はじめに
先日、AI・人工知能Expoに行った際、GRIDのブースで ReNom TDAについて聞いてきました。
データを可視化するのに使いやすく理解の助けになりそうと思い、githubから持ってきて
試して見ました。まずはGUIでcsvファイルの分析を試して見ます。
準備
インストール手順や、使い方等は ReNomのサイトに詳しく書いてあります。
インストール
ReNom本体
http://www.renom.jp/ja/rsts/renomdl/main.html
ReNom TDA
http://www.renom.jp/ja/rsts/renomtda/main.html
ReNom TDA APIでの使用例
http://www.renom.jp/ja/notebooks/tda/mnist-dataset-mapping/notebook.html
GUIでの使い方
http://www.renom.jp/ja/notebooks/tda/how-to-use-gui/notebook.html
GUIでデータ分析する場合のポイント
データ分析では有名なtitanicのデータを分析してみると事にしました。その際少しハマったところは下記の点です。
- Csvファイルを、インストールしたReNomTDA以下の gui/data 以下にコピーする必要がありようです。
- 欠損価があるとそもそもloadできなさそうなので、欠損値のある行はとりあえず削除
- テキストは分析対象にならなさそうなので、数値に置き換え。例えば sex は male=1とfemale=2など
- 名前など分析対象外のものは列ごと削除
上記をまとめて対応したスクリプトです。
sed 's/"\([^"]*\)"/"pname"/' train.csv | cut -d, -f1,2,3,5,6,7,8,10,12 | sed '/,,/d' | sed 's/female/2/' | sed 's/male/1/' | sed 's/C/1/' | sed 's/Q/2/' | sed 's/S/3/' > train_noname.csv
train_noname.csvを読み込めると、ヒストグラムが表示されます。
「計算に使う」はターゲットデータであるSurvived以外にチェック、「色に使う」は全選択します。

分析結果
まずは一般的な主成分分析し、散布図で表示、色はSurvivedかどうかを見てみます。
何となく、生存者かどうか、傾向は見えるように思います。
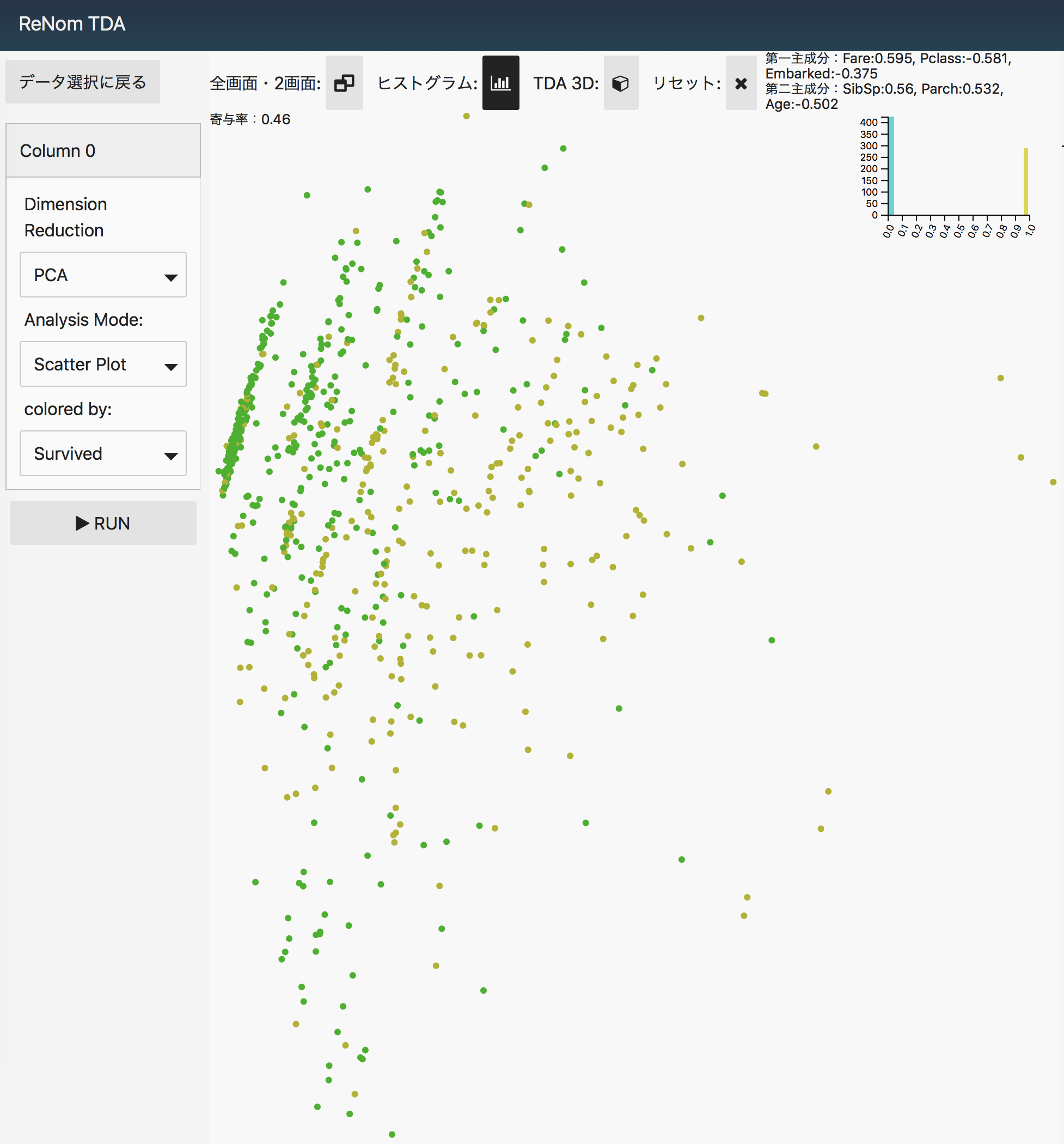
次に分析モードだけをTDAに変えて、散布図と比較して見たところです。
図はカッコいいのですが、どう見ればいいのかな?

終わりに
正直なところ、どう読み取るべきか、いまひとつ分かりません。
TDA 自体を理解する必要があるようです。