はじめに
当記事はkaggleのLearnのIntro to Machine LearningのHow Models Workを翻訳して備忘としたものです。
拙い英語力なので間違い等あればご指摘いただけたらと思います。
まとめ:【kaggle】翻訳記事まとめ【備忘翻訳】
次:【kaggle】機械学習イントロ - 基本的なデータ探索【備忘翻訳】
どのようにモデルは動くのか
導入
機械学習とその使い方について説明します。以前に統計モデリングや機械学習を扱ったことがある場合は基本的なことに感じるかもしれません。すぐに強力なモデルの構築に進みますので、心配しないでください。
このコースでは次のようなシナリオに沿ってモデルを構築していきます:
あなたのいとこは不動産投機で何百万ドルも儲けました。彼はあなたがデータサイエンスに興味を持っていることから、あなたとビジネスパートナーになることを提案してきました。彼は資産を提供します。あなたは様々な家の価値を予測するモデルを提供します。
あなたはいとこに、どうやってこれまで不動産価値を予測してきたのかを尋ねると、単に直感だと答えます。しかし、さらに質問していくと、彼は過去に見た家の価格パターンを特定し、そのパターンを使って検討中の新しい家の価格を予測していることが分かった。
機械学習も同じように機能します。まずは決定木と呼ばれるモデルから始めましょう。決定木よりも正確な予測を出す高度なモデルもありますが、決定木は理解しやすくデータサイエンスにおける最も優れたモデルの基本的な一つとなっています。
簡単にするため、できるだけ単純な決定木から始めます。
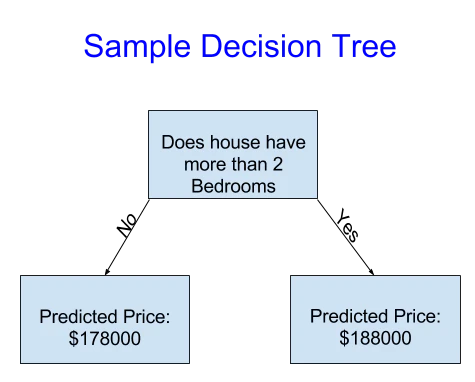
家は2つのカテゴリにのみ分類されます。検討中の住宅の予測価格は同じカテゴリの過去の平均価格です。
データを使用して、家を2つのグループに分ける方法を決定し、それによって各グループの予測価格を決定します。データからパターンをキャプチャするこのステップは、モデルのフィッティングまたは、トレーニングといいます。モデルのフィッティングに利用したデータをトレーニングデータといいます。
モデルの最適化方法の詳細(データの分割方法など)は非常に複雑なので後ほど説明します。モデルのフィッティングが完了したら、新しいデータに適用して追加の家の価格予測ができます。
決定木の改善
次の2つの決定木のうち、不動産トレーニングデータを最適化させた結果、どちらがより現実に即しているでしょうか?
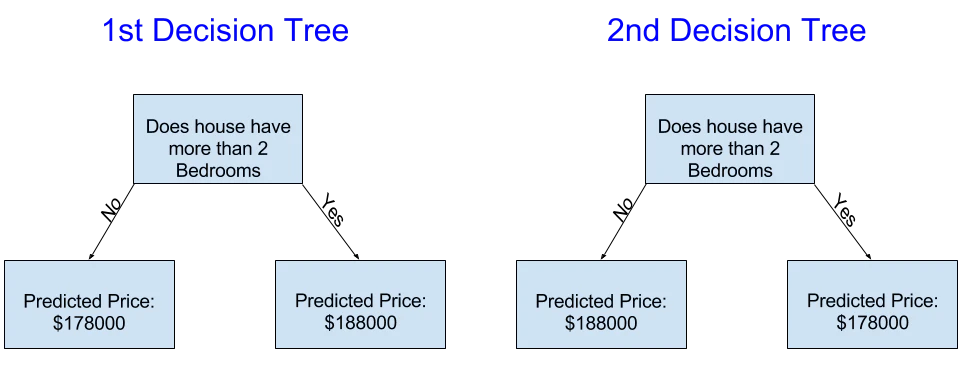
左の決定木は寝室の数が多い家は少ない家よりも高価で売れる傾向があるという現実をとらえているため、理にかなっています。この決定木の最大の欠点はバスルームの数、敷地面積、場所などの住宅価格に影響を与えるほとんどの要因をとらえていないことです。
より多くの「節点」を持つ決定木を使用することで、より多くの要因を補足することができます。より多くの節点を持つ決定木は「深い」ツリーと呼ばれます。各家の敷地の合計サイズも考慮した決定木は次のようになります。
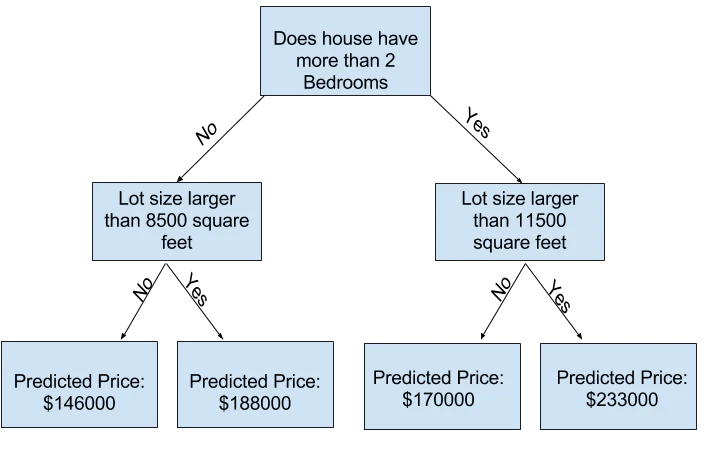
決定木をたどり、その家の特徴に対応する経路を選択することで、家の価格を予想します。家の価格を示すツリーは一番下に当たります。予測を行う一番のポイントは 葉(端点) と呼ばれます。
葉の分割と値はデータによって決定されます。
次回は実際にデータを確認しながら見ていきます。