はじめに
CVPR2020に採択された以下の論文で提案された,新しいニューラルネットワークである$\Pi$-NetをPyTorchで実装しました。
Chrysos, Grigorios G., et al. "$\Pi-$ nets: Deep Polynomial Neural Networks." arXiv preprint arXiv:2003.03828 (2020).
学習に使った全体のコードはGitHubにあります。
Π-Netとは?
$\Pi$-Netではネットワークを途中で分岐させ,再び合流する部分で掛け算を行います。
これにより,出力が入力の多項式で表現されます。
普通のニューラルネットワークでは,各層の出力にReLUやSigmoidなどの活性化関数を適用することで非線形性を持たせています。
活性化関数を使わないと,ネットワークの層数をいくら増やしても入力に対して線形な出力しかできないため,意味がありません。
しかし,$\Pi$-Netでは中間層の出力同士で掛け算を行うことでネットワークに非線形性を持たせているので,活性化関数を用いなくても多層にすることで高い表現能力を得ることができます。
論文中ではいくつかネットワーク構造が提案されていますが,今回はその中の1つである以下の構造をベースに実装しました。
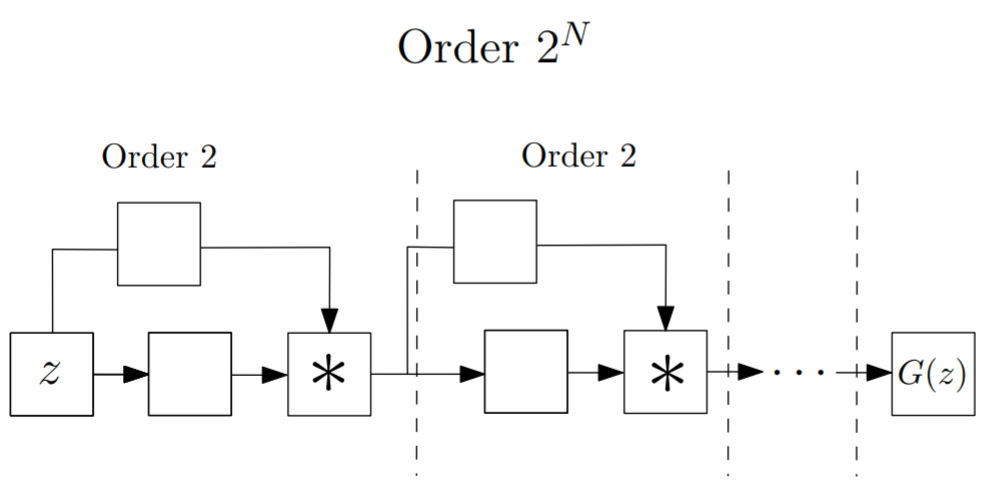
(論文から引用)
Skip-connectionがありResNetのような構造をしていますが,合流する部分が足し算ではなく掛け算(アダマール積)になっています。
各ブロックで前のブロックの出力が2乗されるので,ブロックを$N$個重ねることで$2^N$次の多項式になり,指数的にネットワークの表現能力が増加していきます。
実装
上図のブロックを5つ重ね,以下のようなモデルを書きました。
従って,ネットワークの出力は$2^5=32$次の多項式で表現されます。
活性化関数を全く使っていない点に注目してください。
class PolyNet(nn.Module):
def __init__(self, in_channels=1, n_classes=10):
super().__init__()
N = 16
kwds1 = {"kernel_size": 4, "stride": 2, "padding": 1}
kwds2 = {"kernel_size": 2, "stride": 1, "padding": 0}
kwds3 = {"kernel_size": 3, "stride": 1, "padding": 1}
self.conv11 = nn.Conv2d(in_channels, N, **kwds3)
self.conv12 = nn.Conv2d(in_channels, N, **kwds3)
self.conv21 = nn.Conv2d(N, N * 2, **kwds1)
self.conv22 = nn.Conv2d(N, N * 2, **kwds1)
self.conv31 = nn.Conv2d(N * 2, N * 4, **kwds1)
self.conv32 = nn.Conv2d(N * 2, N * 4, **kwds1)
self.conv41 = nn.Conv2d(N * 4, N * 8, **kwds2)
self.conv42 = nn.Conv2d(N * 4, N * 8, **kwds2)
self.conv51 = nn.Conv2d(N * 8, N * 16, **kwds1)
self.conv52 = nn.Conv2d(N * 8, N * 16, **kwds1)
self.fc = nn.Linear(N * 16 * 3 * 3, n_classes)
def forward(self, x):
h = self.conv11(x) * self.conv12(x)
h = self.conv21(h) * self.conv22(h)
h = self.conv31(h) * self.conv32(h)
h = self.conv41(h) * self.conv42(h)
h = self.conv51(h) * self.conv52(h)
h = self.fc(h.flatten(start_dim=1))
return h
結果
MNISTとCIFAR-10の分類を学習しました。
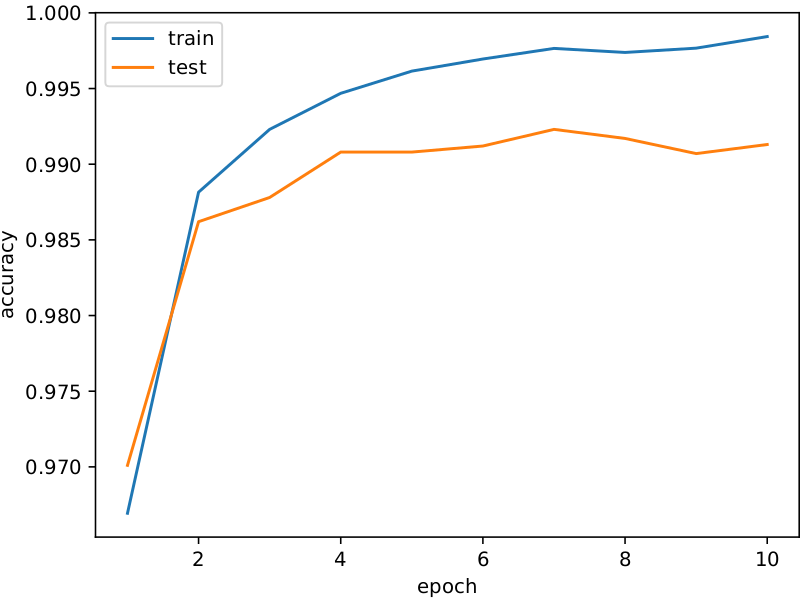
MNIST
Accuracy
Loss
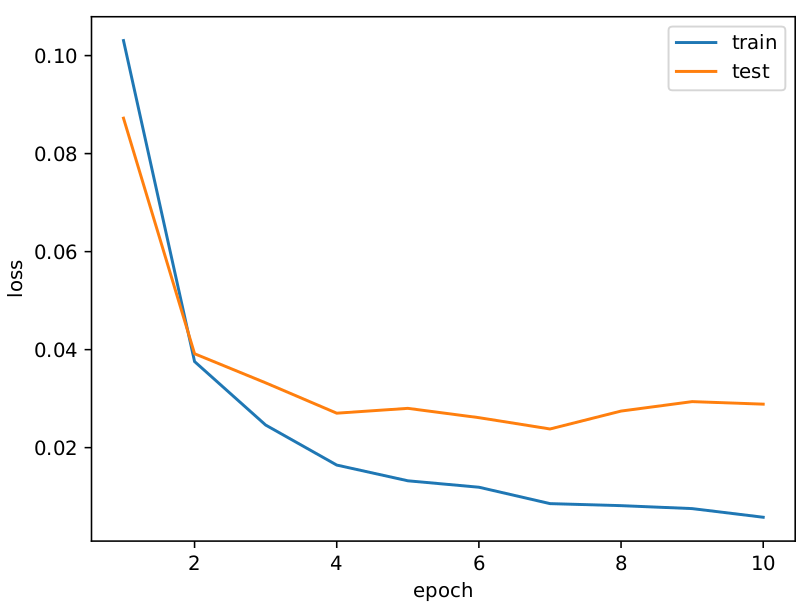
約99%のテスト精度です!
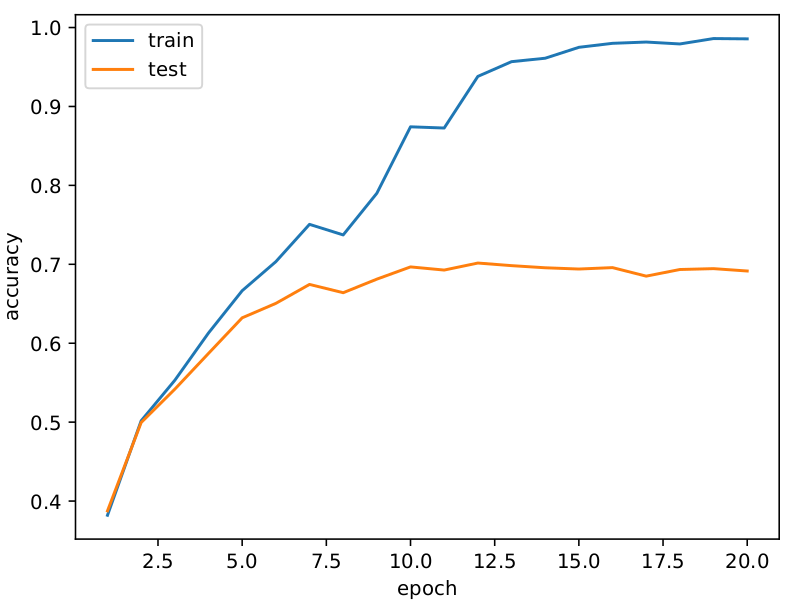
CIFAR-10
Accuracy
Loss
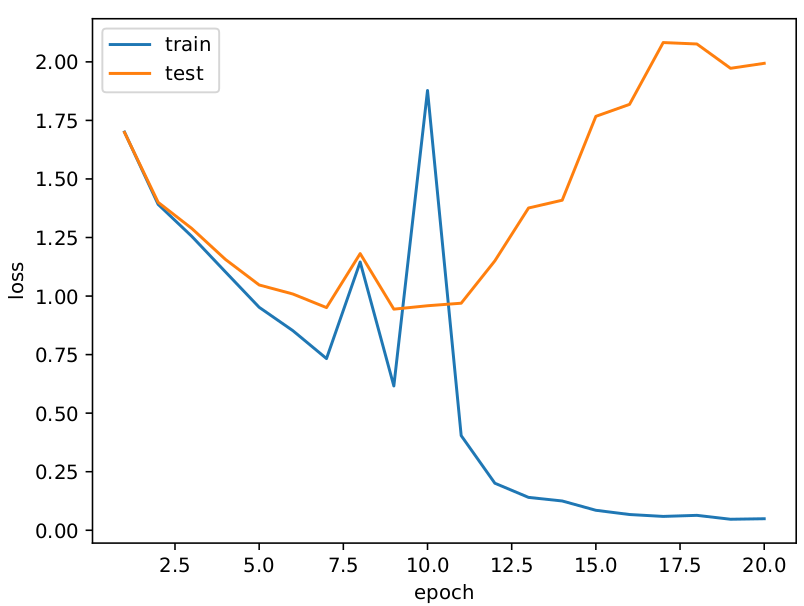
テストが70%くらいの精度ですが過学習していますね・・・
おわりに
出力が入力の多項式になるので活性化関数を使わずに学習ができました。
ブロックを重ねることで表現力が指数的に向上すると上述しましたが、
普通のニューラルネットワークでも層数に対して指数的に表現力が向上することが知られている1ので、正直$\Pi$-Netの利点はよく分からなかったです・・・
-
Montufar, Guido F., et al. "On the number of linear regions of deep neural networks." Advances in neural information processing systems. 2014. ↩