概要
何らかの理由でオープンソースLLMを使いたい場合は、Ollamaが登場する前にかなり工夫しないといけないけど、時代の進化で現在はVM立ち上げからモデルが使えるまで僅か数分で設定できます。早速見ていきましょう。
スペック確認
今回はAWSでやってみます。現時点日本リージョンで最新のGPU付きEC2はg5で、A10GのGPUで、24GB/96G/192GBの3択しかないです。Llama3.3は絶対に24GBで足りないので、g5.12xlargeにします。

そして費用ですが、USリージョンよりやや高くて、東京はUSD8.2 / 1時間となっています。

モデルのスペックは、ollamaに載せている、llama3.3のQ4_K_Mにします。43GBなのでg5.12xlargeで動けるはずです。
EC2設置
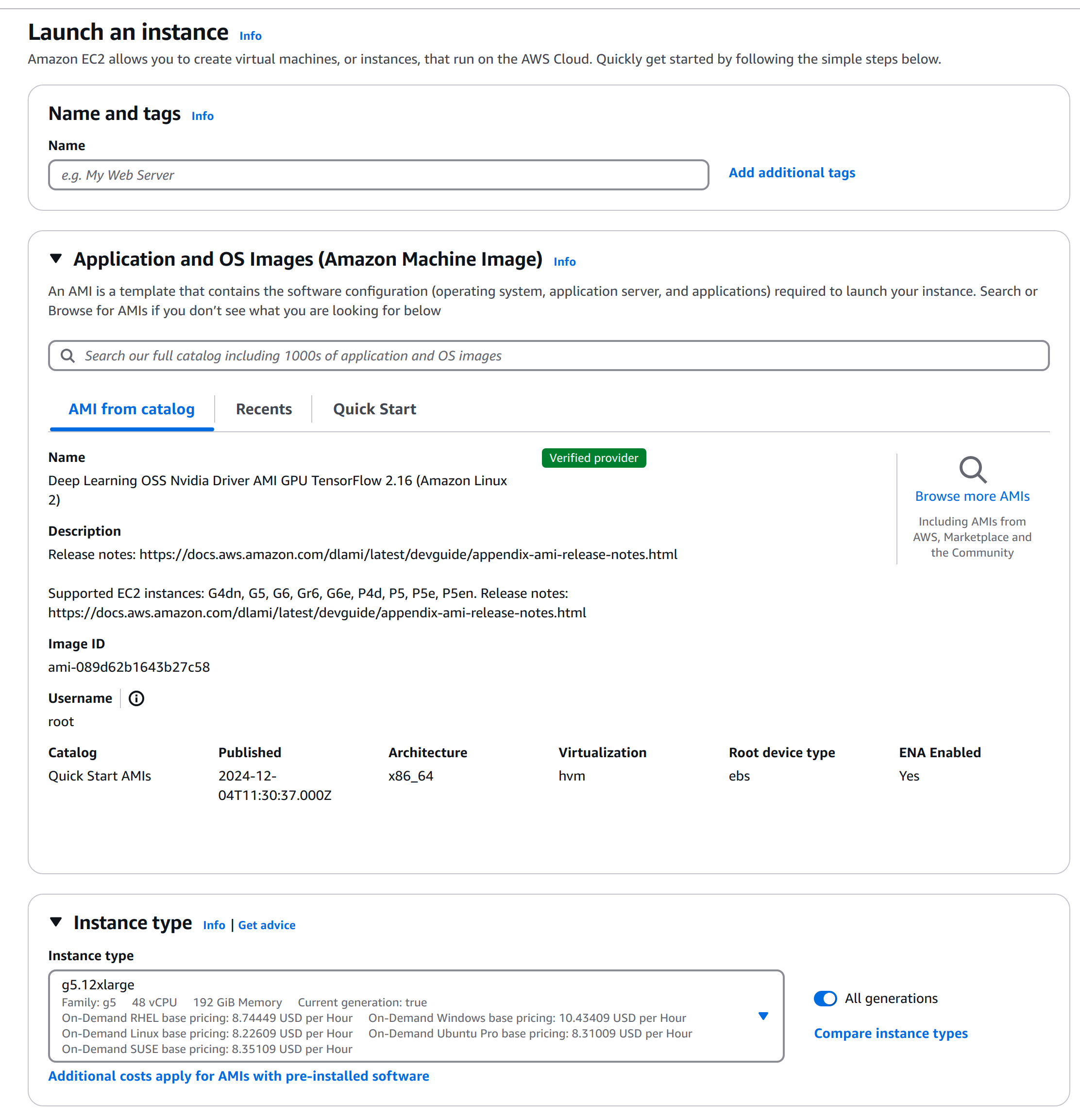
EC2のAMIは、画像のようにNvidiaドライバーが入っているものをおすすめです。ゼロからインストールの場合だと、30分〜1時間がかかる可能性があります。
コマンド
1 . 念の為、rootレベル権限を取得します。
sudo bash
2 . Ollamaをダウンロードしてインストールします。
curl -fsSL https://ollama.com/install.sh | sh
3 . Llama3.3モデルをダウンロードします。
ollama pull llama3.3
4 . これで設置完了なので、1回生成リクエストを送ってみます。
curl http://localhost:11434/api/generate -d '{"model": "llama3.3","prompt": "Give me sample source code for training a lstm network using pytorch"}'


これだけで使えるようになりました。セキュリティグループなどの設定をいじれば、外部に公開することももちろんできます。
最後に、GPUのリソースも確認してみます。
nvidia-smi

半分ぐらい占用されていますね。ネットで48GBのGPUでもギリギリ動けるとの報告もありましたけど、コンスーマレベルのGPUだとやはり生成スピードが遅くて、実用性が疑問になります。