何を書いた記事か
過去にDynamoDB Streams + Kinesis Data Firehose + Lambdaを用いたリアルタイムETLを検証した際のメモをこちらに転載します。
特にKinesis Data Firehoseの裏で動かすLambdaの実装に癖があったので、誰かの参考になれば幸いです。
前提
Webサービスなど展開していて、Database層にDynamoDBを採択している場合、そのデータを分析するための分析基盤構築手法として、Glueを用いたETLが一般的な選択肢になりうるのかなと思います。
最近DynamoDBのTableをS3にExportできる機能もGAになったので、フルダンプ+日時バッチのデータ分析としてはそのような手法も使えるかもしれません。
しかし、DynamoDB上にあるデータをなるべくリアルタイムに分析基盤に連携したい、最低限のETL処理も挟みたい、といったことを考えると、GlueやS3 Exportでは更新頻度やコストの面で優位に働かないケースがほとんどだと思います。
そこで有力な選択肢として上げられるのがDynamoDB StreamsとKinesis Data Firehoseを組み合わせる手法です。
実際にどのような構成で検証したのか、実装上ハマったポイントはどこか、など共有できればと思います。
構成
構成概要
作成した基盤の構成概要は下記です。
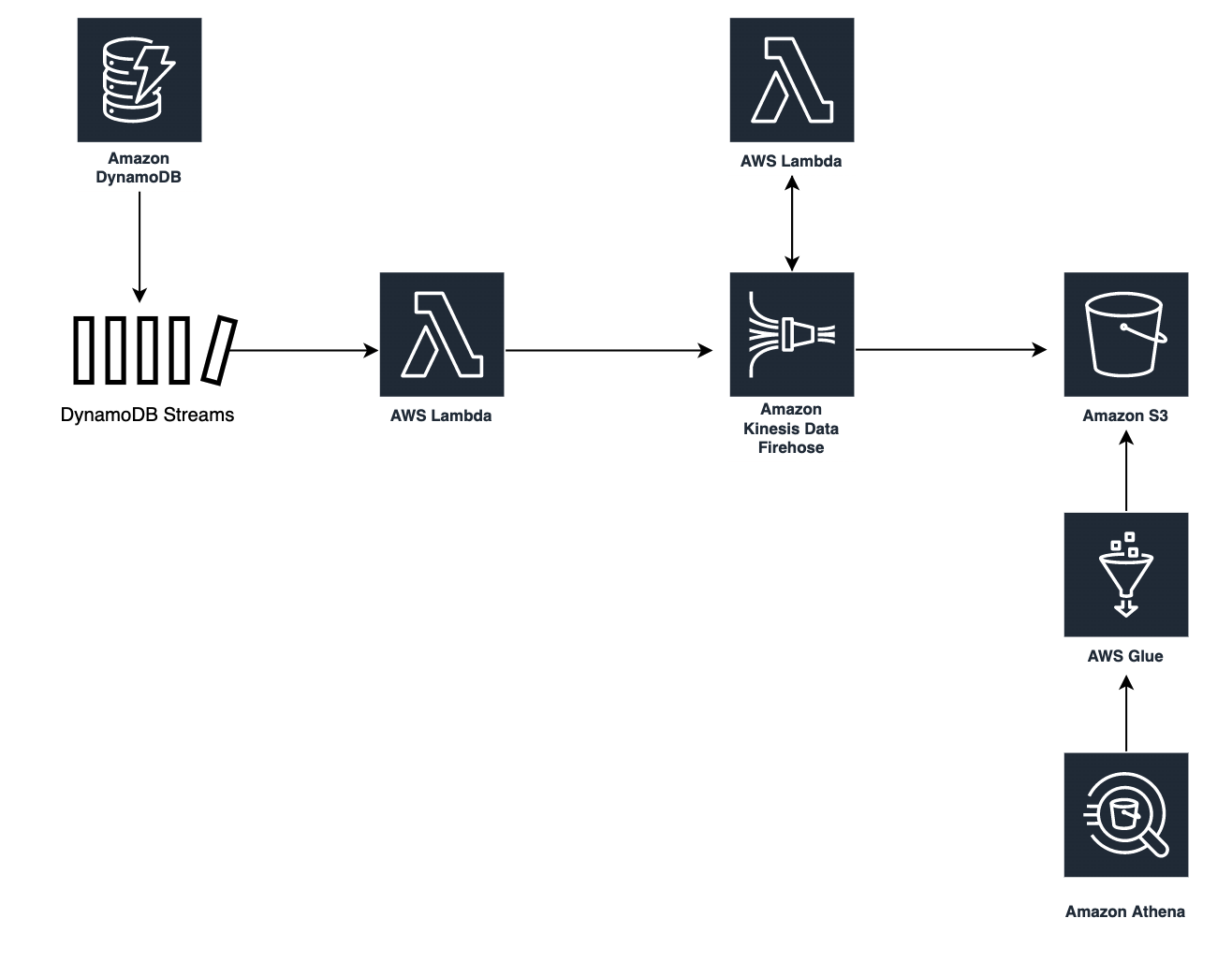
各リソースの役割
各リソースの役割を下記に記載します。
- DynamoDB Streams
- 後続のKinesis連携用Lambdaをキック
- Lambda Function ①
- DDB Streamsから同期実行
- 受け取ったイベントをKinesisにそのまま流すのみ
- Kinesis Data Firehose
- Streaming Dataを受信したら一定時間Bufferingし、Transform用のLambdaを実行
- Transform用Lambdaから返却されたデータをObjectとしてS3に保管
- 保管先のPrefixとしてHive形式のPartitioningを指定
- Lambda Function ②
- Kinesis Firehoseが受け取ったデータを変換する
- ETL処理を担当
- Firehoseに戻す際は、csv形式のレコードをbase64にEncodeし、Statusなど所定のparamsを付与する必要がある(後述)
- S3
- KinesisによってBuffering・TransformされたStreaming Dataを格納
- 格納PrefixはHive形式でPartitioning
- Glue (Crawler)
- S3に置かれたObjectに対してDataCatalogを生成
- Athena
- Glue Crawlerが生成したDataCatalogを用いて、S3上のデータに対してクエリを実行
特記ポイント
DynamoDB Streams → Lambdaの連携について
DynamoDB StreamsはTable単位で有効にすることができ、Subscriberとして選択できるリソースはLambdaのみです。
また、仕様上Lambdaは同期実行されることとなります。
そこで気になったのでStreamsの後ろで実行されるLambdaをわざと失敗する状態にして、
- Lambdaが失敗したとき、DynamoDB自体のINSERT/UPDATE/DELETEに影響はないか
- Lambda自体のリトライや異常終了時にどのような挙動になるか
を調べてみました。
前者の、DynamoDB自体の更新処理に関しては、Streamsの先のLambdaで失敗しても、問題なく完了することが確認できました(そうじゃないと怖くて使えない)
一方、後者のLambdaのリトライについて、確実にRaiseするLambdaを後続で動かして1レコード更新した際、永遠に際実行処理が繰り返されているように見えました。
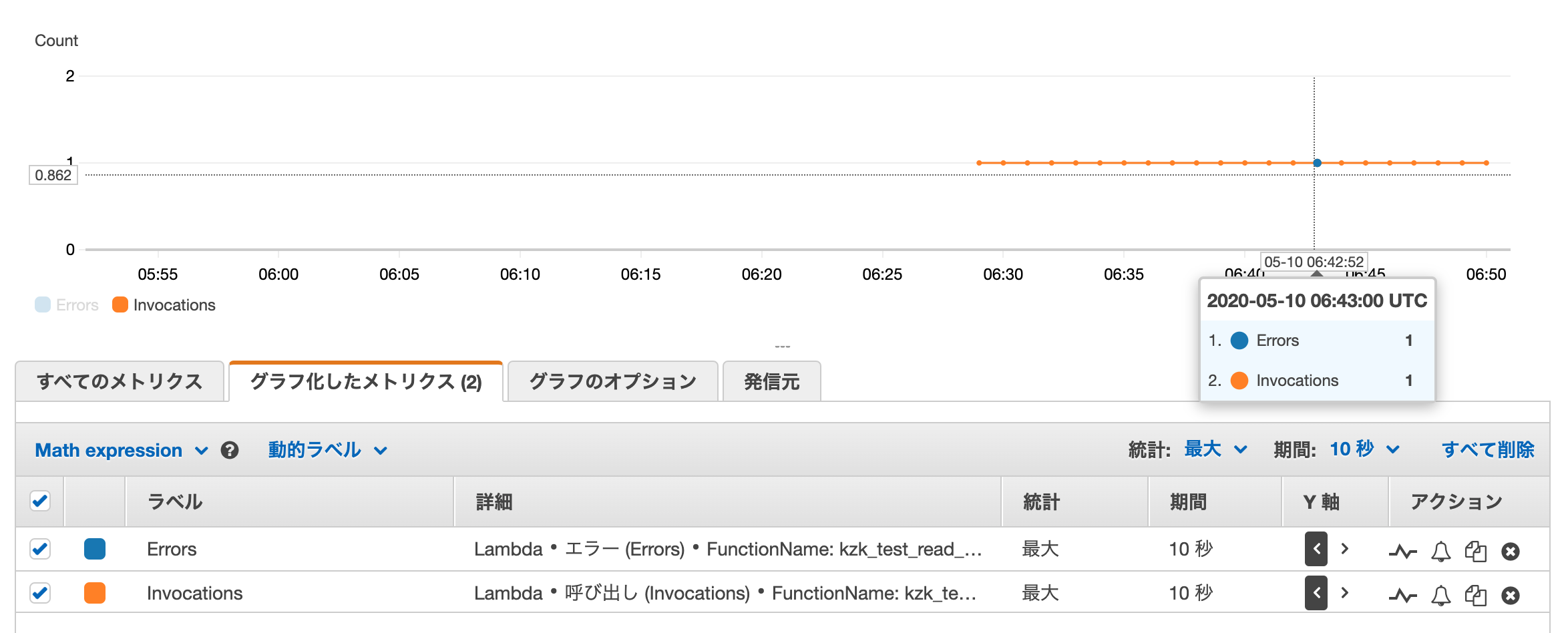
いつまでもLambdaが終了しないので調べてみたところ、同期実行のLambdaはデフォルトで下記の設定になっていることがわかりました。
- リトライ回数は10000回
- 並列度は1
これでは、なんらかのエラーでStreams+Lambdaが失敗したとき、その失敗処理が10000回リトライして終了するまで、後続の更新処理がStreamingされないこととなり、運用上とても実用に耐えうる構成にはなりません。
そこで、下記の修正を加えることとしました。
- EventSourceMappingからリトライ回数を調整(今回は3回)
- 同時実行数を2以上の値に設定
この辺りは本番のトラフィック・データ更新頻度に合わせてチューニングする必要があります。
並列処理に関しては一点懸念があって、並列度を2以上にしたからと言って、どこかのシャードが詰まった時に、その後ろのStreaming Dataは確実に空いてる方のシャードに割り当てられるわけではないということです。
これは、並列実行時にどのシャードにタスクを配置するかは、Hash値によってランダムに決められるので、滞留しているシャードにタスクが配置されたら、結局後続のタスクは実行されず、対流を繰り返すこととなる仕様なので避けられず、好ましい実装としてはリトライ回数を小さく設定し、リトライが全て失敗した時に通知を出すようにするのがベストなのかなと考えました(意見が聞きたいです)。
Kinesis Data Firehoseの裏で実行するETL用Lambdaについて
Kinesis Data Firehoseの裏で呼び出すETL用のLambdaは、Kinesisの仕様をふんだんに取り入れた作りにする必要があります。
Lambda自体はBluePrint(Node.jsかPython)が提供されているので、それを参考に構成するのがいいと思いますが、一応気をつけた方がいいだろうと思ったポイントを記載しておきます。
- Lambda自体のTimeoutは1min以上にする必要がある
- Kinesis Data Firehoseから連携されたPayload Sizeが6MBを超えるときは、PayloadをFirehoseに戻す必要がある
- さらに、その戻すRecord数が500を超える場合は分割する必要がある
- Transform処理が完了したデータをFirehoseに戻す際、所定フォーマットにしたがった形式で、Dataの実態はbase64でencordする必要がある
Lambdaを構築する場合はこの辺り参考にしてみてください。
https://docs.aws.amazon.com/ja_jp/firehose/latest/dev/data-transformation.html
サンプルコードはこんな感じです。
試しにtransform関数の中で必要なレコードを抽出してフォーマット変換し、csvに直して返すような処理にしてみました。
ここに実際に必要なETL処理の本体を書くことになります。
Transform Lambda
import json
import boto3
import base64
from datetime import datetime
PAYLOAD_MAX_SIZE = 6000000
MAX_RECORD_COUNT = 500
def transform(data):
"""
データ変換関数
"""
data['NewColumn'] = 'New Value'
# Change Schema
id = data.get('id').get('S')
user_id = data.get('user_id').get('S')
store_id = data.get('store_id').get('S')
created = data.get('created').get('S')
created = datetime.strptime(created, '%Y-%m-%dT%H:%M:%S').strftime('%Y-%m-%d %H:%M:%S')
updated_at = data.get('updated_at').get('S')
updated_at = datetime.strptime(updated_at, '%Y-%m-%dT%H:%M:%S').strftime('%Y-%m-%d %H:%M:%S')
return_data = f'{id},{user_id},{store_id},{created},{updated_at}'
print(return_data)
return return_data
def proceed_records(records):
"""
transform each data and yield each record
"""
for record in records:
record_id = record.get('recordId')
data = json.loads(base64.b64decode(record.get('data')))
# print("Raw Data : " + str(data))
try:
transformed_data = transform(data)
result = 'Ok'
except Exception as e:
print(e)
transformed_data = data
result = 'ProcessingFailed'
print("New Data : " + transformed_data)
# proceeded_data = json.dumps(transformed_data) + '\n'
proceeded_data = transformed_data + '\n'
return_record = {
"recordId": record_id,
"result": result,
"data": base64.b64encode(proceeded_data.encode('utf-8'))
}
yield return_record
def put_records_to_firehose(streamName, records, client):
print('Trying to return record to firehose')
print(f'Item count: {len(records)}')
print(f'Record: {str(records)}')
try:
response = client.put_record_batch(DeliveryStreamName=streamName, Records=records)
except Exception as e:
# failedRecords = records
errMsg = str(e)
print(errMsg)
def lambda_handler(event, context):
invocation_id = event.get('invocationId')
event_records = event.get('records')
# Transform Data
records = list(proceed_records(event_records))
# Check Data
projected_size = 0 # Responseサイズが6MBを超えない様制御
data_by_record_id = {rec['recordId']: _create_reingestion_record(rec) for rec in event['records']}
total_records_to_be_reingested = 0
records_to_reingest = []
put_record_batches = []
for idx, rec in enumerate(records):
if rec['result'] != 'Ok':
continue
projected_size += len(rec['data']) + len(rec['recordId'])
if projected_size > PAYLOAD_MAX_SIZE:
"""
Lambda 同期呼び出しモードには、リクエストとレスポンスの両方について、
ペイロードサイズに 6 MB の制限があります。
https://docs.aws.amazon.com/ja_jp/firehose/latest/dev/data-transformation.html
"""
print(f"Payload size has been exceeded over {PAYLOAD_MAX_SIZE/1000/1000}MB")
total_records_to_be_reingested += 1
records_to_reingest.append(
_get_reingestion_record(data_by_record_id[rec['recordId']])
)
records[idx]['result'] = 'Dropped'
del(records[idx]['data'])
if len(records_to_reingest) == MAX_RECORD_COUNT:
"""
Each PutRecordBatch request supports up to 500 records.
https://docs.aws.amazon.com/firehose/latest/APIReference/API_PutRecordBatch.html
"""
print(f'Records count has been exceeded over {MAX_RECORD_COUNT}')
put_record_batches.append(records_to_reingest)
records_to_reingest = []
if len(records_to_reingest) > 0:
# add the last batch
put_record_batches.append(records_to_reingest)
# iterate and call putRecordBatch for each group
records_reingested_already = 0
stream_arn = event['deliveryStreamArn']
region = stream_arn.split(':')[3]
stream_name = stream_arn.split('/')[1]
if len(put_record_batches) > 0:
client = boto3.client('firehose', region_name=region)
for record_batch in put_record_batches:
put_records_to_firehose(stream_name, record_batch, client)
records_reingested_already += len(record_batch)
print(f'Reingested {records_reingested_already}/{total_records_to_be_reingested} records out of {len(event["records"])}')
else:
print('No records to be reingested')
# Return records to Firehose
return_records = {
'records': records
}
print(str(return_records))
return return_records
# Transform method for temporary data
def _create_reingestion_record(original_record):
return {'data': base64.b64decode(original_record['data'])}
def _get_reingestion_record(re_ingestion_record):
return {'Data': re_ingestion_record['data']}
このLambdaに処理されたデータは、Kinesis Data Firehoseにバッファリングされたのち、所定の形式でPartitioningされたS3に出力されます。
例えば year=2020/month=12/day=16 みたいなキーに出力するようにFirehose側で設定して、そのキーの上位ディレクトリに対してGlue Crawlerを実行してDataCatalogを作成・更新するように構成すれば、ほぼリアルタイムでDynamoDBに入った更新情報がS3に連携され、そこに対してAthenaなどからクエリを実行できるようになります。
最後に
DynamoDBの更新データをリアルタイム性高くS3に連携し、クエリが実行できる状態にするためのパイプラインの一例について、構成と気をつけポイントを記載しました。
最近はAWSのデータパイプライン周りのUpdateが盛んなので、もしかしたらManaged AirFlowやGlue Elastic Viewsを用いてもっと簡単に構成することができるようになっているかもしれません。
その辺りは未検証なのでなんとも言えないのですが、上記の構成で検討されている誰かが同じところでハマらないよう、参考になれば幸いです。