はじめに
Attentionを試して見たくて、調べて見たところ、下記の記事がサンプルプログラムもあってわかりやすく解説されていたので、試して見ました。
https://medium.com/datalogue/attention-in-keras-1892773a4f22
https://github.com/datalogue/keras-attention
チュートリアル
様々な日付表記文字列をエンコードし、bidirectional LSTMモデルで YYYY-MM-DD フォーマットの文字列をデコードするというものです。データセットは、Fakerいうツールで日付文字列を生成したあとbabelでフォーマット、多言語に変換することで多様な日付表記のデータセットを作り出しています。
トレーニング結果
手元のPCだと、2時間ほどかかりました。最終的にはAccuracyは99%以上になりました。
Epoch 50/50
1/100 [..............................] - ETA: 1:54 - loss: 0.0119 - acc: 0.9962 - all_acc: 0.0000e+00
2/100 [..............................] - ETA: 1:57 - loss: 0.0073 - acc: 0.9975 - all_acc: 0.0000e+00
...
98/100 [============================>.] - ETA: 2s - loss: 0.0092 - acc: 0.9970 - all_acc: 0.0000e+00
99/100 [============================>.] - ETA: 1s - loss: 0.0092 - acc: 0.9970 - all_acc: 0.0000e+00
100/100 [==============================] - 161s 2s/step - loss: 0.0092 - acc: 0.9970 - all_acc: 0.0000e+00 - val_loss: 0.0086 - val_acc: 0.9972 - val_all_acc: 0.0000e+00
トレーニング後、例として"2001年01月01日"という文字列をinputした時のAttentionの様子です。
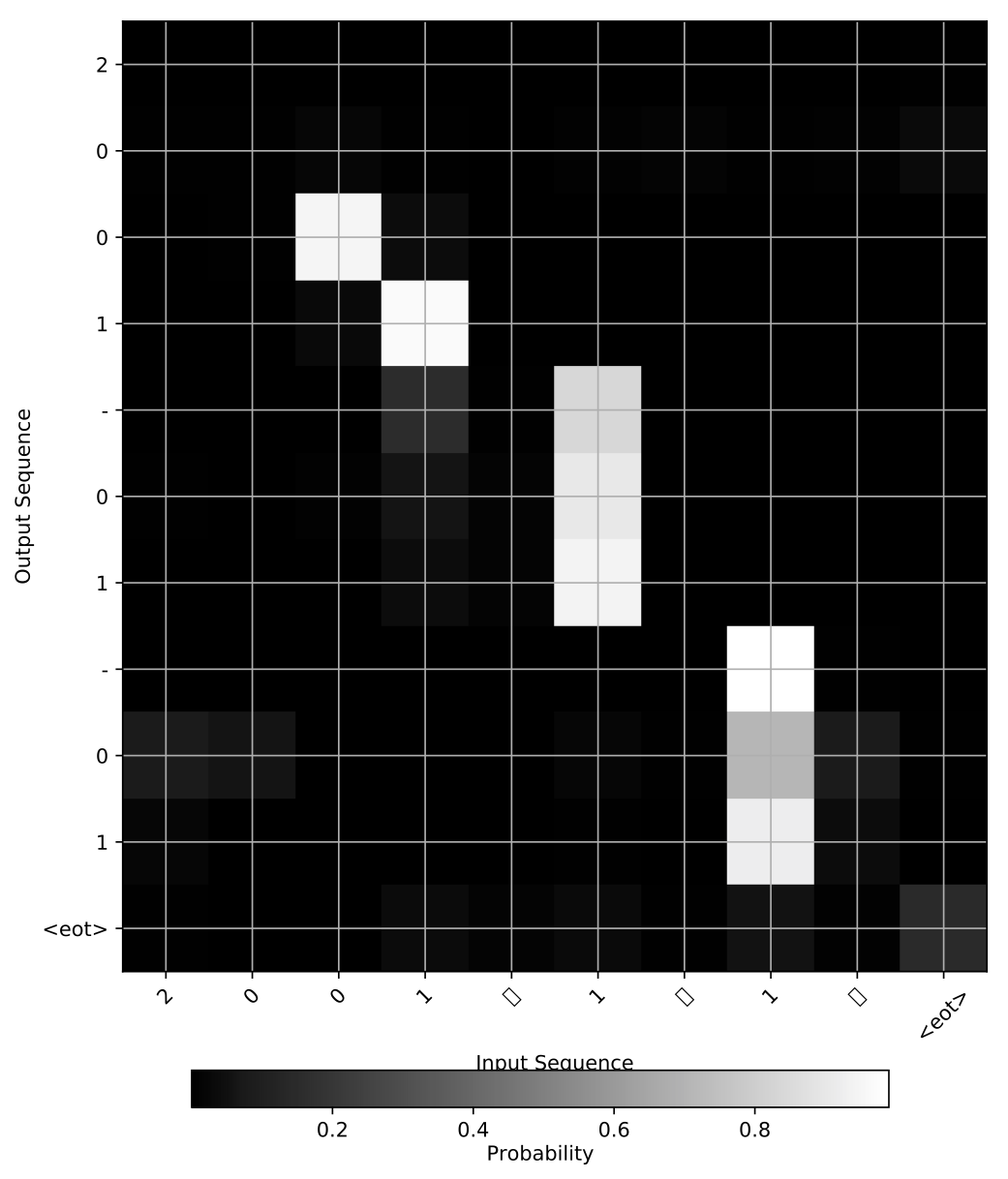
"01"という文字列が複数含まれていても、ちゃんと正しいところをAttentionしてOutputしていることがわかります。
最後に
deep learningはブラックボックスとよく言われますが、Attentionによって着目しているところが明確になることで、ブラックからグレーぐらいにはなるように思います。