自己紹介と参加した理由
はじめまして、@libru1 (りぶりゅわん)こと、リブリュと申します。
改訂版ではありませんが、チェリー本お世話になっております。
自分が思うRubyっぽさが出せたらと思い、チャレンジさせていただきます。
プルリクエスト
はじめに
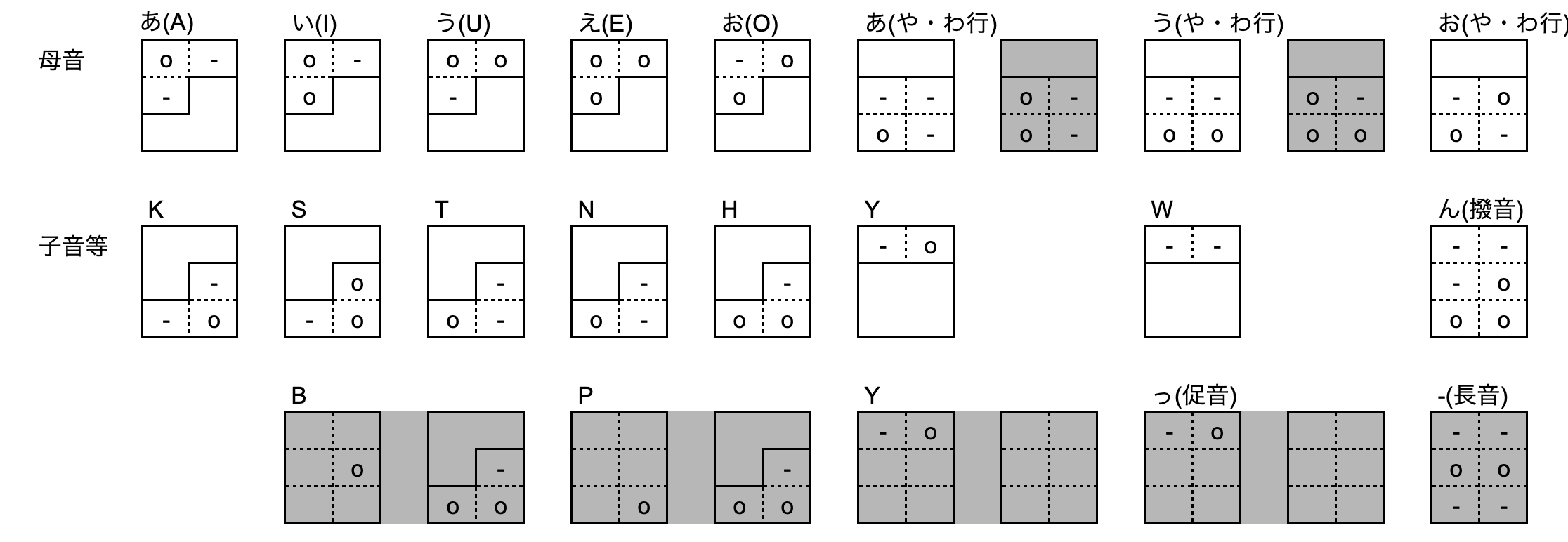
お題の点字ですが、身の回りで見かける事も多いし、ポケモンや国語の教科書などで興味を持った方もいらっしゃると思います。私は缶飲料や家電の文字を読みたいと思って図書室で調べました。数字、文字、アルファベット色々ありましたが、規則性があったので50音はほぼ一日で覚えました。母音、子音、濁点などの組み合わせを6つの点で表現していました。この組み合わせ部分を2進数のビット演算を用い作成しました。
変換の流れ
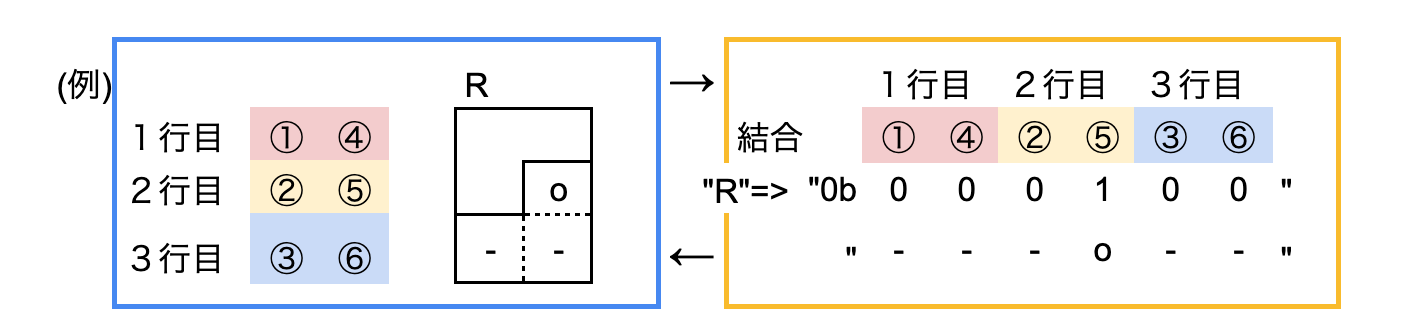
・ローマ字ごとに変換テーブルを用意します。
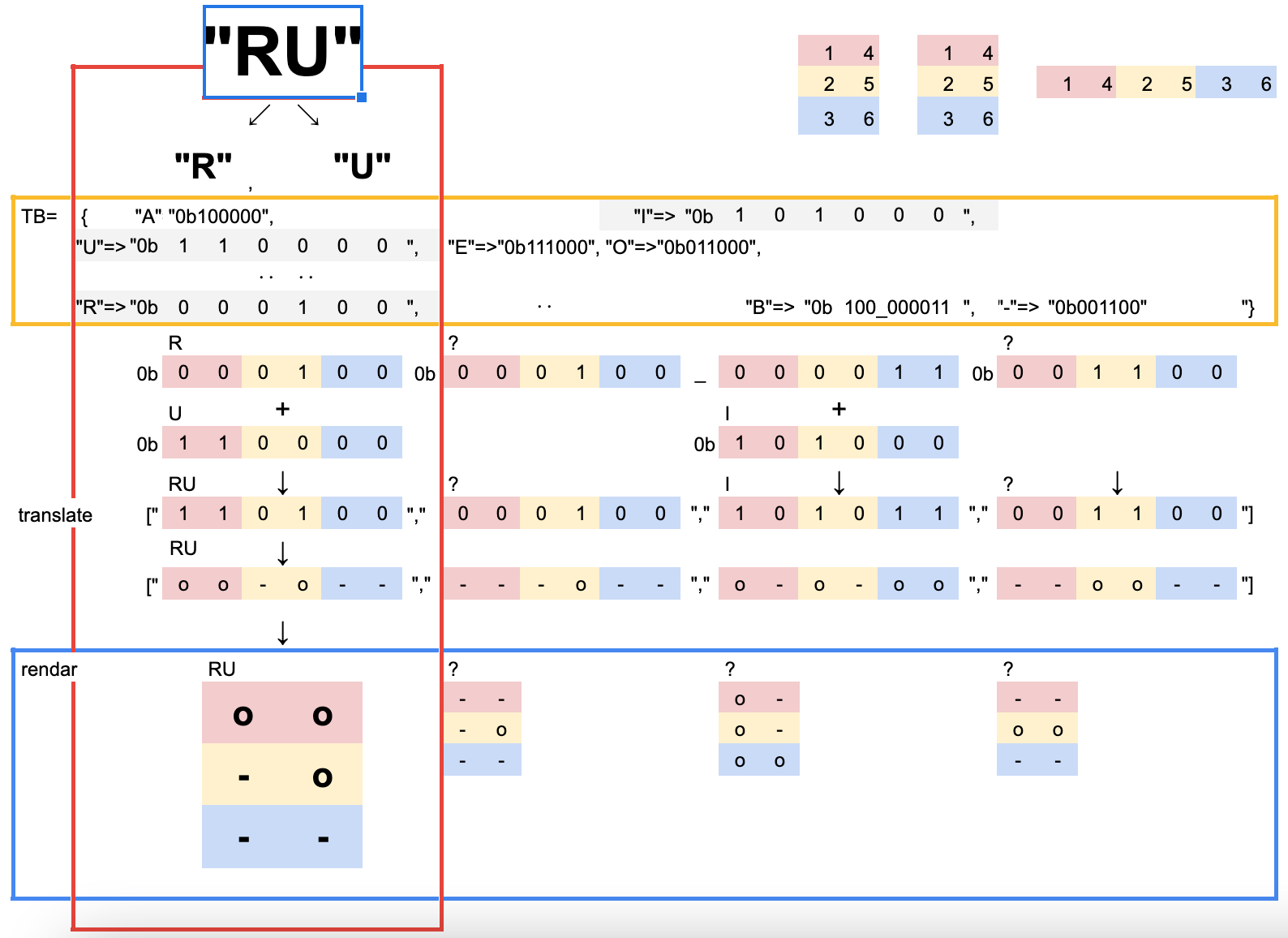
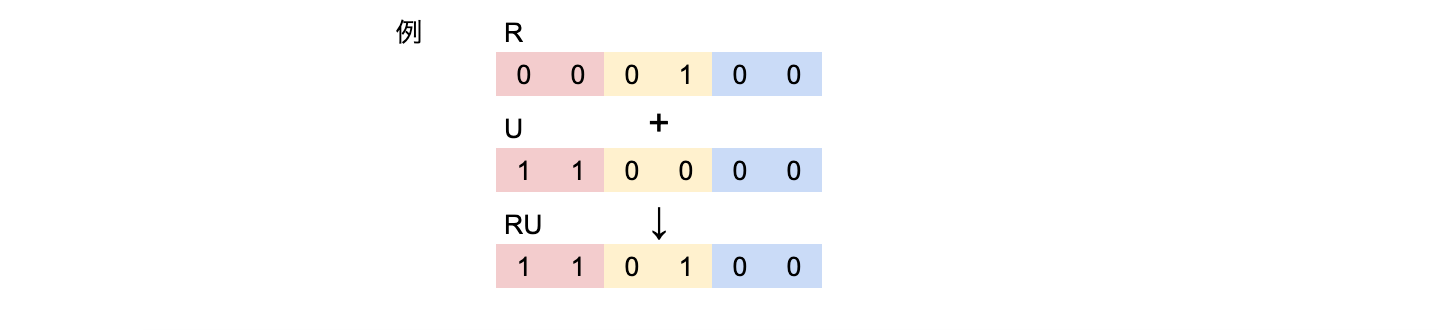
・変換ルールは以下の通り、3行2列を横1行6列にし、演算を施した後戻します。
ロジックの解説
メイン処理
to_tenjiの流れと、実行時のイメージを解説します。
def to_tenji(text)
letters = split_and_normalize_letter text
tenji = translate_letters_to_tenji letters
render tenji
end
文字化けに悩んだ事もありコメントがありません。1ステップずつ解説します。
letters = split_and_normalize_letter text
・渡された文字列をスペースで区切り配列にします。
・また、その際にハッシュ(変換テーブル)を利用出来る形(後述normalize)にします。
tenji = translate_letters_to_tenji letters
・ローマ字の配列から文字を取り出し、以下のルールで点字を結合した6桁の点字文字列の配列にします。
(例) ["A", "HI", "RU"] → ["o-----", "o-o-oo", "oo-o--"]
render tenji
点字文字列を2文字ずつに分割して、1行目、2行目、3行目に分けて改行で接続します。
最初配列をputsでいけるかと思いましたがテストが通らなかった為文字列にしました。
(例) ["o-----", "o-o-oo", "oo-o--"] → "o- o- oo¥n-- o- -o¥n-- oo --"
メインから呼び出されている処理
def normalize(letter)
case letter
when /^[YW]/
letter.capitalize
when /.[Y]/
letter.sub(/Y/,'y')
when /N$/
letter.rjust(2,letter).downcase
else
letter
end
end
ローマ字を一文字ずつ処理する際、ナ行の"N"と撥音のンの"N"や、ヤ行、ワ行の母音と通常の母音、ヤ行の"Y"と拗音の"Y"など、同じ文字でありながら、点字の点の位置が異なるため調整して区別しています。
(例) 'HI NA WA N' → ["HI", "NA", "Wa", "nn"]
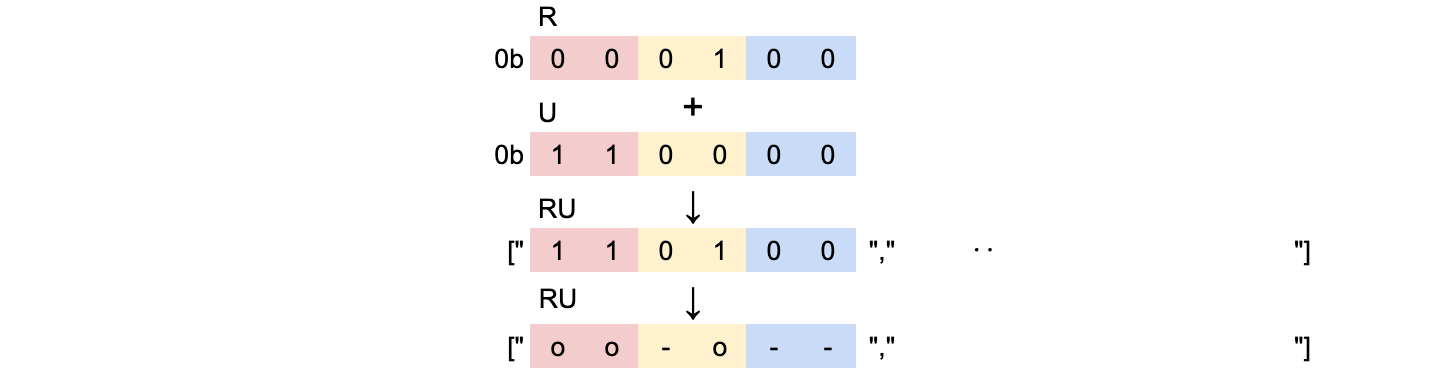
def translate(letter)
val = letter.scan(/./).map{|c| TB[c]}.inject(:|).to_s(2)
len = (val.length > 6) ? 12 : 6
(val.chars.map &{"0"=>"-","1"=>"o"}).join.rjust(len,'-')
end
・ローマ字を一文字ずつハッシュより変換し、それそれの値を足します
・2進数の文字列にし、"0"を"-"に、"1"を"o"にマッピングします
・2進数の桁に合わせ、点字一文字に6つの点、6の倍数になるように"-"を付加します
def split_and_normalize_letter(text)
text.split(' ').map {|letter| normalize letter}
end
・受け取ったテキストをスペースで区切り、文字の配列にします
def translate_letters_to_tenji(letters)
letters.map {|letter| (translate letter).scan(/.{6}/)}.flatten
end
・点字(一文字に6つの点)毎に配列にします。今回のお題では範囲外ですが、濁音、半濁音、拗音などは二文字分となるため、最後にflattenで平準化しています。
def render(tenji)
(0..2).map {|i| tenji.map {|s| s.slice(i * 2,2)}.join(' ')}.join("\n")
end
・点字を組み立てる

以上です
工夫したところ
いろいろやりたくなって複雑化してしまうところ、割り切ってシンプルに
「なるべく」以下の事を目指しました。
・1画面に収まる
・左から右に読めるように
・英文っぽく
仕様を満たすプログラムを作成した後、ロジックはそのままに、ハッシュテーブルにキーと値を
追加すると、濁音、半濁音、拗音(長音は"RU BI -"という表記なら)まで対応しました。
仕様に無いので関係ありませんが、仕様を拡大したら一番シンプルだと思います。
感想
プログラムはすぐ作れたのですが、記事が作成できません。
説明も難しいし、図も切り貼りしたり難しいです。
githubも初めてで不慣れで時間かかってしまいました。
文字化けにも悩まされ、ソースが戻ってしまいました。
文字化けの別記事を書きたいくらいです。
伊藤さんにメッセージ
「チェリー本改訂版」発売おめでとうございます。改訂前のチェリー本でテストの解説があったのですが、実際にminitestしたのは初めてです。用意していただいたテストケース、本当に勉強になりました。テストケースの選び方、記述方法等今後とも参考にさせていただきます。