【はじめに】
- 仕事中にブログネタを思いつくことが時々あり、会社のPCをお借りしてテキストに起こすことがありました。
- 個人アドレスにはメールを送れないので、毎回プリントして帰宅後に自分のPCに転記するということをしています。
- 毎回この作業をすると思うとかなり面倒なので、Pythonを使ってテキストを抽出する方法を試してみました。
本記事の内容
- 準備
- PDFファイルからテキストを抽出してみた
- PDFファイルを画像として認識し、テキストを抽出してみた
【準備】
作業ディレクトリにテキスト抽出したいPDFファイルを配置する
- sample1.pdf

- sample2.pdf

【PDFファイルからテキストを抽出してみた】
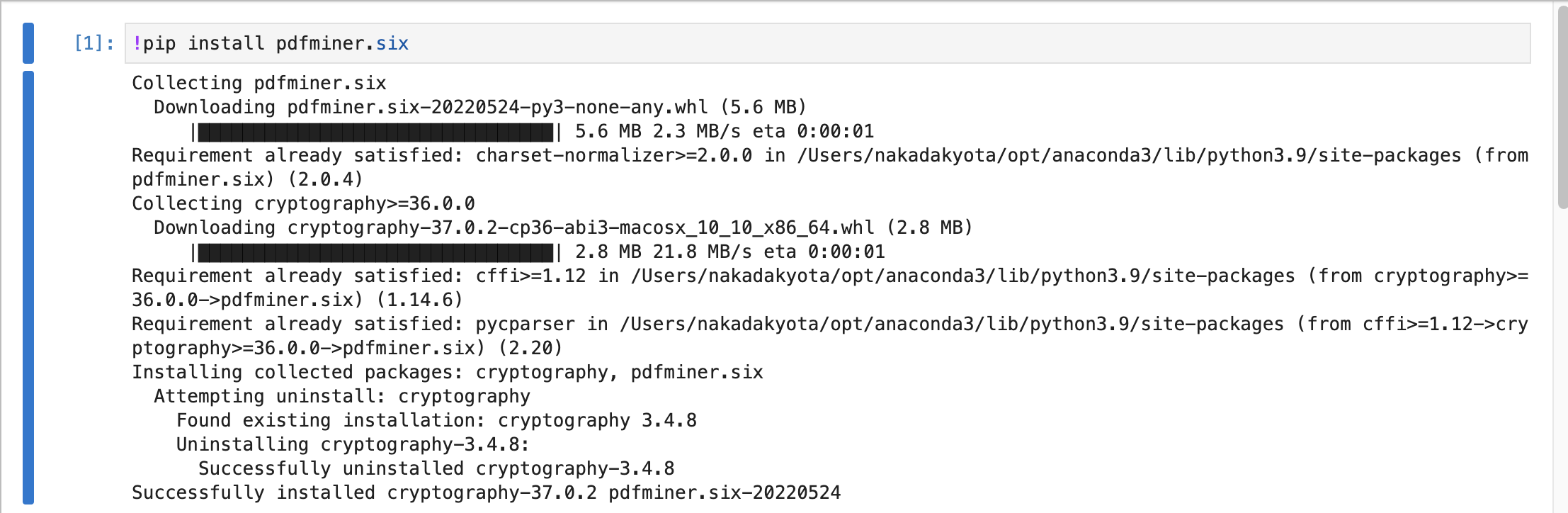
pdfminer.sixをインストール
pdfminer.sixはPDFファイルからテキスト情報を抽出する機能を有するPythonモジュールです。
!pip install pdfminer.six
ライブラリをインポート
import pdfminer
pdfminer.sixのGitHubから公開されているコード「pdf2txt.py」を作業ディレクトリに持ってくる
GitHubにサンプルコードが公開されているため、今回はそのまま使用したいと思います。 同じ名前でファイルを作成し、コードをコピーすればOKです。
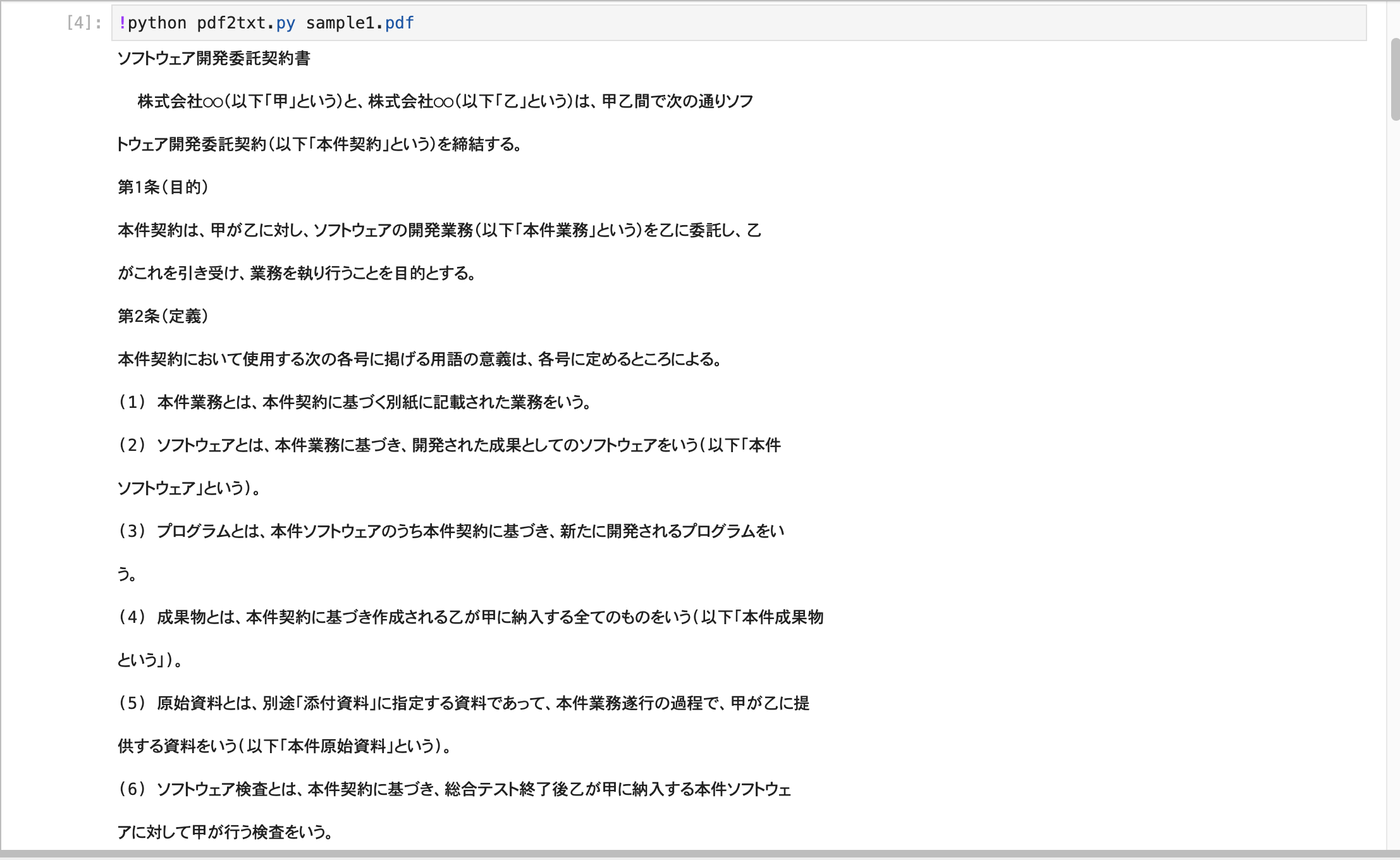
「pdf2txt.py」を実行して「sample1.pdf」のテキストを抽出する
!python pdf2txt.py sample1.pdf
「sample2.pdf」のテキストを抽出する
次のように、実行結果に何も表示されませんでした。 一度出力した資料をスキャンでPDFファイルにした場合は、より高度なOCR処理が必要みたいです。
ディレクトリとコード
今回のディレクトリ構成とコードをまとめるとこのような感じになります。
【PDFファイルを画像として認識し、テキストを抽出してみた】
pdfminer.sixではPDFファイルによっては抽出できないものもありましたので、今回はPDFとしてではなく、画像として認識し文字を抽出できるかどうか試していきたいと思います。PyOCRのインストール
「Pyocr」はPythonのOCRのライブラリで、Tesseract(OCRツール)を利用できます。 TesseractはGoogleが公開したOCRエンジンでGitから無料でダウンロードが可能で、Tesseractを利用することで画像に表示されている文字を抽出することが出来ます。!pip install pyocr

Tesseractのインストール
OCR engineである「Tesseract」をインストールします。!brew install tesseract

pdf2imageのインストール
PDFを画像ファイルに変換してくれるライブラリ「pdf2image」をインストールします。!pip install pdf2image

popplerのインストール
PDFドキュメントのレンダリングに利用されるライブラリ「poppler」をインストールします。!brew install poppler

「sample2.pdf」を画像ファイルに変換してからテキストを抽出する
from PIL import Image
import sys
import pyocr
import pyocr.builders
import pdf2image
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
The tools are returned in the recommended order of usage
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
Ex: Will use tool 'libtesseract'
pdfから画像オブジェクトに
images = pdf2image.convert_from_path("sample2.pdf", dpi=200, fmt='jpg')
lang = 'eng'
#lang = 'jpn'
画像オブジェクトからテキストに
for image in images:
txt = tool.image_to_string(
image,
lang=lang,
builder=pyocr.builders.TextBuilder()
)
print(txt)
Sample2.pdfを使用してみます。
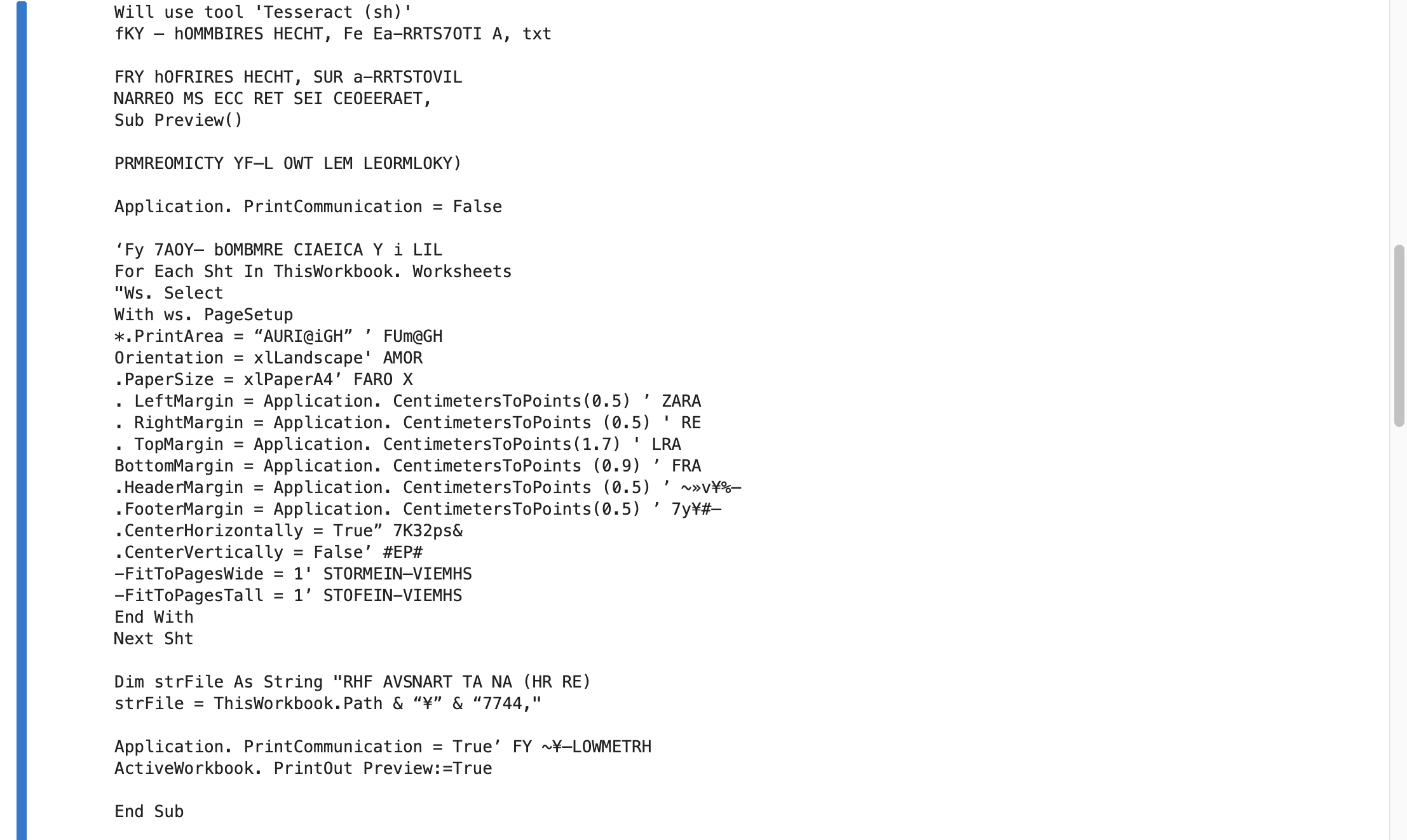


言語が「eng」なので日本語部分は文字化けしていますが、コードの部分はある程度は正しく読み込まれています。
lang = 'jpn'に変えて実行してみる



先ほどより正しく読み込まれている部分が増え、読みやすくなりました。
ディレクトリとコード
今回のディレクトリ構成とコードをまとめるとこのような感じになります。
【さいごに】
PDFファイルからテキストを抽出する方法を2つ試してみました。 特に、一度出力した資料をスキャンでPDFファイルにした場合は、スキャン精度によってテキスト抽出の精度も変わると思うので色々試してみる必要がありそうです。興味ある方は、是非試して見てください。