はじめに
2024年2月15日にOpenAIは新しいAIモデル 「Sora」を発表しました。
「Sora」はこれまでにない高画質かつ長時間の動画を生成できるText to Video Modelです。
個人的に「Sora」の登場は「GPT-4」の登場時と同じレベルの衝撃を受けています。
去年のGPT-4登場の衝撃からまだ1年も経っていないのに、ここまでの進化を遂げるとは思ってもいませんでした。
なにが衝撃だったのか
テキストや画像から動画を生成すること自体は、すでに存在している技術です。
有名どころではStability AIの「Stable Video Diffusion」 やPIKA LABsの「Pika」があります。
「Sora」はこれらの技術と比べて、以下の特徴を持っています。
以下個別に特徴を述べていきます。
- 他社のモデルと比べて、圧倒的に高画質かつ長時間の動画を生成できる
- 物理世界の汎用シミュレーターのための試金石としてとらえていること
- 異なる解像度で動画を出力できる
1. 他社のモデルと比べて、圧倒的に高画質かつ長時間の動画を生成できる
公式によれば「Sora」は フルHD解像度(1920 x 1080)で最大60秒の動画を生成することができます。
fpsの部分は記事中では明示されていませんでしたが、いくつか「Sora」が生成したとされる動画をダウンロードして調べてみたところすべて30fpsでした。

Stability AIの Stable Video Diffusion が WSVGA解像度(576 x 1024) x 最大 25 フレームです。
(community demo だと 4秒25フレームで約6fpsになっています)
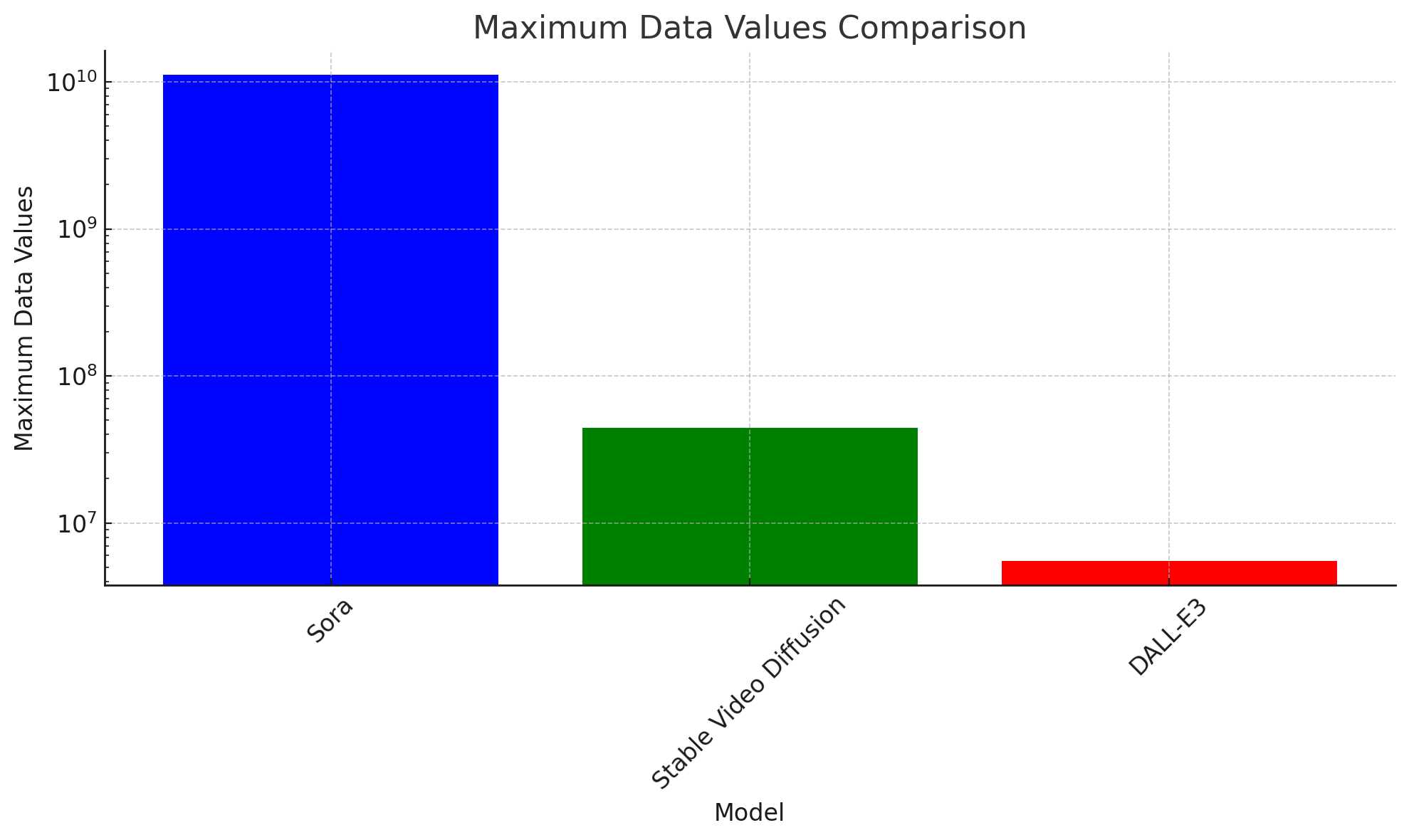
わかりやすくするために、他のモデルとの違いを数値で表してみます。
動画もデータなので、生成されるデータ量を数値化します。
まず前提として、画像1ピクセル当たり、色情報として赤、緑、青の3つのデータ値が必要です。
いわゆるRGB値ですね。
そして、「Sora」が生成したとされる動画が30fpsでした。
フルHD画質(1920 x 1080)で30fpsの動画を60秒生成した場合、「縦のピクセル数 x 横のピクセル数 x 秒数 x フレーム数 x RGBの情報」を合わせて、最大で約111億を超えるデータ値をほぼ破綻がない状態で連続して生成できることになります。
「Stable Video Diffusion」は最大約4423万データ値です。
「Stable Video Diffusion」とは利用可能なマシンリソースが異なるとはいえ、これは驚異的な数値です。
文字通り従前とは桁違いの映像情報を出力し、動画を生成できるようになっています。
Diffusion Modelを使って、この量のデータを時間軸に沿って生成して連続的な動きを表現できているのは、ちょっと去年だと考えられないものです。
参考までにDALL-E3で生成される画像の最大データ値は約550万です。
- Sora : 1920 x 1080 x 60 x 30 x 3 = 最大 11,197,440,000 データ値
- Stable Video Diffusion : 576 x 1024 x 25 x 3 = 最大 44,236,800 データ値
- DALL-E3 : 1792 × 1024 x 3 = 最大 5,505,024 データ値
ChatGPTでこれをプロットしてみたところ、以下の図になりました。
縦軸が 指数になっているところが本当にクレイジーですね。
2. 物理世界の汎用シミュレーターのための試金石としてとらえていること
OpenAIは「Sora」を単なる動画生成AIではなく、物理世界の汎用シミュレーターのための試金石としてとらえています。
Our largest model, Sora, is capable of generating a minute of high fidelity video. Our results suggest that scaling video generation models is a promising path towards building general purpose simulators of the physical world.
実際にほとんどの動画は、見ている感じ生成AIによって作成されたことがわかりません。
普通に現実世界で録画された動画に見えます。
それは、「Sora」によって生成された動画が、現実世界の物理法則をよくシミュレートできていることを示しています。
まだ失敗例もありますが、解決も時間の問題でしょう。
今まで、天気予報等ごく一部の領域でだけ行われてきた物理世界のシミュレーションが汎用化されれば、それこそアニメや漫画といった創作の世界の「〇分先の未来を予測する力」のようなものが実現できそうですね。
OpenAIのなかで、汎用人工知能(AGI)実現までのロードマップの中に物理世界のシミュレーションを可能にすることが必須要件として含まれているのかもしれません。
3. 異なる解像度で動画を出力できる
他社のモデルだと一定サイズでリサイズや切り取り、トリミングで固定されたサイズの動画しか生成できませんでした。
例として挙げた「Stable Video Diffusion」だと576 x 1024の固定解像度の動画しか生成できません。
「Sora」は本来の解像度で学習させることにより、横 1920 x 1080か縦 1080 x 1920の範囲内で自由に縦横比を変更した動画を生成することができます。
マルチデバイス対応や動画の生成にかかる時間を考えると、これは非常に画期的な機能です。

短期的な我々への影響
この技術が広く使えるようになれば、短期的には以下のようなことが起こりそうです。
現時点では、中長期的な影響は予測が困難です。
1. ドラマやアニメといった映像領域の創作の幅が広がる
動画制作のハードルが下がることで、より多くの人が動画を制作できるようになり、創作の幅が広がります。
TikTokのショート動画等も同様ですね。
また、動画の背景を変えたり、原画から動画を作るといったことも相当ハードルが下がるため、編集作業も楽になりそうです。
原作者がそのままプロンプトを作成して直接動画を作成することにより、最近話題の「原作者のイメージ通りに映像化されない」問題の解決につながるかもしれませんね。
(ここはビジネスや政治という実世界の別の変数があるのでなんとも言えませんが。)
2. クリエイティブ領域へのさらなるインパクトの発生
テレビCMやFacebook等の広告動画は数秒~数十秒なので、秒数的に今の「Sora」でも完全に対応できます。
既に生成AIはクリエイティブ領域に大きな影響を与えていますが、「Sora」の登場でその影響はさらに大きくなりそうです。
3. フェイクニュースのさらなる深刻化
現時点でも生成AIのフェイクニュース(いわゆるディープフェイク)は世界的な問題になっています。
高性能な動画生成AIである「Sora」が広く公開された場合、その問題はさらに深刻化しそうです。
OpenAIは従前からAIの悪用リスクを問題視しており、「GPT-2」の時代から、悪用を恐れてモデルの公開を控える等の対応をおこなってきました。
今回も安全性にかなり重点を置いて、しっかりとテストをしてから公開をしていく方針のようです。
そのため、我々が「Sora」を触れるようになるのは結構先になりそうです。
「DALL‐E」のときもそうでした。
さいごに
余談にはなりますが、OpenAIの「Sora」の発表の数時間前にGoogleが「Gemini 1.5」を発表していました。
「Gemini 1.5」は1M tokenに対応しており、「OpenAIも結構技術的に追いつかれてきたな」と思っていたのですが、Soraの登場でその考えは一気に覆されました。
動画の生成は時間軸や連続性といった多くの変数が出てくるので、静止画の生成とは比較にならないぐらいに難易度が高いものとなります。
私も高性能なText to Textの生成AIからText to Videoの生成AIまで1年もかからないとは思いませんでした。
2023年度、Text to Textやマルチモーダルの領域で「GPT-4」は革命的でしたが、OpenAIは2024年度に「Sora」によってText to Videoの領域でも革命を起こした印象です。
今年も生成AI領域はOpenAIがリードしていくという状況は変わらなそうですね。
生成AIの進歩に置いて行かれないように、引き続き私も精進します。
今回の私の記事は以上です。