はじめに
当記事はkaggleのLearnのFeature EngineeringのClustering With K-Meansを翻訳して備忘としたものです。
拙い英語力なので間違い等あればご指摘いただけたらと思います。
まとめ:【kaggle】翻訳記事まとめ【備忘翻訳】
前:【kaggle】特徴量エンジニアリング - 特徴量の作成【備忘翻訳】
次:【kaggle】特徴量エンジニアリング - 主成分分析【備忘翻訳】
当記事に含まれるコードはkaggle内のnotebook内で正常に動作します。動作を試したい場合はkaggleのnotebookで試してください。
K平均法によるクラスタリング
クラスターラベルを使用して複雑な空間関係を解明します。
イントロダクション
このレッスンと次のレッスンでは教師なし学習アルゴリズムと呼ばれるものを利用します。教師なしアルゴリズムはターゲットを利用しません。その代わりに、データの何らかの特性を学習し、特徴量の構造を特定の方法で表現することを目的としています。予測のための特徴量エンジニアリングの文脈では、教師なしアルゴリズムを「特徴量発見」テクニックとして考えることができます。
クラスタリング(clustering) とは、データポイントが互いにどの程度類似しているかに基づいて、データポイントをグループに割り当てることを意味します。クラスタリングアルゴリズムはいわば「似た者同士が集まる」ようにすることです。
特徴量エンジニアリングに使用すると、例えば市場セグメントを代表する顧客グループや、同様の気象パターンを共有する地理的領域を発見することができます。クラスターラベルの機能を追加すると、機械学習モデルが空間や近接性の複雑な関係を解明するのに役立ちます。
特徴量としてのクラスターラベル
単一の実数値の特徴量に適用すると、クラスタリングは従来の「binning(解像度と引き換えに処理速度を向上?)」または、「discretization(離散化?)」変換のように機能します。複数の特徴量では、これは「多次元ビニング
」(ベクトル量子化と呼ばれることもあります)のようなものです。
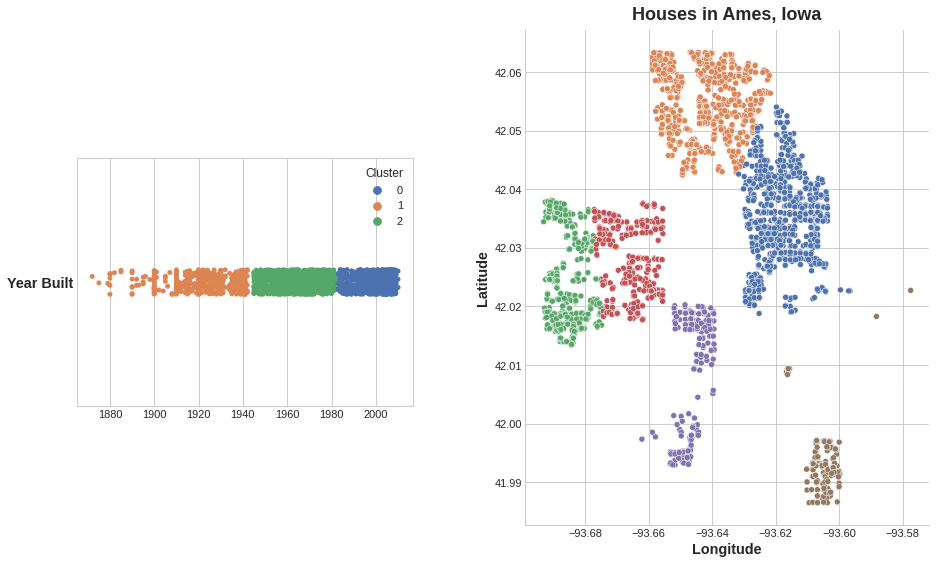
左:単一の特徴量のクラスタリング 右:2つの特徴量のクラスタリング
データフレームに追加されると、クラスターラベルの特徴量は次のようになります。
| Longitude | Latitude | Cluster |
|---|---|---|
| -93.619 | 42.054 | 3 |
| -93.619 | 42.053 | 3 |
| -93.638 | 42.060 | 1 |
| -93.602 | 41.988 | 0 |
このクラスター特徴量はカテゴリ的であることを覚えておくことが大切です。ここでは、一般的なクラスタリングアルゴリズムが生成するラベルエンコーディング(つまり、整数のシーケンス)で表示されています。モデルによっては、one-hotエンコーディングのほうが適切な場合もあります。
クラスターラベルを追加する主な目的は、クラスターによって特徴量間の複雑な関係がより単純なチャンクに分割されることです。そうすると、モデルは複雑な全体を一度に学習する代わりに、より単純なチャンクを1つずつ学習できるようになります。これは「分割して統治する」戦略です。
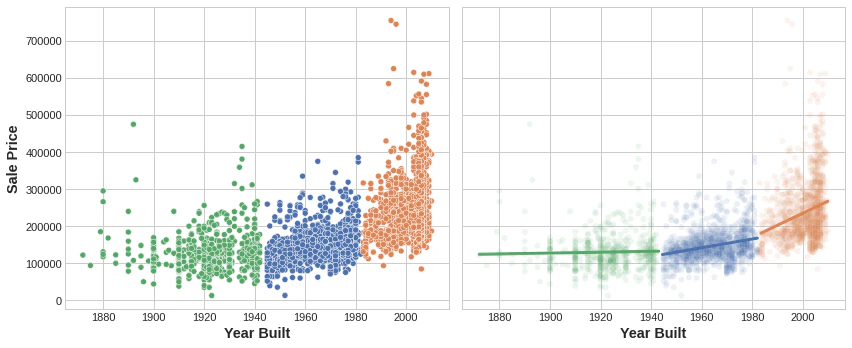
YearBuiltの特徴量をクラスタリングすると、この線形モデルはSalePriceとの関係を学習できるようになります。
この図は、クラスタリングによって単純な線形モデルがどのように改善されるかを示しています。YearBuiltとSalePriceの間の曲線関係はこの種のモデルには複雑すぎます。つまり適合不足です。ただし、より小さなチャンクでは関係はほぼせんけいであり、モデルは簡単に学習できます。
K平均法クラスタリング
クラスタリングアルゴリズムは非常に多く存在します。これらは主に、「類似性」または「近接性」を測定する方法と、どのような種類に特徴量を使用するかという点で異なります。ここで使用するアルゴリズムであるK平均法は直感的で特徴量エンジニアリングに簡単に適用できます。アプリケーションによっては別のアルゴリズムのほうが適している場合があります。
K平均法クラスタリングは、通常の直線距離(つまりユークリッド距離)を使用して類似性を測定します。特徴量空間内に重心と呼ばれる多数の点を配置することでクラスターを作成します。データセット内の各ポイントは、最も近い重心のクラスターに割り当てられます。「K平均法(k-means)」の「k」は、作成される重心(つまり、クラスター)の数です。kは自分で定義します。
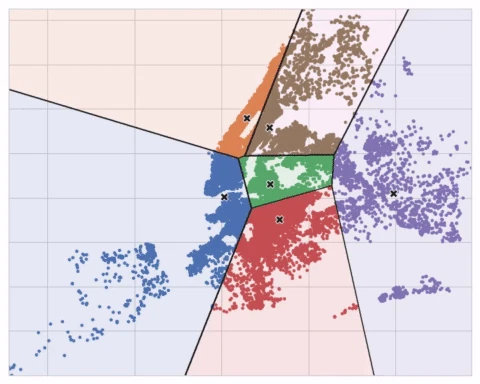
各重臣が放射状の円の連続を通して点を捉えていると想像できます。競合する重心の円の集合が重なると、直線が形成されます。その結果がボロノイ分割(Voronoi tessallation) と呼ばれます。この分割は、将来のデータがどのクラスターに割り当てられるを示します。分割は基本的にk平均法がトレーニングデータから学習するものです。
上記の Ames データセットのクラスタリングはK分割法を用いたクラスタリングです。以下は、分割と重心が表示された同じ図です。
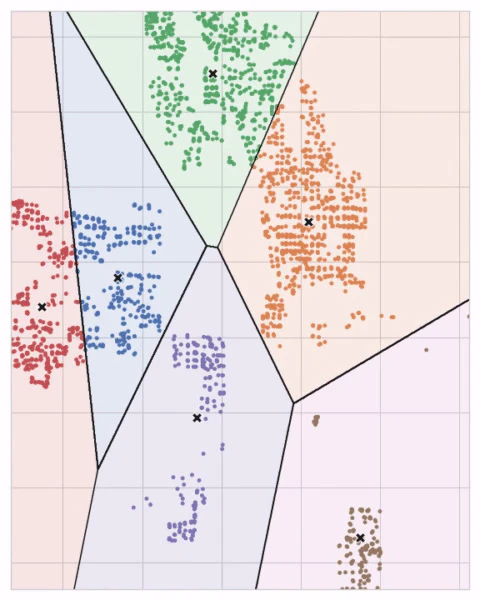
K分割法クラスタリングは、特徴空間のボロノイ分割を作成します。
K平均法アルゴリズムがどのようにクラスターを学習し、それが特徴量エンジニアリングにどのような意味を持つのかを見てみましょう。scikit-learnの実装の3つのパラメータ、n_clusters、max_iter、n_initに焦点を当てます。
これは単純な2段階のプロセスです。アルゴリズムは、事前に定義された数(n_clusters)の重心をランダムに初期化することから始まります。次に、次の2つの操作を繰り返します。
- 最も近いクラスターの重心にポイントを割り当てる
- 各重心を移動して、その点までの距離を最小にする
重心が動かなくなるまで、または最大反復回数(max_iter)が経過するまで、これら2つのステップを繰り返します。
重心の初期のランダムな位置が、不適切なクラスタリングで終了することがよくあります。このため、アルゴリズムは一定回数(n_init)繰り返し、各ポイントとその重心間の合計距離が最小となるクラスタリング、つまり最適なクラスタリングを返します。
以下のアニメーションは、アルゴリズムの動作を示しています。これは、結果が初期の重心に依存していることと、収束するまで反復することの重要性を示しています。
ニューヨークのAirbnbレンタルにおけるK平均法クラスタリングアルゴリズム
クラスターの数が多い場合はmax_iterを増やす必要があり、データセットが複雑な場合はn_initを増やす必要があります。ただし、通常は自分で選択する必要がある唯一のパラメータはn_clusters(つまりk)です。機能セットの最適なパーティショニングは、使用しているモデルと予測しようとしている内容によって異なるため、ハイパーパラメータと同様に調整するのが最適です(たとえば、クロス検証を通じて)。
例 - カリフォルニア住宅
空間的特徴量として California Housing の「緯度(Latitude)」と「経度(Longitude)」は、自然とK平均法クラスタリングの候補になります。この例では、これらをMedInc(平均所得)でクラスター化し、カリフォルニア州の様々な地域の経済セグメントを作成します。
setup
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.cluster import KMeans
plt.style.use("seaborn-whitegrid")
plt.rc("figure", autolayout=True)
plt.rc(
"axes",
labelweight="bold",
labelsize="large",
titleweight="bold",
titlesize=14,
titlepad=10,
)
df = pd.read_csv("../input/fe-course-data/housing.csv")
X = df.loc[:, ["MedInc", "Latitude", "Longitude"]]
X.head()
/opt/conda/lib/python3.10/site-packages/scipy/__init__.py:146: UserWarning: A NumPy version >=1.16.5 and <1.23.0 is required for this version of SciPy (detected version 1.23.5
warnings.warn(f"A NumPy version >={np_minversion} and <{np_maxversion}"
/tmp/ipykernel_20/577165241.py:6: MatplotlibDeprecationWarning: The seaborn styles shipped by Matplotlib are deprecated since 3.6, as they no longer correspond to the styles shipped by seaborn. However, they will remain available as 'seaborn-v0_8-<style>'. Alternatively, directly use the seaborn API instead.
plt.style.use("seaborn-whitegrid")
| MedInc | Latitude | Longitude | |
|---|---|---|---|
| 0 | 8.3252 | 37.88 | -122.23 |
| 1 | 8.3014 | 37.86 | -122.22 |
| 2 | 7.2574 | 37.85 | -122.24 |
| 3 | 5.6431 | 37.85 | -122.25 |
| 4 | 3.8462 | 37.85 | -122.25 |
K平均法クラスタリングはスケールに敏感なので、極端な値を持つデータを再スケールまたは正規化することは良い考えです。今回の特徴量はほぼ同じスケールにあるので、そのままにしておきます。
# Create cluster feature
kmeans = KMeans(n_clusters=6)
X["Cluster"] = kmeans.fit_predict(X)
X["Cluster"] = X["Cluster"].astype("category")
X.head()
/opt/conda/lib/python3.10/site-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
| MedInc | Latitude | Longitude | Cluster | |
|---|---|---|---|---|
| 0 | 8.3252 | 37.88 | -122.23 | 5 |
| 1 | 8.3014 | 37.86 | -122.22 | 5 |
| 2 | 7.2574 | 37.85 | -122.24 | 5 |
| 3 | 5.6431 | 37.85 | -122.25 | 5 |
| 4 | 3.8462 | 37.85 | -122.25 | 2 |
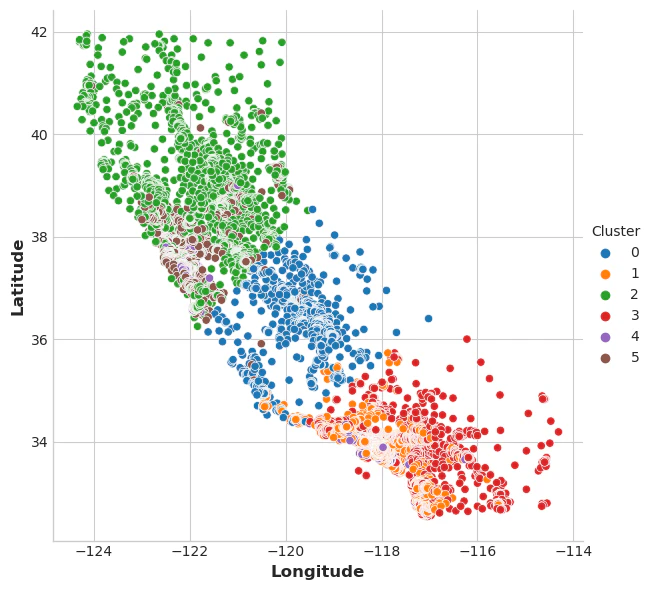
では、これがどれだけ効果的だったかを確認するために、いくつかのグラフを見てみましょう。まず、クラスターの地理的分布をしめす散布図です。アルゴリズムによって、海岸沿いの高所得地域に個別のセグメントが作成されたようです。
sns.relplot(
x="Longitude", y="Latitude", hue="Cluster", data=X, height=6,
);
/opt/conda/lib/python3.10/site-packages/seaborn/axisgrid.py:118: UserWarning: The figure layout has changed to tight
self._figure.tight_layout(*args, **kwargs)
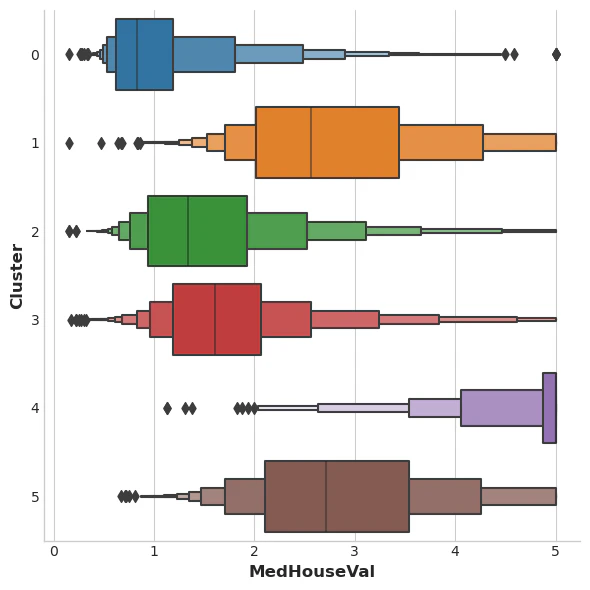
このデータセットのターゲットはMedHouseVal(住宅価格の中央値)です。これらのボックスプロットは、各クラスター内のターゲット分布を示しています。クラスタリングが有益であれば、これらの分布は大部分MedHouseVal全体で分離されるはずであり、実際にその通りになっています。
X["MedHouseVal"] = df["MedHouseVal"]
sns.catplot(x="MedHouseVal", y="Cluster", data=X, kind="boxen", height=6);
/opt/conda/lib/python3.10/site-packages/seaborn/axisgrid.py:118: UserWarning: The figure layout has changed to tight
self._figure.tight_layout(*args, **kwargs)