はじめに
当記事はkaggleのLearnのFeature EngineeringのCreating Featuresを翻訳して備忘としたものです。
拙い英語力なので間違い等あればご指摘いただけたらと思います。
まとめ:【kaggle】翻訳記事まとめ【備忘翻訳】
前:【kaggle】特徴量エンジニアリング - 相互情報量【備忘翻訳】
次:【kaggle】特徴量エンジニアリング - K平均法によるクラスタリング【備忘翻訳】
当記事に含まれるコードはkaggle内のnotebook内で正常に動作します。動作を試したい場合はkaggleのnotebookで試してください。
特徴量の作成
モデルに合わせてPandasを使用して特徴量に変換します。
イントロダクション
ある程度可能性のある特徴量セットを特定したら、開発を開始します。このレッスンでは、Pandasだけで実行できる一般的な変換をいくつか学びます。自信がなくなってきたと感じたらPandasに関する素晴らしいコースがあります。
このレッスンでは、様々な特徴量タイプを持つ4つのデータセットを使用します:アメリカの交通事故、1985年の自動車、コンクリートの配合、そして顧客生涯生産価値です。下の折り畳みでそれらを読み込んでいます。
details
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
plt.style.use("seaborn-whitegrid")
plt.rc("figure", autolayout=True)
plt.rc(
"axes",
labelweight="bold",
labelsize="large",
titleweight="bold",
titlesize=14,
titlepad=10,
)
accidents = pd.read_csv("../input/fe-course-data/accidents.csv")
autos = pd.read_csv("../input/fe-course-data/autos.csv")
concrete = pd.read_csv("../input/fe-course-data/concrete.csv")
customer = pd.read_csv("../input/fe-course-data/customer.csv")
新しい特徴量を見つけるためのヒント
- 特徴量を理解します。データセットのデータドキュメントがある場合は、それを参照してください。
- 問題ドメインを調査して、ドメイン知識を調査します。住宅価格を予測することが課題であれば、例えば、実際の不動産について調査してみましょう。Wikipediaはいい出発点になりますが、書籍や論文記事に最もいい情報が含まれている場合が多々あります。
- 過去の成果を研究してください。過去のKaggleコンテストのソリューション記事は、優れたリソースになります。
- データの視覚化を活用してください。視覚化により、特徴量の分布の異常や、単純化できる複雑な関係を明らかにすることができます。特徴量エンジニアリングプロセスを実行する際には、必ずデータセットを視覚化してください。
数値的変換
特徴量間の数値的関係は、多くの場合、数式で表現されます。これは、ドメイン調査の一環として頻繁に遭遇することになります。Pandasでは、通常の数値と同じように、列に算術演算を適用できます。
自動車データセットには、自動車のエンジンを説明する特徴量が含まれています。調査することによて、潜在的に有用な新たな特徴量を作成するための様々な公式が得られます。例えば「ストローク比率(stroke_ratio)」はエンジンの効率と性能を測る指標です:
autos["stroke_ratio"] = autos.stroke / autos.bore
autos[["stroke", "bore", "stroke_ratio"]].head()
| stroke | bore | stroke_ratio | |
|---|---|---|---|
| 0 | 2.68 | 3.47 | 0.772334 |
| 1 | 2.68 | 3.47 | 0.772334 |
| 2 | 3.47 | 2.68 | 1.294776 |
| 3 | 3.40 | 3.19 | 1.065831 |
| 4 | 3.40 | 3.19 | 1.065831 |
組み合わせが複雑になるほど、モデルが学習するのは難しくなります。例えば、エンジンのパワーの尺度の「排気量(displacement)」は:
autos["displacement"] = (
np.pi * ((0.5 * autos.bore) ** 2) * autos.stroke * autos.num_of_cylinders
)
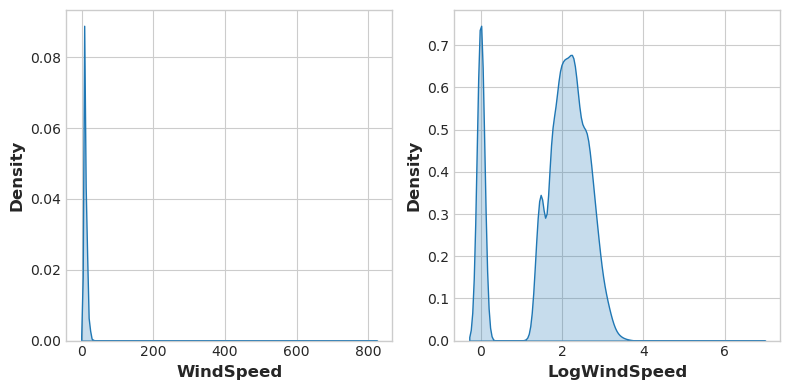
データの視覚化は変換を提案することがあり、多くの場合、累乗や対数による特徴量の「再形成」が行われます。例えば、アメリカの事故における風速の分布は非常に偏ってます。この場合、対数はそれを正規化するのに効果的です。
# If the feature has 0.0 values, use np.log1p (log(1+x)) instead of np.log
accidents["LogWindSpeed"] = accidents.WindSpeed.apply(np.log1p)
# Plot a comparison
fig, axs = plt.subplots(1, 2, figsize=(8, 4))
sns.kdeplot(accidents.WindSpeed, shade=True, ax=axs[0])
sns.kdeplot(accidents.LogWindSpeed, shade=True, ax=axs[1]);
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:6: FutureWarning:
`shade` is now deprecated in favor of `fill`; setting `fill=True`.
This will become an error in seaborn v0.14.0; please update your code.
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:7: FutureWarning:
`shade` is now deprecated in favor of `fill`; setting `fill=True`.
This will become an error in seaborn v0.14.0; please update your code.
import sys
クリーニングのデータの正規化に関するレッスンをご覧ください。ここでは、非常に一般的な正規化であるBox-Cox変換についても学習します。
カウント
何かの存在、または不在を表す特徴量は、多くの場合、病気のリスク要因のセットのような場合に提供されます。カウントを作成することで、このような特徴量を集計できます。
これらの特徴量は、バイナリ(存在する場合は1、存在しない場合は0)または、ブール値(TrueまたはFalse)になります。Pythonではブール値は整数と同じように加算できます。
交通事故データセットには、事故現場の近くに道路上の物体があったかどうかを示す特徴量がいくつかあります。これらをsumメソッドを使用して、近くの道路の特徴量の合計がカウントされます。
roadway_features = ["Amenity", "Bump", "Crossing", "GiveWay",
"Junction", "NoExit", "Railway", "Roundabout", "Station", "Stop",
"TrafficCalming", "TrafficSignal"]
accidents["RoadwayFeatures"] = accidents[roadway_features].sum(axis=1)
accidents[roadway_features + ["RoadwayFeatures"]].head(10)
| Amenity | Bump | Crossing | GiveWay | Junction | NoExit | Railway | Roundabout | Station | Stop | TrafficCalming | TrafficSignal | RoadwayFeatures | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | False | False | False | False | False | False | False | 0 |
| 1 | False | False | False | False | False | False | False | False | False | False | False | False | 0 |
| 2 | False | False | False | False | False | False | False | False | False | False | False | False | 0 |
| 3 | False | False | False | False | False | False | False | False | False | False | False | False | 0 |
| 4 | False | False | False | False | False | False | False | False | False | False | False | False | 0 |
| 5 | False | False | False | False | True | False | False | False | False | False | False | False | 1 |
| 6 | False | False | False | False | False | False | False | False | False | False | False | False | 0 |
| 7 | False | False | True | False | False | False | False | False | False | False | False | True | 2 |
| 8 | False | False | True | False | False | False | False | False | False | False | False | True | 2 |
| 9 | False | False | False | False | False | False | False | False | False | False | False | False | 0 |
データフレームの組み込みメソッドを使用してブール値を作成することもできます。コンクリートには、コンクリート配合の成分量が含まれています。多くの製法では1つまたは、複数の成分データが欠損しています(つまり、データの値が0になっています)。これはデータフレームに組み込まれているgreater-thangtメソッドを使用して、製法に含まれる成分データの数をカウントしています。
components = [ "Cement", "BlastFurnaceSlag", "FlyAsh", "Water",
"Superplasticizer", "CoarseAggregate", "FineAggregate"]
concrete["Components"] = concrete[components].gt(0).sum(axis=1)
concrete[components + ["Components"]].head(10)
| Cement | BlastFurnaceSlag | FlyAsh | Water | Superplasticizer | CoarseAggregate | FineAggregate | Components | |
|---|---|---|---|---|---|---|---|---|
| 0 | 540.0 | 0.0 | 0.0 | 162.0 | 2.5 | 1040.0 | 676.0 | 5 |
| 1 | 540.0 | 0.0 | 0.0 | 162.0 | 2.5 | 1055.0 | 676.0 | 5 |
| 2 | 332.5 | 142.5 | 0.0 | 228.0 | 0.0 | 932.0 | 594.0 | 5 |
| 3 | 332.5 | 142.5 | 0.0 | 228.0 | 0.0 | 932.0 | 594.0 | 5 |
| 4 | 198.6 | 132.4 | 0.0 | 192.0 | 0.0 | 978.4 | 825.5 | 5 |
| 5 | 266.0 | 114.0 | 0.0 | 228.0 | 0.0 | 932.0 | 670.0 | 5 |
| 6 | 380.0 | 95.0 | 0.0 | 228.0 | 0.0 | 932.0 | 594.0 | 5 |
| 7 | 380.0 | 95.0 | 0.0 | 228.0 | 0.0 | 932.0 | 594.0 | 5 |
| 8 | 266.0 | 114.0 | 0.0 | 228.0 | 0.0 | 932.0 | 670.0 | 5 |
| 9 | 475.0 | 0.0 | 0.0 | 228.0 | 0.0 | 932.0 | 594.0 | 4 |
特徴量の組み合わせと分解
複雑な文字列をより単純な部分に分割すると便利な場合がよくあります。一般例をいくつか示します:
- ID numbers:
123-45-6789 - Phone numbers:
(999) 555-0123 - Street addresses:
8241 Kaggle Ln., Goose City, NV - Internet addresses:
http://www.kaggle.com - Product codes:
0 36000 29145 2 - Dates and times:
Mon Sep 30 07:06:05 2013
このような特徴量には、利用できる何らかの構造があることが多いです。例えば、アメリカの電話番号には市外局番(999の部分)があり、発信者の所在地が分かります。いつものようにここでも調査が役立ちます。
strアクセサリを使用すると、splitなどの文字列メソッドを列に直接適用できます。顧客生涯価値データセットには、保険会社の顧客を説明する特徴量が含まれています。Policyの特徴量から、TypeとLevelの情報を分離できます。
customer[["Type", "Level"]] = ( # Create two new features
customer["Policy"] # from the Policy feature
.str # through the string accessor
.split(" ", expand=True) # by splitting on " "
# and expanding the result into separate columns
)
customer[["Policy", "Type", "Level"]].head(10)
| Policy | Type | Level | |
|---|---|---|---|
| 0 | Corporate L3 | Corporate | L3 |
| 1 | Personal L3 | Personal | L3 |
| 2 | Personal L3 | Personal | L3 |
| 3 | Corporate L2 | Corporate | L2 |
| 4 | Personal L1 | Personal | L1 |
| 5 | Personal L3 | Personal | L3 |
| 6 | Corporate L3 | Corporate | L3 |
| 7 | Corporate L3 | Corporate | L3 |
| 8 | Corporate L3 | Corporate | L3 |
| 9 | Special L2 | Special | L2 |
組み合わせに何らかの相互作用があると信じる理由がある場合は、単純な特徴量の合成が新たな合成特徴量にすることもできます。
autos["make_and_style"] = autos["make"] + "_" + autos["body_style"]
autos[["make", "body_style", "make_and_style"]].head()
| make | body_style | make_and_style | |
|---|---|---|---|
| 0 | alfa-romero | convertible | alfa-romero_convertible |
| 1 | alfa-romero | convertible | alfa-romero_convertible |
| 2 | alfa-romero | hatchback | alfa-romero_hatchback |
| 3 | audi | sedan | audi_sedan |
| 4 | audi | sedan | audi_sedan |
グループ変換
最後にグループ変換があります。これは、何らかのカテゴリでグループ化された複数の行に渡って情報を集約します。グループ変換を使用すると、「その人が住んでいる州の平均収入」や「平日に公開される映画のジャンル別割合」などが作成できます。カテゴリ間の相互作用量を発見した場合はそのカテゴリでのグループ変換を調査するといいでしょう。
グループ変換は、集計関数を使用して、グループ化を提供するカテゴリ特徴量と、値を集計する特徴量の2つの機能を組み合わせます。「州別平均収入」の場合、グループ化の特徴量としてState、集計関数としてmean、集計する特徴量としてIncomeを選択します。Pandasでこれを計算するには、groupbyメソッドとtransformメソッドを使用します。
customer["AverageIncome"] = (
customer.groupby("State") # for each state
["Income"] # select the income
.transform("mean") # and compute its mean
)
customer[["State", "Income", "AverageIncome"]].head(10)
| State | Income | AverageIncome | |
|---|---|---|---|
| 0 | Washington | 56274 | 38122.733083 |
| 1 | Arizona | 0 | 37405.402231 |
| 2 | Nevada | 48767 | 38369.605442 |
| 3 | California | 0 | 37558.946667 |
| 4 | Washington | 43836 | 38122.733083 |
| 5 | Oregon | 62902 | 37557.283353 |
| 6 | Oregon | 55350 | 37557.283353 |
| 7 | Arizona | 0 | 37405.402231 |
| 8 | Oregon | 14072 | 37557.283353 |
| 9 | Oregon | 28812 | 37557.283353 |
mean関数は組み込みデータフレームメソッドであるため、文字列として渡して変換することができます。そのほかにも便利なメソッドには、max、min、mediam、var、std、countなどがあります。データセット内で各状態が発生する頻度を計算する方法は次の通りです。
customer["StateFreq"] = (
customer.groupby("State")
["State"]
.transform("count")
/ customer.State.count()
)
customer[["State", "StateFreq"]].head(10)
| State | StateFreq | |
|---|---|---|
| 0 | Washington | 0.087366 |
| 1 | Arizona | 0.186446 |
| 2 | Nevada | 0.096562 |
| 3 | California | 0.344865 |
| 4 | Washington | 0.087366 |
| 5 | Oregon | 0.284760 |
| 6 | Oregon | 0.284760 |
| 7 | Arizona | 0.186446 |
| 8 | Oregon | 0.284760 |
| 9 | Oregon | 0.284760 |
このような変換を使用して、カテゴリ機能の「frequency encoding」を作成できます。
トレーニングと検証の分割を使用している場合は、それらの独立性を維持するために、トレーニングセットのみを使用してグループ化された特徴量を作成し、それを検証セットに結合するのが最適です。トレーニングセットでdrop_duplicatesを使用してイチイの値のセットを作成した後、検証セットのmergeメソッドを使用できます。
# Create splits
df_train = customer.sample(frac=0.5)
df_valid = customer.drop(df_train.index)
# Create the average claim amount by coverage type, on the training set
df_train["AverageClaim"] = df_train.groupby("Coverage")["ClaimAmount"].transform("mean")
# Merge the values into the validation set
df_valid = df_valid.merge(
df_train[["Coverage", "AverageClaim"]].drop_duplicates(),
on="Coverage",
how="left",
)
df_valid[["Coverage", "AverageClaim"]].head(10)
| Coverage | AverageClaim | |
|---|---|---|
| 0 | Premium | 671.603973 |
| 1 | Basic | 375.455516 |
| 2 | Basic | 375.455516 |
| 3 | Basic | 375.455516 |
| 4 | Basic | 375.455516 |
| 5 | Basic | 375.455516 |
| 6 | Basic | 375.455516 |
| 7 | Basic | 375.455516 |
| 8 | Extended | 474.483232 |
| 9 | Basic | 375.455516 |
特徴量作成Tips
特徴量を作成するときは、モデル自体の長所と短所を念頭に置いておくといいでしょう。次にいくつかのガイドラインを示します。
- 線形モデルは和と差を自然に学習しますが、より複雑なものは学習できません。
- 比率は、ほとんどのモデルにとって学習が難しいようです。比率の組み合わせにより、簡単にパフォーマンスが向上することがよくあります。
- 線形モデルとニューラルネットは、通常、正規化された特徴量を使用するとパフォーマンスが向上します。ニューラルネットでは特に、0からそれほど離れていない値にスケーリングされた特徴量が必要です。ツリーベースのモデル(ランダムフォレストやXGBoostなど)は、正規化によってメリットを得られる場合もありますが、通常それほどメリットはありません。
- ツリーモデルは、ほぼすべての特徴量の組み合わせを近似することを学習できますが、組み合わせが特に重要な場合、特にデータが制限されている場合は、明示的に作成することでメリットが得られます。
- カウントはツリーモデルに特に役立ちます。これらのモデルには、一度に多くの特徴量に渡って情報を集約する自然な方法がないためです。