はじめに
普段RDB(MySQL、PostgreSQLなど)を使っていて、DynamoDBのテーブルを初めて作ったときに別物過ぎて全然手出しができなかったので考え方・設計の方針を書こうと思います。
対象読者
DynamoDBのテーブルを初めて作るそこのあなた![]()
サンプルケース
ユーザが購入した本を登録するテーブル(OrderHistories)を考える。
カラムとしては、
- UserId
- CreateAt
- BookId
何も考えずUserIdをプライマリパーティションキー(RDBの主キー相当)として設定した場合、
- CreateAtで範囲検索
- 特定のBookIdがどれくらい売れたか
が検索できません!(スキャンと呼ばれる全文検索になるので現実的ではなくなる)
![]() ってなりますよね?
ってなりますよね?
DynamoDBのテーブルは辞書型だと考える。
DynamoDBはRDBのテーブルではなくプログラミングのよくある辞書型と捉えると理解が早い気がします。
UserIDを主キーにした場合は1レコードが主キーをキーとしたキーバリュー型のデータ、
{ "UserId" : {その他いろいろ} }
になっています。
その他いろいろの部分にCreateAtやBookIdがあり、要素(レコード)によってはそのカラムがあるかどうかすら保証されていません。
一応スキャンという検索方法で探せなくもないですが、これはテーブルの全データをひっくり返して総当りで見つける方法なのでおすすめできません。
アクセスパターンを考える
DynamoDBではカラムで気軽に検索できません。
なのでどのカラムで検索を行うかをしっかり想定する必要があります。
今回は
- ユーザのある時刻の範囲で購入した本を表示したい
- ある本の販売数を調べたい
でしたね。
これを実現するために2つの設定が必要です。
1.ユーザのある時刻の範囲で購入した本を表示したい
やること:プライマリソートキーにCreateAtを設定する
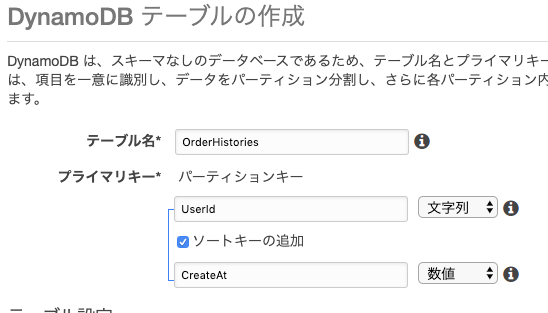
そのままではUserIdでしか検索できませんが、プライマリソートキーを設定することで
UserIdで絞った中でプライマリソートキーでの範囲検索ができるようになります。
2.ある本の販売数を調べたい
やること:インデックスにBookIdを設定する
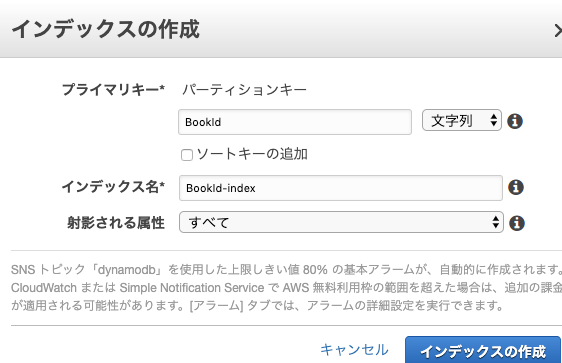
ここはSQLのインデックスに近いものです。
DynamoDBの裏側的にはBookIdをキーにした新しいテーブルができるようです。
{ BookId : {その他いろいろ} }
インデックスを作成する際にその他いろいろの中で必要なカラムを選択することができます。
絞れば検索するときに読み込むデータ量が少なくなるため読み込みキャパシティ消費による料金が安くなります。
困っていること
ある時間範囲で検索したい。SQLで言えばこんな感じ。
select
BookId
from
OrderHistories
where
CreateAt between timeFrom and timeTo
これが難しい。RDBのオートインクリメントされた主キーと違ってバラバラの場所に収まっているため範囲検索しづらい。
苦肉の策として、日別で検索したい場合は、新しいCreateDateを作ってYYYY-MM-DD形式で登録する。
インデックスのパーティションキーとしてCreateDate、ソートキーとしてCreateAtを設定する。
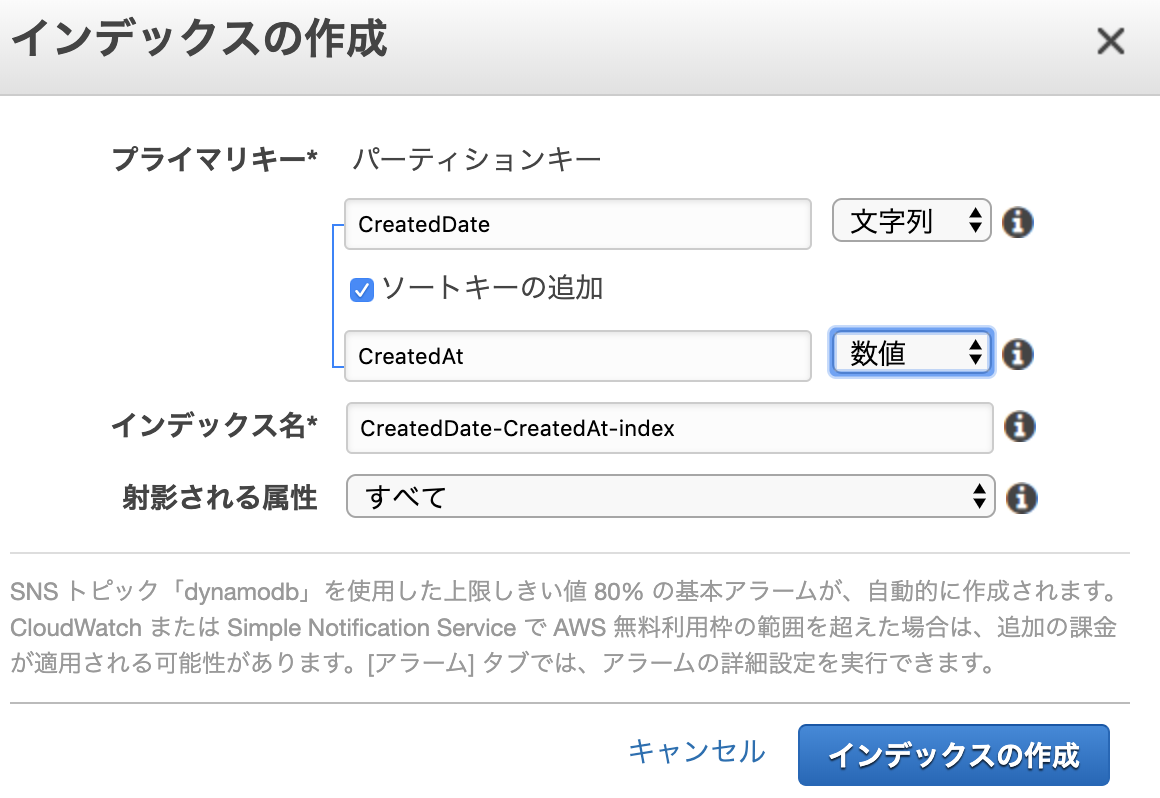
これでYYYY-MM-DD当日中の範囲で検索できる。
その月内で検索する場合はパーティションキーをCreateMonthにする。これしかないのか![]()
もしこの辺の知見(裏技)がある人は教えてほしいです。![]()
まとめ
- 検索するパターンを考える。
- 1.のパターンで使う検索キーに対してインデックスないしパーティションキーを設定する。
です。
RDBがうまいことやってくれていたことを自分で考えて設定しないといけないのでかなりしんどいです。
反面、レコード数無制限、インスタンス管理不要でオートスケール機能、同時接続数の制限がなくなったりとインフラ側の手間が取り払えるのはかなりメリットだと思います。
まだまだ使いこなしているとは言い難いですが、早くその辺の運用上のメリットを感じたいところです。