姿勢推定の論文は単純な回帰で行うものからHeapMapを使ってやるものへと進化していった*1
上記のタイトルの論文はHeapMapを用いたものである*2
姿勢推定を行うためのデータセットは主に以下の3つの機関から配布されていてよく使用されている
・FLIC
・MPII
・Human3.6
タイトルの論文では下の二つが使われている。しかしながらいずれもヒートマップに関する情報は含まれておらず、おそらく自分でヒートマップ情報を生成する必要がある。
HeatMap
HeatMap ベースの方法は2014年Tompsonによって考案された*3
http://www.cims.nyu.edu/~tompson/others/joint-training-convolutional.pdf
私の理解が正しければ簡単に言うとこの方法は通常のフィルターで、任意の体位らしき場所を推定した後その連結した体位と一緒にNNに突っ込むことで正しく位置を推定するというものである。
初めはこの方法で自分でHeatMapに関するデータセットを作るのかとも思っていた。
しかし少し前の論文、
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach*5
のgithubリポジトリ
https://github.com/xingyizhou/pose-hg-3d
を見るとdrawGaussianという関数で自分でガウシアンのヒートマップを任意の分散で生成している。
おそらくタイトルの論文もこの方法で通常のヒートマップのGround Truthを作るのだと思われる。いずれもどの方法でもこれは自分で適当に作ればよい。
Location Map
これはすごく理解するのに時間がかかった。
まず本論文のキーポイントは
・2Dのデータセット3Dのデータセットをうまく組み合わせて3Dの推定の精度を上げる
・リアルタイムで実行できるようにする
の二つである。複雑なNNを通してHeatMapおよびXYZのLocationMapの4チャネル分を出力するという方法をとるのは以上の二つを実現したいからに他ならない。
一番理解するのに時間がかかったのはLocationMapのGroundTruthの作り方である。
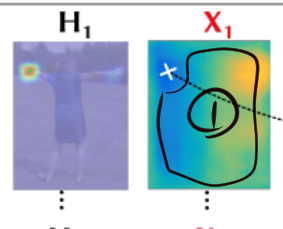
図1 Fig3 切り取り引用
前までなぜXYZがこのような出力になって、図1で示している①領域があるのかずっと理解不能だった。しかし二つのキーポイントと、本論(1)のLoss関数を理解すれば簡単な話だった。
理解するために以下の二つを覚えておきたい
・HeatMapは2Dのデータセットから作るということ
・LocationMapはHeatMapの頂点座標の部分が3Dのデータセットと一致するようにすること
初めはGroundTruth と CNNからの出力はほぼ同じなのかと思っていて①で示した領域のGroundTruthはどうやって生成するのかずっと不明であった。
しかしLoss関数
Loss(x_j) =||H^{GT}_j ⊙ (X_j − X^{GT}_j
)∥ \hspace{15pt} (1)
はHeatMapとのHadamardProductのおかげで (1) は ① で示した領域を0にする。したがって ① 以外の領域はどうなっててもよく最適化に関与しないことがわかる。①以外の領域はdrawGaussianのように適当にやればいい。また、LocationMapはGaussianである必要はない。
おそらくいろいろな位置にあるデータセットでやっているうちに図1のような出力になるのではないかと思われる。
今後
pytorchで完全なる実装をし以下のOSSでipadアプリを作る。https://blog.prismalabs.ai/diy-prisma-app-with-coreml-6b4994cc99e1
参考文献
[1] DeepPose: Human Pose Estimation via Deep Neural Networks
https://arxiv.org/pdf/1312.4659.pdf (回帰を使った方法)
[2] VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera (タイトルの論文)
http://gvv.mpi-inf.mpg.de/projects/VNect/content/VNect_SIGGRAPH2017.pdf
[3]Joint Training of a Convolutional Network and a
Graphical Model for Human Pose Estimation (HeatMapベースの原点)
http://www.cims.nyu.edu/~tompson/others/joint-training-convolutional.pdf
[4]Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach
https://arxiv.org/abs/1704.02447