文法とか、よく使う命令文の一覧。
最低限、簡単なABAPレポートプログラムが書ける程度のものを目的とします。
例によって、ABAP環境の構築は大変~~(面倒くさい)~~なので、基本は文字だけとなります。
私はやっぱり悪くないよねぇ?
基本用語など
FIELD-SYMBOL
フィールドシンボル。C言語でいうところのポインタでもあるし、JavaでいうところのReflectionAPIでもある。
色々とやりたい放題できるけど、プロジェクトによっては使用が禁止されていることもあるので、用法・用量は守って使いましょう。
コメントの記述方法
行コメントは、行頭に「*」を記述する。
* コメントhoge
行中のコメントは、コメントにしたい箇所の頭に「"」を記述する。
" コメントfuga
文字リテラル
''(シングルクォーテーション)で囲う。
'hoge'
行末記号
.(ピリオド)を記述する。
'hoge'.
※Javaでいうところの「;」のことですが、これの名称って何と言うのでしょうね?
ここではとりあえず行末記号としました
チェーン命令
Javaで…近しいものが思い浮かばない…。
同じ命令を複数回実行する際に、記述を省略できる。
「:」(コロン)を記述する。
WRITE /01 'hoge'.
WRITE 10 'fuga'.
WRITE:
/01 'hoge',
10 'fuga'.
上記の命令文は、どちらも同じ結果になります。
メッセージクラス
SAP標準のものと、アドオンで作成されるものがある。
Tr-CD:SE91にて管理できる。(tblはT100というところ)
名称のとおり、メッセージのクラス。
メッセージクラス毎に番号を定義し、それを指定することでそのメッセージを呼び出すことができる。
うまく説明できてますか、これ?
選択テキスト
パラメータ項目に付随する、テキストラベルみたいなもの。
上限は30文字までらしいです。へー。
本編
全編通して、参考URLは下記になります。
ABAP Quick Reference
やっぱり公式サイトが一番なんですよね。
というか、日本語で充実しているサイトが少ないというか、海外フォーラムの方がABAP関連は活発というか…。
カスタマイズ系は、日本語でも活発なコミュニティがあるのですけどね。私コンサルじゃないから知らんけど。
REPORT文
プログラム開始の宣言文。これがないとはじまらない。
REPORT <rep> [MESSAGE-ID <mid>]
[NO STANDARD PAGE HEADING]
[LINE-SIZE <col>]
[LINE-COUNT <n>(<m>)].
<rep>:プログラムID 普通にやってると、=ソースファイル名になる。
※あまり意識したことなかったのですが、これって生成されるロードモジュール名なのでしょうかね?
MESSAGE-ID <mid>:そのプログラムで使用されるメッセージクラスを記述する。importとか、includeとか、そのあたり。
もちろん、ここで指定したメッセージクラスしか使えないとか、そういうわけではないです。
NO STANDARD PAGE HEADING:第2画面(実行結果画面)のヘッダ部を出力しない設定。見栄えとか、そんな感じ用。
LINE-SIZE <col>:第2画面(実行結果画面)での、出力可能列数の上限値を指定する。半角1、全角2とかだった気がする。
LINE-COUNT <n>(<m>):第2画面(実行結果画面)での、出力可能行数の上限値を指定する。
<n>が明細部の行数で、<m>がフッター部の行数。
たぶん、フッターの方を指定することは少ないと思います。
この上限値を超えると、改ページ処理が行われます。
TYPES句
そのプログラム内独自の型を定義する。通常、スコープがグローバルになる箇所で定義されることが多いはず。
(ローカルブロックでも定義可能です)
単一の型を定義することは少なくて、構造を定義することの方が多い気はします。
TYPES:
BEGIN OF <struc_name>,
...
<data_name> TYPE <type_name>,
...
END OF <struc_name>.
<struc_name>:構造の名称を指定します
<data_name>:その構造内でユニークとなる、コンポーネント名を指定します。
アクセスする方法は、<struc_name>-<data_name>です
<type_name>:abapディクショナリに登録されたデータ型などを指定します。
テーブル内のコンポーネントを指定することもできます
例:BELNR TYPE BKPF-BELNR.(会計伝票番号)など
DATA句
変数の定義です。
DATA:
...
<data_name> TYPE <type_name>,
...
<data_name> RANGE OF <type_name>,
<data_name> LIKE LINE OF <itab_name>.
RANGE OFは、レンジテーブルを意味します。
レンジテーブルとは、内部テーブルの一種です。主に、DBからのSELECT時の用途として定義することが多いと思います。
LIKE LINE OFは、<itab_name>(内部TBL)と同じ構造をもった構造を宣言しています。
RANGEテーブル
通称、範囲テーブル。…だと、そのまますぎますね。
RANGEテーブルは、4つの列(コンポーネント)から構成されています。
| 列名 | 内容 |
|---|---|
| SIGN | I(Include)/E(Exclude)を指定する。 後述するOPTION, LOW, HIGHに対して、含む(I)のか、含まない(E)のかを指定する。 基本Iしか使わないと思う |
| OPTION | EQ, NE, BT, NB, GE, GT, LE, LT, CP, NPなどを指定する。詳細は後述します |
| LOW | 取得対象とする範囲の下限値を指定する |
| HIGH | 取得対象とする範囲の上限値を指定する。ただし、OPTIONによっては指定できない(指定しても意味がない)ので注意 |
OPTIONの詳細です。
| OPTION値 | 意味 | HIGHの指定可否 |
|---|---|---|
| EQ | EQual、LOWと同じ値のものを対象とする | × |
| NE | Not Equal、LOWと異なる値のものを対象とする | × |
| BT | BeTween、LOW~HIGHの値を対象とする | 〇 |
| NB | Not Between、LOW~HIGHと異なる値のものを対象とする | 〇 |
| GE | Greator than Equal、LOWの値以上のものを対象とする | × |
| GT | Greater Than、LOWの値より大きいものを対象とする | × |
| LE | Less than Equal、LOWの値以下のものを対象とする | × |
| LT | Less Than、LOWの値より小さいものを対象とする | × |
| CP | Check Pattern、ワイルドカード(+、*、EscSym:#)を含めたLOWの値を対象とする | × |
| NP | Not check Pattern、ワイルドカードを含めたLOWの値と異なるものを対象とする | × |
| 色々とありますが、EQ、NE、BT、CPを覚えていたらなんとかなります。 | ||
| 上記ルールにのっとった値をRANGEテーブルに設定しておくことで、値のチェックが容易に行えます。 |
DATA:
W_GJAHR1 TYPE BKPF-GJAHR, "会計年度1
W_GJAHR2 TYPE BKPF-GJAHR, "会計年度2
R_GJAHR RANGE OF BKPF-GJAHR, "会計年度レンジテーブル
RH_GJAHR LIKE LINE OF R_GJAHR. "会計年度レンジテーブルヘッダ
W_GJAHR1 = 2018.
W_GJAHR2 = 2020.
RH_GJAHR-SIGH = 'I'.
RH_GJHAR-OPTION = 'BT'.
RH_GJAHR-LOW = 2019.
RH_GJAHR-HIGH = 2020.
APPEND RH_GJAHR TO R_GJAHR. "設定したレンジテーブルヘッダをレンジテーブルへ格納
* IFは他の言語と同じだよ
IF W_GJAHR1 IN R_GJAHR.
MESSAGE S000(ZTEST) WITH 'W_GJAHR1 is between 2019-2020'.
ENDIF.
IF W_GJAHR2 IN R_GJAHR.
MESSAGE S000(ZTEST) WITH 'W_GJAHR2 is between 2019-2020'.
ENDIF.
上記のようなコードがあった場合、実行されるのはW_GJAHR2の方のみです。
IF文の中にある「IN」句は、左辺に対して右辺の内容を評価する意味になります。
この「IN」句は、RANGEテーブルか、SELECT-OPTIONSテーブル(選択テーブル)しか使用できません。
今回の例ですと、W_GJAHRx(1or2)に対し、2019~2020であれば、評価の結果はTRUEとなります。
ですので、2018であるW_GJAHR1はFALSEとなり、2020であるW_GJAHR2はTRUE、MESSAGE文が実行される結果になります。
ワイルドカードは、「+」が任意の1文字、「*」が任意の0文字以上のもの、となります。
なお、RANGEテーブルは、SELECT文のWHERE句にも使用できます。
が、その際は注意が必要です。
ABAPにおけるSQL文は、OPEN-SQLとNATIVE-SQLがあります。
NATIVE-SQLは、普段よくみる感じのSQLで、例えばMySQL、OracleなどのRDBMSのSQL文法を記述します。
(S/4だと、インメモリDBなHANADBとか言われてるやつになるのですよね)
それに対しOPEN-SQLとは、ABAP独自のSQL文法となります。
詳細はSQL文のブロックに書きますが、INTO TABLE句や、今回のWHERE any IN RANGEなどです。
レポートプログラムを開発する際は、基本OPEN-SQLでの形式で記述します。しますよね?
そうやって記述されたOPEN-SQLを、NATIVE-SQLへ変換し、SQLを発行する、というのが一連の動作になります。
ようやく本題ですが、今回のようにWHERE句にてRANGEテーブルを指定した場合、NATIVE-SQLに変換すると…
全部展開されます。
具体例を見ましょう。
SELECT BKPF-BLART
BKPF-BELNR
FROM BKPF
WHERE BKPF-GJAHR IN R_GJAHR.
ここに記述してある「R_GJAHR」は、RANGEの例として記載したものと同じ値とします。
これはOPEN-SQL形式です。ではこれをNATIVE-SQLに変換します。
SELECT BKPF.BLART
BKPF.BELNR
FROM BKPF
WHERE BKPF.GJAHR = 2019
OR BKPF.GJAHR = 2020.
今回は2年分でしたのでこれだけで済みましたが、これが20年分であればそれだけ増えて…となります。
(こうして展開されたSQL文が長すぎてショートダンプということもよくあります)
アドオンの速度が悪く、それがDBアクセスを行っている場合はSELECT文の内容を見直すところから始めると良いかもしれません。
CONSTANTS句
定数の定義です。
この句を用いて定義されたものは定数となり、値の変更ができません。
CONSTANTS:
<const_name> TYPE <type_name> VALUE <value>.
<value>には変数は指定できません。定数のみを指定してください。
ひとまず、「ABAP_ON」と「ABAP_OFF」を知っておいたら色々と捗るんじゃないでしょうか。
PARAMETERS句
選択画面における、単一の入力項目を定義する際に使用されます。
PARAMETERS:
<param_name> TYPE <type_name>.
PARAMETERS:
<param_name> AS CHECKBOX.
PARAMETERS:
<param_name> RADIOBUTTON GROUP <group_name>,
<param_name> RADIOBUTTON GROUP <group_name>.
オプションとして、OBLIGATORY句というものがあり、これを指定するとその項目は必須入力項目になります。
もちろん、自身の手で入力チェックおよび必須入力チェックを実装することもできます。
AS CHECKBOXは、そのパラメータ項目をチェックボックスとして定義することを意味します。
実態としては、C型の1バイト項目として定義され、チェックがオンの場合は'X'が、オフの場合は''が設定されます。
RADIOBUTTONは、そのパラメータ項目をラジオボタンとして定義することを意味します。
その性質上、そのラジオボタンが属するGROUP、には、最低でも2つ以上のラジオボタンが属している必要があります。
チェックボックス同様、実態はC型の1バイト項目として定義され、該当するラジオボタンが選択されている場合は’X'が、選択されていない場合は''が設定されます。
SELECT-OPTIONS句
選択画面における、From-Toの入力項目を定義する際に使用されます。
SELECT-OPTIONS:
<sel_name> FOR <data_name>.
注意点は、通常の変数などと異なり、「TYPE」ではなく「FOR」を使用する点です。
<data_name>の<sel_name>のとおり、<data_name>の型を参照した、<sel_name>が定義されるということです。
ちなみに、このSELECT-OPTIONSの構造は、RANGEテーブルと同様に4つの列(コンポーネント)から成ります。
SQLにも使えますが注意点もRANGEテーブルと同じです。
画面定義文
こういう呼び名で適切かどうかわかりませんが。
選択画面を少しでも煌びやかにするための手法の一つです。
SELECTION-SCREEN BEGIN OF LINE ~ SELECTION-SCREEN END OF LINE.
通常、選択画面のパラメータ項目は上から順にしか配置できませんが、この文を使用することで、横並びに配置することができます。
主な使用例としては、チェックボックスやラジオボタンを横並びに配置することでしょうか。
注意点としては、選択テキスト(テキストラベル)を手で記述してあげる必要があります。記述方法は後述。
SELECTION-SCREEN POSITION <pos>
ポジション位置(カーソル)を設定する。
SELECTION-SCREEN BEGIN OF LINE.
SELECTION-SCREEN POSITION <pos>.
PARAMETERS:
<param_name> TYPE <type_name>.
SELECTION-SCREEN END OF LINE.
例えばこのように使う。<pos>の位置から、<param_name>の項目を表示させる、ということ。
ただし、前述のとおりこのままだと選択テキストは出力されない。
SELECTION-SCREEN COMMENT <pos>(<len>) <text> [FOR FIELD <param_name>]
任意の文字(コメント)を表示させるための文。選択テキストの代替項目として用いることが可能となる。
SELECTION-SCREEN BEGIN OF LINE.
SELECTION-SCREEN POSITION <pos>.
SELECTION-SCREEN COMMENT <pos>(<len>) <text>.
PARAMETERS:
<param_name> TYPE <type_name>.
SELECTION-SCREEN END OF LINE.
使用方法はこんな感じ。<pos>から<len>の長さ分、<text>を出力する。
注意点としては、COMMENTで指定する<pos>は、POSITIONの<pos>とは異なるということ。
POSITIONにより位置を変更した入力項目と、COMMENTによる出力位置が被ると、コンパイルエラーになります。
まぁ、コンパイラでエラー検知できる分にはいいよね。
FOR FIELDのオプションは、チェックボックスやラジオボタンだと付けた方が良いかも。
このオプションが指定されている場合、COMMENT文で出力されたテキストに対し操作すると、FOR FIELDで指定されたパラメータ項目も連動して操作されます。
例えば、COMMENTのテキストをクリックすると、そのパラメータ項目もクリックした扱いになります。ですので、チェックボックスやラジオボタンだと、テキストを選択することで、その項目を選択した扱いにできるということです。
チェックボックスやラジオボタンの入力域って小さいからね。~~(私みたいな)~~目が悪い人にやさしくなろう。
SELECTION-SCREEN BEGIN OF BLOCK <blk_name> WITH FRAME TITLE <title_name>.
複数の項目を一つのフレーム、枠として扱うための文です。

つまり、こういうこと。
本当は、WITH~以降はオプションですが、まぁ、ほぼセットみたいなものだと思います。
SELECTION-SCREEN関連はこれだけ知っていれば大体なんとかなります。大体。たぶん。知らんけど。
繰り返し処理
プログラミングの基本命令ですね。ABAPにもいくつかあります。
LOOP AT ~ ENDLOOP命令
繰り返し処理に使う命令。動作的には、ForEachです。(ちょっと違いますが)
LOOP AT <itab> INTO <itabh>.
ENDLOOP.
内部テーブル<itab>の内容を1件ずつ<itabh>で受けつつ、処理を行う感じ。
お察しのとおり、この構文ですと、<itabh>は事前に定義が必要です。
また、内部テーブルの更新を行う際に、<itabh>の内容を使って、MODIFYする必要があります。めんどう。
そんなあなたに、こんな構文。
LOOP AT <itab> ASSIGNING FIELD-SYMBOL(<fs>).
ENDLOOP.
これならば、動的に<itab>のLIKE lINE OFな型が<fs>に割り当てられ、処理できるのだ!!
しかも、内部テーブルを更新する際はMODIFYがいらない!!!
ASSIGNにより、直で内部テーブルの書き換えが可能(内部テーブルのポインタが割り当てられてるイメージ)なのだ!!!
…はい。調べてみたら、これはS/4からのインライン宣言という構文らしいです。
R/3だとこうなるらしいです。
FIELD-SYMBOL <fs>.
LOOP AT <itab> ASSIGNING <fs>.
ENDLOOP.
変数の事前定義が必須、ということですね。
それでも、直で内部テーブルの書き換えが可能という利点はあります。
まぁ、プロジェクトの規則でFIELD-SYMBOLの使用が禁止されていたら結局は、なのですが。
DO <n> TIMES ~ ENDDO命令
必ずこの回数分処理をする、という時に使います。
使途がいまいち思い浮かばない? FICO的にはあると便利です。
TYPES:
BEGIN OF TYP_TEST,
PERIOD01 TYPE BSEG-DMBTR,
PERIOD02 TYPE BSEG-DMBTR,
...
PERIOD12 TYPE BSEG-DMBTR,
END OF TYP_TEST.
CONSTANTS:
C_PERIOD(13) TYPE C VALUE 'S_TEST-PERIOD'.
DATA:
W_NUMC(2) TYPE NUMC,
W_SUM TYPE BSEG-DMBTR,
W_PERIOD(15) TYPE C,
S_TEST TYPE TYP_TEST.
FIELD-SYMBOL:
<F_PERIOD> TYPE BSEG-DMBTR.
W_NUMC = 0.
DO 12 TIMES.
CLEAR W_PERIOD.
W_NUMC = WNUMC + 1.
* 'S_TEST-PERIOD'と文字数値2桁を結合し、'S_TEST-PERIODnn'を生成(CONCATENATEは文字列結合の命令だよ。詳細は後ほど)
CONCATENATE C_PERIOD
W_NUMC
INTO W_PERIOD.
* 生成された'S_TEST-PERIODnn'の値を、<F_PERIOD>に割り当てる(Reflectionみたいな動き)
ASSIGN W_PERIOD TO <F_PERIOD>.
* 集計処理
TRY.
W_SUM = W_SUM + <F_PERIOD>.
CATCH CX_SY_ARITHMETIC_OVERFLOW.
W_SUM = 99999999.
ENDTRY.
ENDDO.
例えばこんな使い方。COLLECT? 知らない子ですねぇ
FICOは12(15)会計期間分のデータを保持しているテーブルがそれなりにあるので、DO命令は重宝するのです。
WHILE <log_exp> ~ ENDWHILE命令
一応あるけど、あまり使わないんじゃないでしょうか。
LOOPがあれば事足りちゃうし…。
お前それDO命令の前でも言えるの?
LOOP AT SCREEN命令
これに触れないわけにはいかない。
通常のLOOP命令とは別です。「LOOP AT SCREEN」という命令なのです。
ではこれがどういう命令かとなりますと、現在の画面要素プロパティを構造:SCREENへ読み込む。という処理です。
画面要素とは、要するに入力項目等のことです。そしてそのプロパティを読み込むということは、更新もできるわけで…。
つまり、特定のチェックボックス(ラジオボタン)が選択されている時のみ、関連する入力項目を表示/非表示させる、という制御が可能になります。
上記の制御を実現するには、SCREEN-NAME、SCREEN-INPUT、SCREEN-OUTPUTを知っていたら良いです。
構造SCREENの詳細はSAP公式を参照してください。
AUTHORITY-CHECK命令
権限チェック。アドオン開発ではかかせない命令です。
これの解説をする前に、SAPシステムにおける組織の考え方について簡単に説明します。
モデルとして、とある会社Aと、その子会社Bを例とします。
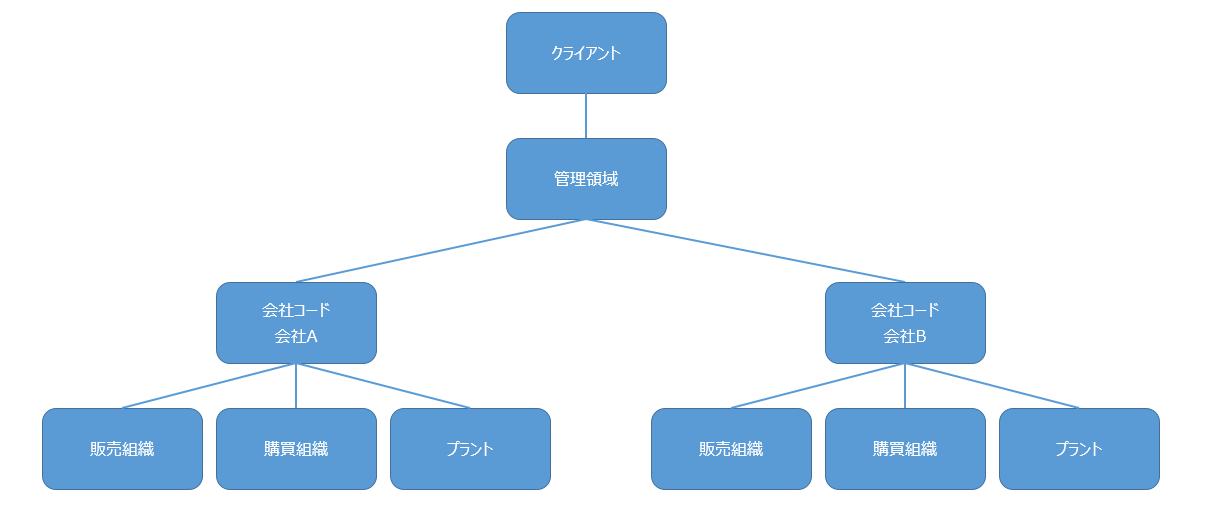
(実際は、原価センタとか利益センタとか事業領域とか他にも色々あるのゆるして)
一つのクライアント…この場合は、SAP導入を決めた親会社である、会社A…から始まり、
各会社の損益を結合、一元管理するための領域として管理領域。
各会社毎の管理単位である、会社コード。そこから、販売(営業部門)組織、購買(調達部門)組織、プラント(在庫管理)と続いていきます。
さて。親会社であるA会社の経理部門は、子会社であるB会社の経営状況を確認することもあるでしょう。
しかし、同じA会社所属であっても、営業部門に所属している一社員は、B会社のそれを確認する必要は、権限はあるのでしょうか。
このような、権限を制御するための手段として、権限オブジェクトというものが用意されています。(名前の通り。そのまま)
そして、権限オブジェクトに対し、操作者がその処理の実行権限を有しているかを判断するための命令が、AUTHORITY-CHECKなのです。
PARAMETERS:
P_BUKRS TYPE BKPF-BUKRS.
...
AUTHORITY-CHECK OBJECT 'F_BKPF_BUK'
ID 'ACTVT' FIELD '*'
ID 'BUKRS' FIELD P_BUKRS.
IF SY-SUBRC <> 0.
* えらーめっせーじ
ENDIF.
上記例は、会社コードの権限チェック一例です。
権限オブジェクト「F_BKPF_BUK」を用いて、入力された「P_BUKRS」に対して、各種権限(登録/更新/参照)を、実行ユーザが有しているかチェックを行っています。
チェック結果は、SY-SUBRCへ格納されます。
とりあえず雑に、SUBRC<>0であれば、その権限は持っていないという理解で良いのではないでしょうか。
(本当は、SUBRC=4とか、SUBRC=12とかあるらしいですよ。気になったら調べてみてください)
CASE文
いわゆるswitch文のことです。
CASE <log_exp>.
WHEN <operand1>.
...
WHEN <operandN>.
WHEN OTHERS.
ENDCASE.
特に言う事はないです。OTHERSは、default句のことです。各WHEN(case:)毎にbreakみたいなやつは記述しなくてもよいです。
あと、イディオム構文が使えます。ラジオボタンのチェックで割と使われてる感がします。
CASE 'X'.
WHEN RB_EXA1.
WHEN RB_EXA2.
ENDCASE.
こんな感じ。
CONCATENATE文
こんけーとねいと。通称、コンカチ。Excelの関数にも同じようなのがあった気がする。
文字列の結合ができます。
CONCATENATE <obj1> <obj2> ... <objN>
INTO <result>
SEPARATED BY <sep>.
SEPARATED BYは、区切り文字<sep>で区切って結合する、という意味です。オプションなので、指定しなくても良いです。
CLEAR命令
変数を初期化する感じ。COBOLでいうINITIALIZEです。
似たようなのに、REFRESH命令もあります。でも、これはS/4だと非推奨になってた気がする。
FREE命令
内部テーブル用。内部テーブルが使用しているメモリ領域を解放するらしいです。
WRITE命令
画面にABAP一覧として出力させたり、特定の書式で変数へ代入したり、色々できる命令です。
使う際は、通貨参照や数量参照などに注意しましょう。
内部テーブル関連
APPEND命令
内部テーブルに追加する。そのまま。
* 通常の書式
APPEND <itabh> TO <itab>.
* 内部テーブルへ追加すると同時に、そのFSを割り当てる
APPEND INITIAL LINE OF TO <itab> ASSIGNING <fs>.
<fs>-BUKRS = ''.
...
後者の方は、例によって<fs>の事前定義が必要です。
MODIFY命令
内部テーブルの内容を更新する。
* 速い
MODIFY <itab> INDEX <idx> FROM <itabh> TRANSPORTING <comp1> <comp2> ... <compN>.
* うぇあー
MODIFY <itab> FROM <itabh> TRANSPORTING <comp1> ... <compN> WHERE <log_exp>.
可能であれば、前者の書式の方が処理が速いです。
TRANSPORTINGは、そこで指定された列(コンポーネント)のみ更新する、ということです。
DELETE命令
内部テーブルからデータを削除する。そのまま。
* 速い
DELETE <itab> INDEX <idx>.
* 条件指定
DELETE <itab> WHERE <log_exp>.
* 重複削除(要ソート)
DELETE ADJACENT DUPLICATES FROM <itab> COMPARING <comp1> <comp2> ... <compN>.
1つ目、2つ目は特に言う事ないです。
3つ目の書式、これはSORT実行後であることが前提となりますが、重複データの削除が行えます。
キー重複の判定には、COMPARING以降で指定されたコンポーネントが対象となります。
SORT命令
SORT <itab> BY <comp1> [ASCENDING/DESCENDING]
<compN> [ASCENDING/DESCENDING].
省略するとASCです。
DESCRIBE TABLE
内部テーブルの情報を読み取ります。
DESCRIBE TABLE <itab> LINES <line>.
内部テーブルの行数を、<line>に格納します。
DESCRIBE TABLEはとりあえずこれを知っておいたらじゅうぶん。
READ命令
内部テーブルからデータを読み込む。
* 基本形
READ TABLE <itab> INTO <itabh>
WITH KEY <log_exp>
BINARY SEARCH.
* おまけ
READ TABLE <itab> TRANSPORTING NO FIELDS
WITH KEY <log_exp>
BINARY SEARCH.
BINARY SEARCHオプションは、実質的には必須みたいなもの。
ただし、事前にSORTしてないとダメです。当然だけど。
後者の書式は、単純に該当するキー項目を持つレコードがいるか、存在チェックを行うためのもの。
だから、項目を転送しないの。
おわり
これだけ知っていたら、本当に最低限レポートプログラムは書けます。
だって私がそうだったから!!!!
つかれた。Rubyで遊ぶんだぁ…。