この記事は Google Cloud Platform(2) Advent Calendar 2016 の10日目の記事です。昨日は avvmoto さんの GAE/Go の記事でした。
この記事では Google Cloud Platform のサービスのひとつである Cloud Machine Learning (以下 Cloud ML と表記します)で提供されている Hyper Parameter Tuning という機能についての調査結果を報告します。
Google Cloud Machine Learning について
一言であわらすと TensofFlow を利用したプログラムに特化した実行環境のホスティングサービスです。
学習(training)のフェーズでは python のパッケージにしたプログラムを GCS(Google Cloud Storage)にアップロードして GCP 上のコンテナで走らせることができます。このコンテナはおそらく GKE (Google Container Engine) と同様のものが動いていると思われますが、利用者のプロジェクトの GKE クラスタが作られるわけではなくて、Cloud ML 用の環境が用意されて使ったぶんだけ利用料がかかるという、いわゆるフルマネージドなサービスです(利用料については Pricing のページ参照)。
また Cloud ML 上で学習した結果は GCS 上に保存することができ、それをModel としてデプロイすることで、予測(prediction)を API として呼び出すことができるようになります(Cloud ML 自体は public beta ですが Online prediction についてはドキュメントではまだ alpha feature とされています)。
この「学習時環境のホスティング」「学習済みモデルのホスティング」の2つが主な機能になっています。
詳しくはドキュメントを参照してください。
Hyper Parameter Tuning について
この Cloud ML の学習時の機能として Hyper Parameter Tuning というものがあります。これはモデルの学習時の learning rate、隠れ層のユニット数などの Hyper Parameter を指定した範囲内で変化させて最適な組み合わせを探索する、というのを自動的にやってくれるという便利機能です。
Tuning 対象の Hyper Parameter のオプション名1、型(タイプ)、範囲などは学習ジョブを投入する時に指定します。詳しい指定内容は API Reference の ParameterSpecの部分にありますがドキュメントのサンプルをみるだけでもだいたい雰囲気はつかめると思います。
また Hyper Parameter Tuning を用いる時には TensorFlow の summary として決まった名前の metric を保存するように要求されます。この metric を最小化(または最大化)することが Hyper Parameter Tuning の目的となります。
Hyper Parameter Tuning の探索アルゴリズムを探る
前置きが長くなりました、ここからが本題です。この Hyper Parameter Tuning ですが、要するに N 個のパラメータの組み合わせごとに決まる metric の最小値(または最大値)を探索する最適化問題と捉えることができます。実際にはほとんどの場合はモデル学習は乱数の影響を受けるので、同じ Hyper Parameter の組み合わせでも常に同じ metric が得られるとは限りませんが、そこは一意な結果が得られるものと(Cloud ML の Hyper Parameter Tuning 機能の探索アルゴリズムが仮定していると)仮定します。
またあきらかに勾配はわからないはずなので、勾配を用いた最適化方法ではないと考えられます。
さて Cloud ML の Hyper Parameter Tuning はどんな戦略で最適なパラメータを探索しているのでしょうか。Hyper Parameter の組み合わせ毎にある関数で metric を返すようなパッケージを作成して、どんな探索が行なわれるのかを調べてみました。
1変数実数値の場合
まずは簡単なところで、1変数で実数値を持つ Hyper Parameter の場合を試してみます。
parameter の範囲は全て $-1.0 <= x <= 1.0$ にしています。
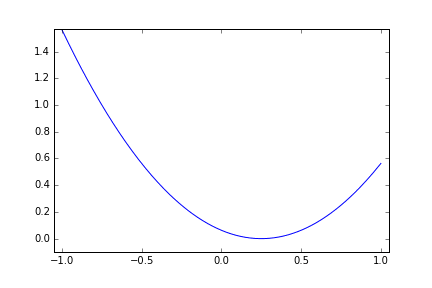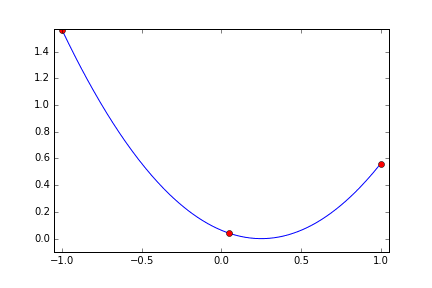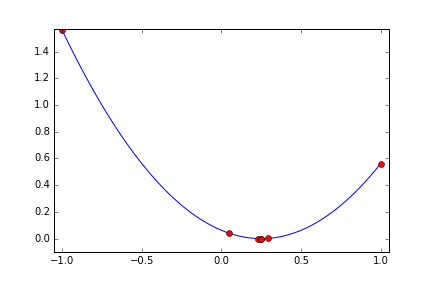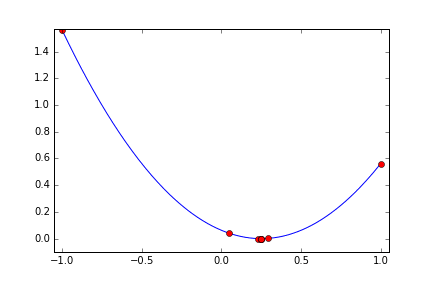
二次関数(x=0 で最小)
まずは簡単に、以下の関数で metric を返すようなモデルで実験してみます。 x=0.0 で最小値 0 になります。
metric = x^2
探索に使う回数は 10 回として Cloud ML が取った Hyper Parameter x の値を赤い点で順にプロットしてみます。
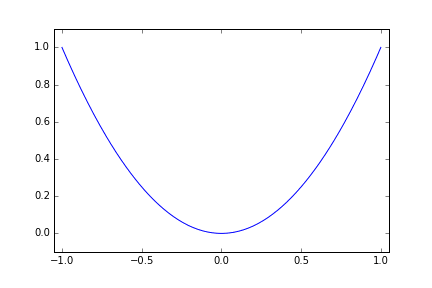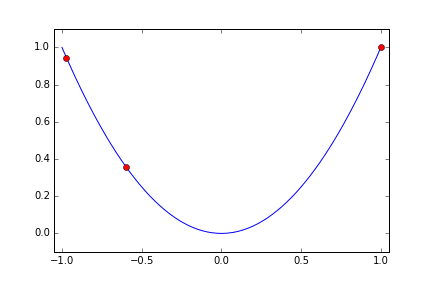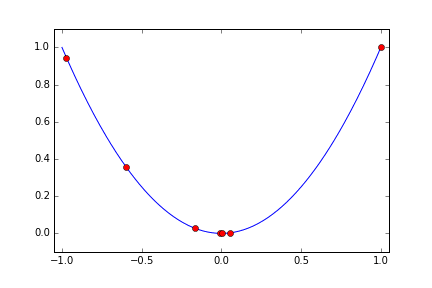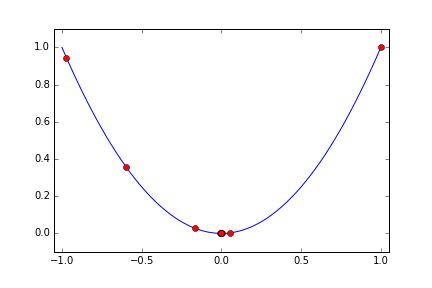
最初に x の値域の上限と下限に近い値を試したあと、割と急速に最小値に向かって寄せていっています。
二次関数(x=0.25 で最小)
次は最小値を取る x を中央からずらしてみます。 x=0.25 で最小値 0 になります。
metric = (x - 0.25)^2
今度は最初に x=0 付近を試していますが、やはり上限下限近くを試した後かなり的確に最小値付近を探索しています。
四次関数(局所解あり)
次は局所解のある関数にするため次のような四次関数にしてみます。 x=0.5 で最小値 0 になります。 x=-0.5 に局所解があります。
metric = ((x+0.5)^2+0.02)(x-0.5)^2
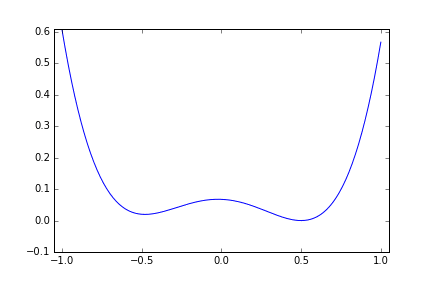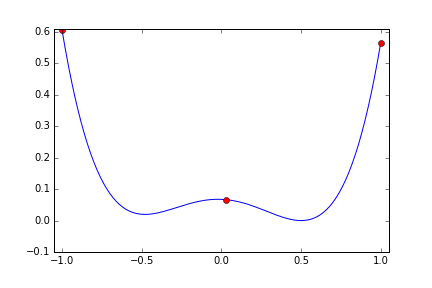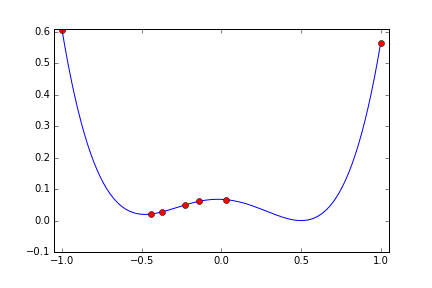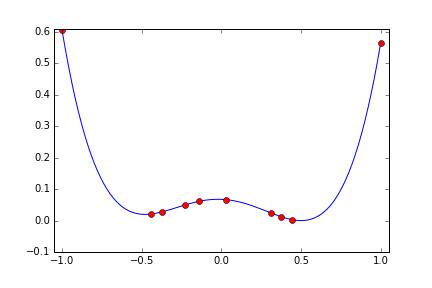
今度は x=-0.5 の局所解の周辺に落ち込むか? と思わせておいて 8回目にx=0.3760 と x>0 の範囲にジャンプして 0.5 に寄せています。まるで2つの谷があることを見抜いているみたいな探索のしかたです。二次関数の時に比べると 10回の試行では最適値に充分近づいているという感じはしませんが、もう少し試行回数を増やせばもっと良い結果を出してくれそうな気がします。
どうやら Cloud ML の Hyper Parameter は多項式のような分布に対してはかなり効率の良い探索をするようです。
デルタ関数
では非線形なものを、ということでもっと難しい以下のような関数を使ってみました。
metric = 1.0 - \frac{4 e ^{-100x}}{(1 + e^{-100x})^2}
sigmoid 関数の導関数を使って最小値 x=0 の付近でのみ大きく変動する関数です。
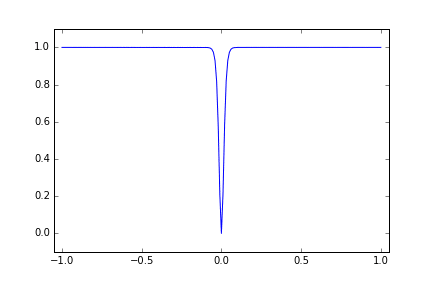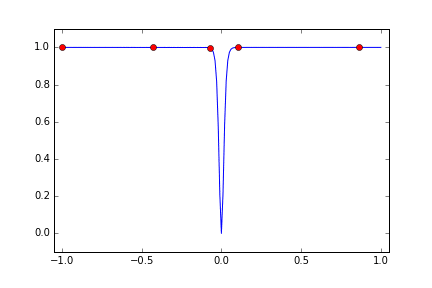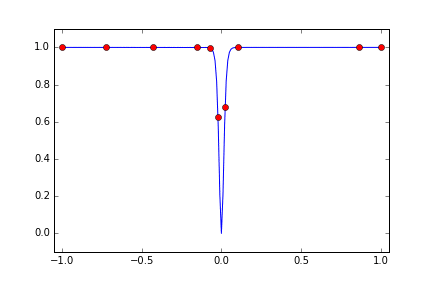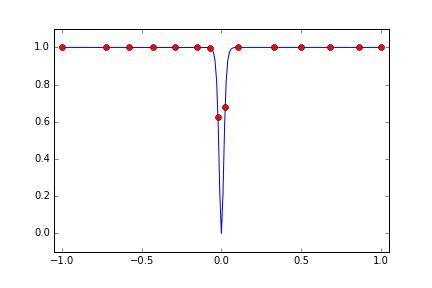
x=0 の付近をはなれると、浮動小数点数の精度の問題で 1.0 に貼りつくので、Cloud ML からみると最初はどこでも 1.0 という結果になりどうしようもなさそうだったので、試行回数を 15回に増やしています。すると 9, 10回目で x=0 の近傍の metric が小さくなるところをみつけたので、ここの近傍を絞り込むか? と思いきや、また離れた場所を探索しはじめて、結果的にはほぼまんべんなく探索しているような分布になりました。
多峰的な関数
それではもっと起伏の激しい多峰的な関数はどうだろうかということで次のような関数を使います。
1-\frac{cos(50x) + 2cos(x)}{3}
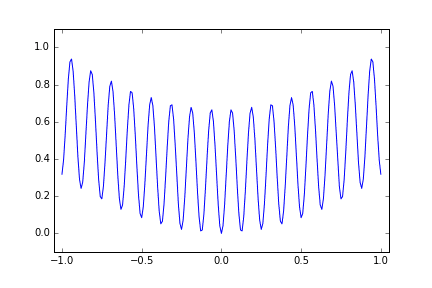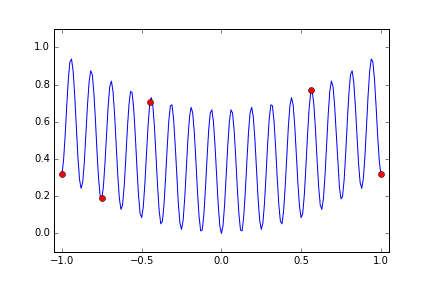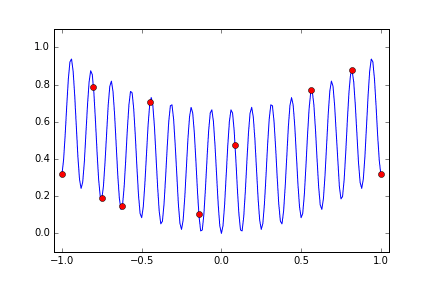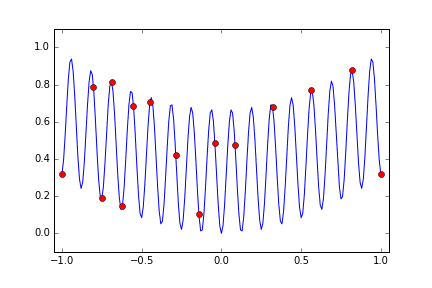
今度も試行回数は 15回にしています。偶然小さな metric を得た x<0 の領域のほうに多めに分布していますがやはりまんべんなく探索しているようになりました。
2変数実数値の場合
Hyper Parameter を x, y の2つの実数値にして探索してみます。
二次関数
まずはやはり二元二次関数でやってみます。
metric = x^2 + y^2
3D グラフにしてみるとこんな形です。 (x, y) = (0, 0) で最小値 0 を取ります。
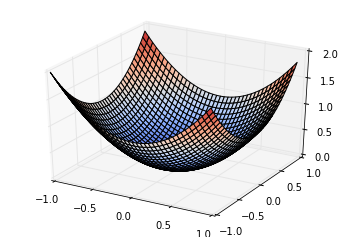
探索の様子をプロットしてみます。パラメータ数が 1 → 2 に増えていますから、Hyper Parameter Tuning の trial 数も 30 に増やしてみています。
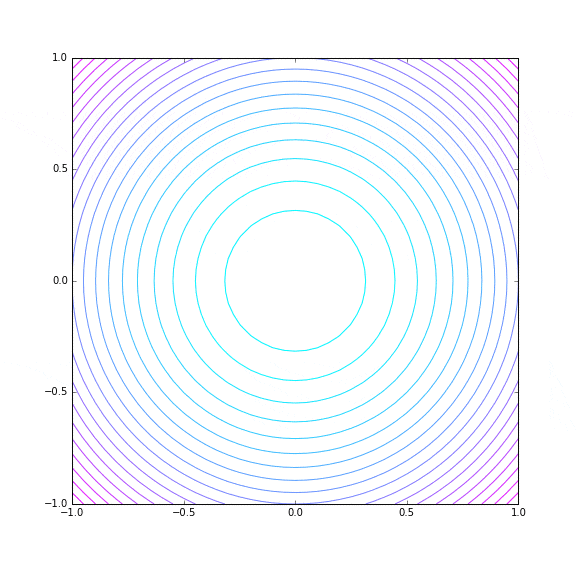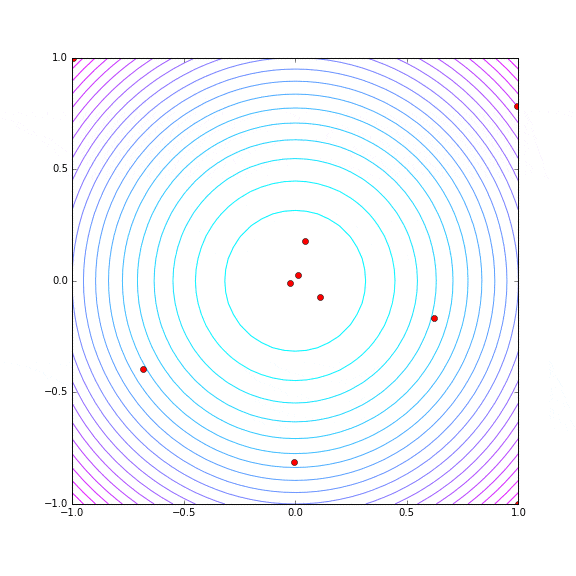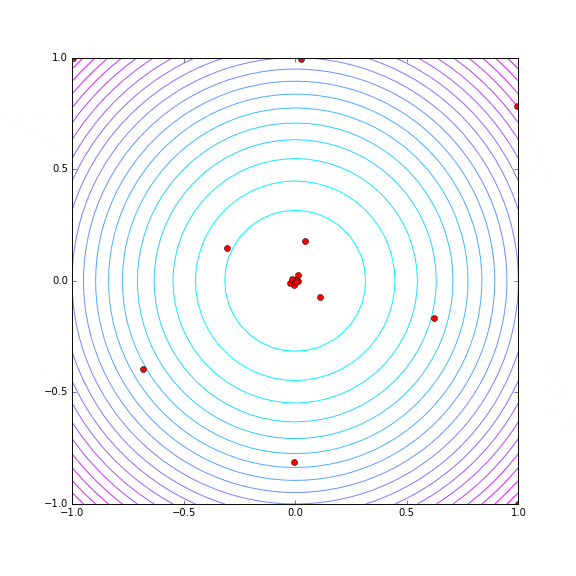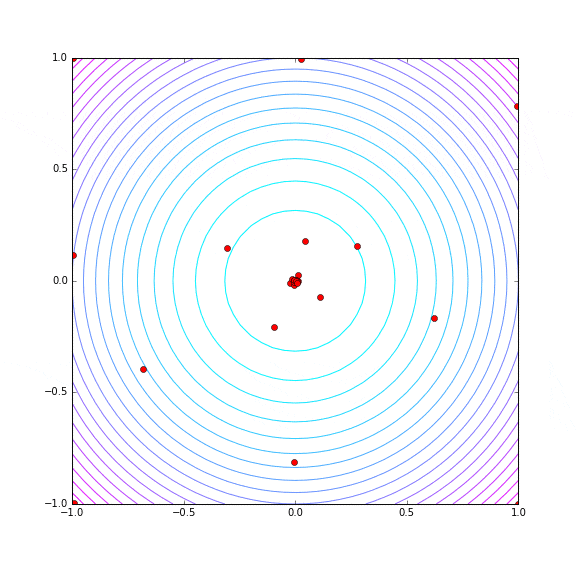
2次元になってもかなり最小値付近を重点的に探索していて、分布の形状を見抜いているような感触があります。
Ackley function
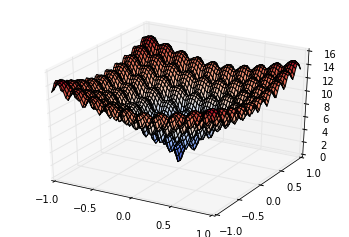
二次元の多峰的な関数をやってみたくて最適化問題のテスト関数のひとつ Ackley function を値域が $ -1 <= x <= 1$, $-1 <= y <= 1$ になるようにスケールしたものを利用します(数式は Wikipedia のものを参考にしました)。
metric = 20 + e - 20 e^{-0.2\sqrt{12.5(x^2+y^2)}} - e^{0.5(cos(10\pi x)+cos(10\pi y))}
3D グラフにするとこんな感じです。(x, y) = (0, 0) で最小値 0 を取ります。
同じく trial 数 30 で Hyper Parameter Tuning の探索の様子をプロットしてみます。
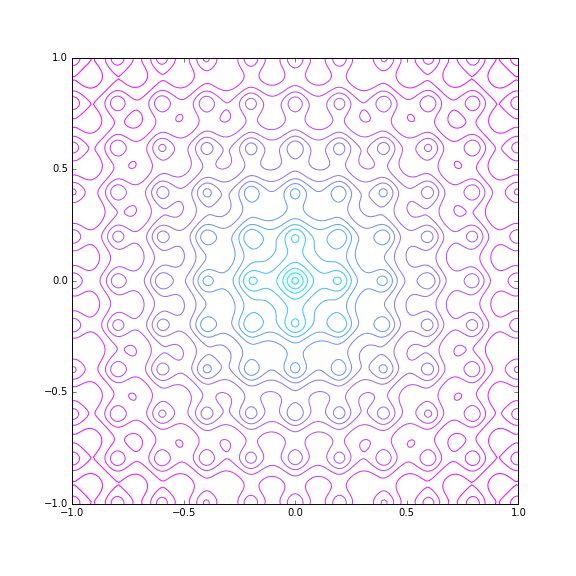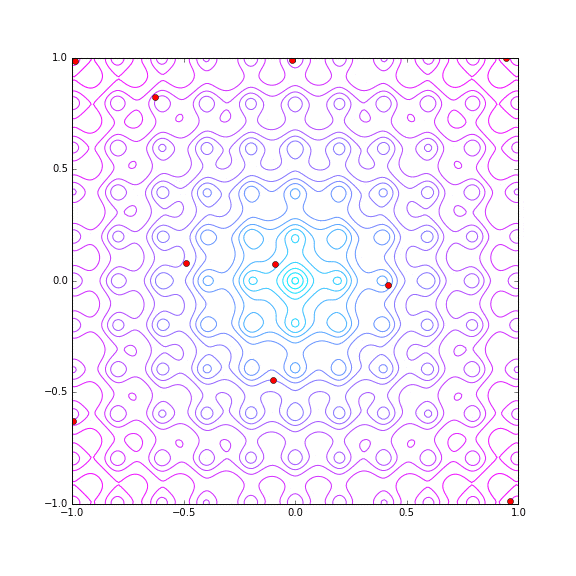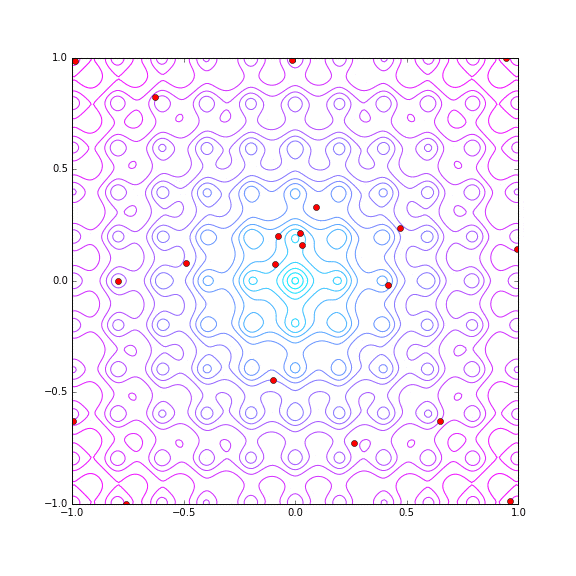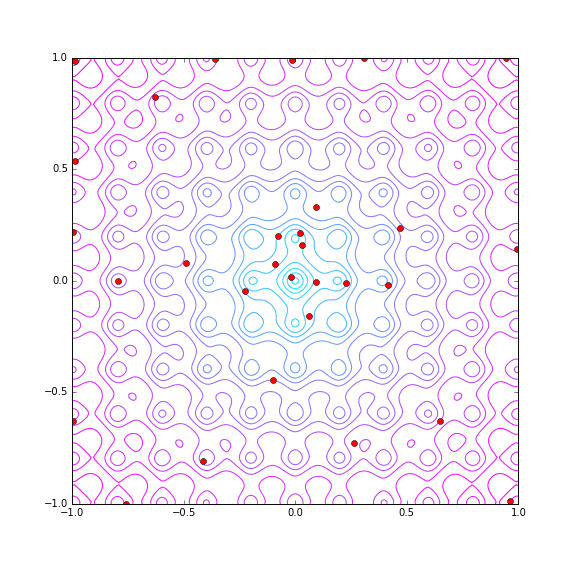
21回目でたまたま? (x, y) = (-0.018704156236258651, 0.018851304268984848) で metric = 1.21807169914 という最小値の近傍をあてていますが、その後わりとばらけた探索をしています。若干原点付近(平均的には metric が小さい)を重点的に探索しているようではありますが。
このあたりで、Google Cloud Platform のプロジェクトの利用料金が気になってきたので、今回の実験はここまでにします。
パラメータが整数の場合や Discrete (あらかじめ決められた値から選択する方式の場合についても調べたかったのですが、また別の機会があればやってみたいと思います。
考察
最適化アルゴリズムに詳しくないので、Cloud ML がどんなアルゴリズムを使ってるのか、ずばり推理することはできません。ただ二次関数や四次関数の時の狙い打ちしているような挙動をみると、最初の数回で多項式として推定してうまくいっているようだったらそれを使いだめだったら何らかの大域探索の手法に切りかえる、というような複数のアルゴリズムを組み合わせているのではないか、という感じがします。
この結果からどんな手法なのか推測できるぞ、という方はぜひ教えてください。
私見ですが、現時点の Cloud ML の Hyper Parameter Tuning は、すくなくとも実数のパラメータの探索については、(あまり次数の高くない)多項式で近似されうるような、いくつか局所解はあっても探索範囲内で比較的なだらかに変化しているようなものではとても効率的に働き、そうでない時はそれなりなので最適値が非常に狭い範囲にあるようなことが予想されるときは trial 数を充分増やす必要があるのではないか、という印象です。
Cloud ML はクラウドサービスですし、いつのまにか機能が強化されていたり細かい挙動がこっそり変化しているというのは GCP のサービスではよくあることです。今回の実験は2016年11月時点のものでこの先 Hyper Parameter Tuning の探索方法や性能が変化する可能性は大いにあります。
なお、わたしが Hyper Parameter Tuning の探索方法を調べようと思った動機は、サンプルにあるように Hyper Parameter として隠れ層(hidden layer)のユニット数だけでなく層の数も同時に調整の対象にしたいので、ひとつのパラメータに層の数と各層のユニット数というのを詰め込んでエンコードしてそのパラメータを Hyper Parameter Tuning の対象にするという方法を考えたからでした。
たとえば n進グレイコード のようなエンコード方法を用いることで、ひとつのパラメータが1増減した時にどこかの層のユニットが1つ増減するだけで局所的にはあまり大きく変動しないようにする(つまり metric がそのひとつのパラメータに対して連続的な関数になることを期待できる。ただし層の数が増減するところでは不連続になってしまう)ことができます。しかしそのようにエンコードしたパラメータに対して metric はかなり多峰的な関数になると予想できたので、Hyper Parameter Tuning がそのような分布をする関数に対してどういう戦略をしているのかを調べようと思ったのがきっかけでした。
結論としては現状ではひとつのパラメータにつめこむのは探索の効率が悪くなりそうなので、やはり層ごとにユニット数の調節をしてもらうほうが良さそうです。
また Cloud ML の training では maxParallelTrials というパラメータで Hyper Parameter Tuning の trial を並列に実行するよう指示することもできます。リファレンスによるとこの場合は既に完了している trial のみ考慮して Hyper Parameter を決めるそうなので、数打ちゃ当たる戦法の場合でなければ1つずつ実行するほうが予測精度は良さそうです。
かかった費用
ちなみに、この実験のために作成した Google Cloud Platform のプロジェクトの利用金額は Training time が 23.33 hour で $11.43 でした。

実験に使った Python パッケージは Hyper Parameter に対して metric を計算して tf.train.SummaryWriter で書き出すだけのものなのでほとんど処理時間はかからないのですが、provisioning やパッケージのインストール、その他謎の待ち時間などのオーバヘッドがあるので、1 trial で 2, 3分くらいかかってしまいます。実際に意味のある学習処理を行う場合にはとても時間がかかるのであまり気にならないオーバヘッドだと思いますが、trial の間のインターバルが妙に長いのは短縮できるものなら速くなってくれれば嬉しいです。
最後に
Cloud ML の大きな利点は Distributed TensorFlow (今回は利用していませんが)を含むの環境のセットアップをしてくれるという点と Hyper Parameter Tuning の機能を提供してくれていることだと思います。今回の実験で Hyper Parameter Tuning はどうやらただの Grid Search よりはちょっと賢い探索をしてくれているのではないかという感触を得ました。また来年の初めには GPU も利用可能になるそうですので、高速化も期待できそうです。
明日の記事は、残念ながらこれを書いている時点でまだ決まっていません。誰か書いてくれるといいのですが。
-
Hyper Parameter Tuning を利用する時には Tuning 対象の Hyper Parameter はコマンドラインオプションで指定できるように実装しておく必要があります。 ↩