防衛装備庁主催の第3回空戦AIチャレンジに参加しました。3ヶ月間苦戦した結果銀メダルで、金メダルまであと一歩で悔しかったけど、特別賞を受賞していただきました。下記で少し思いを共有します。
どのようなコンペ
- 強化学習で2機対2機の空戦
- 実際は強化学習を使わずにルールベースだけでも全然OK
なぜ苦戦した
- 配布されたソースコードとドキュメントの量が多くて、理解するだけで1週間かかった
- 座標系について全く知らなくて、ChatGPTに聞きながら3次元ベクトル処理のことを勉強
- パソコンのスペックがそこまで良くなくて、1回の訓練 + その後の結果確認や検証だけで2-3日かかったので、実装したかったことが多いけど時間がない
何のモデルを作った
- ルールベース + 強化学習、強化学習はやはり限界があるので、ルールベースのオーバーライドを加えると、強化学習がうまく行かない時にも撃墜や墜落などの一番まずい結果がある程度回避できる
- ルールベースで一部のアクションを制御することによって、強化学習の方で制御するアクションがより精度よく(アクションスペースを細かく分ける)学習できる
銀メダル獲得の工夫
- 配布されたドキュメントを全部読む、基本の基本だけど仕様がわからないと後々苦しくなるだけ
- 高速のPDCA、モデルを少し改善 ⇛ 訓練 ⇛ 検証 ⇛ 少し改善 ⇛ …、1回モデルを大幅に編集すると、結果が良くなっても実際の原因がわからない可能性が高い
- ネット資料を活用、外国のサイトで実際の戦闘機のスペックシートがあるので、それらを活用して戦闘機の性能を制御
うまく行かなかった部分
- 訓練環境で勝率を上がっても、実際のテスト環境・最後の評価環境と違って、勝率がかなり異なる
こちらは各バージョンのモデルで、訓練環境でベスト500回勝率とテスト環境・最後の評価環境のスコア

一致しているのは最初のバージョンだけ、特に最後のバージョンは勝率60%を超えても、テスト環境のスコアがなかなか上がらない
原因把握していないけど、このような一致していない場合は、一番改善策が考えにくい
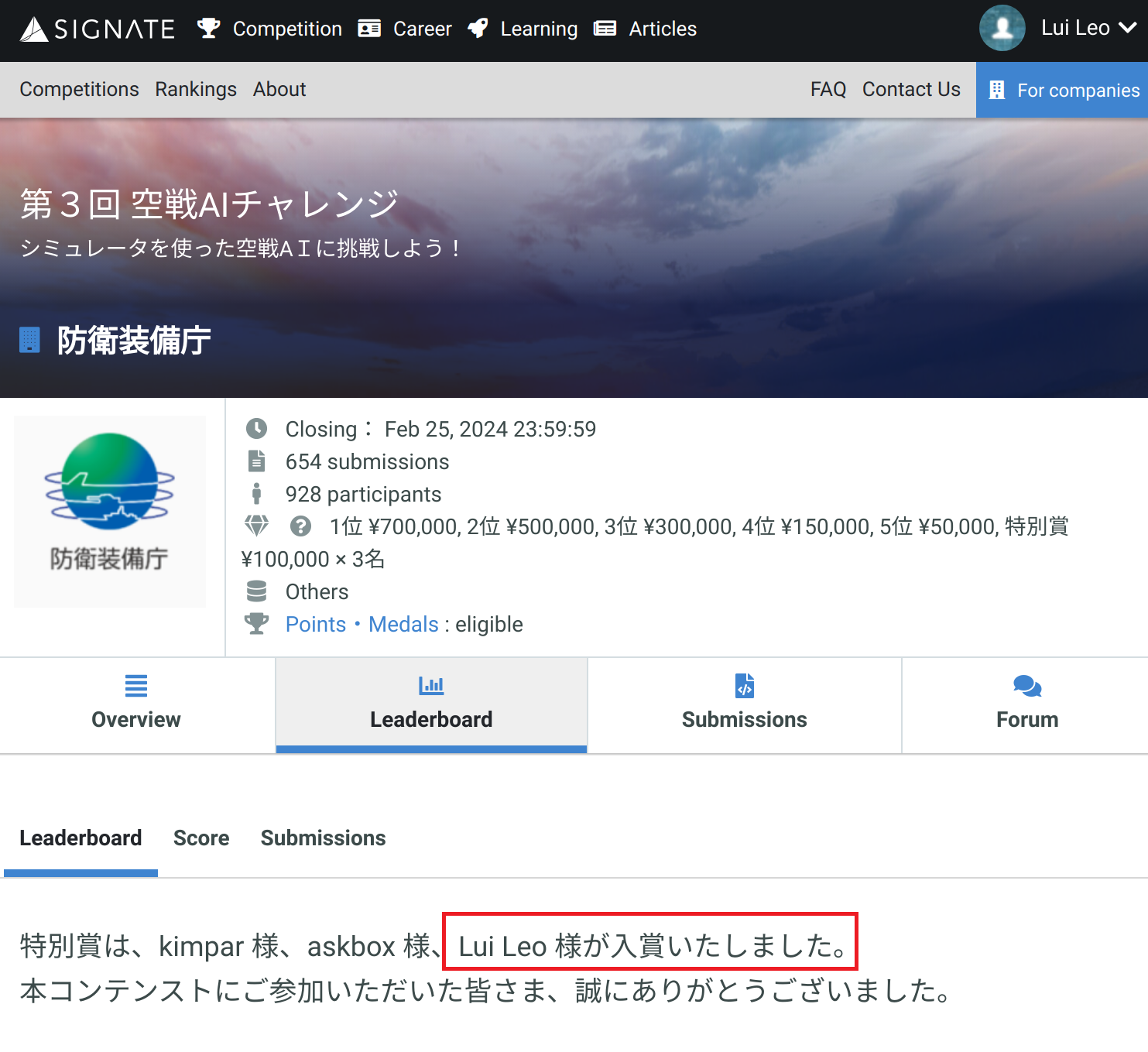
特別賞について
サイトにより、「フォーラムにて、コンペの運営円滑化や他参加者のフォローに貢献いただいた方から、最大3名を選定」との記載がありました。フォーラムで上げられた内容の公開はしかねますが、みんなのRL訓練方法・対戦を勝つためのいろんな実装手法・戦闘機関連の共有を見てかなり知識が広がりました。今回の受賞を受けて、今後も積極的に発信していきます。
最後に、いろいろ苦戦したけど、苦労したからこそ勉強になりました。またいつか金メダルをGETします。