はじめに
今から14年ほど前から1、この世には「D言語くん」と呼ばれるキャラクターが存在することが確認されています。しかしこのキャラクターが一体何なのか、人類は未だにそれを解明できていません。
Qiitaでは12月になると数多の研究者の人たちがその生態を発表してきましたが、その実態が生物なのかメカなのか、はたまた超常的な存在であるのかすらわかっていないのが現実です。
しかし人類は本当にこの間何もわからぬまま停滞していたのでしょうか?
いいえ、決してそんなことはありません!
人類はその間にも多くの技術革新を起こしており、ここでD言語くんの歴史はまた一歩先へ進む時がきました!!
ここに第1回 D言語くん認識選手権大会を開催します!!!
大会規定
概要
D言語くん認識選手権大会とは、ありとあらゆる技術を使ってD言語くんの正体を明らかにすべく、その詳細に踏み込んだ情報を取り出す技術を競い、その結果を独断と偏見によって評価するものです。
第1回なので、とてもシンプルな「画像認識」を用いた大会とし、以下のルールとしたいと思います。
- 公式のD言語くん画像を出場者に認識させる
- それぞれの画像に対してつけたタグのうち、信頼度(Confidence)が高いとされるものを抜き出して一覧とする
- 共通基準として数値的には
0.6とします
- 共通基準として数値的には
- それらを見て最もD言語くんを表しているであろうものを独断で評価する(不安)
はてさて、現代技術を使ってD言語くんの正体にどこまで迫れるのでしょうか!?
画像認識とは
深層学習、人工知能などなど、この界隈では説明が難しい四字熟語が多いですね。しかし人類はD言語くんと同じで正体がわからないゆるふわ感に惹かれるらしいです。
さて、今回使うのは画像ファイルを解析し、映っているものが「猫」であるとか「車」であるとか「食べ物」であるとか、そういったタグをつける「画像認識」のタスクです。
実装や用途によっては画像分類と呼ばれることもありますが、これ自体は非常に一般的な技術かと思われますので、世の参考情報にお任せして詳細は省略します。
今回は「どんなタグが付与されるのか」「その信頼度がどの程度か」といった点に着目しつつ、その内容を総合的に見て考察してみることが主目的となります。
使う画像
みなさんご存知この子です。公式絵。かわいい。

出典はこちらです。
https://github.com/dlang-community/d-mans
出場者紹介
記念すべき第1回として、現代技術の巨人と呼べるクラウドベースの画像認識サービスを提供する3社に参加いただきたいと思います!
今回は「ブラウザから無料/無登録で画像認識のAPIが試せる」「私が短時間で見つけられた」という厳正なる条件のもと、Microsoft、Google、IBMの3社に決定いたしました!
(AWSさんにも類似サービスはあるようですがデモページが見つけられず、あれば追試するのでお知らせください)
なお念のため記載しておきますが、どのサービスも大変素晴らしい技術であり、このような設定が良くない限定的なタスクで性能や善し悪しを決める意図はありません。
みなさん技術選定はご慎重に!
Microsoft: Computer Vision
Microsoftでは、画像認識やテキスト解析、音声や動画の解析などが行える「Cognitive Services」というサービスで様々なAPIを提供しています。
今回はその中から「Computer Vision」という画像認識APIを利用させていただきます。
リンク先にそのまま画像を認識させられる画面がついており、画像をアップロードするとポンと結果が得られるので大変簡単です。
米国本社のCEOが自らサンプル画像に出てくるあたり、非常に面白い取り組みをされていると感じますね!
Google: Vision AI
Googleが展開するGCP(Google Computing Platform)にも、「AI ビルディング ブロック」という名前で様々なデータを認識、解析するためのAPIが提供されています。
ここから今回の対象となるのは、画像認識全般を取り扱う「Vision AI」というものです。
名前にAIとついていると何だかわかりませんが非常に強そうな印象を受けますね!
- Vision AI
こちらも画像を選ぶだけでポンと試せるデモページになっています。
結果画面で属性以外にもWebの情報をベースにいろいろな情報が取得できるようになっており、このページを見ているだけで非常に面白く、re:CAPTCHAがついてるあたり本気度が高そうな印象を受けます。
IBM: Watson Visual Recognition
IBMからは、クイズ大会優勝の経歴でおなじみのWatsonさんシリーズで「Visual Recognition」というサービスがあります。
Watsonさんマジ万能ですね。
- Visual Recognition
デモページでは、下の左のほうに「Pre Trained Models」というメニューがありますので、そこから画像を読み込ませることでWatsonさんがよろしく解析してくれるようです。
あと信頼度に色が付くのがわかりやすくて良いと思います。
今大会で信頼度の閾値とした 0.6 はここを参考とさせていただきました。
結果
画像認識の処理は一瞬なので捉えることは難しく、競技中の内容は全カットで結果だけお伝えしていきます。
なお、クラウドサービスは日進月歩ですので、明日にはより良い結果が得られている可能性もあります。
これは2019年12月21日時点の一時的な結果ですので、それを踏まえて雰囲気中心でご覧ください。
一覧
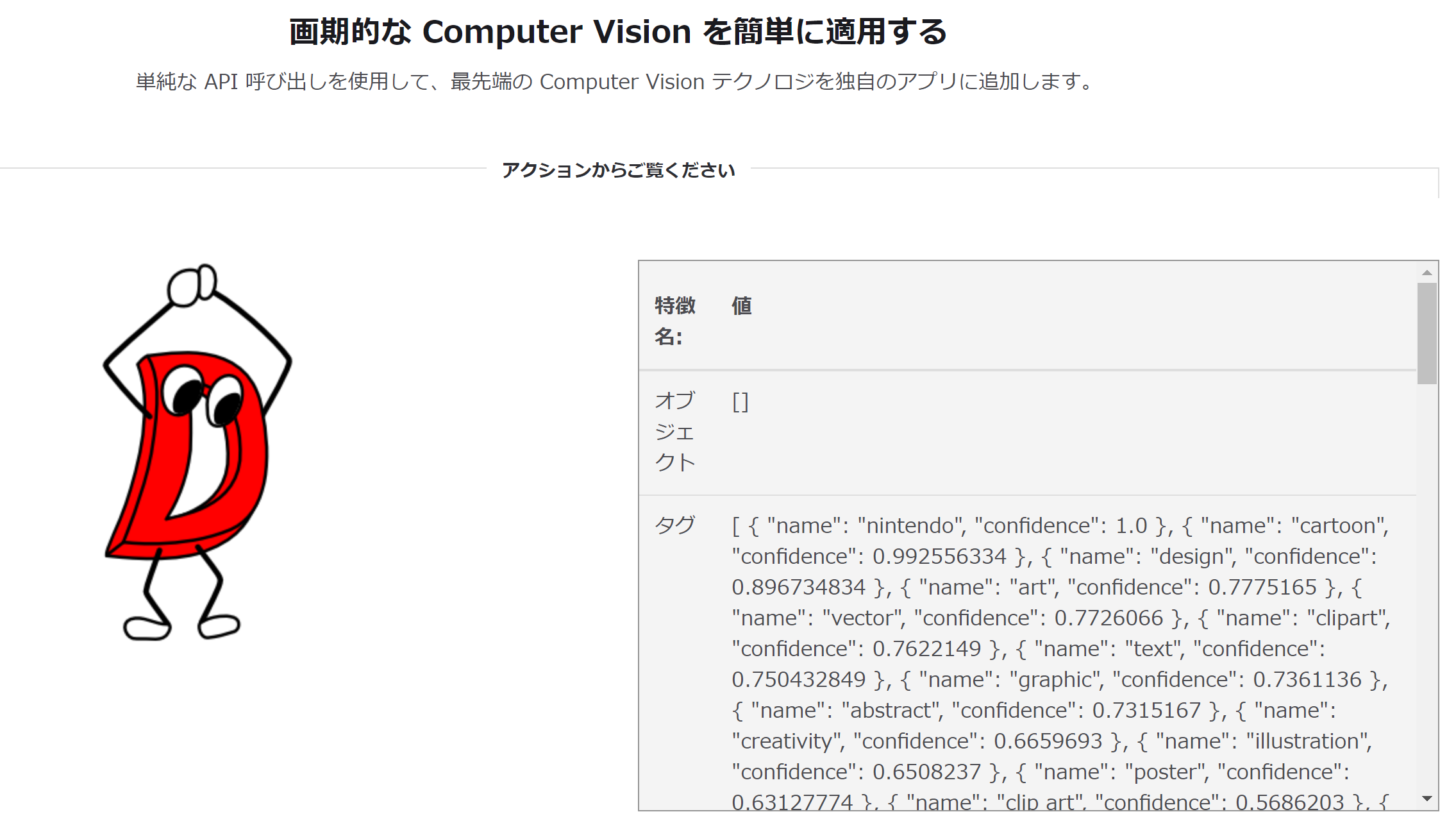
Microsoft: Computer Vision
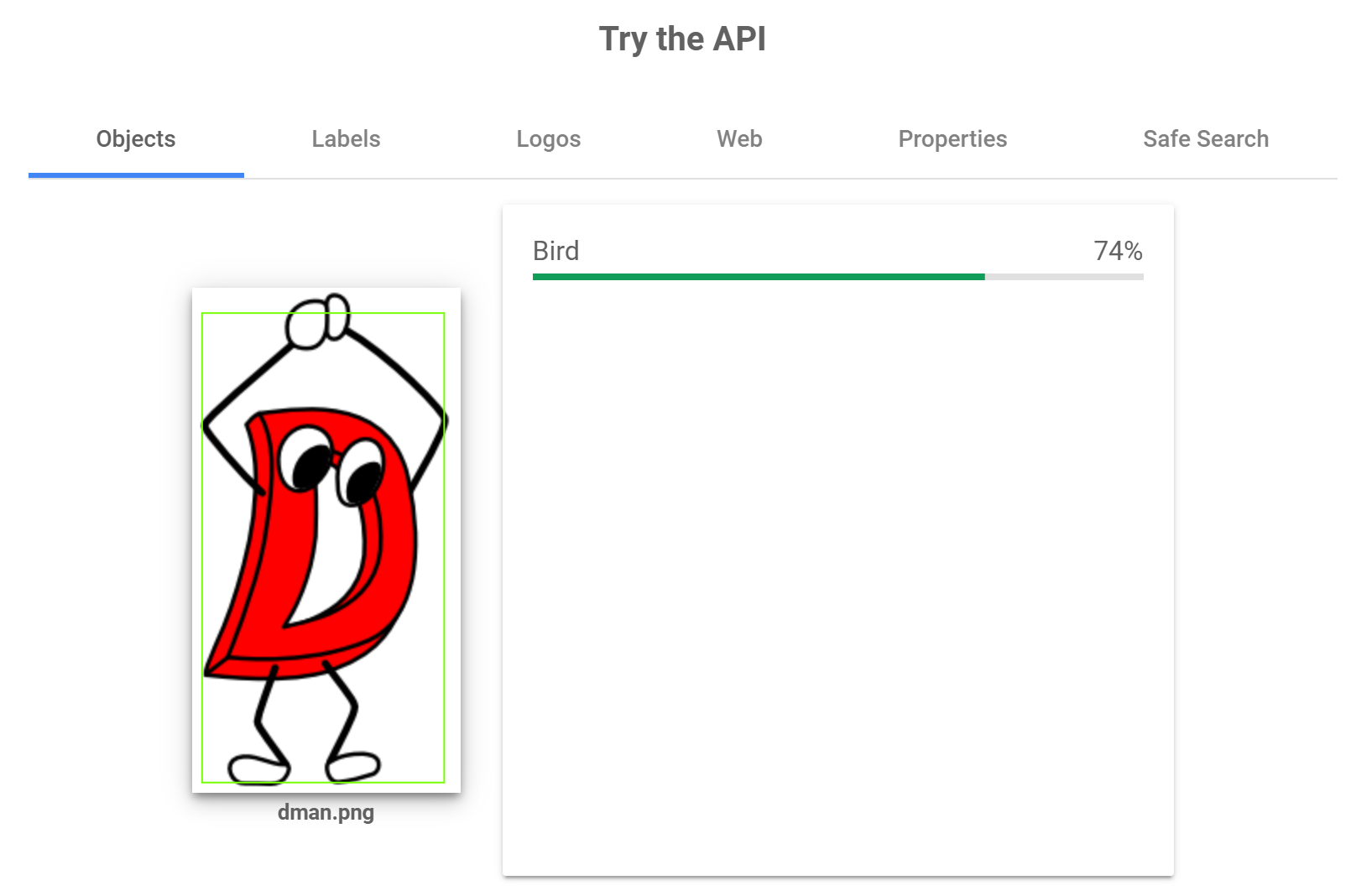
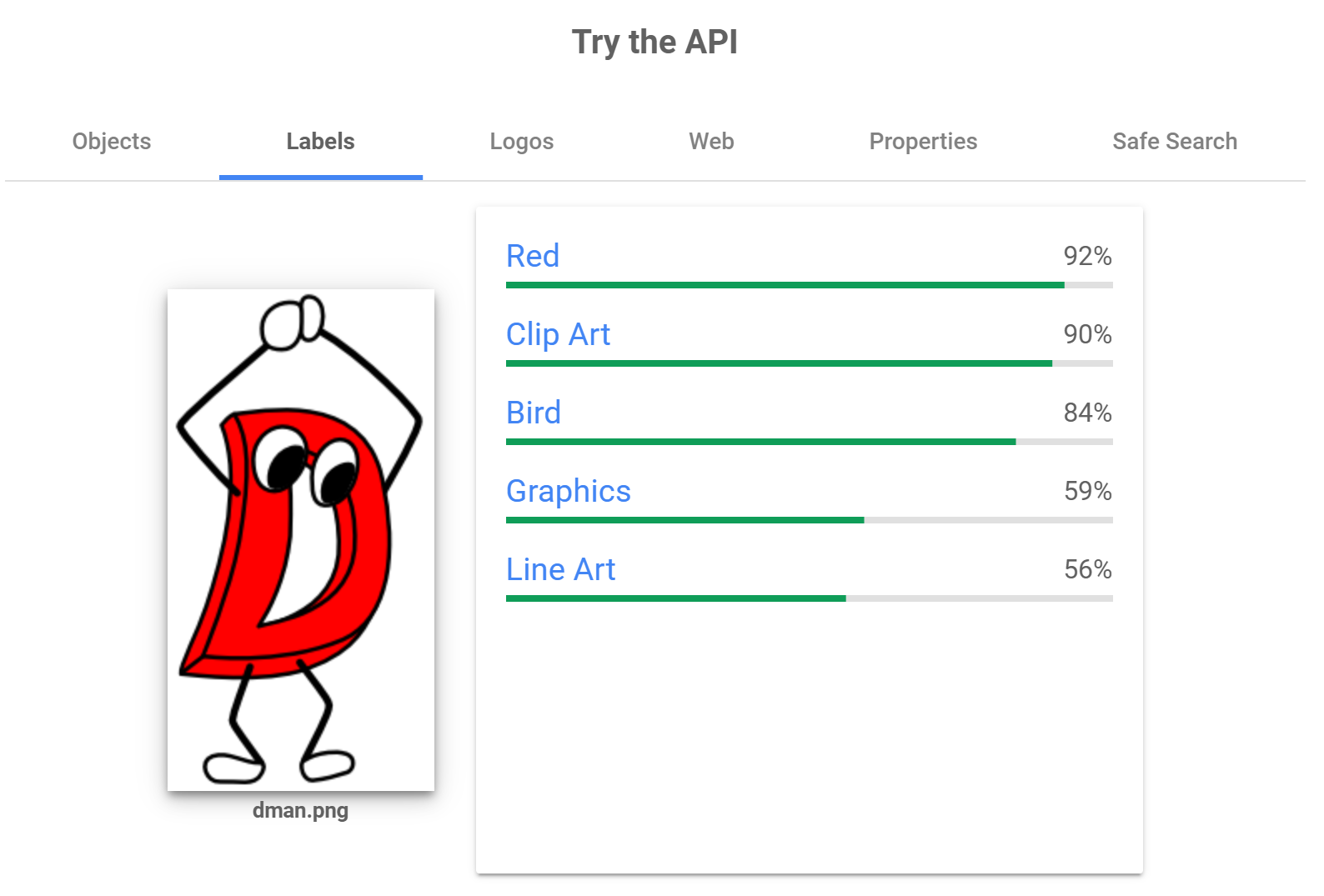
Google: Vision AI
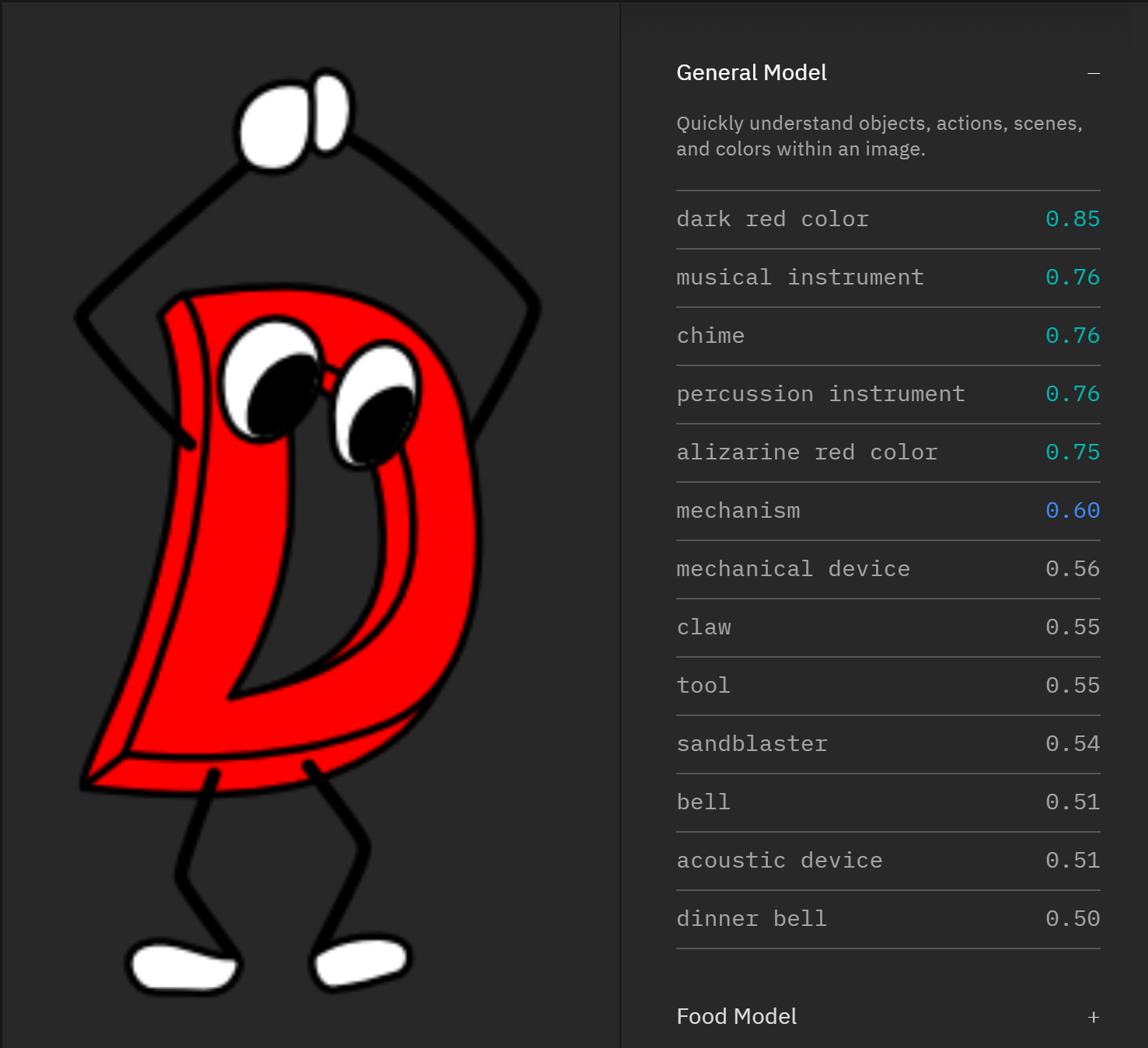
IBM: Visual Recognition
評価
結果整理
結果を見ると三者三様ですね。
ある程度信頼度が高い属性(0.6/60%以上)を高い順に抜き出すと、各選手以下の状況でした。
(サービス名だと折り返ったり区別しづらかったりしたので社名で記載してます)
| # | Microsoft | IBM | |
|---|---|---|---|
| 1 | nintendo | Red | dark red color |
| 2 | cartoon | Clip Art | musical instrument |
| 3 | design | Bird | chime |
| 4 | art | percussion instrument | |
| 5 | vector | alizarine red color | |
| 6 | clipart | mechanism | |
| 7 | text | ||
| 8 | graphic | ||
| 9 | abstract | ||
| 10 | creativity | ||
| 11 | illustration | ||
| 12 | poster |
画像種別(マンガや線画)を表すタグが付くのか、メインカラーを検出するのか、などなど、これだけでサービスの特徴がわかるような気もします。
Microsoft の Computer Vision は頭一つ抜けて多くの属性を見出しています。多くが90%以上の信頼度を持つものの、数の多さは逆に不安の表れとも取れるかもしれません。検出できた情報を一通り報告してくれる「できる作業員」タイプでしょうか。
逆に Google の Vision AI は抽出された属性が少なく、かなり確信があるのかまったくわからないのかいずれかのように見えます。種別と色と物体の属性で1つずつ示していることから、「簡潔に結論だけ伝える」タイプの人にも感じられますね。
IBM の Visual Recognition の結果はタグの傾向が似通っているものの、信頼度が90%を超えるものがなく全体的に自信がないようにも見えます。しかしその分類の細かさは際立っており、Watsonさんは非常に細かいことまで見て気にしてくれる「繊細」なタイプの性格なのかもしれません。
結果を解釈する
どの選手も容易に試せるAPIを提供し、読みやすい結果、素晴らしい内容を残してくれました。
全体的に「絵」「クリップアート」という認識はされているようなので、そのあたりを除外したうえで結果を解釈していきたいと思います。
Microsoft の Computer Vision は、要するに「ポケモン」だと言っているようです。信頼度100%で「nintendo」だと言っているのだから間違いありませんね。2(nintendoというタグがあるのがすごい…)
他にも「text」という属性があるのはおそらく「D」を認識したものと考えられ、「cartoon」や「art」など他の属性と絡めても非常に良くキャラクターを捉えていると考えられます。
Google の Vision AI いわく、要するに「鳥」だと言っているようです。
今までD言語くんに飛行属性を見出した人は少ないと思いますし、物体認識のほうでも74%の信頼度があるようなのでこれは重要な情報ですね。
IBM の Visual Recognition いわく、要するに「楽器(機械や道具)」だと言っているようです。
過去の研究ではD言語くんの生物的な側面が多く見られましたが、ここで「音楽性」や「機械や無機物」という可能性を提示してくれたのは示唆に富んでおり参考になりそうです。
まとめ
今大会では、D言語くんに対して「nintendo」などネタにちょうど良い示唆に富むタグを与えつつも「cartoon」や「text」などのタグをつけてその理解度の高さが伺えた、 Microsoft の Cognitive Service から、 Computer Vision の優勝としたいと思います!![]()
![]()
![]()
そして今回は現代技術の巨人たちによって、D言語くんから「ポケモン」「鳥」「楽器」という特徴的な属性が得られました。
しかしそれらの条件に該当しそうなポケモンは未だ見つかっていないため、将来新種のポケモンとして再発見されることでしょう。
また一番属性的に近いポケモンとして「ペラップ」が考えられそうですが、どうなんでしょうか…色とか違いますけど…この子なのかな…?(目が節穴)
さいごに
というわけで、画像認識という技術のイメージや各サービスの雰囲気が少しでも伝われば幸いです。
なお大切なことなので書いておくと、こういった1つの画像認識の結果について利用者が深く考察するのは大体アンチパターンです。そういう時は人間が見てしっかり判断をしましょう。
使う側としては技術やサービスの特性をしっかり考え、そこそこの精度で大量のデータを捌く/人が見るべきかどうかをフィルタリングする、という目標が設定できると良く、そうなるように心掛けることが重要です。
ただ、現代の画像認識技術をもってすれば、D言語くんはある程度認識が可能であることがわかりました。
今回は問題設定の甘さから、明確に「D」という表現を得ることはできませんでしたが、今後は画像の説明文を生成するようなAPIを使ってチャレンジし、「D」という表現が得られるかどうかを見守っていきたいと思います。
そして最終的に「ポケモン」という結論を得た今回ですが、その実D言語くんの正体は謎のまま、来年こそはこういった技術を使ってD言語くんの正体が解き明かされることを期待したいと思います!
画像認識は面白い!D言語くんかわいい!
-
先行研究で2005年に存在が確認されています。 https://qiita.com/__pandaman64__/items/da67cfbb809a141d91e2 ↩
-
試しにネット上のヒトカゲ画像を認識させても100%「nintendo」だと言っているので、これはほぼポケモンを表すタグだと考えられます。 ↩