あるデータ系列の頻度を表すものとしてヒストグラム。
2変数の関係を表そうと思ったら散布図、3次元なら頑張って3Dで図示してグリグリ動的に動かせると楽しいです。
で、それ以上というか4次元以上は完璧に見通すのは常人には無理なので(汗)、ある程度情報量が落としてもいいので何か出せないか、という時のアイデアの1つに平行座標(parallel coordinates)があります。
散布図のように縦軸・横軸を直行させる代わりに、無理矢理同じ方向(=平行)に並べていく感じです。
library読み込み
from sklearn.datasets import load_iris
from pandas.tools.plotting import parallel_coordinates
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.style.use('ggplot')
ここでコケた場合は、pip installなりcondaあたりで必要なパッケージを入れておいて下さい。
parallel_coordinatesが今回のテーマです。
データ読み込み
data = load_iris()
df = pd.DataFrame(data.data, columns=data.feature_names)
この時点で中身を確認すると、、、
df.head()
|#|sepal length (cm)|sepal width (cm)|petal length (cm)|petal width (cm)|
|-----|----|----|----|----|----|
|0|5.1| 3.5|1.4|0.2|
|1|4.9| 3.0|1.4|0.2|
|2|4.7| 3.2|1.3|0.2|
|3|4.6| 3.1|1.5|0.2|
|4|5.0| 3.6|1.4|0.2|
マジメに表現しようとすると、4次元なので、直交座標では表現出来ません。
irisの名前をつける
irisにはお約束の名前をtarget_nameとして付加しておきましょう。
df['target_names'] = [data.target_names[i] for i in data.target]
df.head()
| # | sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target_names |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
、、となって右側のカラムにsetosaなどのtarget_nameカラムが追加されました。
表示
target_namesを凡例として平行座標表示:
plt.figure()
parallel_coordinates(df, 'target_names')
plt.show()
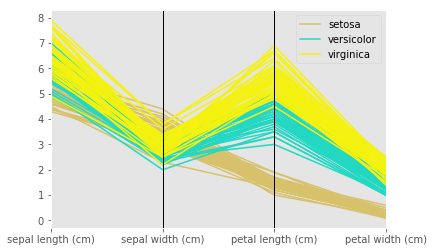
例えば、黄色のvirginicaを見てみると、sepal length(cm)が、他の2種類より全体的に大きく、sepal width(cm)は中くらい、、、などが視覚的にわかりますね。
勿論、きちんとデータ分析などに使う場合は雰囲気だけじゃなくて統計量を使って定量的に見ましょう(当然)。
次元数(=カラム数)は4つ使っていますが、連続量に関する大小関係を視覚的につかみたい場合には適していそうですね。
References
- parallel coordinates: