はじめに
当記事はkaggleのLearnのFeature EngineeringのWhat Is Feature Engineeringを翻訳して備忘としたものです。
拙い英語力なので間違い等あればご指摘いただけたらと思います。
まとめ:【kaggle】翻訳記事まとめ【備忘翻訳】
前:【kaggle】データの視覚化 - プロットタイプとカスタムスタイルの設定【備忘翻訳】
次:【kaggle】特徴量エンジニアリング - 相互情報量【備忘翻訳】
当記事に含まれるコードはkaggle内のnotebook内で正常に動作します。動作を試したい場合はkaggleのnotebookで試してください。
特徴量エンジニアリングとは
より良い機能を作成するための手順と原則を学びます。
特徴量エンジニアリングへようこそ!
このコースでは、優れた機械学習モデルを構築するための最も重要なステップの1つである特徴量エンジニアリングについて学習します。
- 相互情報量を用いてどの特徴が最も重要であるかを判断する
- いくつかの現実世界の問題領域で新しい機能を発明する
- ターゲットエンコーディングを使用したhigh-cardinality categoricalsエンコード
- k-means 法クラスタリングによるセグメンテーション機能の作成
- 主成分分析を使用してデータセットの変化を特徴に分解する
実践的な演習により、これらすべてのテクニックを適用した完全なnotebookが作成され、House Prices Getting Startedコンテストに応募できるようになります。このコースを修了すると、パフォーマンスをさらに向上させるために使用できるアイデアがいくつか得られます。
準備はいいですか?さあ、行きましょう!
特徴量エンジニアリングの目的
特徴量エンジニアリングの目標は、単にデータを現在の問題により適合させることです。
暑さ指数や風冷指数などの「体感温度」について考えてみましょう。これらの量は、気温、湿度、風速など、直接測定できるものに基づいて、人間が感じる温度を測定しようとします。体感温度は一種の特徴量エンジニアリング、つまり観測されたデータを、私たちが実際に気にしているもの、つまり外で実際にどのように感じられるかを関連付けようとする試みの結果であると考えることができます。
特徴量エンジニアリングを実行すると、次のような効果が得られます。
- モデルの予測性能を向上させる
- 計算やデータの必要性を減らす
- 結果の解釈可能性を向上させる
特徴量エンジニアリングの基本原則
特徴量が有用であるためには、モデルが学習できるターゲットとの関係がなければなりません。たとえば、線形モデルは線形関係のみを学習できます。したがって、線形モデルを使用する場合、ゴールは、特徴量を変換して、ターゲットとの関係を線形にすることです。
ここで重要な考え方は、特徴量に適用する変換が本質的にモデル自身の一部になるということです。例えば、正方形の土地の一片の長さからその土地の価格を予測しようとしているとします。線形モデルを長さに直接当てはめると、関係が線形ではないため、結果は良くありません。
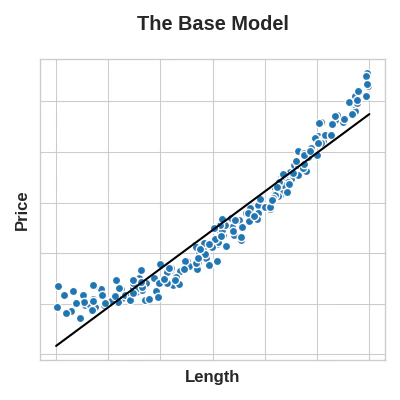
線形モデルは、長さのみを特徴量とすると適合性が悪くなります。
しかし、長さの特徴量を二乗して「面積」を取得すると、直線関係になります。特徴量セットにAreaを追加すると、この線形モデルが放物線状に適合します。言い換えれば、特徴量を二乗すると、線形モデルに二乗された特徴量に適合するモデルになります。
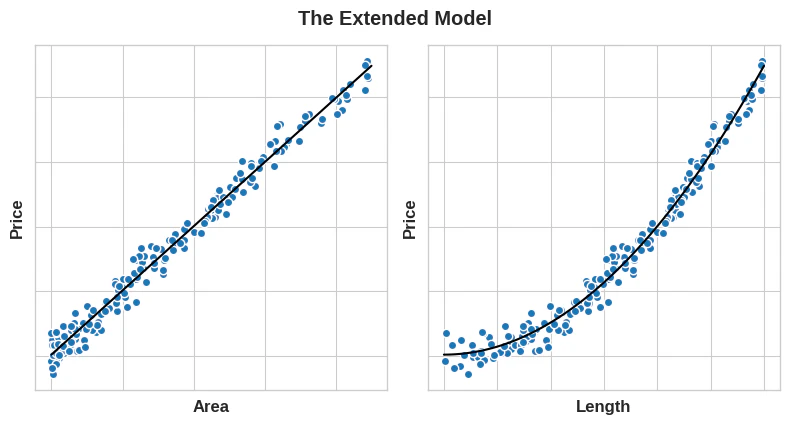
左:面積への適合感が向上しました。右:長さへの適合感も向上しました。
これにより、特徴量エンジニアリングに投資した時間に対して、なぜこれほど高い成果が得られるかが分かるはずです。モデルが学習できない関係は、変換することによって、自分で提供できます。特徴量セットを開発する際には、モデルが最高のパフォーマンスを実現するためにはどのような情報を使用できるかを検討してください。
例 - コンクリートの配合
これらのアイデアを説明するために、データセットにいくつかの合成特徴量を追加することで、ランダムフォレストモデルの予測パフォーマンスがどのように向上するかを見ていきます。
コンクリートデータセットには、様々なコンクリート配合と、その結果得られる製品の圧縮強度(その種類のコンクリートがどの程度の荷重に耐えられるかを示す指標)が含まれています。このデータセットのタスクは、コンクリートの配合に基づいてコンクリートの圧縮強度を予測することです。
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
df = pd.read_csv("../input/fe-course-data/concrete.csv")
df.head()
| Cement | BlastFurnaceSlag | FlyAsh | Water | Superplasticizer | CoarseAggregate | FineAggregate | Age | CompressiveStrength | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 540.0 | 0.0 | 0.0 | 162.0 | 2.5 | 1040.0 | 676.0 | 28 | 79.99 |
| 1 | 540.0 | 0.0 | 0.0 | 162.0 | 2.5 | 1055.0 | 676.0 | 28 | 61.89 |
| 2 | 332.5 | 142.5 | 0.0 | 228.0 | 0.0 | 932.0 | 594.0 | 270 | 40.27 |
| 3 | 332.5 | 142.5 | 0.0 | 228.0 | 0.0 | 932.0 | 594.0 | 365 | 41.05 |
| 4 | 198.6 | 132.4 | 0.0 | 192.0 | 0.0 | 978.4 | 825.5 | 360 | 44.30 |
ここでは、各種類のコンクリートに含まれる様々な材料を見ることができます。これらから派生したいくつかの合成特徴量を追加することで、モデルがそれらの間の重要な関係を学習するのにどのように役立つかを見ていきます。
まず、そのままのデータセットでモデルをトレーニングしてベースラインを決めます。これにより、新しい特徴量が実際に役立つかどうかを判断します。
このようなベースラインを確立することは、特徴量エンジニアリングプロセスの開始時に行うのが良い方法です。ベースラインスコアは、新しい特徴量を維持する価値があるかどうか、または破棄して別の特徴量を試す必要があるかどうかを判断するのに役立ちます。
X = df.copy()
y = X.pop("CompressiveStrength")
# Train and score baseline model
baseline = RandomForestRegressor(criterion="absolute_error", random_state=0)
baseline_score = cross_val_score(
baseline, X, y, cv=5, scoring="neg_mean_absolute_error"
)
baseline_score = -1 * baseline_score.mean()
print(f"MAE Baseline Score: {baseline_score:.4}")
MAE Baseline Score: 8.232
自宅で料理をしたことがある人なら、レシピの材料の絶対量よりも、その割合の方が料理の仕上がりを予測するうえで優れていることをご存じかもしれません。そうすると、上記の特徴量の比率は圧縮強度の優れた予測因子になると考えられます。
下のコードは、データセットに3つの新しい比率の特徴量を追加します。
X = df.copy()
y = X.pop("CompressiveStrength")
# Create synthetic features
X["FCRatio"] = X["FineAggregate"] / X["CoarseAggregate"]
X["AggCmtRatio"] = (X["CoarseAggregate"] + X["FineAggregate"]) / X["Cement"]
X["WtrCmtRatio"] = X["Water"] / X["Cement"]
# Train and score model on dataset with additional ratio features
model = RandomForestRegressor(criterion="absolute_error", random_state=0)
score = cross_val_score(
model, X, y, cv=5, scoring="neg_mean_absolute_error"
)
score = -1 * score.mean()
print(f"MAE Score with Ratio Features: {score:.4}")
MAE Score with Ratio Features: 7.948
そして予想通り、パフォーマンスが向上しました。これは、これらの新しい比率の特徴量によって、以前は検出されていなかった重要な情報がモデルで取得できたことの証拠です。