カリキュラム強化学習でタクシー問題を解ける
Github(英語バージョン)
https://github.com/leolui2004/curriculum_taxi
概要
過去の強化学習は、複数のステージに関する問題を解決するのに弱いです。Taxi-v3の例を使用すると、通常のactor-criticな方法はリプレイキューを使用しないと機能しません(この場合はDQNが機能します)。カリキュラム強化学習を導入することにより、モデルは段階ごとに目標を完了することを学習し、最後にタスク全体を完了することができます。また、トレーニングの効果に何らかの影響があるかどうかを確認するために、curiosityを追加しようとしました。
Taxi-v3
ゲームはシンプルで、タクシーは5 x 5フィールドのランダムな位置から開始し、タクシーは乗客を迎えに行くたびに環境によってランダムに選択された位置に移動し、次に別の位置に移動して降車する必要があります。
500の状態、6つのアクション(左、右、上、下、ピックアップ、ドロップオフ)があり、ゴールは1つだけですが、実際には4つのステージ(ピックアップ位置に移動、ピックアップ、ドロップオフ位置に移動、ドロップオフ)があります。 )。目標を達成するための+20の報酬、間違ったピックアップまたはドロップオフアクションの場合は-10、タイムステップごとの移動ごとに-1。
手法
OpenAIが提供するTaxi-v3はラップされた環境であり、カリキュラム学習として使用し、アルゴリズムの学習も容易にするために、状態、アクション、報酬、完了ステータスを変更する必要があります。
Stateのカスタマイズ
def state_decode(i):
out = []
out.append(i % 4)
i = i // 4
out.append(i % 5)
i = i // 5
out.append(i % 5)
i = i // 5
out.append(i)
return list(reversed(out))
Actionのカスタマイズ
def action_curiosity(curiosity, action_space, action):
if random.random() > curiosity:
return action
else:
return random.randint(0, action_space - 1)
RewardとDoneの選択のカスタマイズ
def done_stage_process(state_list, reward, done_stage, done):
done_ = 0
reward_ = 0
if done_stage == 0: # go to pick up
if state_list[2] == 0:
if state_list[0] == 0 and state_list[1] == 0:
reward_ = 150
done_stage = 1
elif state_list[2] == 1:
if state_list[0] == 0 and state_list[1] == 4:
reward_ = 150
done_stage = 1
elif state_list[2] == 2:
if state_list[0] == 4 and state_list[1] == 0:
reward_ = 150
done_stage = 1
elif state_list[2] == 3:
if state_list[0] == 4 and state_list[1] == 3:
reward_ = 150
done_stage = 1
elif done_stage == 1: # pick up
if state_list[2] == 4:
done_stage = 2
reward_ = 300
elif done_stage == 2: # go to drop off
if state_list[3] == 0:
if state_list[0] == 0 and state_list[1] == 0:
reward_ = 450
done_stage = 3
elif state_list[3] == 1:
if state_list[0] == 0 and state_list[1] == 4:
reward_ = 450
done_stage = 3
elif state_list[3] == 2:
if state_list[0] == 4 and state_list[1] == 0:
reward_ = 450
done_stage = 3
elif state_list[3] == 3:
if state_list[0] == 4 and state_list[1] == 3:
reward_ = 450
done_stage = 3
elif done_stage == 3: # drop off
if reward_ == 20:
reward_ = 600
done_ = 1
if reward_ == -10:
reward_ = -5
return reward, done_stage, done_
強化学習の部分では、少し変更を加えたPPOを使用しました。参照コードは、ここにあります。
結果
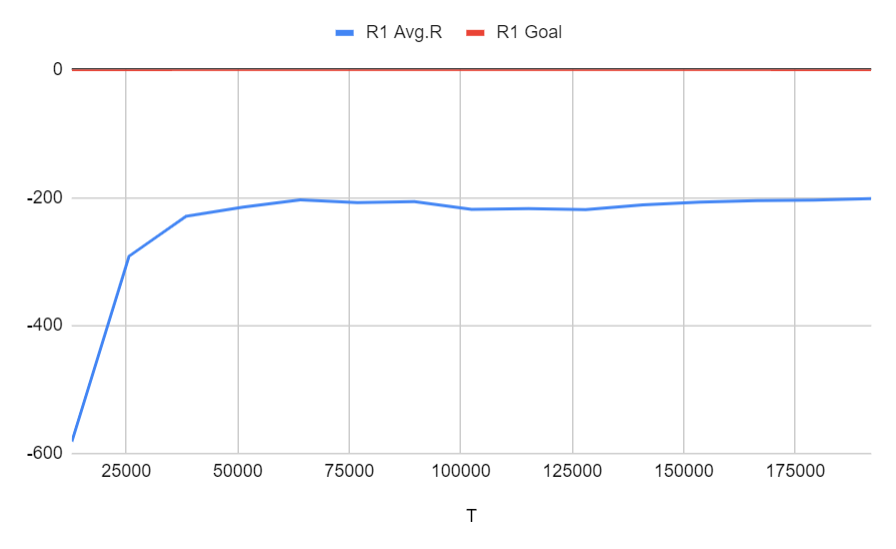
Run 1: 通常通り(ベースライン)
Run 2: 通常通り + 1% curiosity
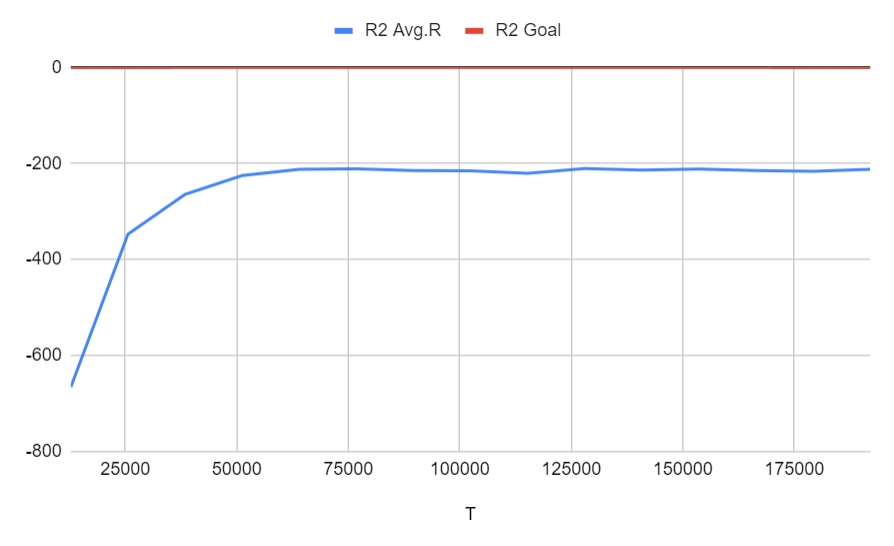
合計報酬は-200まで増加を停止し、目標に到達しませんでした。これは、モデルが間違ったピックアップまたはドロップオフで-20を受け取ったため、ゲームが終了するまで移動する傾向があったためである可能性があります(最大タイムステップ200)。
Run 3: ゴールは乗客を迎えに行くポジションまでたどり着くだけ (ステージ4の1)に設定、間違ってピックアップもしくは降客の報酬は-5、タスクの報酬は150
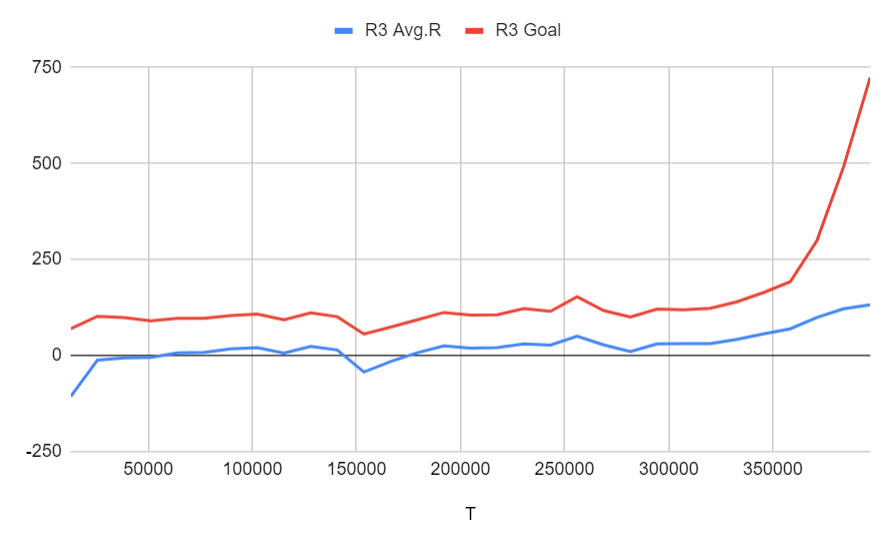
タスクは最初の段階にのみ削減されますが、モデルは正の累積報酬を達成し、目標の達成を増やすことを学ぶことができました。
Run 4: ゴールは乗客をピックアップしただけ (ステージ4の2)に設定、間違ってピックアップもしくは降客の報酬は-5、タスクの報酬は250
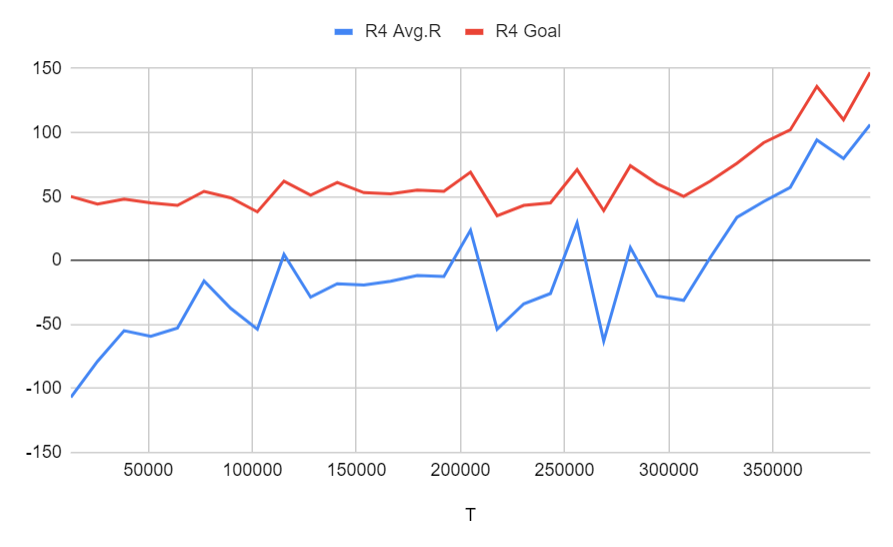
Run 5: ゴールは乗客をピックアップしただけ (ステージ4の2)に設定、間違ってピックアップもしくは降客の報酬は-5、タスクの報酬は300、さらにピックアップのポジションまでたどり着けば中間報酬として150がもらえる
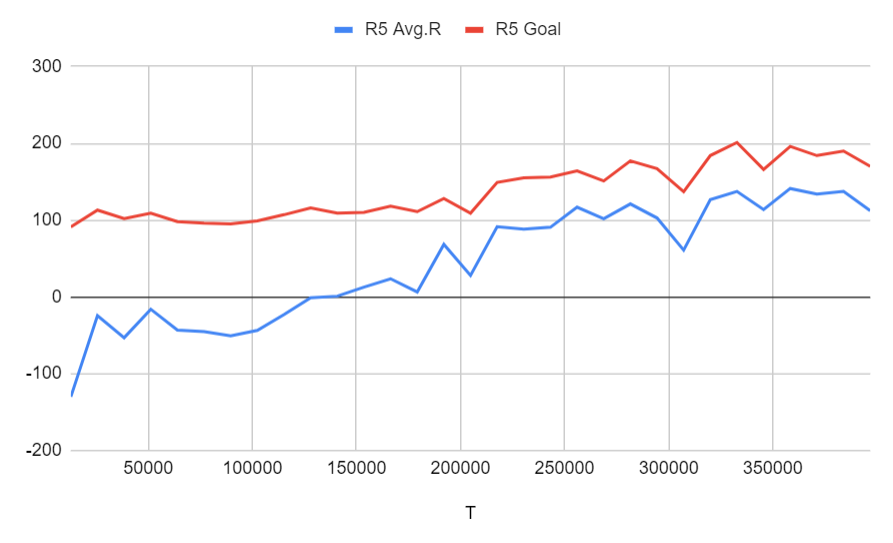
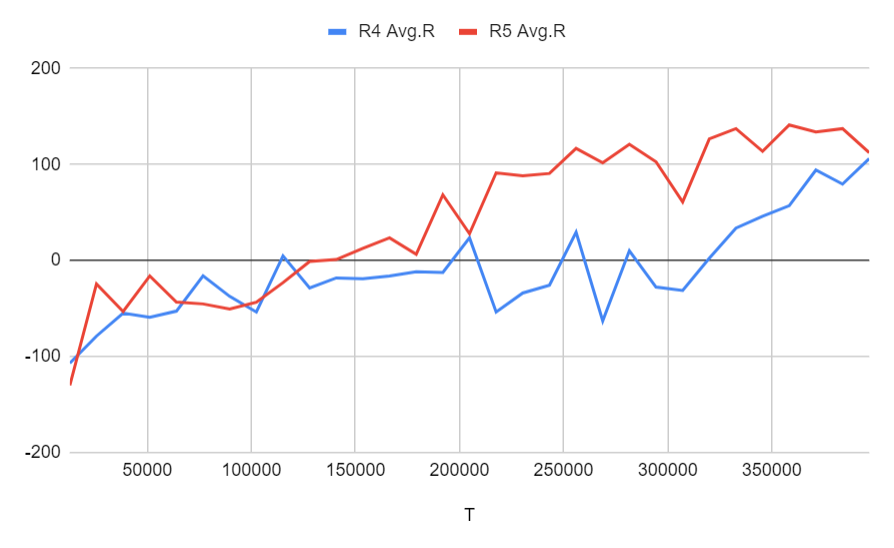
どちらもタスクを完了するために正常に学習されており、中間目標を設定することの違いは、ここでは大きな違いを示していません。
Run 6: ゴールは乗客をピックアップして、降客のポジションまでたどり着くだけ (ステージ4の3)に設定、間違ってピックアップもしくは降客の報酬は-5、タスクの報酬は450、さらにピックアップのポジションまでたどり着けば中間報酬として150がもらえる、ピックアップ成功は300がもらえる
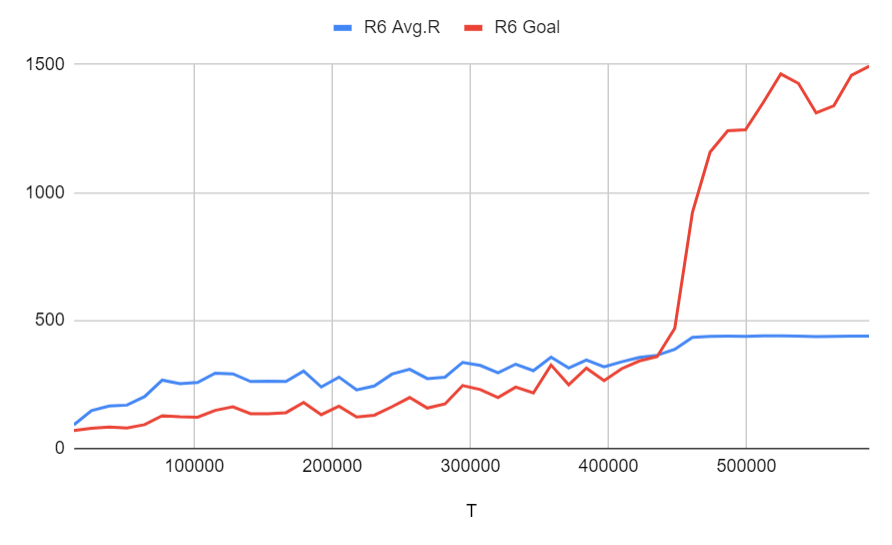
Run 7: オリジナルのゴールと同じ (ステージ4の4)に設定、間違ってピックアップもしくは降客の報酬は-5、タスクの報酬は600、さらにピックアップのポジションまでたどり着けば中間報酬として150がもらえる、ピックアップ成功は300がもらえる、降客のポジションまでたどり着けば450がもらえる
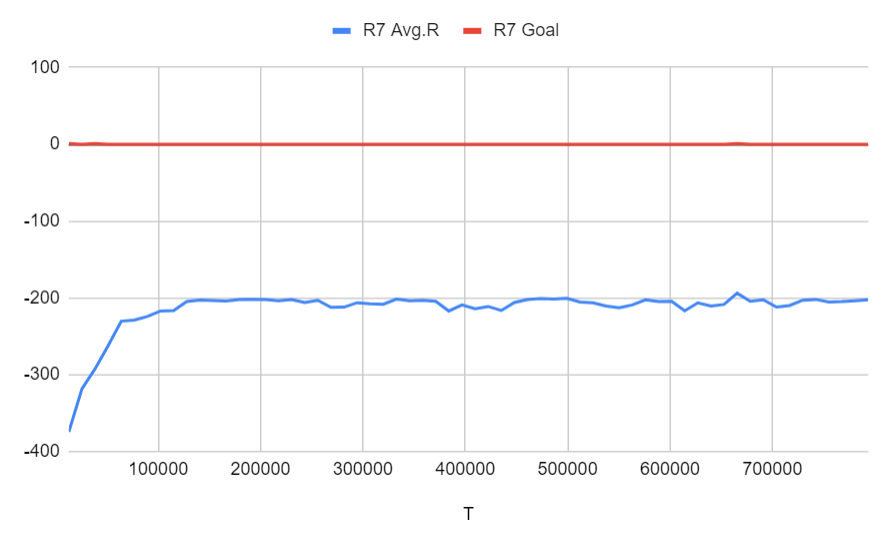
Run 8: Run 7と同じ設定 + 1% curiosity
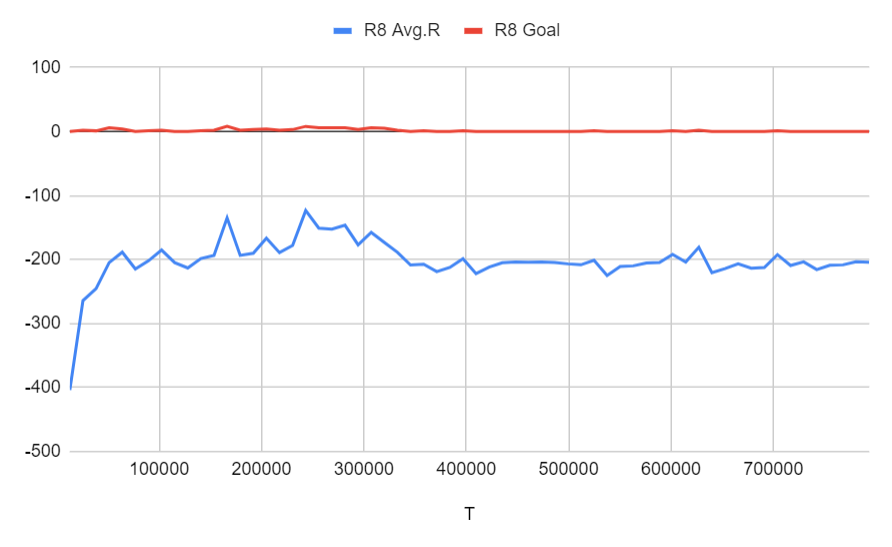
Run 9: Run 8と同じ設定 + 200,000ステップごとに学習率が50%下がる
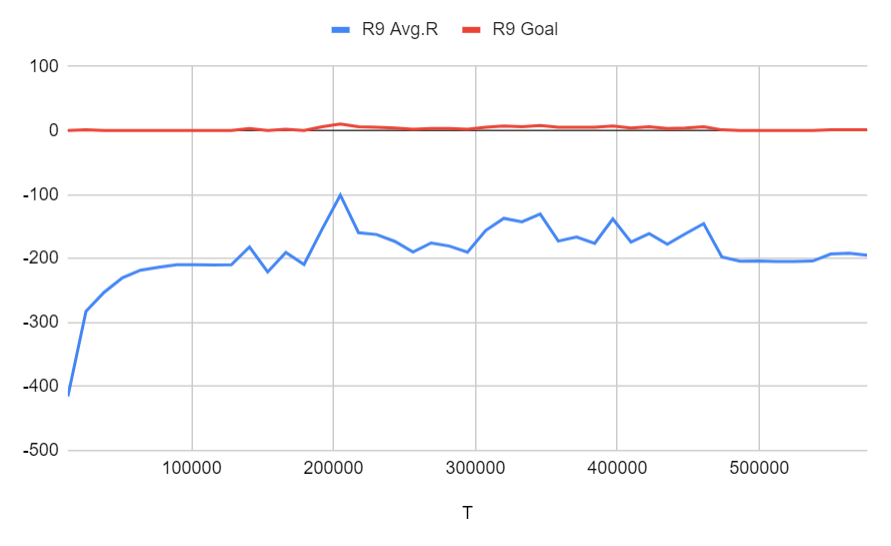
モデルはステージ3までは正常に学習しましたが、ステージ4までは学習できませんでした。好奇心を加えても、モデルは最初はタスクを数回完了しようとしましたが、最後には実行1の結果と同じように学習できませんでした。学習率が低下する予定であっても、結果はあまり改善されません。
Run 10: Run 7と同じ設定 + カリキュラム学習 + 最後の200,000ステップの学習率は本来の10%
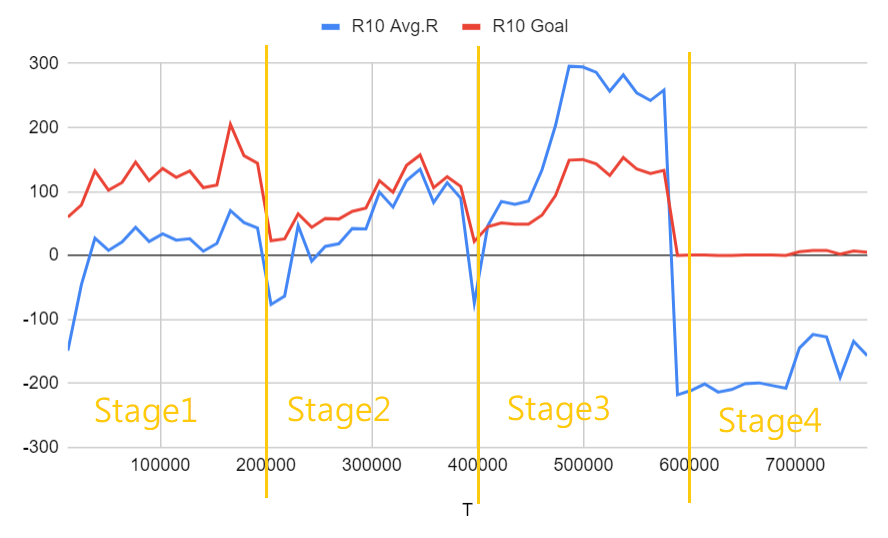
モデルは最初の3ステージではかなり速く学習しましたが、最後のステージでは失敗しました。最初の3ステージでは、各ステージでモデルの累積報酬が最初に低下しましたが、その後すぐに、より困難なタスクを完了することを学習しました。
Run 11: Run 7と同じ設定 + カリキュラム学習 + 最後の2ステージの訓練ステップは本来の2倍、最後のステップの学習率は本来の10%
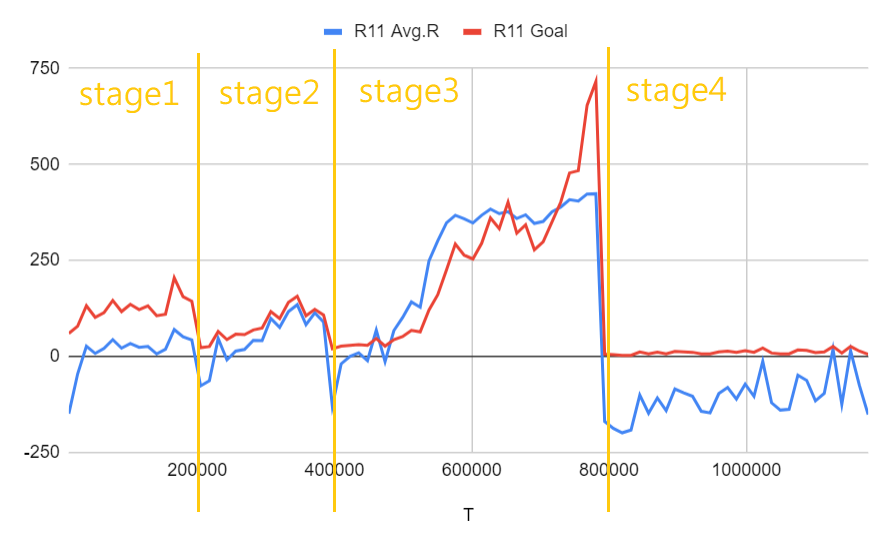
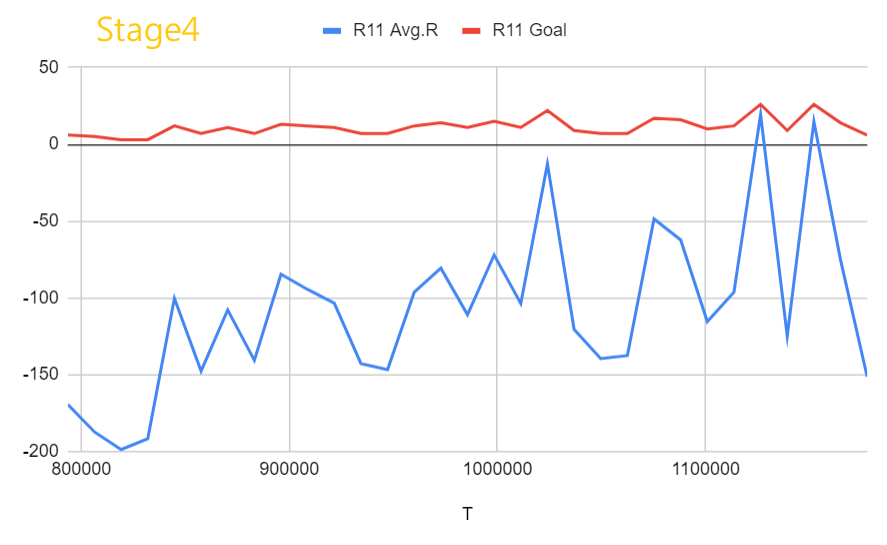
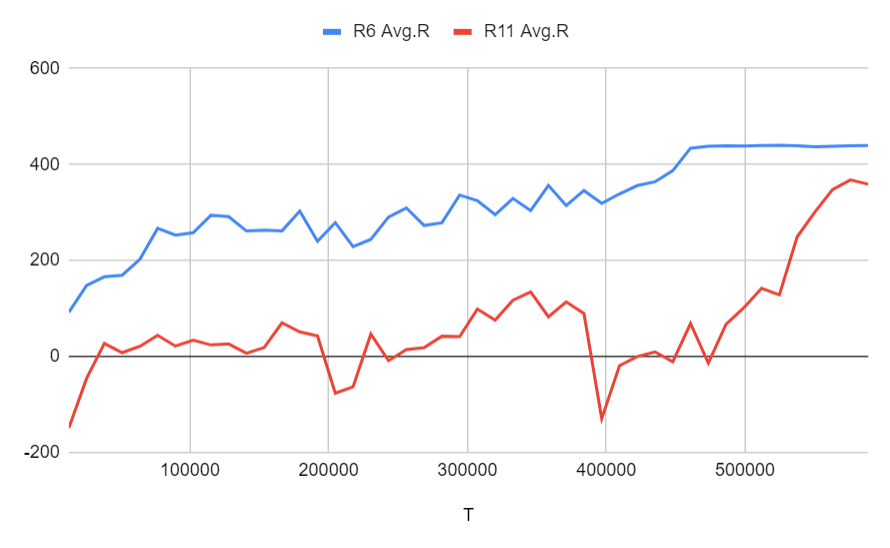
結果はそれほど素晴らしいものではありませんが、モデルは正常に学習できます。 Run 6と簡単に比較すると、カリキュラム学習を使用している場合は、カリキュラム学習を使用していない場合とほぼ同じ速度で学習できることがわかります。