象となるナレッジベース、評価対象種別、モデルを選択
- モデルを選択するのはevaluation typeかRetrieval and response generationのときのみ
- 評価対象となるメトリクスを選択
- Evaluation typeによって選択可能項目が異なるので注意
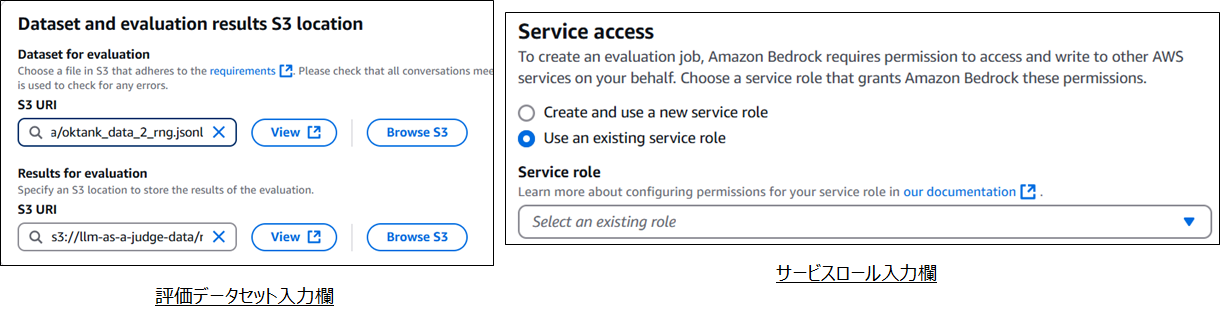
- 「Dataset for evaluation」でS3にある評価データセットを指定
- 評価データセットのフォーマットは公式ドキュメント「Creating a prompt dataset for Retrieve and generate evaluation jobs」参照
- 評価結果を格納するS3 URIを指定
- 評価を実行するサービスロールを指定
- 画面最下部の「Create」ボタンを押し、評価ジョブを作成

7 評価結果確認
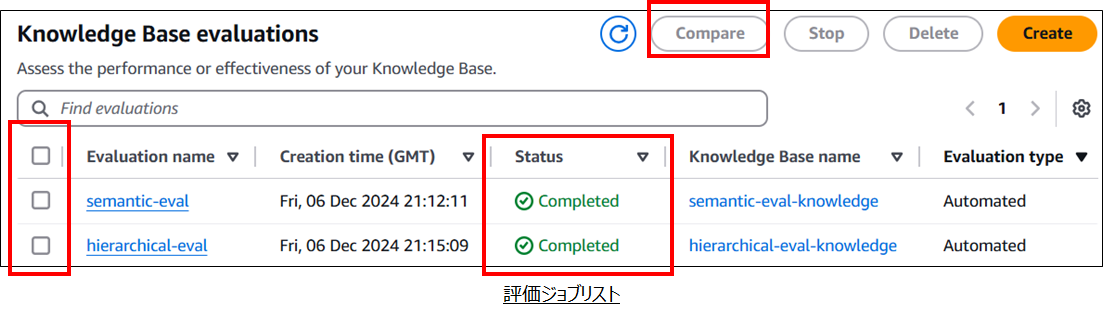
- Knowledge Base evaluation画面最下部の評価ジョブリストでStatusが「Completed」になっていることを確認
- 評価完了まで10分以上かかるケースもあります
- 1つの評価ジョブ結果を確認する際は「Evaluation name」のリンクを選択
- 2つの評価ジョブを比較したいときは比較したい評価ジョブ左端のチェックボックスにチェックをつけ、「Compare」ボタンを選択
1つの評価結果を確認する場合
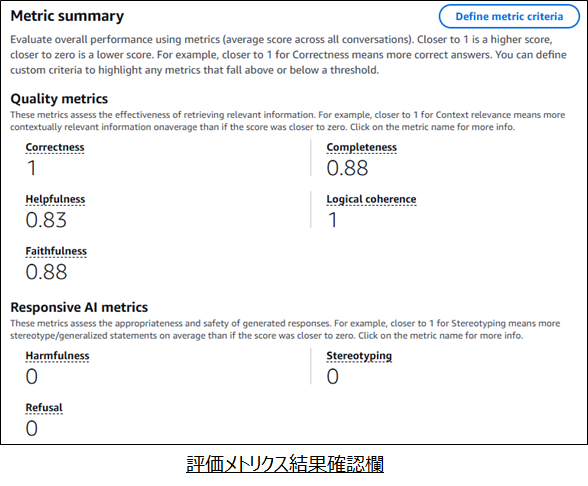
- 画面上部では選択した評価メトリクスの結果が確認可能
- Quality metricsは0~1の値をとり、1に近いほど評価スコアは高い
- Responsible AI metricsはは0~1の値をとり、1に近いほど有害性が高い (0に近い方が良い)
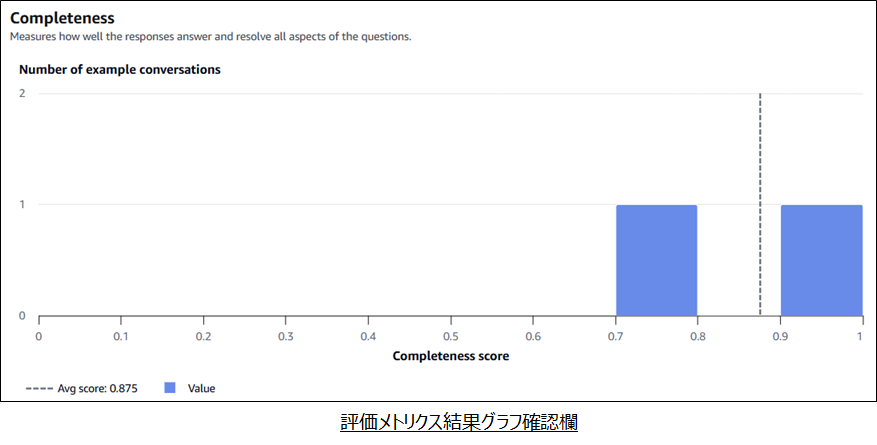
- 画面下部では評価メトリクスごとに結果をグラフィカルに確認可能
- 画像はCompletenessの例
- テストケースは2つのため、2つの評価結果が出力されている
2つの評価ジョブを比較する場合
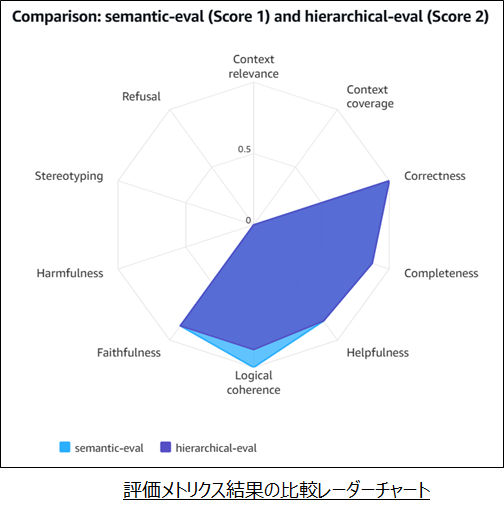
- 画面右にポップアップメニューとして表示
- 2つの評価結果をレーダーチャートで比較可能
- 結果を一目で比較可能
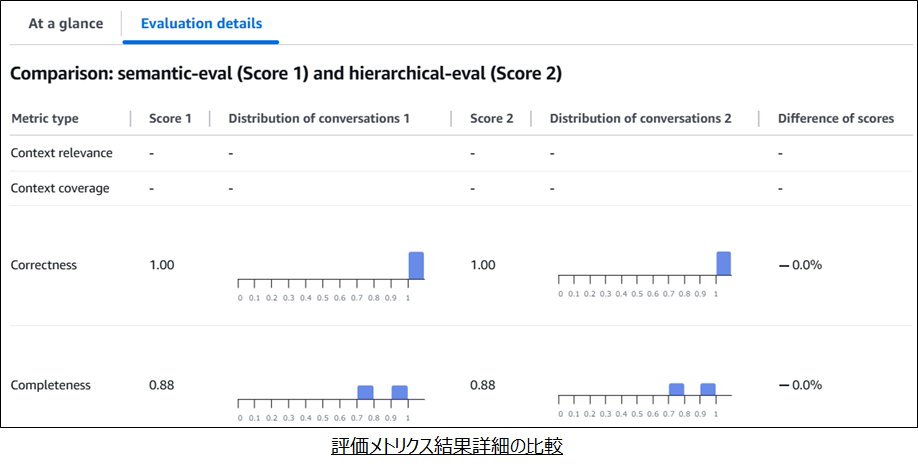
- 「Evaluation details」タブを選択することで、各評価結果の分布図を確認可能
- より詳細に比較したい場合はこちらが有用
8 まとめ
re:Invent 2024開催前日に発表されたKnowledge Base Evaluationを用いて、Knowledge Baseの定量的な評価を実施しました。
- Bedrock Knowledge Basesがすでに存在すれば、複雑な設定なしに評価の実行が可能
- 複数の評価ジョブを比較可能
- 評価結果、比較結果はマネージドコンソールからグラフィカルに確認することが可能
- 今回は未記載だが、API/SDK経由で評価結果を取得可能
おわりに
同様の評価はRagasなどを用いて、これまでも実現できましたが、事前に評価ツールなどの準備が必要でした。今回の機能追加でAWSの1機能としてLLM as a Judgeによる定量的評価ができるため、AWS上にある既存のKnowledge Basesを簡単に評価することができるようになりました。