この記事は CUDA & OpenCL Advent Calendar 2014 の 6 日目です。
スキルセットにHTML5入れるんならWebAudioとかWebCLとかもちろん使えるんですよね????
— 自然界 (@mizchi) December 3, 2014
という煽りを見たのでWebCLを触ってみました
http://webcl.nokiaresearch.com/
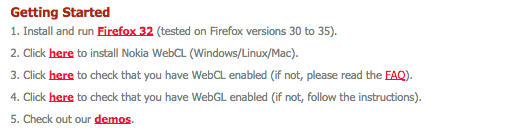
とあるので、その通りFirefox35をインストールしました。Firefox37 Nightlyはダメでした。
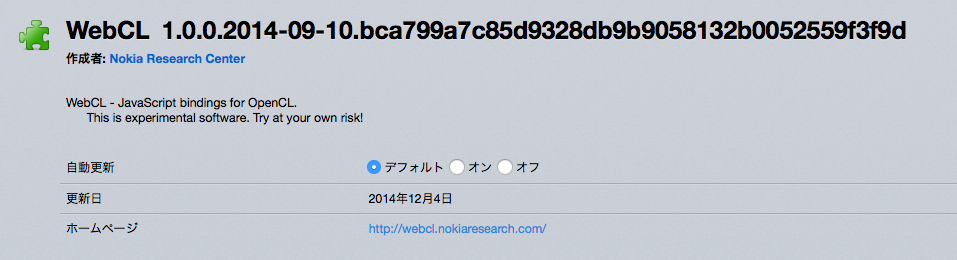
こんなが入ります
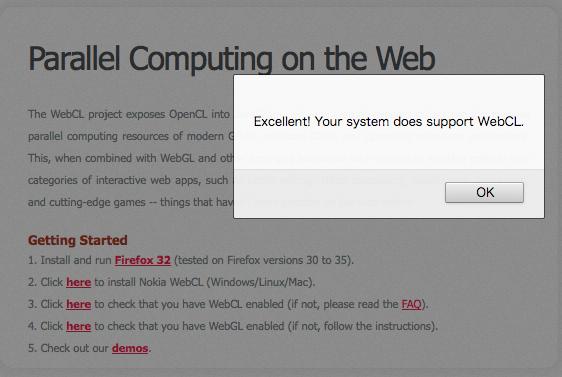
準備できました
とりあえずWebCL Tutorialというチュートリアルのコードを写経して雰囲気を掴んでいきます。
前日_likrさんがWebCLプログラミング入門というのを書かれているので解説は省きます。
OpenCL C言語についてはOpenCL 1.1 Reference Pagesを覗きながら書きました
また、OpenCLもGPGPUも初めてでしたので、ローカルワークサイズとグローバルワークサイズについてはワークアイテム・ワークグループ・次元数についてという記事を眺めてました
こうしてできたのがこちらになります
'WebCLでライフゲーム' http://t.co/Ik2lypzlHV #altjsdoit pic.twitter.com/Nge5t7zXMT
— 初期値鋭敏性 (@duxca) December 4, 2014
この実装では
globalWS = [width, height]
cmdQueue.enqueueNDRangeKernel(kernel, globalWS.length, null, globalWS)
というように次元数2でローカルワークアイテムを使わずグローバルワークアイテムのみをつかう実装にしました。
ところが、これで2000x2000のライフゲームを100ステップ動かしてみると、GPUよりCPUを使った方が早いという結果になりました
WebCLでの2000x2000のライフゲーム、HD Graphics 4000は16722ミリ秒、Intel(R) Core(TM) i5-3427U CPU @ 1.80GHzは3778ミリ秒 http://t.co/XKRyAvrMVA #altjsdoit
— 初期値鋭敏性 (@duxca) December 4, 2014
カーネルからグローバルメモリにアクセスしているのが原因のようです。
@duxca 昨晩altjsdoitに載せていたソースですかね?各ワークアイテムでグローバルメモリの読み込みが8回入るのが気になります。ローカルメモリはワークグループで共有されるので、ローカルメモリへ読み込み、同期、自分の場所を計算して書き込みとすると良いような気がします。
— Yosuke ONOUE (@_likr) December 4, 2014
kernel void cell(global char* vectorIn1,
global char* vectorOut,
uint vectorWidth){
int x = get_global_id(0);
int y = get_global_id(1);
int width = get_global_size(0);
int height = get_global_size(1);
int index = width * y + x;
int xplus = (x+1 <= width-1 ? x+1 : 0);
int yplus = (y+1 <= height-1 ? y+1 : 0);
int xminus = (0 <= x-1 ? x-1 : width-1);
int yminus = (0 <= y-1 ? y-1 : height-1);
int mylife = vectorIn1[width * y + x] > 0;
//グローバルメモリに9回アクセスしている
int nears[8] = {
vectorIn1[width * yplus + xminus],
vectorIn1[width * yplus + x ],
vectorIn1[width * yplus + xplus ],
vectorIn1[width * y + xminus],
// vectorIn1[width * y + x ],
vectorIn1[width * y + xplus ],
vectorIn1[width * yminus + xminus],
vectorIn1[width * yminus + x ],
vectorIn1[width * yminus + xplus ]
};
int lives = 0;
for(int i=0; i<8; i++){
if(nears[i]) lives++;
}
if(mylife){
if(lives == 0 || lives == 1){
vectorOut[index] = 0;
}else if(lives == 2 || lives == 3){
vectorOut[index] = 1;
}else{
vectorOut[index] = 0;
}
}else{
if(lives == 3){
vectorOut[index] = 1;
}else{
vectorOut[index] = 0;
}
}
}
OpenCLではメモリが階層化されており、アクセスの高速な順に次のようになっています
- プライベートメモリ
- ローカルメモリ
- コンスタントメモリ
- グローバルメモリ
- ホストメモリ
グローバルメモリはカーネルが直接アクセスできるメモリの中で一番遅いようです
そこでローカルメモリを利用したプログラムを書こうと思ったのですが・・・
ローカルメモリへ読み込み、同期、自分の場所を計算して書き込み、barrierを使えばできる気がするが・・・ムーア近傍取ってるのでローカルメモリの大きさ=ワークグループ内のアイテムの数にならないのがつらみ
— 初期値鋭敏性 (@duxca) December 5, 2014
どんどんGPUデバイスべったりなコードになっていくつらみ
— 初期値鋭敏性 (@duxca) December 5, 2014
21世紀のプログラマが書くプログラムじゃない
— 初期値鋭敏性 (@duxca) December 5, 2014
というように普段ブラウザで富豪プログラミングしてる私にはつらい領域に達してきたので今回はここまでです
ローカルメモリを使った実装はまた今度挑戦します
Advent Calendarの次の担当は@ykstさんです。