RAGの基礎的な仕組み
RAG(Retrieval-Augmented Generation)システムは、LLM(Large Language Model)と呼ばれる大規模言語モデルと、Retrieval(文書検索モデル)を組み合わせた、質問応答(QA)を行うための自然言語処理(NLP)システムの一種です。その主な機能は、大量の情報源から必要な情報を取り出し、その情報に基づいて回答を生成することです。
毎日、私たちはインターネットを利用して無数の情報を調査し、情報を手に入れるためにWebページをクリックし、記事を読み、情報を収集しますが、その過程は時間がかかり、また情報を見つけ出す能力も個々のスキルに依存する形になっています。RAGを使うことで、機械学習モデルが大量の情報源から必要な情報を見つけ出し、その情報に基づいて答えを生成してくれるという体験が実現されます。
RAGシステムは大きく二つのステップで機能します。最初のステップである「Retrieval」ステップでは、入力されたクエリに基づいて、RAGシステムはナレッジベースから関連する文書を検索します。二つ目のステップである「Generation」ステップでは、選択された文書をベースにして最終的な回答を生成します。
このRAGシステムの登場により、LLMの強みである流暢な言葉で回答する能力に加え、LLMの弱点である間違った回答をしてしまう(ハルシネーションが起こる)可能性を回避し、知識をもとに正しい回答を行うことが可能になりました。
RAGのコア:ナレッジの検索と選択
RAGの鍵となる機能は、大量の情報から必要な情報を検索し選び出すことです。
このプロセスは、「情報の検索」と「選択」の2ステップで実現されます。まず「情報の検索」では、AIモデルは特定の特徴を持つクエリに基づいて情報を検索し、適切な候補をナレッジベースから取り出します。この取り出された情報は、次のステップである「選択」の中で評価されます。
「選択」ステップでは、取り出された候補情報が評価され、その中から最適な情報源が選ばれます。選択の中心となるのは特徴量に基づく類似度です。この類似度は、入力されたクエリと様々な情報源との間の類似度を評価します。
具体的には、情報源は多次元空間上の点として表され、その位置は情報源が持つ特徴量に基づいて決定されます。次に、各情報源と入力クエリの間の類似度が計算され、最も類似度の高い情報源が選ばれます。このプロセスは効率化されており、数千から数百万の情報源の中から瞬時に適切な情報を選択することが可能になっています。
▼RAGの仕組み図 出典:https://storialaw.jp/blog/9916

しかし、質問文との類似度で知識を引っ張ってくる仕組みについて、「回答に必要な知識=質問に似た知識」とは限らないと考えられるため、今後このナレッジ検索の技術は進化していくと考えられます。
未来の方向性: 知識グラフとRDF
具体的には、将来的には類似度に基づく関連知識の検索ではなく、知識グラフやRDF(Resource Description Framework)といったツールを活用し、情報の検索がより進化すると予想しています。
知識グラフとは、実体間の関連性をグラフ形式で示すことができるツールであり、RDFは情報を主語、述語、目的語の3つの要素で組み合わせて表現するシステムです。これらの手法が活用されると、より直感的で人間らしい検索と情報の抽出が可能になると考えられます。
▼知識グラフ概要 出典:https://keywordmap.jp/academy/knowledge-graph/
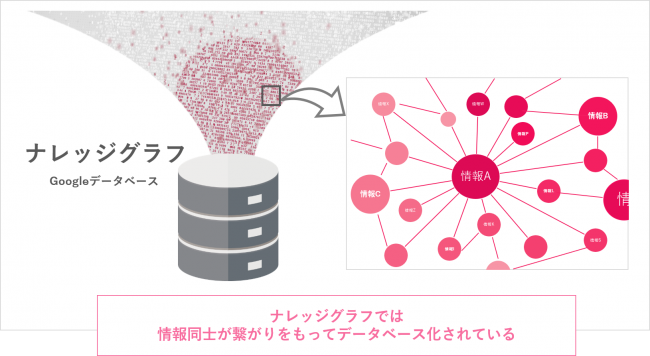
これは、単に特徴量の類似性による評価を越えて、意味的な関連性や情報の階層構造を利用して情報を抽出する能力をRAGにもたらす可能性があります。システムが自ら問いを解決するための文脈を理解し、どの情報が適切な知識として利用できるかを判断する方法を学ぶことが可能になるかもしれません。
これはあくまでも予想ですが、引き続き新しいアプローチと技術がRAGシステムにどのように統合され、どのように知識検索技術が進化していくのか、これからの見どころだと考えられます。