1.Amazon Redshift とは
データウェアハウスサービスです。
・データウェアハウスサービスって何よ!
データウェアハウスサービスとは、企業経営の中で時系列に蓄積されたデータの中から、各項目にある関連性を分析するためのシステムです。
たとえば、コンビニの売上データから「月曜日にお弁当を購入する20代の男性は野菜ジュースなどの健康食品を購入していることが多い」や、「雨の日に最も売れる商品は傘」など従来の単純なデータ集計では発見できなかった各データ間の関連性を洗い出すことができます。
RDBMSとは違って、継続的な書き込みや更新には向いておらず、一括でデータを書き込み分析のため大容量データを読み出すという処理に最適化されています。
Amazon Redshiftでは、大量のデータを短時間で読み出し・分析することが可能です。
2.特徴
-
超並列処理アーキテクチャを列志向ストレージおよび自動圧縮と組み合わせて採用しているため、ペタバイト規模のデータセットに対して非常に高速なクエリパフォーマンスを提供することができます。
年間でテラバイトあたり1000ドル/年で処理することができ、従来のデータウェアハウスソリューションの1/10のコストらしい。カラム型データベース。
・並列処理とは?
並列処理とは、一つのタスクをより小さなサブタスクに細分化し、複数のプロセッサを用いてこれらを並列に処理することによって全体の処理効率向上を図る手法です。
・列指向データベースと行指向データベース
行指向:必要なデータを含むレコードを一旦全て取得した上で、特定の列のデータのみを取り出す必要がある。
列指向:特定の列に対するクエリに対しては、1列のデータを参照するだけで必要なデータを取り出すことができる。
よって、列指向の方が効率的となる。Redshiftは、書き込み回数が少なく、複雑なクエリを頻繁的に実行する場合に利用する。逆の場合はRDBMSを利用する。
-
redshift spectrumを使用するとS3のエクサバイトのデータに対して直接クエリを実行できます。
-
redshift クラスターを管理、モニタリング、スケールするための管理タスクのほとんどを自動化するのは非常に簡単です。これによりユーザーはデータとビジネスに集中できます。
-
セキュリティは組み込まれているため、強力な暗号化をデータに適用できます。
-
既に利用しているツールと互換性があります。標準のSQLがサポートされ、高パフォーマンスのJDBCコネクタとODBCコネクタが提供されているため、ユーザは好みのSQLクライアントやビジネスインテリジェンスツールを使用することができます。
-
ノードタイプを変更することでの、手動でのスケールイン・スケールアウトが必要。
3.料金
4.シングルノードとマルチノード
シングルノード
他のドライブとデータが冗長化されている場合、単一ドライブでの障害は自動復旧されサービス利用可能です。
自動復旧ができない場合スナップショットからの復旧が必要です。
なお、ロードされたデータは常時S3に自動的にバックアップされています。
マルチノード
ノード内でドライブが冗長されているので1つのドライブに障害が発生したとしても、冗長化による別のドライブの複製されたデータにより入出力が行われ、処理が続行されますのでサービス利用可能です。
他のドライブにデータの移動ができない場合はノード交換が自動的に行われデータは別のノードから復元されますがノード交換が終わるまではサービス利用不可となります。
このように、基本的にはマルチノードでの利用が高可用性として推奨されています。
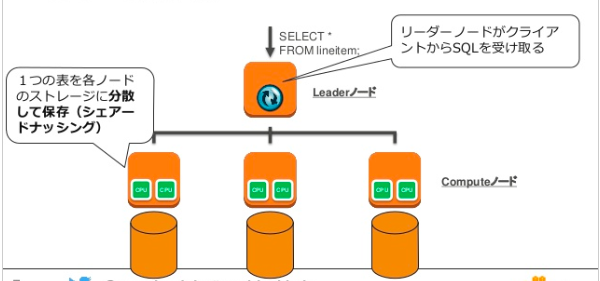
シングルノード構成の時は、リーダーノードがコンピューターノードを兼任します。
この場合、ノードが一つしかないため、並列処理(MPP)は行われません。
5.スナップショット
Redshiftがスナップショット用の無料ストレージを提供してますが、クラスターのストレージ容量を利用することになります。
スナップショットの空き容量の上限に達すると、通常の料金で追加のストレージに課金されてしまいます。
このため、自動スナップショットを保存し、それに応じて保存期間を設定する必要がある日数を評価し、不要になった手動スナップショットを削除する必要があります。
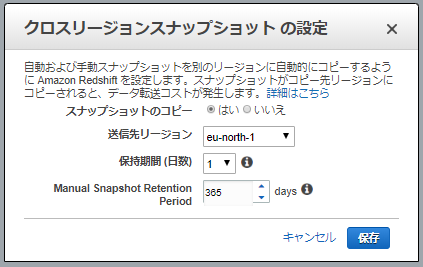
クロスリージョンスナップショット
別リージョンにコピーしておくことも可能です。なお、データ転送コストが発生する。
6.VPC拡張ルーティング
「VPC拡張ルーティング」を有効にすることにより、VPCにて設定しているルートテーブルに従った通信を行う。
7.クラスターセキュリティグループ
「お客様のアカウントは、このリージョンの EC2-Classic プラットフォームをサポートしていません。クラスターセキュリティグループは、EC2-Classic プラットフォームがサポートされている場合にのみ使用できます。クラスターへのアクセスを制御するには、代わりに VPC セキュリティグループを使用してください。EC2 コンソールに移動 を実行して VPC セキュリティグループを表示します。詳細については、サポートされているプラットフォームに関する Amazon Redshift ドキュメント および VPC でクラスターを管理するを参照してください。」
と表示されたので調べてみた。
要するに今はVPCセキュリティグループでいいみたい。
8.暗号化
- SSLを利用して、通信を暗号化する場合は、AWS ACMを利用して、証明書をクラスターにインストールする必要があります。
- クラスター作成時に、KMSを利用して暗号化することができます。RDS同様に後から暗号化することはできません。
9.Redshift Spectrum
S3バケットから、Redshiftへデータをロードせずに、S3バケット内のデータに対して直接クエリを実行できる機能です。
マルチノード構成以外に、Redshift Spectrumを利用し、S3に直せるクエリを実行させることで可用性を高めることも可能です。
なお、この機能を利用するには、S3とRedshift Spectrumの間に、Amazon Athenaによって作成されたAWS Glueデータカタログか、Apache Hiveメタストアが必要です。
10.コールドクエリ
- [Jun 2, 2020]Amazon Redshift がコンパイル時間を大幅に改善することで、コールドクエリのパフォーマンスが向上
- [Feb 1, 2021]Amazon Redshift のコールドクエリのパフォーマンスが、さらに 3 つの AWS リージョンで向上
Readshiftはクエリを受け取った際に、Leaderノードの方で、クエリのコンパイルを行って、clusterノードに配る動きをすることがあります。
Readshiftにはキャッシングの機能があるので、2回目以降同じクエリが投げられた場合は、キャッシュからその内容を返すので、コンパイル処理はいらないと。
ただ、初回時どうしてもコンパイル処理が入るので、初回のクエリのことを「コールドクエリ」と呼んでいる。
このアップデートで、コールドクエリのオーバヘッドが大幅に解消し、レイテンシが大きく抑えられるようになりました。
11.Data Sharing
Data Sharing とは、クラスタ間でライブデータを安全かつ簡単に共有できる
ライブデータ とは、データコピーを必要とせず、取得できるデータを指します。
ゆえに、クラスタ間で、データをコピーすることなく、クエリだけでデータアクセスができるようになる。
また、Data Sharing によりクエリ実行時には、データを共有される側のコンピューティングリソースが消費されるので、データを共有する側のクラスターのパフォーマンスが悪化することはありません。
[ on 11 MAR 2021 ]Amazon Redshift Data Sharing が一般提供開始となり、東京リージョンでもご利用可能
12.クロスデータベースクエリ
クロスデータベースクエリとは、クラスター内のDB間で、クエリ実行を行う。
接続しているDB間に関係なく、シームレスに他の任意のDBからデータを引っ張てこれるのでデータの結合が楽になります。
[Oct 15, 2020]Amazon Redshift でのクロスデータベースクエリを発表 (プレビュー)
13.demo
14.Redshift Serverless
Redshift Serverless は、ノード部分の綿密なキャパシティプランニング(ノード数やインスタンスタイプの決定)をする必要がなくなり、分析のためのクエリ実行時に自動でプロビジョニング・スケールしてくれる、というものです。
- 概要
- ハンズオン