Twitter アカウント間の関係を視覚化するための Dash Cytoscape
Github(英語バージョン)
https://github.com/leolui2004/dash_cytoscape
Github での 10 プロジェクト目となります。 Dash Cytoscape を使用して、日本の有名なアーティストの Twitter フォロワーのネットワーク関係を示し、ファンの共通趣味を分析する実験です。これはあくまでデモンストレーションなので、精度が高い分析プロジェクトではないことに注意してください。
コメントをお寄せください。昨年 Python の学習を始めたばかりで、現在はデータ分析、視覚化、ディープラーニングアプリケーションに集中しています。
簡単な紹介
ゴールと使い方
従来のグラフでは、ネットワーク間の困難な関係を表すことができません。最も一般的な例は、ソーシャルネットワーク上のユーザーです。ネットワークグラフを使用してそれらの関係を視覚化することで、さまざまなタイプのユーザー間の関係を知ることで、ユーザーの共通趣味を簡単に見つけることができます。 またはターゲットユーザーへたどり着くジャーニーを理解します。
Dash Cytoscape
Dash Cytoscape は、ネットワークのグラフを表示するための視覚化ツールです。 Cytoscape 用のツールもたくさんありますが、個人的には Dash に精通していますし、Dash はユーザーにますます多くのツールを提供することに非常に熱心に取り組んでいるので、好みで Dash を使用することにしています。
データソース
今回は 2021 年 NHK 紅白歌合戦の女性アーティストを分析対象としました。 Twitter アカウントを持っていないものを除いて、合計 Twitter アカウント 19 個があります。これらの Twitter アカウントのフォロワーを取得するプロセスを示し、以下のセクションで関係を視覚化します。
名前と Twitter アカウントリスト
Ai, Ai, micaholic1981
Aimyon, あいみょん, aimyonGtter
Sayuri Ishikawa, 石川さゆり, N/A
Awesome City Club, Awesome City Club, CcAwesome
Mone Kamishiraishi, 上白石萌音, mone_tohoent
Fuyumi Sakamoto, 坂本冬美, Fuyumi_staff
Sakurazaka46, 櫻坂46, sakurazaka46
Yoshimi Tendo, 天童よしみ, N/A
Tokyo Jihen, 東京事変, nekoyanagi_line
NiziU, NiziU, NiziU__official
Nogizaka46, 乃木坂46, nogizaka46
Perfume, Perfume, Perfume_Staff
Bish, BiSH, BiSHidol
Hinatazaka46, 日向坂46, hinatazaka46
Seiko Matsuda, 松田聖子, N/A
Misia, MISIA, MISIA
Kaori Mizumori, 水森かおり, mizumyoutube
Milet, milet, milet_music
Millennium Parade, millennium parade, mllnnmprd
Belle, Belle(中村佳穂), KIKI_526
Hiroko Yakushimaru, 薬師丸ひろ子, N/A
Yoasobi, YOASOBI, YOASOBI_staff
Lisa, LiSA, LiSA_OLiVE
プロセス
Twitter フォロワーの取得
Twitter API で(https://developer.twitter.com/en/docs/twitter-api/v1/accounts-and-users/follow-search-get-users/api-reference/get-followers-ids)各 Twitter アカウントのフォロワーリストを取得します。一部の Twitter アカウントフォロワーが 100 万人を超えるので、1 〜 2 日かけてすべてのフォロワーリストを取得しました。すべてのフォロワーリストは csv として保存され、各ファイルは各アーティストの Twitter アカウントを表します。プライバシー情報関係のため、これらのフォロワーは名前やスクリーン名ではなく Twitter ID で表されますが、フォロワー自身ではなく関係のみを考慮しているため、これにより多くの時間を節約できます(Twitter アカウントの名前を取得する)はるかに時間がかかります)。
from requests_oauthlib import OAuth1Session
import json
import csv
import time
CK = '' # Consumer Key
CS = '' # Consumer Secret
AT = '' # Access Token
AS = '' # Accesss Token Secert
session = OAuth1Session(CK, CS, AT, AS)
def getFollower(screen_name, cursor):
url = 'https://api.twitter.com/1.1/followers/ids.json'
res = session.get(url, params = {'screen_name':screen_name, 'cursor':cursor, 'skip_status':1, 'count':5000})
resText = json.loads(res.text)
return resText
twitter_dict = {"micaholic1981":"Ai","aimyonGtter":"あいみょん","CcAwesome":"Awesome City Club","mone_tohoent":"上白石萌音",
"sakurazaka46":"櫻坂46","nekoyanagi_line":"東京事変","NiziU__official":"NiziU","nogizaka46":"乃木坂46","Perfume_Staff":"Perfume",
"BiSHidol":"BiSH","hinatazaka46":"日向坂46","MISIA":"MISIA","milet_music":"milet",
"mllnnmprd":"millennium parade","KIKI_526":"Belle(中村佳穂)","YOASOBI_staff":"YOASOBI","LiSA_OLiVE":"LiSA"}
for twitter_account in twitter_dict.keys():
next_cursor = -1
follower = twitter_account
while next_cursor != 0:
resText = getFollower(follower, next_cursor)
next_cursor = resText['next_cursor']
for id in resText['ids']:
with open(f'raw/{follower}.csv', 'a+', encoding='utf-8', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow([id])
time.sleep(60)
フォロワーのサンプリング
取得されたフォロワーリストの総数は 1,000 万行を超えており、Dash Cytoscape にロードすることは不可能であるため、何らかのサンプリングが必要です。いくつかの方法を試しましたが、詳細は次のとおりです。
手法 1:
関係のない(すべてのフォロワーリストに 1 回だけ表示されます)すべてのレコードを削除します
手法 2:
レコードから 1% のサンプルを取得します(100 レコードごとに 1 レコードをキープします)
手法 2 の場合、それは簡単な作業ですが、手法 1 の場合、達成する方法はたくさんありますが、方法が異なれば効率も異なります。ここに方法と結果を示します。
手法 1 方法 1: レコード各行について、すべてのレコードで同じ Twitter ID を見つける
結果:とても遅い、ご想像のとおり、ループのループです
手法 1 方法 2: SQLite データベースを設定し、すべてのレコードについて、それ(Twitter ID)がデータベースに配置されていない場合はデータベースに配置します。そうでない場合は、その Twitter ID の出現頻度を更新し、その後、レコードの各行について、その出現頻度が 1 であれば削除します。(または、出現頻度が 1 より大きい場合にのみ行をキープします)
結果:遅い、SQLiteは IO が多いタスクに向けない
手法 1 方法 3: 方法 2 と同じですが、SQLite データベースの代わりに Python ディクショナリを使用するだけです
結果:とても早い、10M 行程度のデータにも関わらず
ただし、アプローチの1つだけを実行するだけでは不十分です。たとえば、アプローチ1を終了した後、3〜4Mのレコードが残っているか、アプローチ2を終了した後、10万のレコードが残っています。これは、視覚化にはまだ非常に大きいです。したがって、サンプリングプロセスでは、2つのアプローチを組み合わせる必要がある場合があります
サンプリングプロセス 1:手法 1 + 手法 2
結果:一部の csv が 30k 行以上のレコードを持っている、一方で一部の csv が 10 行以下のレコードを持っている
サンプリングプロセス 2:手法 2 + 手法 1
結果:1 つの csv の最大行数は 200 未満であり、視覚化に最適です。
import csv
twitter_dict = {"micaholic1981":"Ai","aimyonGtter":"あいみょん","CcAwesome":"Awesome City Club","mone_tohoent":"上白石萌音","Fuyumi_staff":"坂本冬美",
"sakurazaka46":"櫻坂46","nekoyanagi_line":"東京事変","NiziU__official":"NiziU","nogizaka46":"乃木坂46","Perfume_Staff":"Perfume",
"BiSHidol":"BiSH","hinatazaka46":"日向坂46","MISIA":"MISIA","mizumyoutube":"水森かおり","milet_music":"milet",
"mllnnmprd":"millennium parade","KIKI_526":"Belle(中村佳穂)","YOASOBI_staff":"YOASOBI","LiSA_OLiVE":"LiSA"}
def sampling():
for twitter_acct in twitter_dict.keys():
row_count = 0
with open(f'raw/{twitter_acct}.csv', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
row_count += 1
if row_count % 100 == 1:
with open(f'sample/{twitter_acct}.csv', 'a+', encoding='utf-8', newline='') as file_product:
writer = csv.writer(file_product)
writer.writerow([row[0]])
return
acct_dict = sampling()
import csv
twitter_dict = {"micaholic1981":"Ai","aimyonGtter":"あいみょん","CcAwesome":"Awesome City Club","mone_tohoent":"上白石萌音","Fuyumi_staff":"坂本冬美",
"sakurazaka46":"櫻坂46","nekoyanagi_line":"東京事変","NiziU__official":"NiziU","nogizaka46":"乃木坂46","Perfume_Staff":"Perfume",
"BiSHidol":"BiSH","hinatazaka46":"日向坂46","MISIA":"MISIA","mizumyoutube":"水森かおり","milet_music":"milet",
"mllnnmprd":"millennium parade","KIKI_526":"Belle(中村佳穂)","YOASOBI_staff":"YOASOBI","LiSA_OLiVE":"LiSA"}
acct_dict = {}
def get():
for twitter_acct in twitter_dict.keys():
print(twitter_acct)
with open(f'sample/{twitter_acct}.csv', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
if row[0] in acct_dict:
acct_dict[row[0]] = acct_dict[row[0]] + 1
else:
acct_dict[row[0]] = 1
return acct_dict
acct_dict = get()
for twitter_acct in twitter_dict.keys():
print(twitter_acct)
with open(f'sample/{twitter_acct}.csv', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
if acct_dict[row[0]] > 1:
with open(f'product/{twitter_acct}.csv', 'a+', encoding='utf-8', newline='') as file_product:
writer = csv.writer(file_product)
writer.writerow([row[0]])
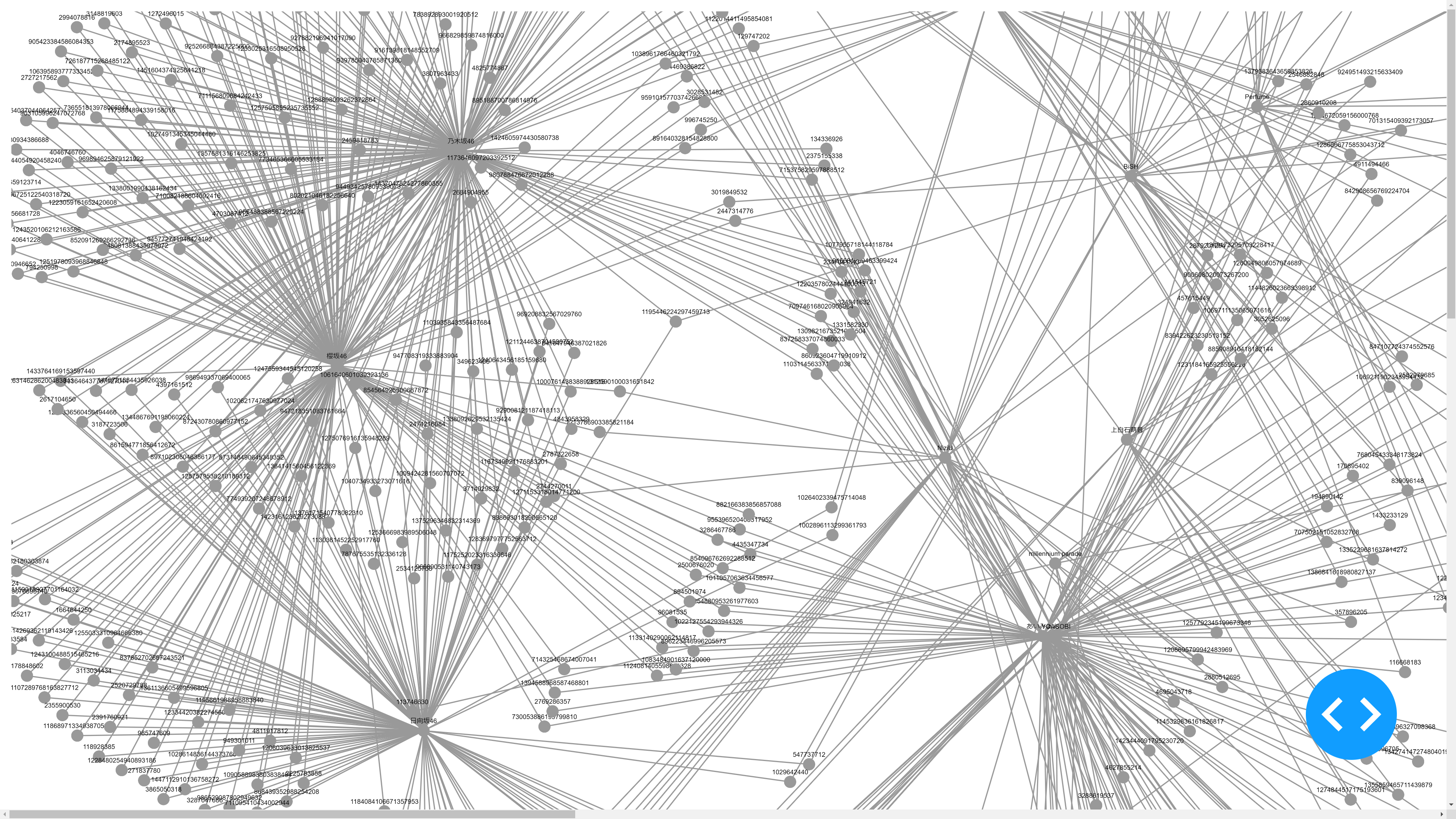
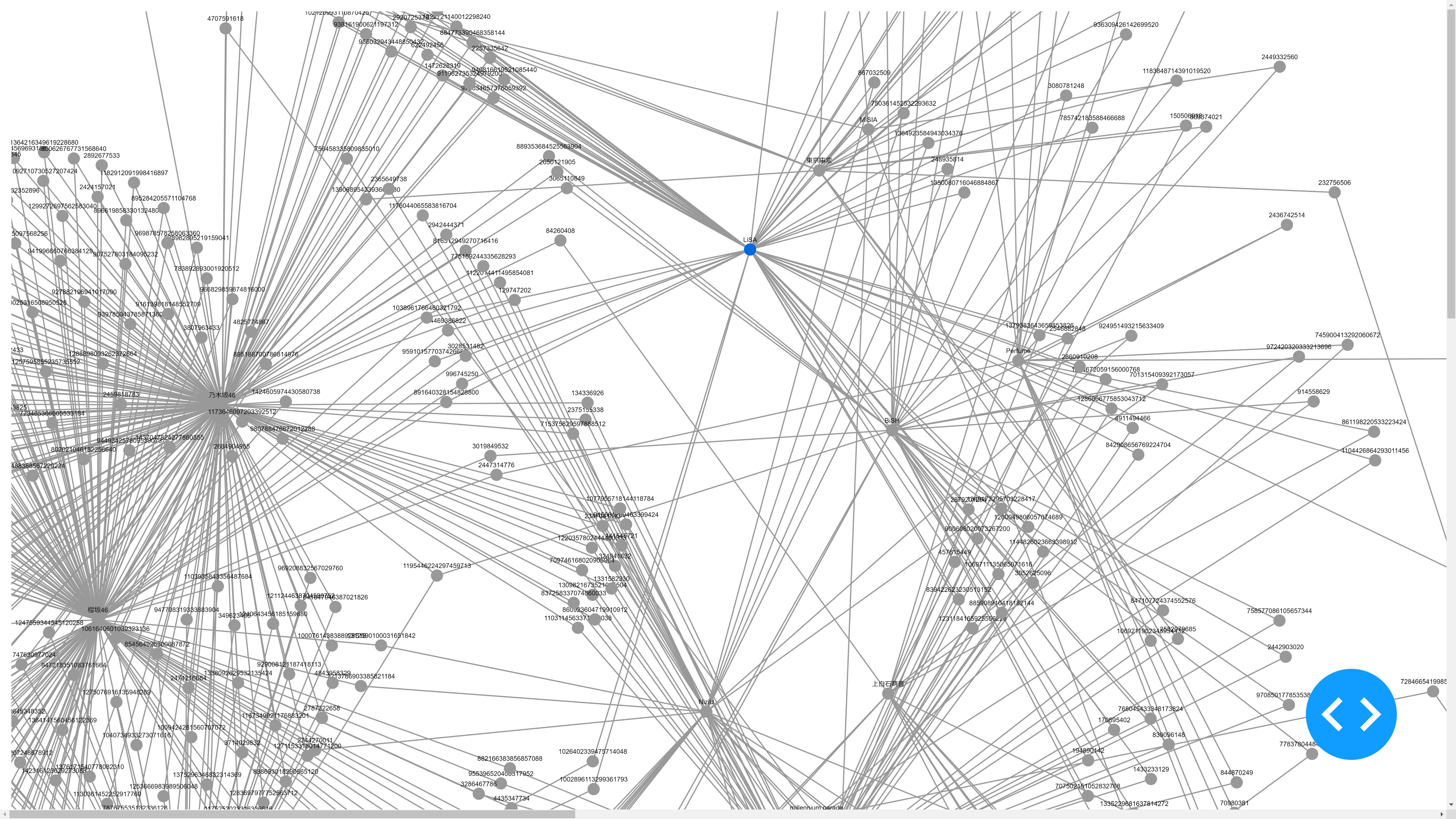
可視化結果
これらのデータを収集してサンプリングした後、NetworkX を使用してネットワークグラフを作成し、それを Dash Cytoscape の形式に変換しました(Dash Cytoscape は NetworkX グラフを直接読み取ることができません。この問題の解決案については、ネット上にいくつかの関連記事があります)。
また、VM に pygraphviz をインストールするときにいくつかのバグに遭遇しましたが、それらはネットでソリューションを検索することで簡単に解決できます。
import dash
import dash_cytoscape as cyto
import dash_html_components as html
import networkx as nx
import csv
twitter_dict = {"micaholic1981":"Ai","aimyonGtter":"あいみょん","CcAwesome":"Awesome City Club","mone_tohoent":"上白石萌音",
"sakurazaka46":"櫻坂46","nekoyanagi_line":"東京事変","NiziU__official":"NiziU","nogizaka46":"乃木坂46","Perfume_Staff":"Perfume",
"BiSHidol":"BiSH","hinatazaka46":"日向坂46","MISIA":"MISIA","milet_music":"milet",
"mllnnmprd":"millennium parade","KIKI_526":"Belle(中村佳穂)","YOASOBI_staff":"YOASOBI","LiSA_OLiVE":"LiSA"}
twitter_lists = []
for twitter_list in twitter_dict.keys():
twitter_lists.append(twitter_dict[twitter_list])
node_attrs = {}
center_to_followers = {}
for screenname in twitter_dict.keys():
node_attrs[screenname] = {}
node_attrs[screenname]['name'] = twitter_dict[screenname]
for screenname in twitter_dict.keys():
twitter_followers = []
with open(f'product/{screenname}.csv', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
twitter_followers.append(row[0])
if row[0] not in node_attrs:
node_attrs[row[0]] = {}
node_attrs[row[0]]['name'] = row[0]
center_to_followers[screenname] = twitter_followers
graph = nx.from_dict_of_lists(center_to_followers)
nx.set_node_attributes(graph, node_attrs)
pos = nx.nx_agraph.graphviz_layout(graph)
pos_list = []
for value in pos.values():
pos_list.append({'x': value[0] * 10, 'y': value[1] * 10})
cy = nx.readwrite.json_graph.cytoscape_data(graph)
for i in range(len(cy['elements']['nodes'])):
cy['elements']['nodes'][i]['data']['label'] = cy['elements']['nodes'][i]['data']['name']
cy['elements']['nodes'][i]['position'] = pos_list[i]
if cy['elements']['nodes'][i]['data']['label'] in twitter_lists:
cy['elements']['nodes'][i]['classes'] = 'red triangle'
elements_list = []
for j in cy['elements']['nodes']:
elements_list.append(j)
for k in cy['elements']['edges']:
elements_list.append(k)
app = dash.Dash(__name__)
app.layout = html.Div([
cyto.Cytoscape(
id='cytoscape-two-nodes',
layout={'name': 'preset'},
style={'width': '2160px', 'height': '1440px'},
elements=elements_list
)
])
if __name__ == '__main__':
app.run_server(host='0.0.0.0', debug=True)
結果
結果の画像は素晴らしいネットワークグラフです。
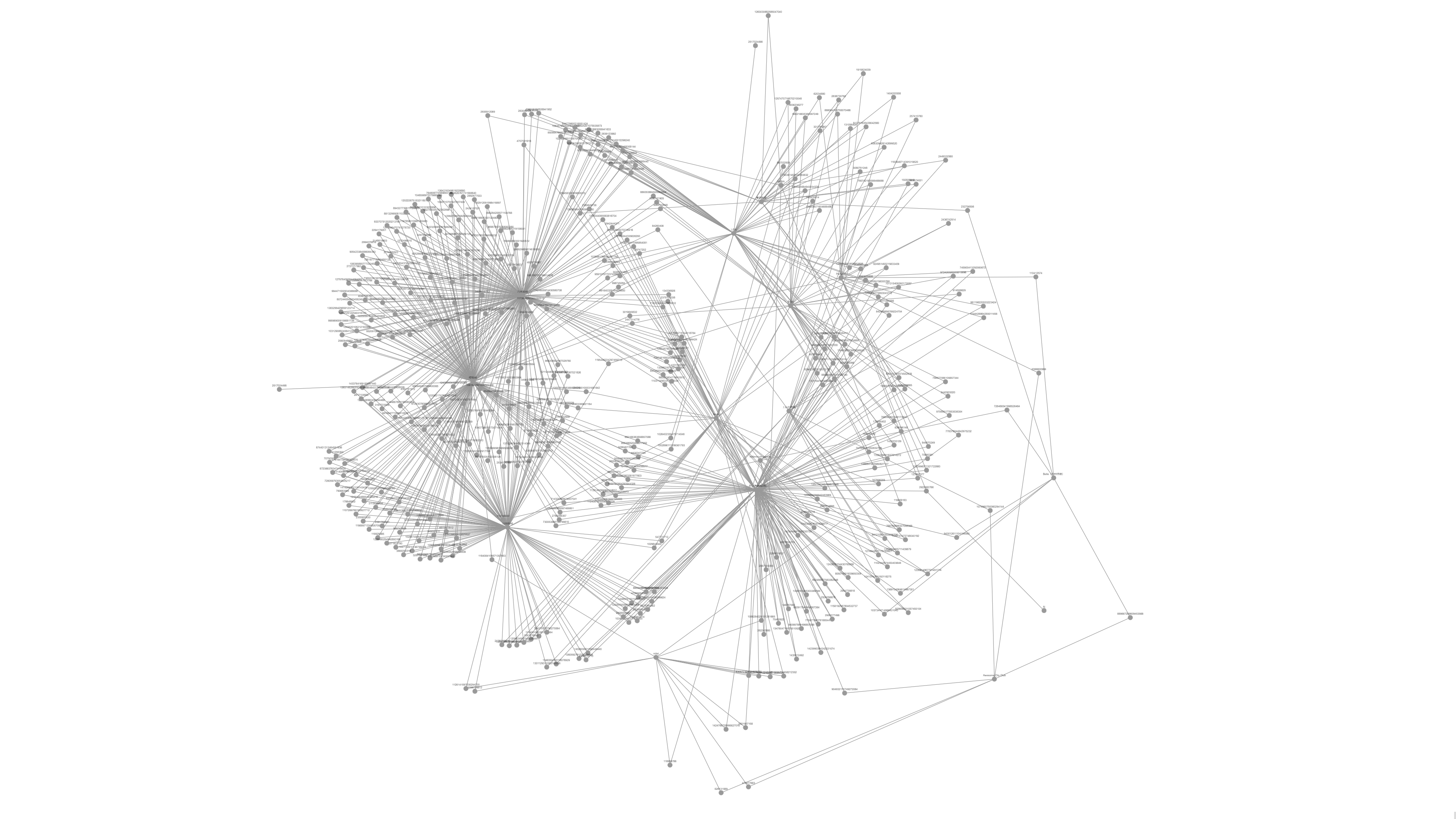
結果は、46 グループのフォロワー(櫻坂46、乃木坂46、日向坂46)が密接に関連していることを明確に示しています。これは、予測と一致するはずです。