はじめに
当記事はkaggleのLearnのIntro to Machine LearningのDistributionsを翻訳して備忘としたものです。
拙い英語力なので間違い等あればご指摘いただけたらと思います。
まとめ:【kaggle】翻訳記事まとめ【備忘翻訳】
前:【kaggle】データの視覚化 - 散布図【備忘翻訳】
次:【kaggle】データの視覚化 - プロットタイプとカスタムスタイルの設定【備忘翻訳】
当記事に含まれるコードはkaggle内のnotebook内で正常に動作します。動作を試したい場合はkaggleのnotebookで試してください。
分布
ヒストグラムと密度プロットを作成する。
このチュートリアルでは、ヒストグラムと密度プロットについて学習します。
notebookのセットアップ
いつものように、コーディング環境の設定から始めます。
setup
import pandas as pd
pd.plotting.register_matplotlib_converters()
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
print("Setup Complete")
Setup Complete
データセットの選択
3つの異なる種類のアヤメ(Iris setosa、 Iris versicolor、 Iris virginica)からそれぞれ50個ずつ、合計150種類の花のデータを扱います。

データをロードして調べる
データセットの各行は異なる花に対応しています。測定値は4つあります:萼片の長さと幅、花弁の長さと幅。対応する種を追跡します。
# Path of the file to read
iris_filepath = "../input/iris.csv"
# Read the file into a variable iris_data
iris_data = pd.read_csv(iris_filepath, index_col="Id")
# Print the first 5 rows of the data
iris_data.head()
| Sepal Length (cm) | Sepal Width (cm) | Petal Length (cm) | Petal Width (cm) | Species | |
|---|---|---|---|---|---|
| Id | |||||
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
ヒストグラム
アヤメの花びらの長さがどのように変化するかを見るためのヒストグラムを作成します。これはsns.histplotコマンドで実行できます。
# Histogram
sns.histplot(iris_data['Petal Length (cm)'])
<AxesSubplot:xlabel='Petal Length (cm)', ylabel='Count'>
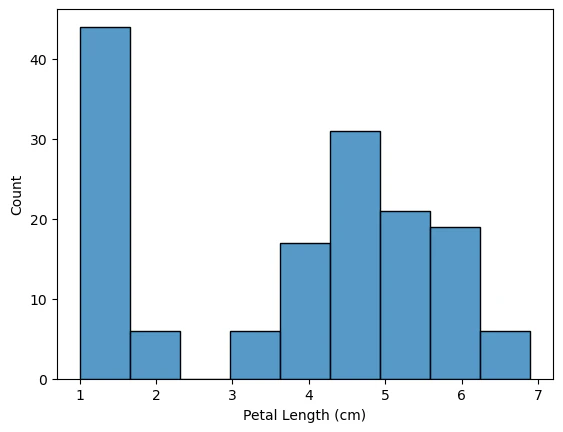
上記のコードではプロットする列をコマンドに指定する必要がありました。(この場合は、Petal Length (cm)を選択しました。)
密度プロット
次のタイプのプロットは、カーネル密度推定(kernel density estimate (KDE) )といいます。KEDプロットに詳しくない場合はこれを滑らかなヒストグラムとして考えることができます。
KEDプロットを作成するには、sns.kdeplotコマンドを使用します。shade=Trueに設定すると、曲線の下の領域に色が付きます(data=はプロットする列を選択します)。
# KDE plot
sns.kdeplot(data=iris_data['Petal Length (cm)'], shade=True)
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:2: FutureWarning:
`shade` is now deprecated in favor of `fill`; setting `fill=True`.
This will become an error in seaborn v0.14.0; please update your code.
<AxesSubplot:xlabel='Petal Length (cm)', ylabel='Density'>
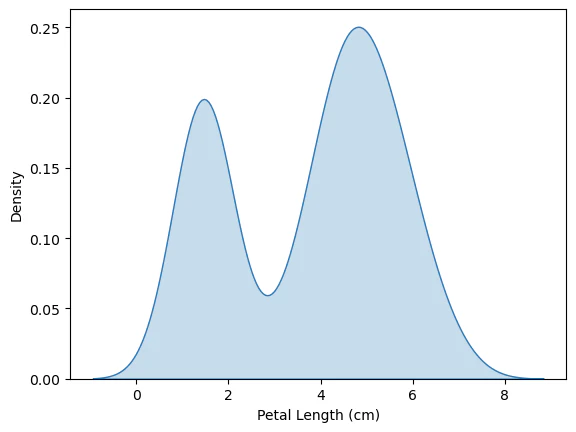
2D KDE プロット
KDEプロットを作成するときは、1つの列に制限されません。sns.jointplotコマンドを使用して、2次元(2D)KDEプロットを作成できます。
下の図では、色分けにより、萼片の幅と花弁の長さの様々な組み合わせが見られる可能性がどれくらいあるかが示されており、図の暗い部分のほうが可能性が高いことが分ります。
# 2D KDE plot
sns.jointplot(x=iris_data['Petal Length (cm)'], y=iris_data['Sepal Width (cm)'], kind="kde")
<seaborn.axisgrid.JointGrid at 0x786187a48f50>
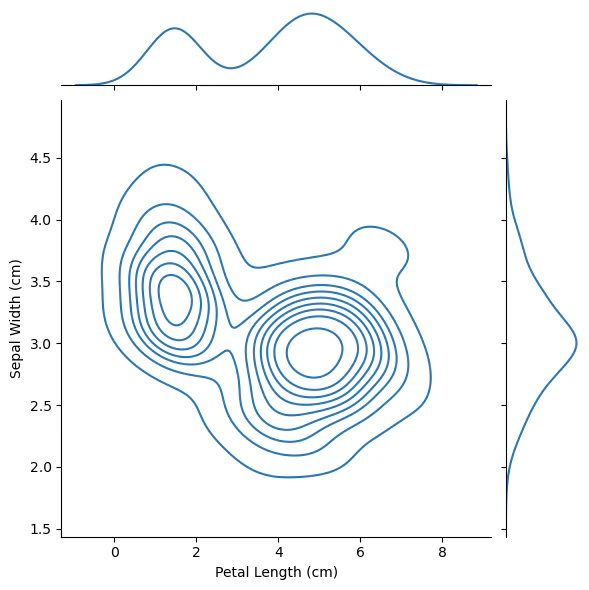
中央の2D KDEプロットに補足して、
- 図の上部の曲線は、x軸上のデータ(この場合は
iris_data['Petal Length (cm)'])のKEDプロットであり、 - 図の右側の曲線は、y軸上のデータ(この場合は
iris_data['Sepal Width (cm)'])のKEDプロットです。
color-code プロット
チュートリアルの次のパートでは、種間の違いを理解するためのプロットを作成します。
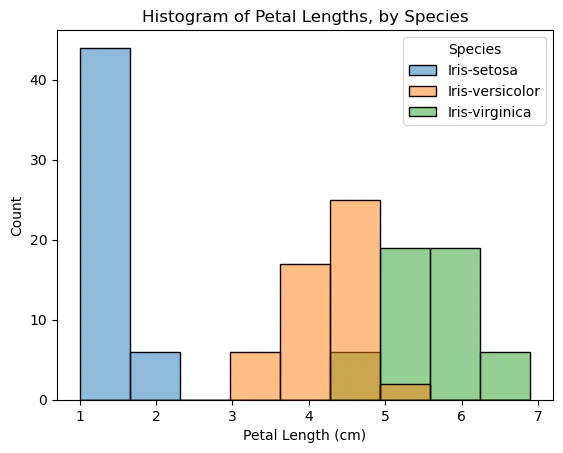
sns.histplotコマンド(上記)を使用すると、花弁の花の長さの3つのことあるヒストグラム(種ごとに1つ)を作成できます。
-
data=は、データの読み込みに使用した変数の名前を入力します。 -
x=プロットしたいデータの列名を設定します。 -
hue=は、データを異なるヒストグラムに分割するために使用する列を設定します。
# Histograms for each species
sns.histplot(data=iris_data, x='Petal Length (cm)', hue='Species')
# Add title
plt.title("Histogram of Petal Lengths, by Species")
Text(0.5, 1.0, 'Histogram of Petal Lengths, by Species')
sns.kdeplit(上記)を使用して、それぞれの種のKEDプロットを作成することもできます。data、x、hueの機能は上でsns.histplotを使用したときと同じです。さらに、shade=Trueを設定して、各曲線の下の領域に色を付けます。
# KDE plots for each species
sns.kdeplot(data=iris_data, x='Petal Length (cm)', hue='Species', shade=True)
# Add title
plt.title("Distribution of Petal Lengths, by Species")
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:2: FutureWarning:
`shade` is now deprecated in favor of `fill`; setting `fill=True`.
This will become an error in seaborn v0.14.0; please update your code.
Text(0.5, 1.0, 'Distribution of Petal Lengths, by Species')
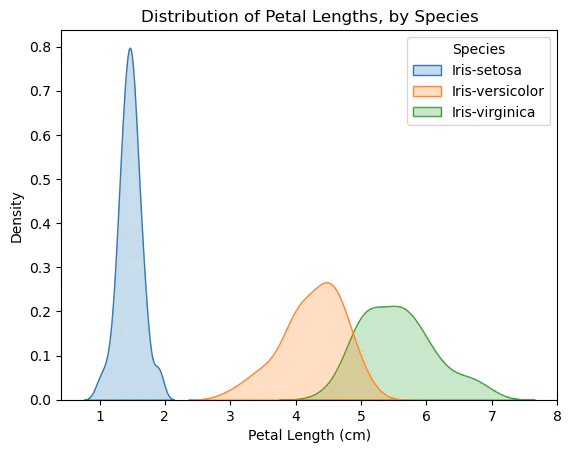
プロットに見られる興味深いパターンの一つは、植物が2つのグループのいずれかに属しているように見えることです。Iris VersicolorとIris virginicaは花びらの長さの値が似ているように見えますが、Iris setosaは独自のカテゴリに属しています。
実際にこのデータセットによれば、花びらの長さを見るだけで、どのアヤメ科植物もIris setosaとして分類できる可能性があります。アヤメの花びらの長さが2cm未満であればIris setosaである可能性が最も高くなります。