あのURLで見たBASE64の名前を僕達はまだ知らない。
あれは BASE64URL Encoding と言うらしい。
(どれだよ)
- Base64#変形版 - Wikipedia
URLアプリケーションのための変形 Base64
('base64url' encoding)
概要
BASE64 でエンコードした文字列には、 URL 上で意味を持つ + 、 / 、 = が含まれている。そのため URL で利用するためには工夫が必要である。BASE64 には BASE64URL Encoding と言う変形版が公式仕様にあり、URL Encoding や Percent Encoding よりも、URL上で利用するには都合が良い様に感じた。
今回WEBアプリで BASE64URL Encoding を扱うにあたり、ついでに BASE64 の自体も実装をしてみようと思い、やってみた、そんな話。
BASE64の解説
① BASE64 (original)
読んでみると超シンプルな代物。
- Base64 - Wikipedia
- バイナリ全体をbitの配列 (bit stream) として捉え、6bit ずつ区切り、対応する文字列に置き換える。
- 6bit = 2^6 = 64 (⇒ 64文字種)
- 文字テーブル:
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
(64文字種) - 3btyte (24bit) ずつ処理し、4byteに伸長する。※ 24は8と6の最小公倍数。
- 不足するbitは0で埋める。
- 不足するbyteは
=文字で埋める。 - 必ず文字列長は4の倍数になる。

コーディングの前に視覚化して整理するのも良いと思う。
② BASE64 URL Encoding (URL安全なBASE64)
BASE64 の仕様 RFC 4648 内で Section 5 「Base 64 Encoding with URL and Filename Safe Alphabet」 にて定義されている。
・RFC 4648 - The Base16, Base32, and Base64 Data Encodings #Section-5 Base 64 Encoding with URL and Filename Safe Alphabet
-
+、/、=はURL上意味を持つ記号のため、それらの文字を回避したもの。 (URL上の役割は割愛。) - 62番
+⇒-で表現する。 - 63番
/⇒_で表現する。 -
=によるパディングは行わない。
結構シンプルで、ほぼ一緒。
|#|bit|hex|BASE64|BASE64URL|#|bit|hex|BASE64|BASE64URL|
|:|:--|:--|:-----|:--------|:|:--|:--|:-----|:--------|
|0|00000000|0x00|A|A|32|00100000|0x20|g|g|
|1|00000001|0x01|B|B|33|00100001|0x21|h|h|
|2|00000010|0x02|C|C|34|00100010|0x22|i|i|
|3|00000011|0x03|D|D|35|00100011|0x23|j|j|
|4|00000100|0x04|E|E|36|00100100|0x24|k|k|
|5|00000101|0x05|F|F|37|00100101|0x25|l|l|
|6|00000110|0x06|G|G|38|00100110|0x26|m|m|
|7|00000111|0x07|H|H|39|00100111|0x27|n|n|
|8|00001000|0x08|I|I|40|00101000|0x28|o|o|
|9|00001001|0x09|J|J|41|00101001|0x29|p|p|
|10|00001010|0x0A|K|K|42|00101010|0x2A|q|q|
|11|00001011|0x0B|L|L|43|00101011|0x2B|r|r|
|12|00001100|0x0C|M|M|44|00101100|0x2C|s|s|
|13|00001101|0x0D|N|N|45|00101101|0x2D|t|t|
|14|00001110|0x0E|O|O|46|00101110|0x2E|u|u|
|15|00001111|0x0F|P|P|47|00101111|0x2F|v|v|
|16|00010000|0x10|Q|Q|48|00110000|0x30|w|w|
|17|00010001|0x11|R|R|49|00110001|0x31|x|x|
|18|00010010|0x12|S|S|50|00110010|0x32|y|y|
|19|00010011|0x13|T|T|51|00110011|0x33|z|z|
|20|00010100|0x14|U|U|52|00110100|0x34|0|0|
|21|00010101|0x15|V|V|53|00110101|0x35|1|1|
|22|00010110|0x16|W|W|54|00110110|0x36|2|2|
|23|00010111|0x17|X|X|55|00110111|0x37|3|3|
|24|00011000|0x18|Y|Y|56|00111000|0x38|4|4|
|25|00011001|0x19|Z|Z|57|00111001|0x39|5|5|
|26|00011010|0x1A|a|a|58|00111010|0x3A|6|6|
|27|00011011|0x1B|b|b|59|00111011|0x3B|7|7|
|28|00011100|0x1C|c|c|60|00111100|0x3C|8|8|
|29|00011101|0x1D|d|d|61|00111101|0x3D|9|9|
|30|00011110|0x1E|e|e|62|00111110|0x3E|+|-|
|31|00011111|0x1F|f|f|63|00111111|0x3F|/|_|
||||||pad|n/a|n/a|=|n/a|
実装
① BASE64 ⇔ BASE64URLの相互変換
- BASE64 Safe URL Convert.(Java) | Online editor and compiler
/**
* URL安全なBASE64に変換.
*
* @param base64
* @return base64url
*/
private static String convertBase64SafeUrl(final String base64) {
if(base64 == null) {
return null;
} else {
String ret = base64;
ret = ret.replaceAll("\\+", "-");
ret = ret.replaceAll("\\/", "_");
ret = ret.replaceAll("=+$", "");
return ret;
}
}
/**
* 通常 (URL非安全) のBASE64に変換.
*
* @param base64url
* @return base64
*/
private static String convertBase64UnSafeUrl(final String base64url) {
if(base64url == null) {
return null;
} else {
String ret = base64url;
ret = ret.replaceAll("-", "+");
ret = ret.replaceAll("_", "/");
ret += "===";
ret = ret.substring(0, ((ret.length() / 4) * 4));
return ret;
}
}
url safe :8KCut/CfpJTwn42G8J+RjQ== (24) >>>> 8KCut_CfpJTwn42G8J-RjQ (22)
url unsafe :8KCut_CfpJTwn42G8J-RjQ (22) >>>> 8KCut/CfpJTwn42G8J+RjQ== (24)
url safe :01234=== (8) >>>> 01234 (5)
url safe :012345== (8) >>>> 012345 (6)
url safe :0123456= (8) >>>> 0123456 (7)
url safe :01234567 (8) >>>> 01234567 (8)
url safe :a+/b==a+/b++a+/b//a+/b==a+/b==a+/b== (36) >>>> a-_b==a-_b--a-_b__a-_b==a-_b==a-_b (34)
url safe :a+/b==a+/b++a+/b//a+/b==a+/b==a+/b (34) >>>> a-_b==a-_b--a-_b__a-_b==a-_b==a-_b (34)
url unsafe :01234 (5) >>>> 01234=== (8)
url unsafe :012345 (6) >>>> 012345== (8)
url unsafe :0123456 (7) >>>> 0123456= (8)
url unsafe :01234567 (8) >>>> 01234567 (8)
url unsafe :012345678 (9) >>>> 012345678=== (12)
url unsafe :a-_b==a-_b--a-_b__a-_b==a-_b==a-_b (34) >>>> a+/b==a+/b++a+/b//a+/b==a+/b==a+/b== (36)
url unsafe :a-_b==a-_b--a-_b__a-_b==a-_b==a-_b (34) >>>> a+/b==a+/b++a+/b//a+/b==a+/b==a+/b== (36)
url unsafe :?*+/-_=== (9) >>>> ?*+/+/====== (12)
文字列途中にある = については、そもそものルール違反のため、関知しない。
BASE64の文字についても、そもそものルール違反のため、関知しない。
元々末尾に = がついていた場合も、関知せずパディングを行う。
② BASE64のEncode/Decode
STEP① とりあえずBYTE配列をBASE64にするコードを作ってみる。
とりあえず、書いてみた。
-
6bitごとにbyte配列を整形する処理と文字列化するコードを分けて記述。 - 進数変換と同様の考え方。
今回のbitをbit maskで抽出し、前回余ったbitとを論理和で合成する。 -
今回余ったbitは 左シフトし、不用bitを落としておき、次回に持ち越す。 - 今回取り出すbitの右シフト量 (
v) は2,4,6の3パターン。 (⇒(((i % 3) + 1) * 2)) - 次回に持ち越すbitの左シフト量は右シフト量 (
v) に応じて求められ、4,2,0の3パターン。 (⇒(6 - v))- 上位2bitは落としておく。 左シフトのため下位bitは無視して良い。
public static byte[] convert6bitBinary(byte[] data) {
if(data == null) {
return data;
} else {
byte mod = 0x00;
List<byte> list = new List<byte>();
byte[] lowMaskList = new byte[] {
0x3F, // [0] 00111111
0x0F, // [1] 00001111
0x03, // [2] 00000011
};
for(int i = 0; i < data.Length; i++) {
int j = i % 3;
int v = ((j + 1) * 2);
byte lowMask = lowMaskList[j];
byte b0 = data[i];
byte b6 = (byte)(mod | (lowMask & (b0 >> v)));
list.Add(b6);
mod = (byte)(0x3F & (b0 << (6 - v)));
if(j == 2) {
list.Add(mod);
mod = 0;
}
}
if((data.Length % 3) != 0) {
list.Add(mod);
}
return list.ToArray();
}
}
public static string ToBase64(byte[] data, bool isUrlSafe = false) {
StringBuilder sb = new StringBuilder();
if(data != null) {
string base64_map;
if(isUrlSafe) {
base64_map = BASE64_MAP_URLSAFE;
} else {
base64_map = BASE64_MAP_BASIC;
}
foreach(byte b in data) {
sb.Append(base64_map[b]);
}
if(!isUrlSafe) {
int max;
sb.Append("===");
max = (sb.Length / 4) * 4;
sb.Remove(max, sb.Length - max);
}
}
return sb.ToString();
}
STEP② 4文字ごと に着目した処理を考え実装する。
BASE64は比較的古くからある仕様であり、展開や実装の容易さと言うのも兼ね備えていたと考える。なので、 = を用いたパディング は何のために必要なのか疑問語を覚えるが。これは逆説的に、4文字ごと に作業を行うことで、最適化が行える を可能性を感じられる。特に 4文字 で表現される 24 bit は 8 と 6 の 最小公倍数 である。即ち、3byte ずつ 4文字 にする のである。この程度であれば、下手にベタ書きしたした方が可読性もあり、 if文 も減り、高速化が望めそうである。そんな訳で、処理を見直して、Encode処理とDecode処理を組み直してみる。
※ 現在のPCのCPUは計算機の発展であり、計算が得意で条件分岐が苦手である。レガシーなPCでは限られたリソースで速度を得るため、条件分岐を省き効率よく処理を作る必要性が高かった。
Encode (BASE64化)
- 3byteずつ、
int配列[3]にコピーする。byteの長さを超えた場合は、9bit目だけが立っている0x0100にする。 -
int配列[3]からbyte配列[4]6bitずつ格納していく。- (1)
int配列[n]の9bit目をbyte配列[n]の7bit目に論理和。
※ 6bitに伸長した場合は7-8bit目は使わないので、存在しないバイトはbitを立てて64以上の値にする。 - (2) 上位ビットはカレントとして
int配列[n]の該当bitをbyte配列[n - 1]の該当bitへ左シフト + マスク (抽出)して 論理和 - (3) 下位ビットは不足分として
int配列[n - 1]の該当bitをbyte配列[n - 1]の該当bitへ右シフト + マスク (抽出)して 論理和 - 存在するバイト値は
0 ~ 63の値になる。
※0x0100の下位8bitが0なので、不足分で使われても問題ない。 - 存在しないバイト値は
64の値になる。
※ これも、0x0100の効果。
- (1)
-
byte配列の値を文字化して格納。- 通常の
BASE64では変換表の64番目に=を入れておき、条件分岐無くパディング行う。 - URL安全の
BASE64 URL場合は、64番目以上はスキップします。
- 通常の
private static readonly string BASE64_MAP_BASIC = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
private static readonly string BASE64_MAP_URLSAFE = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_";
public static string encode(byte[] data, bool isUrlSafe = false) {
StringBuilder sb = new StringBuilder();
for(int i = 0; i < data.Length; i += 3) {
int[] src = new int[3];
byte[] tgt = new byte[4];
//copy or default.
for(int j = 0; j < 3; j++) {
int k = i + j;
if(k < data.Length) {
src[j] = data[k];
} else {
//(bit: 0001 0000)
src[j] = 0x0100;
}
}
// reformat.
tgt[0] = (byte)((0x00) | (0x00) | (0x3F & (src[0] >> 2)));
tgt[1] = (byte)((0x00) | (0x3F & (src[0] << 4)) | (0x0F & (src[1] >> 4)));
tgt[2] = (byte)((0x40 & (src[1] >> 2)) | (0x3F & (src[1] << 2)) | (0x03 & (src[2] >> 6)));
tgt[3] = (byte)((0x40 & (src[2] >> 2)) | (0x3F & (src[2] << 0)) | (0x00));
// to character.
if(isUrlSafe) {
foreach(byte b in tgt) {
if(b < 0x40) {
sb.Append(BASE64_MAP_URLSAFE[b]);
}
}
} else {
sb.Append(BASE64_MAP_BASIC[tgt[0]]);
sb.Append(BASE64_MAP_BASIC[tgt[1]]);
sb.Append(BASE64_MAP_BASIC[tgt[2]]);
sb.Append(BASE64_MAP_BASIC[tgt[3]]);
}
}
return sb.ToString();
}
結構条件分岐が減って、良い感じ。また、符号化には最低でも2文字必要になるため、1-2文字目用のパディング判定処理は省いている。
Decode (BASE64からの復号)
通常の BASE64 と URL安全の BASE64 URL どちらでも復号ができる様にしている。
-
文字列からbyte配列[4]に値を格納する。存在しないbyte値は、64にする。- 通常の
BASE64では変換表の64番目に=を入れておき、こちらも64になる。 - 値が見つからなかった時は、URL安全の
BASE64 URLの変換表も探索し、-_を補完する。
- 通常の
-
byte配列[4]からint配列[3]へ 8bitずつ格納していく。- (1)
byte配列[n + 1]の7bit目をint配列[n]の9bit目に論理和。 - (2) 上位ビットはカレントとして
byte配列[n]の該当bitをint配列[n]の該当bitへ左シフト + マスク (抽出)して 論理和 - (3) 下位ビットは不足分として
byte配列[n + 1]の該当bitをint配列[n]の該当bitへ右シフト + マスク (抽出)して 論理和 - 存在するバイト値の場合 byteの範囲を内の
0 ~ 255の値になり、バイナリに追加する。 - 存在しないバイト値の場合、byteの範囲を超えた
256 (0x0100)の値になり、バイナリに追加しない。
- (1)
private static readonly string BASE64_MAP_BASIC = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
private static readonly string BASE64_MAP_URLSAFE = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_";
public static byte[] decode(string base64) {
List<byte> list = new List<byte>();
if(!string.IsNullOrEmpty(base64)) {
for(int i = 0; i < base64.Length; i +=4) {
byte[] src = new byte[4];
int[] tgt = new int[3];
for(int j = 0; j < 4; j++) {
int k = i + j;
byte code;
if(k < base64.Length) {
char c = base64[k];
int index = BASE64_MAP_BASIC.IndexOf(c);
if(index < 0) {
index = BASE64_MAP_URLSAFE.IndexOf(c);
}
code = (byte)index;
} else {
// 01000000 (64)
code = 0x40;
}
src[j] = code;
}
tgt[0] = (0x00) | (0xFC & (src[0] << 2)) | (0x03 & (src[1] >> 4));
tgt[1] = (0xFF00 & (src[2] << 2)) | (0xF0 & (src[1] << 4)) | (0x0F & (src[2] >> 2));
tgt[2] = (0xFF00 & (src[3] << 2)) | (0xC0 & (src[2] << 6)) | (0x3F & (src[3] >> 0));
foreach(int val in tgt) {
if(val < 0xFF) {
list.Add((byte)val);
} else {
break;
}
}
}
}
return list.ToArray();
}
こちらも変換表の64番目に = を追加して64以上を使うことで、処理を少し簡略化出来ている感がある。
また、復号には最低でも2文字必要になるため、1byte目の復号には存在チェック用のbit処理を省いている。
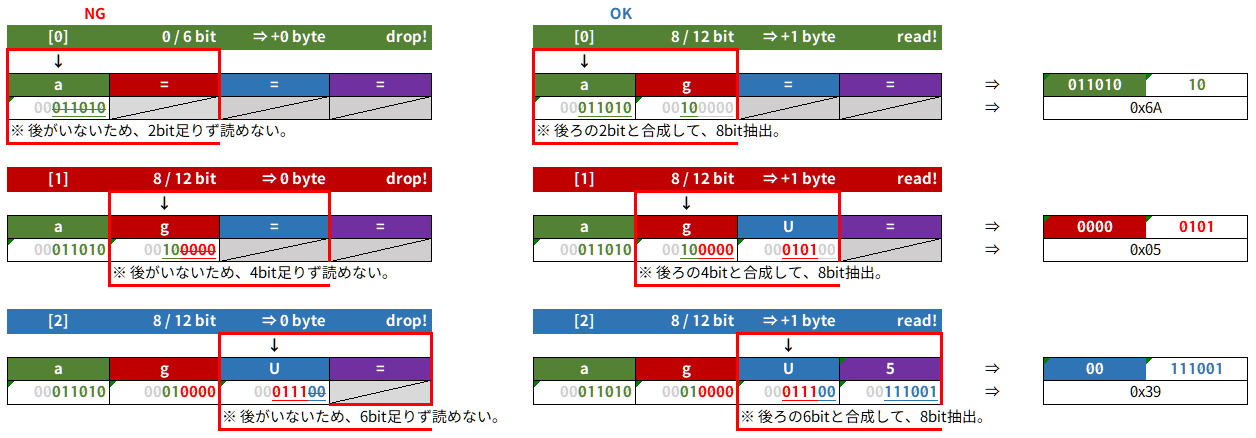
本来 = 前の文字の場合は更にその前の余りを含んでいるので、
- 1文字の場合 ⇒ BASE64上ありえない
(=で3文字パディング。) - 2文字の場合 ⇒
=の 前の文字の下位4bitが0 (=で2文字パディング。) - 3文字の場合 ⇒
=の 前の文字の下位2bitが0 (=で1文字パディング。) - 4文字の場合 ⇒ 余りなし (
=でパディングする必要もなし。)
な感じになる。
実行例
- BASE64 scrap (C#) | Online editor and compiler
// check strs[0]-------------------------------------------------------
#source
str : Hellow C#
bin (hex) : 48 65 6C 6C 6F 77 20 43 23
bin (bit) : 01001000 01100101 01101100 01101100 01101111 01110111 00100000 01000011 00100011
#encode
base64 : SGVsbG93IEMj
base64url : SGVsbG93IEMj
#decode (basic) SGVsbG93IEMj
bin (hex) : 48 65 6C 6C 6F 77 20 43 23
bin (bit) : 01001000 01100101 01101100 01101100 01101111 01110111 00100000 01000011 00100011
str : Hellow C#
#decode (urlsafe) SGVsbG93IEMj
bin (hex) : 48 65 6C 6C 6F 77 20 43 23
bin (bit) : 01001000 01100101 01101100 01101100 01101111 01110111 00100000 01000011 00100011
str : Hellow C#
// check strs[1]-------------------------------------------------------
#source
str : BASE64-
bin (hex) : 42 41 53 45 36 34 2D
bin (bit) : 01000010 01000001 01010011 01000101 00110110 00110100 00101101
#encode
base64 : QkFTRTY0LQ==
base64url : QkFTRTY0LQ
#decode (basic) QkFTRTY0LQ==
bin (hex) : 42 41 53 45 36 34 2D
bin (bit) : 01000010 01000001 01010011 01000101 00110110 00110100 00101101
str : BASE64-
#decode (urlsafe) QkFTRTY0LQ
bin (hex) : 42 41 53 45 36 34 2D
bin (bit) : 01000010 01000001 01010011 01000101 00110110 00110100 00101101
str : BASE64-
// check strs[2]-------------------------------------------------------
#source
str : 𠮷🤔🍆👍
bin (hex) : F0 A0 AE B7 F0 9F A4 94 F0 9F 8D 86 F0 9F 91 8D
bin (bit) : 11110000 10100000 10101110 10110111 11110000 10011111 10100100 10010100 11110000 10011111 10001101 10000110 11110000 10011111 10010001 10001101
#encode
base64 : 8KCut/CfpJTwn42G8J+RjQ==
base64url : 8KCut_CfpJTwn42G8J-RjQ
#decode (basic) 8KCut/CfpJTwn42G8J+RjQ==
bin (hex) : F0 A0 AE B7 F0 9F A4 94 F0 9F 8D 86 F0 9F 91 8D
bin (bit) : 11110000 10100000 10101110 10110111 11110000 10011111 10100100 10010100 11110000 10011111 10001101 10000110 11110000 10011111 10010001 10001101
str : 𠮷🤔🍆👍
#decode (urlsafe) 8KCut_CfpJTwn42G8J-RjQ
bin (hex) : F0 A0 AE B7 F0 9F A4 94 F0 9F 8D 86 F0 9F 91 8D
bin (bit) : 11110000 10100000 10101110 10110111 11110000 10011111 10100100 10010100 11110000 10011111 10001101 10000110 11110000 10011111 10010001 10001101
str : 𠮷🤔🍆👍
// check 1st impl.
encode : 6A 05 39 => agU5
encode : 6A 05 => agU=
encode : 6A => ag==
encode : 6A 05 39 => agU5
encode : 6A 05 => agU
encode : 6A => ag
decode : agU5 => 6A 05 39
decode : agU= => 6A 05
decode : ag== => 6A
decode : a=== =>
decode : agU5 => 6A 05 39
decode : agU => 6A 05
decode : ag => 6A
decode : a =>
// check 2nd impl.
encode : 6A 05 39 => agU5
encode : 6A 05 => agU=
encode : 6A => ag==
encode : 6A 05 39 => agU5
encode : 6A 05 => agU
encode : 6A => ag
decode : agU5 => 6A 05 39
decode : agU= => 6A 05
decode : ag== => 6A
decode : a=== =>
decode : agU5 => 6A 05 39
decode : agU => 6A 05
decode : ag => 6A
decode : a =>
BASE64URL の活用法
私が今回使おうと思った背景では、Servlet のWEBアプリケーションで ChromeのAcrobat拡張 を利用するために、リクエストをURLに再現性のない POST から再現性のある GET に変更しようと思ったのがある。パラメータは複数あり、あまり生で見せたくないというのもあり、全パラメータをまとめて BASE64 での シリアライズ を行うことにした。
ChromeのAcrobat拡張 ではURLを再度開いているだけのため、再現性のあるURLである必要がある。これはfirefoxで内蔵ビューアで開いたPDFをオンザフライでAdobeReaderなどに開かせる際も同様かと思う。
GETによるアプリケーション連携が増えている昨今。一時的なリクエストにせよ、GET化することのメリットがそれなりに出てきている。
と言うか、私は パーマネント リンク大好きマン なので参照メインのサイトで パーマネント リンク 取れない時に結構キレてます。えぇ、最近のアニメ公式サイトとか多いですね。。。すっごいゴテゴテで、友人にshareしようとしたら、 パーマネント リンク が取れなくてTOPページしか送れないこととか。。。
ダイミダラーの公式サイト を見習って欲しい
(そういう意味ではFLASHが死に絶えたのはほんと、良かったのかも知れない。FLASHだけで作ってるサイトも度々あったので)
パーセント エンコーディング や URI エンコーディング じゃダメだったのか? 
パーセント エンコーディング 及び URI エンコーディングはどんな文字列にもエンコード/デコードを処理をかけることができ、符号化/復号化がブラウザやWEBサーバーのリクエスト処理に含まれてしまっている。そのため、間に認証ページなどでジャンプが挟まる様な場合、ジャンプ数を加味して多重でパーセント エンコーディングをかけたりする必要がある場合がある。特に = が含まれている場合には、多段でジャンプ中にQueryStringとして前のページでのパラメータとして喰われてしまい、自分のページに届かない、なんてこともある。BASE64 の場合は + / により、多段ジャンプ自体が阻害される場合もある。
BASE64URL では自分で展開処理を行わなければいけないデメリット自体がそのままメリットとなり、他のページとの競合を避けることができる。誰も勝手に復号したりしないので、最後までそのまま自分のところに届く。
多段ジャンプ(笑) と思うこともあるかも知れないが。案外Twittterの認証など色々画面見てても、結構パラメーターを引きずっていることが多くあると思い、そんなにマイノリティでは無いかと思う。
HTTPのリクエストのセキュリティは、GET 以上のものが POST で得られるもんでも無いと思うので、もっと別の形で確保してください。
(だから認証でも GET を使っているのでしょう。)
総括
ベンチマークは取らないが、BASE64の実装をして理解を深めることが出来たと思います。とてもシンプルなロジックなので、一度自分で書いてみるのは、bit演算の訓練にもなって良いかと思った。あと、行数によってはベタに書くことも悪く無く、今回の BASE64 もその類なのかと思う。
なお、JavaとC#が混在しているのは単に気分です。( 当方、final教信者 の C#er です )。
参考 (謝辞)
-
Base64 - Wikipedia
https://ja.wikipedia.org/wiki/Base64 -
RFC 4648 - The Base16, Base32, and Base64 Data Encodings
https://tools.ietf.org/html/rfc4648