■AWS Fargateって?#
Amazon EC2を利用した場合、インスタンスの管理もしなければいけない。
コンテナ、アプリケーションのことだけを考えたい。
そのために、開発されたのが、AWS Fargate
なので、
インスタンスの管理が不要になる。
そして、EC2の場合はリソースが余っていた場合も課金されていたが、本当に利用した分のみの課金となり、コスト削減へと繋がります。
要するにサーバレスの考え方です。
■EC2起動タイプとの違い#
仕組み##
事前にEC2インスタンスを起動し、ECSのタスクを起動していました。

Fargateではフルマネージドのフレーム転送など単純な処理をする(データプレーン)が提供されます。
そのため、事前にEC2インスタンスを起動する必要がありません。インスタンスを気にせず、集中できるようになります。

- 下記のような用途では、EC2起動タイプが適する
- GPUサポート
- Windows コンテナ
Auto Scalingの優位性##
| Fargate | EC2 |
|---|---|
| •Serviceのスケールに応じて自然にコンテナが起動・終了する • コンテナの起動時間に対してのみ課金 |
• インスタンスのリソースも上手くスケールさせる必要があり煩雑 • 余分に持っているバッファ分もインスタンスの課金が必要 |
- Fargateの方がシンプルとなる。
■価格#
| Fargate | Compute Savings Plans | Fargate Spot |
|---|---|---|
| 長期的なコミットなしで、コンテナに割り当てたリソースの秒単位での従量課金 | 1年間もしくは3年間での1時間あたりの利用金額をコミットすることで、大幅な割引を受けます。 | 空きキャパシティのリソースをFargateの標準価格の最大70%割引で利用できます。 |
■CPU、メモリ割り当て#
| タスクレベル(必須) | コンテナレベル(オプション) |
|---|---|
| • タスクに使用されるCPUとメモリの合計値 • CPU、メモリ共にハード制限 |
• cpu: コンテナ用に予約する cpu ユニット数 • memory: コンテナに適用されるメモリ量(MiB)のハード制限、これを超えようとすると強制終了 • memoryReservation: コンテナ用に予約するメモリのソフト制限(MiB) |
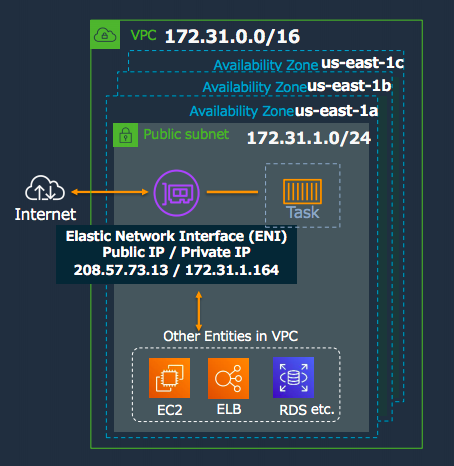
■ネットワークモード#
ECSでFargate起動タイプを使用する場合は、awsvpcモード を利用することとなる。
-
タスク毎にENIが自動的に割り当てられる。
-
セキュリティグループをタスク毎に設定することが可能になる。
-
VPC Flow Logsでのモニタリングができる。
-
localhost I/Fを共有して、タスク内のコンテナ同士が通信することが可能。
-
VPC内の他のリソースへプライベートIPで通信可能。
◼︎タスク実行ロール#
- Fargate 起動タイプでは以下の目的に必要なポリシーをアタッチ
- コンテナイメージをプルするための Amazon ECR の呼び出し
- コンテナアプリケーションログを保存するための CloudWatch の呼び出し
- これには、管理ポリシー AmazonECSTaskExecutionRolePolicy を利用可能
■同時実行数#
- Fargate On-Demand
- Amazon ECS タスク
- Amazon EKS ポッド
- Fargate Spot
- Amazon ECS タスク
のリソースの同時実行数が、1000までに増加。
[2021/02/16]AWS Fargate がデフォルトのリソース数サービスクォータを 1000 に増加
■Fargateのベストプラクティス#
1.ストレージ
消えては困るデータは外部ストレージに残し、内部のコンテナには残さない!
では、なぜ内部に残さないほうがいいのか?
EBSやEFSをマウントすることはできないので、
書き込み可能なストレージは、
レイヤーストレージ
ボリュームストレージ
の2種類です。
これらは、停止したら消えてしまうため、アプリケーションをステートレスな作りにすることが重要。
2.ログ
Dockerコンテナ全般のこととなりますが、コンテナ内で動かすアプリケーションが吐き出すログのうち、後から参照する必要があるものを全て、標準出力、標準エラー出力に送ること。
FargateはネイティブにCloudWatch Logsへのログ書き出しをサポートしているため、これを利用しましょう!
CloudWatch Logsを使うための注意は2つ。
・タスク実行ロールに
logs:CreateLogStream
logs:PutLogStream
を追加する。
・CloudWatch Logs のロググループは、事前に作成しておくこと。
3.メトリクス
CloudWatch でネイティブに確認できるFargateのメトリクスはサービスレベルのCPU/メモリ/使用率。
なので、
以下のような情報をとりたい場合は、”タスクメタデータエンドポイント”を使う。
・タスクメタデータ:タスクについての情報が取れる。
・統計データ:CloudWatchの標準より詳細な情報が取得できる。
4.分散トレーシング
そもそも分散トレーシングて?
分散トレーシングとは、分散されたシステム間でやり取りされる処理を追跡するための考え方やそれを実現された仕組みのこと。
なので、
アプリケーションで発生したエラーや障害の原因特定。
パフォーマンス問題の原因特定
がしやすくなる。
5.スケーリング
”Target Tracking”を利用する!
設定そのものはメトリクスに対してターゲットとなる値を設定するだけです。
↓
この指定した値に近づくように Application Auto Scalling が自動的にサービスの DesiredCount(クラスターで実行する同時タスクの数)を調整してくれます。
6.サービスディスカバリ
サービス間の連携にELBとECSサービスディスカバリを利用する。
そもそもサービス間の連携て?
名前によって解決されたIPアドレスやポートをもつタスク間通信のことを指します。
2種類のサービスディスカバリがある。
・ロードバランサベース
ECSサービスがタスクを起動したうえで、ターゲットグループに登録し、停止時は登録を解除します。
呼び出し元のサービスは、ロードバランサのDNS名で宛先を解決する。
・DNSベース
ECSサービスがタスクを起動したうえで、レコードを追加し、停止時は削除します。
呼び出し元のサービスは、相手方の名前を使って宛先を解決する。
例として、
ユーザーからのアクセスがあるサービスはロードバランサベース、
VPN間のサービスについてはDNSベース
を使うなど。。。
更にセキュリティグループの設定が、ロードバランサベースとDNSベースで異なるので次の項目で見ていきましょう。
7.サービス間のアクセス制御
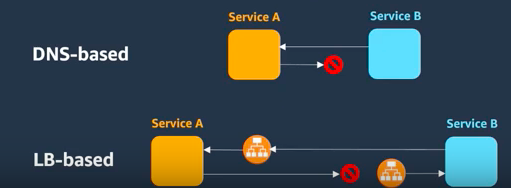
上記の通り、
DNSベースの場合は、相互のサービスを直接意識した設計となります。
ロードバランサベースの場合は、トラフィックを送受信するのが、ロードバランサになるため、ロードバランサのセキュリティグループで考慮する必要があります。。