introduction
dpdkプラットフォームで、distributorモデルのEncap/Decapパケット転送装置を設計すると、システムイメージは以下のようになる
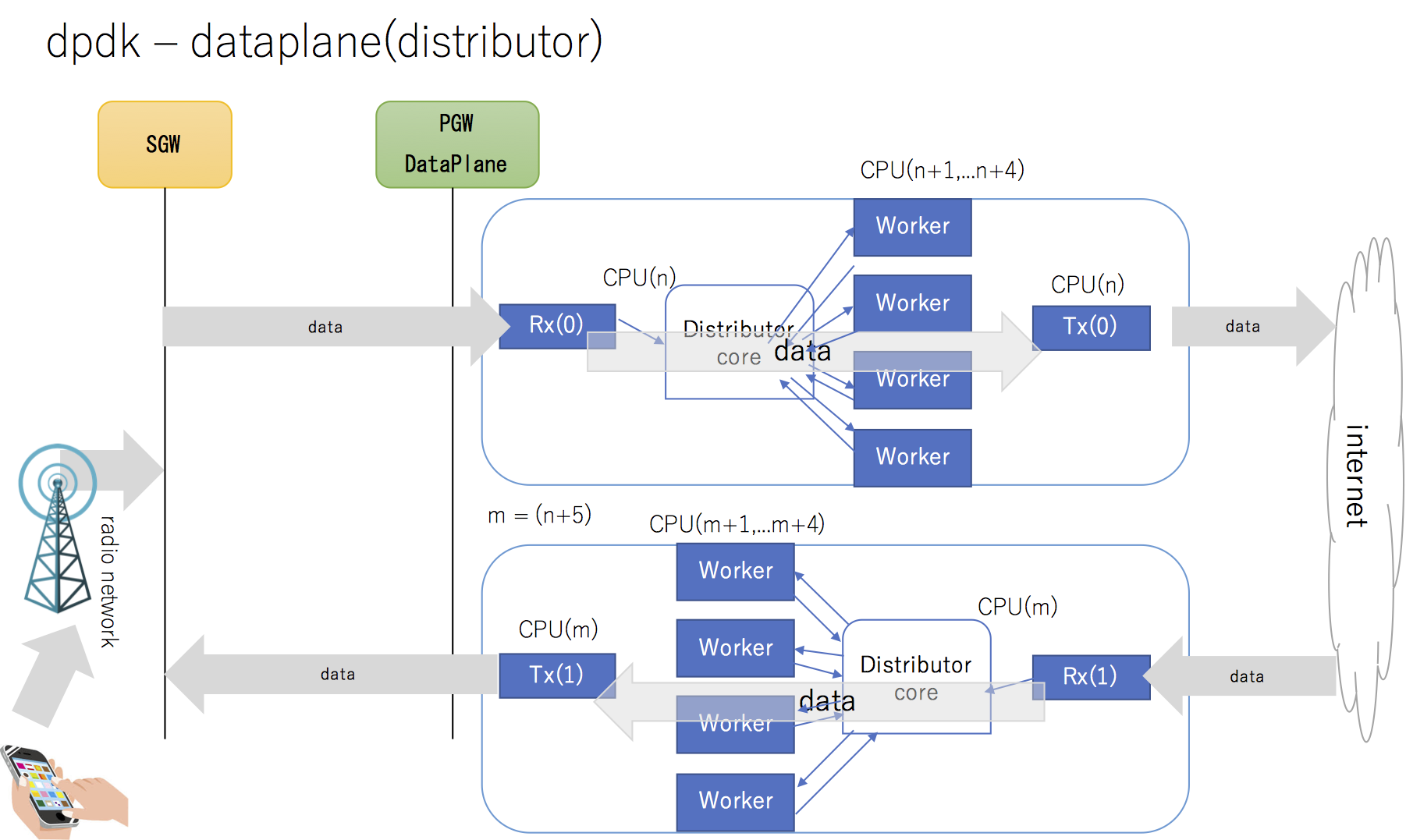
ingress packet sequence
radio ネットワーク、モバイルコアネットワークからのingressパケットのデータシーケンスは以下のように定義する
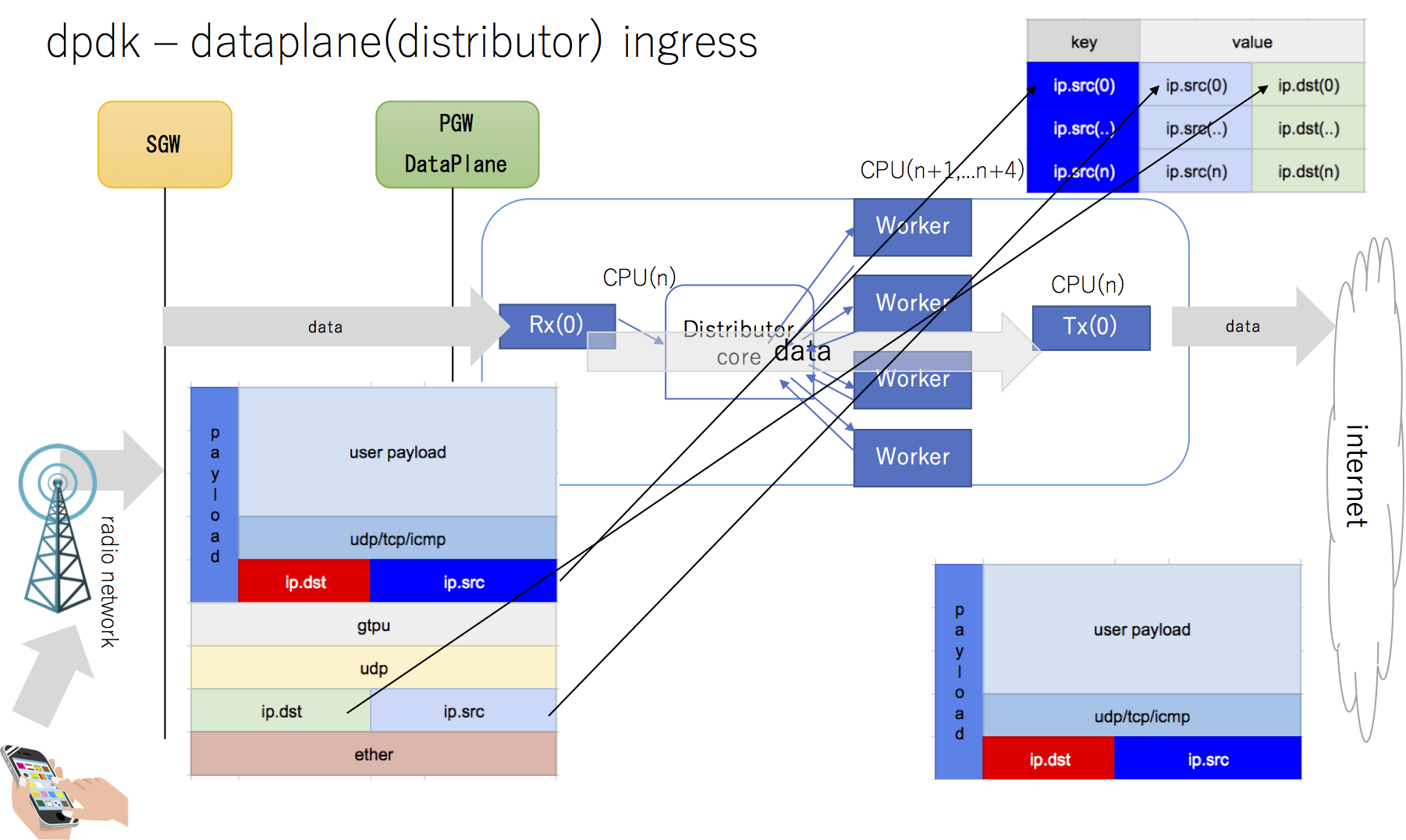
egress packet sequence
engress パケットデータシーケンスを以下のように定義する
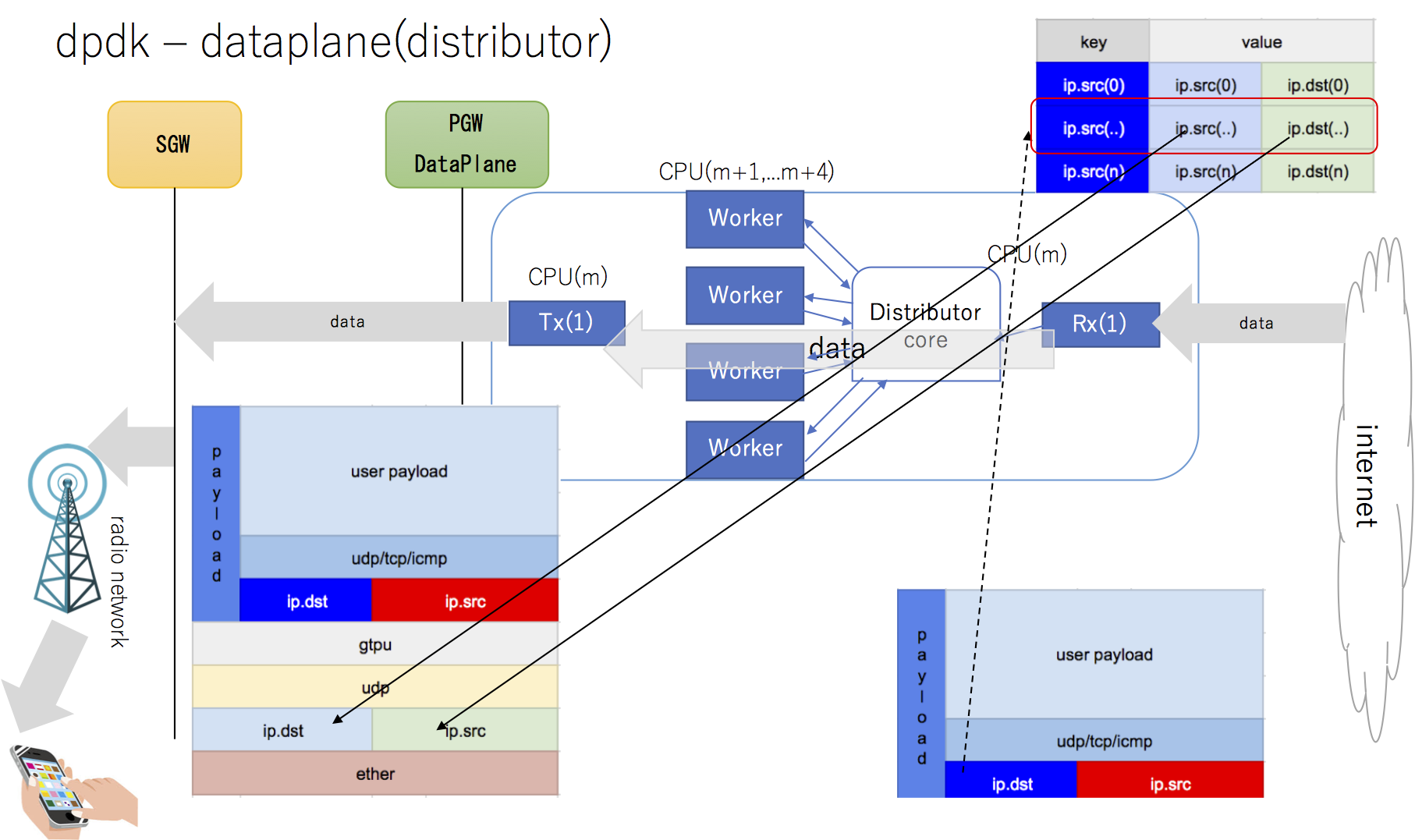
コア間共有map
cpu(n+1) : cpu(m+1) ... cpu(n+4) : cpu(m+4) ..においてCPUコア間を共有するmapを以下に定義し 全てのingressパケッット でmap検索、更新処理を以下イメージで設計した
shared valiables
typedef uint32_t KEYIPSRC;
typedef uint32_t VALIP;
static std::unordered_map< KEYIPSRC, VALIP > shared_map;
static rte_spinlock_t core_lock[MAX_WORKERS];
static struct ether_header encap_ether;
static struct udphdr encap_udp;
static struct gtpu encap_gtpu;
static bool is_first_packet = true;
ingress core
auto lock = core_lock[rte_lcore_id()];
// cpu core[n+[1-4]]
auto ip = rte_pktmbuf_mtod_offset(m, struct ip*, sizeof(struct ether_hdr));
auto ip_internal = rte_pktmbuf_mtod_offset(m, struct ip*, sizeof(struct ether_header)+
sizeof(struct ip) +
sizeof(struct udphdr) +
sizeof(struct gtpu));
auto value = ((uint64_t)ip->ip_src.s_addr)<<32) || ((uint64_t)ip->ip_dst.s_addr));
if (is_first_packet){
memcpy(&encap_ether,
rte_pktmbuf_mtod(m, char*), sizeof(encap_ether));
memcpy(&encap_udp,
rte_pktmbuf_mtod_offset(m, char*,
sizeof(struct ether_header) +
sizeof(struct ip)), sizeof(encap_udp));
memcpy(&encap_gtpu,
rte_pktmbuf_mtod_offset(m, char*,
sizeof(struct ether_header) +
sizeof(struct ip) +
sizeof(struct udphdr)), sizeof(encap_gtpu));
is_first_packet = false;
}
rte_spinlock_lock(&lock);
auto it = shared_map.find(ip_internal->ip_src.s_addr);
if (it != shared_map.end()){
if ((it->second).ip_src.s_addr != ip->ip_src.s_addr ||
(it->second).ip_dst.s_addr != ip->ip_dst.s_addr){
shared_map.find[ip_internal->ip_src.s_addr] = value;
}
}else{
shared_map.find[ip_internal->ip_src.s_addr] = value;
}
rte_spinlock_unlock(&lock);
egress core
auto lock = core_lock[rte_lcore_id()];
// cpu core[m+[1-4]]
auto ip = rte_pktmbuf_mtod_offset(m, struct ip*, sizeof(struct ether_hdr));
bool drop = false;
struct ip found_ip;
rte_spinlock_lock(&lock);
auto it = shared_map.find(ip->ip_dst.s_addr);
if (it != shared_map.end()){
if ((it->second).ip_src.s_addr != ip->ip_src.s_addr ||
(it->second).ip_dst.s_addr != ip->ip_dst.s_addr){
found_ip = (it->second).ip_src;
found_ip = (it->second).ip_dst;
}else{
drop = true;
}
}else{
drop = true;
}
rte_spinlock_unlock(&lock);
if (drop){
rte_pktmbuf_free(m);
}else{
// do forward.
do_forward(&encap_ether, &found_ip, &encap_udp, &encap_gtpu,
}
シミュレータネットワーク接続前
シミュレータ環境ネットワークに接続する前に、ingress / egress 双方向がwire rateトラフィックのケースでどの程度パフォーマンスがあるのか評価した
(非ロックfixedのmapと比較: http://qiita.com/l2nw/items/c0f7c5bb572cad31da3c )
busy loopでの計測
- std::unorderedmap に1Mレコードを投入
- CPUコア[x]にingress相当の仮想処理
- CPUコア[x']でegress〃
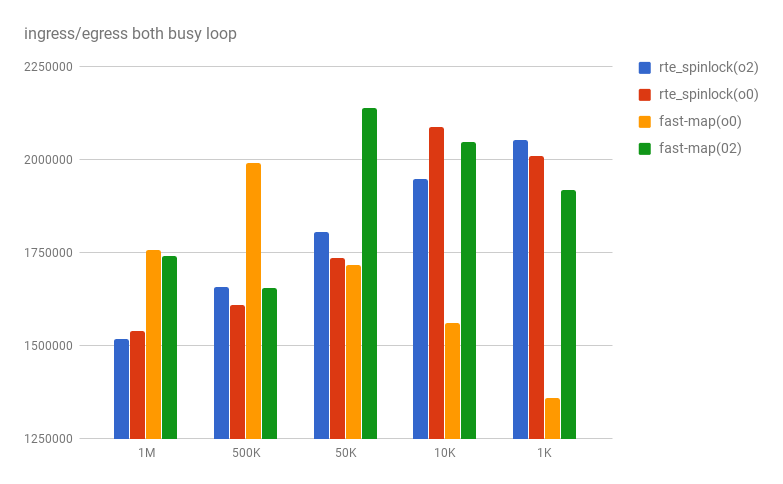
100万〜1000 レコードまで計測すると、安定して遅く、1.5Mops(秒間オペレーション数)程度であった
比較対象のfastmapは、計測結果の揺らぎが大きくなった、推測では、busy-loopの場合、粒度の高いロックで処理したほうが、numa memory coherence protocol をbusy-loopするよりも平準化していると考えた
ingress 側にCPUローカルでexpire - cache
busy - loopでは、1コアあたり2Mppsを超えると、map::findがボトルネックとなりパケットドロップが発生することがわかったため、ingress側処理の存在確認をThread Local(CPU local)一次キャッシュで判定するように変更すると、以下までパフォーマンスをアップできた
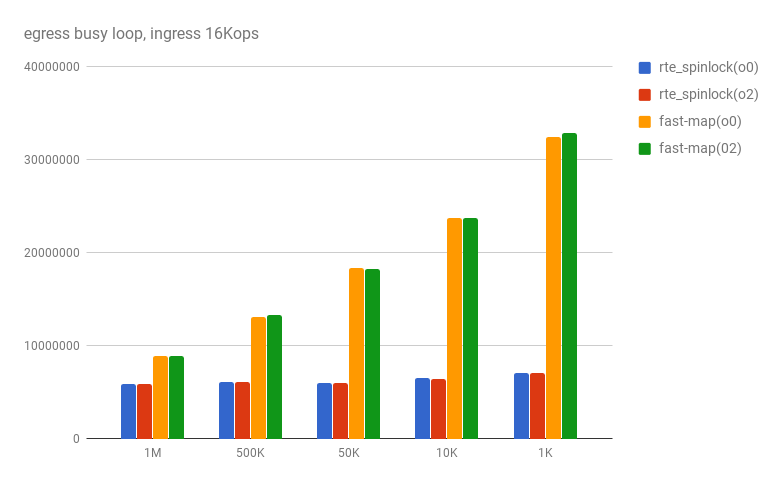
rte_spinlock_lock 使用時でも6Mops,fastmap使用時はレコード数に反比例してパフォーマンス劣化するが、おおよそ1Mレコードで1.5倍、500kレコードで2倍であった
このことからも、 memory coherence protocol の処理頻度を平準化することが、パフォーマンスに直接的に関連することがわかった