必要に迫られたのでJavaでKinesisを扱ってみようと思います。
- AWSは触るがスクリプト言語(Python、Javascript)がメイン
なエンジニアの勉強記録。
Amazon Kinesis Data Streams概要
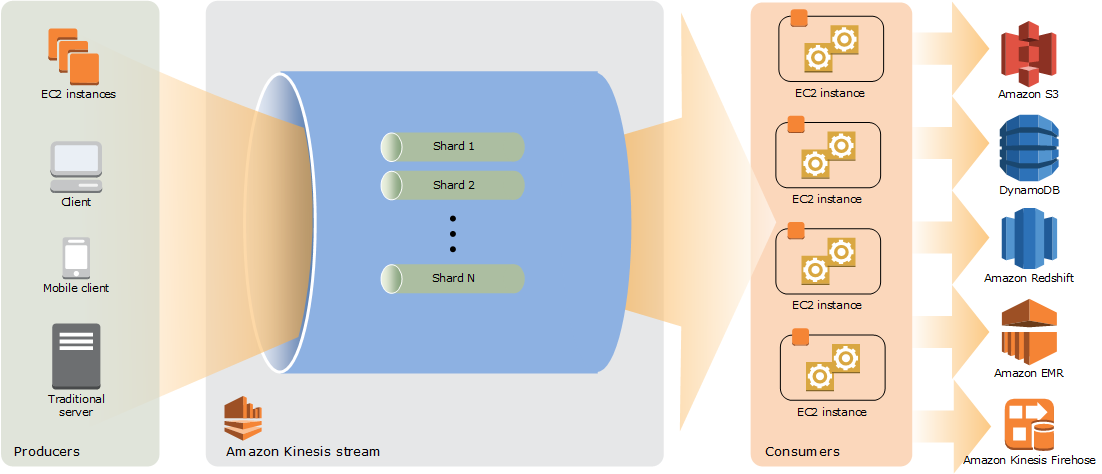
ざっくりいうと大量データ向けのキューのサービス。
キューのサービスは他にもSQSやAmazon MQ、もっというとAWS IoTやStep Functionsあたりもありますが、Kinesisは特に大量のデータにフォーカスしているサービスです。
- シャード増減による能力増減
- 一定期間レコードの保存
- ロード、分析のサービス(Firehose、Analytics)との連携
- PrivateLinkによる閉域アクセス
あたりが大きな特徴かと思います。さらに
- 書き込み側のライブラリ(Kinesis Producer Library, KPL)、読み込み側のライブラリ(Kinesis Client Library, KCL)が提供
される点も一つの特徴です。
無論他のAWSサービス同様、APIコールなのでAWS CLIやAWS SDKからも利用できます。
一方でKPL、KCLを利用することでパフォーマンスや双方の連携面でメリットがあるとのことです。
このKPL、KCLはJavaで書かれています。そのためJavaでの利用を学習してみよう、と思った次第。
(正確には、KPLはC++で書かれたモジュールををJavaでラップしていたり、KCLはPython、NodeなどによるJavaラッパの利用も可能だったりします)
公式チュートリアル
さっそくチュートリアル: Amazon Kinesis Data Streams を使用したウェブトラフィックの可視化をやってみようと思います。
基本的にぽちぽちクリックしていくだけで進むので、上ドキュメント読みながら気になった点をメモしていきます。
環境構築
このCFnテンプレートを走行させるだけで環境ができあがります。
ParametersのApplicationArchiveについては、デフォルトが2018/7/4現在v1.1.1になっていますが、最新版は1.1.2なのでhttps://github.com/aws-samples/amazon-kinesis-data-visualization-sample/releases/download/v1.1.2/amazon-kinesis-data-visualization-sample-1.1.2-assembly.zipへと書き換えます(こちらで最新版をチェックしておくと良いかもしれません)。キーペアやSSHのアドレス制限には適切な値を入力しておきましょう。
およそ5分ほどでステータスがCREATE_COMPLETEになるので、OUTPUTSタブからCFnの出力を確認します。
アプリケーションの確認
グラフのチェック
OutputsタブのURL項目に表示されたアドレス(EC2で可視化のアプリケーションがホストされています)へアクセスするとグラフが表示されるかと思います。
アクセスしてきたユーザーのrefererについてWebサーバーがKinesisへ逐次Publish、この結果をポーリングしリアルタイムで可視化や集計をするアプリケーション、のシミュレーションのようです。
Kinesisの設定値
KinesisDataVisSampleAppという名前のDataStreamが作成されているかと思うので各設定値を確認してみます。Detailsタブをみてみます。
Shards(シャード)
シャードは書き込まれるレコードの分割数で
各シャードは、読み取りは最大 1 秒あたり 5 件のトランザクション、データ読み取りの最大合計レートは 1 秒あたり 2 MBをサポートできます。また、シャードは、書き込みについては最大 1 秒あたり 1,000 レコード、データの最大書き込み合計レートは 1 秒あたり 1 MB (パーティションキーを含む) もサポートしています。ストリームの総容量はシャードの容量の合計です。
と公式ドキュメントにあるように、1シャードあたりの性能が決まっており、これを増減することで性能を調整します。基本的に大きいほど性能が上がりますが、パーティションキー(後述)がシャードの数より十分大きい必要があります。今回作成されたアプリケーションだと2に設定されているかと思います。
Server-side encryption
オンにするとKMSを利用してのデータの暗号化ができます。
Data retention period
データをKinesis内へ保持しておける期間で、24〜168時間の範囲で設定できます。
(もちろん長いほど追加料金あり)
Shard level metrics
シャードレベルでのメトリクスを見ることができ、データが各シャードに効率的に分散しているかを見るのに役立ちます。これも追加料金発生。
コンソールからのモニタリング
Monitoringタブを見ると各メトリクスのグラフが見えます。
実際の値については青線で表示され、赤線で表示される項目は現在のシャードの値での限界値を示していることにだけ注意する必要があるかと思います(赤線だけが表示されていて動いている、と思っても実際は動作していない)
データプロデューサー
Kinesisに書き込みを行う側をプロデューサーと呼びます。
このアプリケーションではアクセスしてきた人のrefererをPush、というのをシミュレーションしていますが、そのアドレスは6つのURLからランダムに選択したものをKinesisに向かって投げつける、というようにしています
ここにプロデューサー側のコードがあるのでチェックして見ることにします。
(筆者はJavaは全然わからないのでウザい位にコメントつけていきます)
// package: 名前空間区切るもの、世界の誰かとの衝突を防ぐために保有ドメインを使うらしい...
package com.amazonaws.services.kinesis.samples.datavis.producer;
// import: Pythonと似ている、最も後ろ(この行だとIOException)がこのファイル中の名前空間にグローバルに導入
import java.io.IOException; // java. で始まるのが標準ライブラリ
import java.nio.ByteBuffer; // バッファ(nio: non-blocking ioらしい、なるほど)
import java.util.concurrent.TimeUnit; // 時刻便利操作ライブラリ
import org.apache.commons.logging.Log; // commons-logging というらしい、統一的なログのインターフェースを提供するライブラリ
import org.apache.commons.logging.LogFactory; // ↑とセットで利用するファクトリ
// AWS SDK for Java
import com.amazonaws.AmazonClientException;
import com.amazonaws.services.kinesis.AmazonKinesis;
import com.amazonaws.services.kinesis.model.ProvisionedThroughputExceededException;
import com.amazonaws.services.kinesis.model.PutRecordRequest;
import com.amazonaws.services.kinesis.samples.datavis.model.HttpReferrerPair; // リファラ生成プログラム(名前空間ややこしいがsamples以下が今回チュートリアルのコードに)
import com.fasterxml.jackson.databind.ObjectMapper; // Jackson:Java用のJSONパーサーライブラリ
/**
* HTTPリファラのペアをKinesisへ送信
*/
public class HttpReferrerKinesisPutter {
private static final Log LOG = LogFactory.getLog(HttpReferrerKinesisPutter.class); // ログ、自身のクラスを喰わせるらしい
private HttpReferrerPairFactory referrerFactory; // リファラ生成用のファクトリ
private AmazonKinesis kinesis; // AWS SDK
private String streamName;
private final ObjectMapper JSON = new ObjectMapper(); // こいつを介してJavaオブジェクト↔︎JSONを変換
// リファラ生成のファクトリとAWS SDKと書き込み先のKineisi Stream名を受けてKinesisへと書き込む
// Javaではクラス名と同名の返り値なしメソッド宣言でコンストラクタとなる
public HttpReferrerKinesisPutter(HttpReferrerPairFactory pairFactory, AmazonKinesis kinesis, String streamName) {
// 引数エラー処理
if (pairFactory == null) {
throw new IllegalArgumentException("pairFactory must not be null");
}
if (kinesis == null) {
throw new IllegalArgumentException("kinesis must not be null");
}
if (streamName == null || streamName.isEmpty()) {
throw new IllegalArgumentException("streamName must not be null or empty");
}
this.referrerFactory = pairFactory; // うーんクラスって感じだ
this.kinesis = kinesis;
this.streamName = streamName;
}
// ↓みたいなのをJavadocという、@ でアノテーションを付けてドキュメントの生成が可能に(docstringとSphinx的な
/**
* 決められた数のHTTPリファラのペアをKinesisへ送信。これらはシーケンシャルに送信
* もしスループットが欲しい場合はmultiple {@link HttpReferrerKinesisPutter}sを利用
*
* @param n Kinesisへ送られるペアの数
* @param delayBetweenRecords レコード送信の間の待機時間、0以下の場合は無視される
* @param unitForDelay 待機時間として使用される時間の単位
*
* @throws InterruptedException 次のペアを送信するまでにインタラプトされた際のエクセプション
*/
public void sendPairs(long n, long delayBetweenRecords, TimeUnit unitForDelay) throws InterruptedException {
for (int i = 0; i < n && !Thread.currentThread().isInterrupted(); i++) { // currentThreadで現在のスレッドを取得
sendPair(); // 送信
Thread.sleep(unitForDelay.toMillis(delayBetweenRecords)); // 待機
}
}
/**
* HTTPリファラのペアを延々Kinesisへ連続して送信、インタラプトされた時のみ停止
* スループットが欲しい時はmultiple {@link HttpReferrerKinesisPutter}sの利用を検討すること
*
* @param delayBetweenRecords レコード送信の間の待機時間、0以下の場合は無視される
* @param unitForDelay 待機時間として使用される時間の単位
*
* @throws InterruptedException 次のペアを送信するまでにインタラプトされた際のエクセプション
*/
public void sendPairsIndefinitely(long delayBetweenRecords, TimeUnit unitForDelay) throws InterruptedException {
while (!Thread.currentThread().isInterrupted()) {
sendPair();
if (delayBetweenRecords > 0) {
Thread.sleep(unitForDelay.toMillis(delayBetweenRecords));
}
}
}
/**
* PutRecordを利用して単一のペアをKinesisへ送信
*/
private void sendPair() {
HttpReferrerPair pair = referrerFactory.create(); // リファラのペアを生成
byte[] bytes; //これで「byte型のリスト bytes」を宣言
try {
bytes = JSON.writeValueAsBytes(pair); // pairをUTF-8エンコーディングしたbyte配列にしてJSON化(シリアライズ)
} catch (IOException e) {
LOG.warn("Skipping pair. Unable to serialize: '" + pair + "'", e);
return;
}
PutRecordRequest putRecord = new PutRecordRequest();
putRecord.setStreamName(streamName);
// リソースをパーティションキーとして利用することで、与えられたリソースの合計を正確に算出できる
putRecord.setPartitionKey(pair.getResource());
putRecord.setData(ByteBuffer.wrap(bytes)); // おそらくbytesが何であれとりあえずメモリを確保しセット? 要調査
// このアプリケーションに順序は関係ないのでSequenceNumberForOrderingは送信しない
putRecord.setSequenceNumberForOrdering(null);
try {
kinesis.putRecord(putRecord);
} catch (ProvisionedThroughputExceededException ex) { // スループットが超過した場合
// ログがONなら出力
if (LOG.isDebugEnabled()) {
LOG.debug(String.format("Thread %s's Throughput exceeded. Waiting 10ms", Thread.currentThread().getName()));
}
// 10秒待つ
try {
Thread.sleep(10);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
} catch (AmazonClientException ex) {
LOG.warn("Error sending record to Amazon Kinesis.", ex);
}
}
}
これをHttpReferrerStreamWriter.javaのメインクラスから呼んで書き込みを行っています。ちゃんと書かれてるので長いですがやってることはデータの生成をKinesisへの書き込み、それを延々回してるだけですね。
プロデューサーではありますが、KPLは利用せずにAWS SDKを利用して書き込みしています。
データコンシューマー
反対にデータ取得を行う側をデータコンシューマーと呼びます。
このアプリケーションでは、決められた秒数間データストリームから取得・集約してそれをDynamoへ書き込むことで永続化をしています(その後Webアプリケーションが可視化する模様)。
こちらはAPIを直接呼ぶのではなくKCLを利用しています。ちょっと長いですがCountingRecordProcessor.javaを見てみます。
package com.amazonaws.services.kinesis.samples.datavis.kcl;
import java.io.IOException;
import java.util.List;
import java.util.Map;
// concurrent: マルチスレッド用のライブラリ
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
// kcl
import com.amazonaws.services.kinesis.clientlibrary.exceptions.InvalidStateException;
import com.amazonaws.services.kinesis.clientlibrary.exceptions.ShutdownException;
import com.amazonaws.services.kinesis.clientlibrary.exceptions.ThrottlingException;
import com.amazonaws.services.kinesis.clientlibrary.interfaces.IRecordProcessor;
import com.amazonaws.services.kinesis.clientlibrary.interfaces.IRecordProcessorCheckpointer;
import com.amazonaws.services.kinesis.clientlibrary.types.ShutdownReason;
import com.amazonaws.services.kinesis.model.Record;
import com.amazonaws.services.kinesis.samples.datavis.kcl.counter.SlidingWindowCounter;
import com.amazonaws.services.kinesis.samples.datavis.kcl.persistence.CountPersister;
import com.amazonaws.services.kinesis.samples.datavis.kcl.timing.Clock;
import com.amazonaws.services.kinesis.samples.datavis.kcl.timing.NanoClock;
import com.amazonaws.services.kinesis.samples.datavis.kcl.timing.Timer;
import com.fasterxml.jackson.databind.DeserializationFeature;
import com.fasterxml.jackson.databind.ObjectMapper;
/**
* (HttpReferrerPair -> count(pair))のマッピングを決められた時間幅の中で計算。カウントは与えられたインターバルの間に計算する
*
* @param <T> このプロセッサがカウント可能なレコードの型: <>でジェネリクスを表現(異なる型を引数にとるオブジェクト生成の際に利用)
*/
public class CountingRecordProcessor<T> implements IRecordProcessor { // implementsでインターフェースの実装、KCLではIRecordProcessor の実装を行う必要がある
private static final Log LOG = LogFactory.getLog(CountingRecordProcessor.class);
// タイマーを利用するためにロック
private static final Clock NANO_CLOCK = new NanoClock();
// チェックポイントをスケジュールするためのタイマー
private Timer checkpointTimer = new Timer(NANO_CLOCK);
// レコードをデシリアライズする為のJSONobjectマッパー
private final ObjectMapper JSON;
// distinct countを計算するまでのインターバル
private int computeIntervalInMillis;
// 合計を計算する際に見込まれるトータルの時間
private int computeRangeInMillis;
// インターバルあたりのカウントを保持する為のカウンター
private SlidingWindowCounter<T> counter;
// このプロセッサが計算を行うシャード
private String kinesisShardId;
// 異なるスレッドに対し、固定のレート(computeIntervalInMillis)でカウントのアップデートをスケジュール
private ScheduledExecutorService scheduledExecutor = Executors.newScheduledThreadPool(1);
// インターバルごとのカウント永続化を実施
private CountPersister<T> persister;
private CountingRecordProcessorConfig config;
// JSONとして受けるだろうレコードの型
private Class<T> recordType;
/**
* 新しいプロセッサを生成
*
* @param config このレコードプロセッサの設定
* @param recordType UTF-8 JSON文字列として受け取るだろうレコードの型
* @param persister このレコードプロセッサに永続化されるだろうカウント
* @param computeRangeInMillis distinct countを計算する範囲
* @param computeIntervalInMillis 全ての時間の全てのカウントの計算についてのインターバル
*/
public CountingRecordProcessor(CountingRecordProcessorConfig config,
Class<T> recordType,
CountPersister<T> persister,
int computeRangeInMillis,
int computeIntervalInMillis) {
if (config == null) {
throw new NullPointerException("config must not be null");
}
if (recordType == null) {
throw new NullPointerException("recordType must not be null");
}
if (persister == null) {
throw new NullPointerException("persister must not be null");
}
if (computeRangeInMillis <= 0) {
throw new IllegalArgumentException("computeRangeInMillis must be > 0");
}
if (computeIntervalInMillis <= 0) {
throw new IllegalArgumentException("computeIntervalInMillis must be > 0");
}
if (computeRangeInMillis % computeIntervalInMillis != 0) {
throw new IllegalArgumentException("compute range must be evenly divisible by compute interval to support "
+ "accurate intervals");
}
this.config = config;
this.recordType = recordType;
this.persister = persister;
this.computeRangeInMillis = computeRangeInMillis;
this.computeIntervalInMillis = computeIntervalInMillis;
// unknownなプロパティは無視する、デシリアライズしたレコードのオブジェクトマッパーを作る
JSON = new ObjectMapper();
JSON.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
}
@Override // アノテーション、実装スペルミスなどをチェックしてくれる
public void initialize(String shardId) {
kinesisShardId = shardId;
resetCheckpointAlarm();
persister.initialize();
// それぞれのインターバルのカウントの全ての範囲を保持するのに充分なサイズのスライディングウィンドウの作成
counter = new SlidingWindowCounter<>((int) (computeRangeInMillis / computeIntervalInMillis));
// 全てのcomputeIntervalInMillisごとに計算実行しカウントを永続化するスケジュールタスクの生成
scheduledExecutor.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
// カウンタを同期させる、そのためチェックポイントを作る最中はインターバルを進めるのを止める
synchronized (counter) {
try {
advanceOneInterval();
} catch (Exception ex) {
LOG.warn("Error advancing sliding window one interval (" + computeIntervalInMillis
+ "ms). Skipping this interval.", ex);
}
}
}
},
TimeUnit.SECONDS.toMillis(config.getInitialWindowAdvanceDelayInSeconds()),
computeIntervalInMillis,
TimeUnit.MILLISECONDS);
}
/**
* 内部のスライディングウィンドウカウンタをインターバルで1進める、ウィンドウがいっぱいであればカウント永続化を起動
*/
protected void advanceOneInterval() {
Map<T, Long> counts = null;
synchronized (counter) {
// 全部のレンジのデータを保持していた時のみカウントを永続化。プロセス開始時のそれぞれの一部のカウントは不要。
if (shouldPersistCounts()) {
counts = counter.getCounts();
counter.pruneEmptyObjects();
} else {
if (LOG.isDebugEnabled()) {
LOG.debug(String.format("We have not collected enough interval samples to calculate across the "
+ "entire range from shard %s. Skipping this interval.", kinesisShardId));
}
}
// ウィンドウを「ひと針」進める
counter.advanceWindow();
}
// 全てのレンジを保持していたらデータ永続化
if (counts != null) {
persister.persist(counts);
}
}
@Override
public void processRecords(List<Record> records, IRecordProcessorCheckpointer checkpointer) {
for (Record r : records) {
// Deserialize each record as an UTF-8 encoded JSON String of the type provided
// 渡された型について、それぞれのレコードをUTF-8のJSON文字列へとデシリアライズ
T pair;
try {
pair = JSON.readValue(r.getData().array(), recordType);
} catch (IOException e) {
LOG.warn("Skipping record. Unable to parse record into HttpReferrerPair. Partition Key: "
+ r.getPartitionKey() + ". Sequence Number: " + r.getSequenceNumber(),
e);
continue;
}
// 新しいペアのためにカウンタをインクリメント。毎回のインターバルでカウンタから読み込み合計を計算する他のスレッドが存在するため同期的。
synchronized (counter) {
counter.increment(pair);
}
}
// その時間であればチェックポイント
if (checkpointTimer.isTimeUp()) {
// チェックポイント中に計算が実行されて追加でカウントされることがないようロックをかける
synchronized (counter) {
checkpoint(checkpointer);
resetCheckpointAlarm();
}
}
}
/**
* どのカウントを永続化する前にも、全ての範囲のウィンドウで充分なサンプルなデータを集めておく必要がある
*
* @return {@code true} 全てのレンジについて全てのカウントを集め永続化に充分な数のデータを集めているか
*/
private boolean shouldPersistCounts() {
return counter.isWindowFull();
}
@Override
public void shutdown(IRecordProcessorCheckpointer checkpointer, ShutdownReason reason) {
LOG.info("Shutting down record processor for shard: " + kinesisShardId);
scheduledExecutor.shutdown();
try {
// 最高30秒エグゼキュータサービスのタスクが完了するまで待機
if (!scheduledExecutor.awaitTermination(30, TimeUnit.SECONDS)) {
LOG.warn("Failed to properly shut down interval thread pool for calculating interval counts and persisting them. Some counts may not have been persisted.");
} else {
// スレッドプールをシャットダウンに成功した時のみチェックポイント
// シャードの末尾に到達した後にチェックポイントすることが重要、それにより子シャードでデータの処理が開始できる
if (reason == ShutdownReason.TERMINATE) {
synchronized (counter) {
checkpoint(checkpointer);
}
}
}
} catch (InterruptedException ie) {
// クリーンなシャットダウンに失敗した場合、チェックポイントを行わない
scheduledExecutor.shutdownNow();
// このエラーについてはホストやプロセスのクラッシュやJVMのAbortと同様に扱う
LOG.fatal("Couldn't successfully persist data within the max wait time. Aborting the JVM to mimic a crash.");
System.exit(1);
}
}
/**
* 次のチェックポイントの為のタイマーを設定
*/
private void resetCheckpointAlarm() {
checkpointTimer.alarmIn(config.getCheckpointIntervalInSeconds(), TimeUnit.SECONDS);
}
/**
* リトライを伴うチェックポイント
*
* @param checkpointer
*/
private void checkpoint(IRecordProcessorCheckpointer checkpointer) {
LOG.info("Checkpointing shard " + kinesisShardId);
for (int i = 0; i < config.getCheckpointRetries(); i++) {
try {
// まず全ての計算されたカウントが永続化されたことを保証するためにpersisterをチェックポイントする
persister.checkpoint();
checkpointer.checkpoint();
return;
} catch (ShutdownException se) {
// プロセッサインスタンスがシャットダウンした場合チェックポイントは無視する(フェールオーバー)
LOG.info("Caught shutdown exception, skipping checkpoint.", se);
return;
} catch (ThrottlingException e) {
// 一時的障害(transient failure)の際には戻って再試行
if (i >= (config.getCheckpointRetries() - 1)) {
LOG.error("Checkpoint failed after " + (i + 1) + "attempts.", e);
break;
} else {
LOG.info("Transient issue when checkpointing - attempt " + (i + 1) + " of "
+ config.getCheckpointRetries(),
e);
}
} catch (InvalidStateException e) {
// DynamoDBに関する問題を示す(テーブルやIOPSをチェック)
LOG.error("Cannot save checkpoint to the DynamoDB table used by the Amazon Kinesis Client Library.", e);
break;
} catch (InterruptedException e) {
LOG.error("Error encountered while checkpointing count persister.", e);
// 再試行中に失敗
}
try {
Thread.sleep(config.getCheckpointBackoffTimeInSeconds());
} catch (InterruptedException e) {
LOG.debug("Interrupted sleep", e);
}
}
// このエラーについてはホストやプロセスのクラッシュやJVMのAbortと同様に扱う
LOG.fatal("Couldn't successfully persist data within max retry limit. Aborting the JVM to mimic a crash.");
System.exit(1);
}
}
高度なこと(高度なこと)始めててJava初心者にはちょっとツラいですが、IRecordProcessor メソッドを実装するをこのファイルではやっています(コメント日本語訳がしんどいのはご容赦ください)。
-
initialize(): 初期化、処理するシャードの特定 -
processRecords(): レコードの処理 -
shutdown(): 処理の終了
の3つのメソッドを実装して一連の処理を規定し、またprocessRecordにはすでに処理されたレコードを追跡するcheckpoint()メソッドが渡されています。これらにより、どのシャードのどの部分を処理しているかが制御されます。
実際には2秒間のウィンドウをスライドさせながら、上位3つの閲覧者をカウントし保存、と言うことを行なっているそうです(まだ完全にこの部分理解できてません、今後の課題。)
DynamoDB
KCLではアプリケーションの状態情報 (checkpointやシャードとワーカーの対応) を維持するためのテーブルを DynamoDB に作成します。実際にアプリケーションを走らせると、DynamoDBのテーブルが作成されていることがわかります。一方はカウント結果の格納用ですが、もう一方がこの状態管理用のテーブルです(KinesisDataVisSampleApp-KCLDynamoDBTable-[randomString])。中を覗いてみるとleaseKeyやcheckpointなど色々なkeyがあります。これらを用いてどの文を読んでいるか、について状態を管理しています。こちらのドキュメントに各keyの説明があります。
さしあたって内容の理解は飛ばしますが、読み取り速度に応じてのシャードの変更が必要になるでしょう。
ここまで勉強してなんですが、チュートリアル: AWS CLI を使用した Amazon Kinesis Data Streams の使用開始が次のチュートリアルのようなのでCLI経由で触ってみようと思います。