
この記事ではPythonを使って簡単な株価予測モデルを作成する方法を紹介します。
はるか昔にJavaやSQLなどでビジネスアプリケーション開発をしていた筆者が、機械学習をより具体的に学習したいという思いをきっかけに、6ヶ月前からAidemyの講座を通じてPythonを学び始めました。
この記事は講座の最終課題としてこれまでの私の学びを整理するためのものです。
同時に、これから機械学習に取り組んでみたい初心者の方々向けに、Pythonを活用した機械学習の大まかなながれを理解いただけるように構成してみました。
題材は「株価予測」モデルの構築で、具体的には米国Salesforce社(ティッカーシンボル: CRM)の株価を予測するモデルを目指します。モデルの学習においては、Salesforce社の株価以外にNYダウ、NASDAQ、S&P500の終値や相対力指数(RSI)も特徴量として組み入れることが有効かどうかについて考察します。
このPythonコードはGoogle Colab環境で実行可能です。Google Colabを使うことで、手軽にコードを実行し、結果を確認することができます。以下に、Google Colabの簡単なガイドを記載しますので、初めての方も安心して始められます!
目次
- 0. Google Colabの簡単ガイド
- 1. ライブラリのインポート
- 2. データの取得
- 3. RSIの計算
- 4. データの前処理
- 5. 相関の確認
- 6. 不要な列の削除
- 7. データの可視化
- 8. 特徴量とターゲットの設定
- 9. データの分割
- 10. モデルの訓練
- 11. 予測と評価
- 12. 結果の可視化
- 13. モデルの評価
- おわりに
0. Google Colabの簡単ガイド
Google Colabとは?
Google Colab(Google Colaboratory)は、Googleが提供する無料のJupyter Notebook環境です。Pythonコードをブラウザ上で実行でき、特にデータサイエンスや機械学習のプロジェクトに便利です。
Google Colabを使い始める手順
1. Googleアカウントにログイン:
Google Colabを利用するには、Googleアカウントが必要です。まだアカウントを持っていない場合は、Googleアカウントを作成してください。
2. Google Colabにアクセス:
ブラウザでGoogle Colabにアクセスします。
3. 新しいノートブックを作成:
Google Colabのホームページで「新しいノートブック」をクリックします。
4. ノートブックにコードを入力:
新しく作成されたノートブックに、記事中のPythonコードをコピー&ペーストします。
5. セルを実行:
コードセルの左側にある再生ボタンをクリックするか、Shift + Enterキーを押してセルを実行します。
これで、Google Colab上でコードを実行し、結果を確認することができます。
1. ライブラリのインポート
まずは、必要なライブラリをインポートします。これらのライブラリは、データの取得、前処理、可視化、モデル作成に必要です。
株価等のデータをYahoo! Financeから取得するためのyfinanceライブラリもインポートしています。
import pandas as pd
import yfinance as yf
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
import warnings
warnings.filterwarnings("ignore")
from sklearn.model_selection import train_test_split
2. データの取得
Yahoo! FinanceからSalesforce、NYダウ、NASDAQ、S&P500の株価データを取得します。
データの取得期間は任意ですが、今回は2010年1月1日から2024年7月31日分までを取得します。
# 定義する株式シンボル
stock_symbol = "CRM"
dow_symbol = "^DJI"
nasdaq_symbol = "^IXIC"
sp500_symbol = "^GSPC"
# Yahoo Financeから過去のデータをダウンロード
stock_data = yf.download(stock_symbol, start='2010-01-01', end='2024-07-31')
dow_data = yf.download(dow_symbol, start='2010-01-01', end='2024-07-31')
nasdaq_data = yf.download(nasdaq_symbol, start='2010-01-01', end='2024-07-31')
sp500_data = yf.download(sp500_symbol, start='2010-01-01', end='2024-07-31')
3. RSIの計算
株価を評価する指標のひとつにRSI(相対力指数)というものがあります。RSIは、株価の買われ過ぎや売られ過ぎを判断するためのテクニカル指標です。
個人的にこの指標が株価予想に役立つ(特徴量として組み入れることに意味がある)のではないかと思っていたのでまずはRSI値を計算し、データセットに組み込んでいます。
RSI値の計算ロジックの詳細はこの記事では割愛しますので興味ある方は別途リサーチしてみてください。
# RSIの計算
def calculate_RSI(data, window):
delta = data['Close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=window).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=window).mean()
RS = gain / loss
RSI = 100 - (100 / (1 + RS))
return RSI
# 14日間のRSIを計算してデータに追加
stock_data['RSI'] = calculate_RSI(stock_data, 14)
4. データの前処理
各データの終値を取り出し、株価データとマージします。また、欠損値を削除します。
# 各データの終値を取り出し
stock_data['Dow_Close'] = dow_data['Close']
stock_data['Nasdaq_Close'] = nasdaq_data['Close']
stock_data['SP500_Close'] = sp500_data['Close']
# 欠損値の確認と処理
stock_data.dropna(inplace=True)
5. 相関の確認
データの相関を確認し、視覚化します。これにより、特徴量どうしの相関を確認できます。
# データの相関を確認
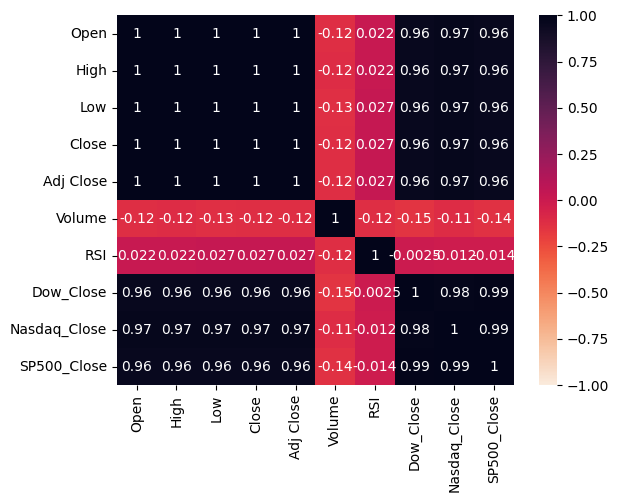
sns.heatmap(stock_data.corr(), vmin=-1, vmax=1, annot=True, cmap="rocket_r")
plt.show()
生成されたヒートマップを見たところ、Volume(取引量)とRSIの2つは、目的変数であるClose(終値)との相関が低いことがわかります。よって特徴量としては除外するのが適切であると判断できます。
(RSIを株価予想に組み込めるのでは?という私の個人的な思惑は統計的に否定されました)
6. 不要な列の削除
データセットから不要な列(特徴量)を削除します。
Adj CloseはCloseとほぼ値が同じなので除外します。
Volume(取引量)とRSIも終値との相関が低いので除外します。
# 不要な列を削除
stock_data.drop(['Adj Close', 'Volume', 'RSI'], axis=1, inplace=True)
7. データの可視化
データをプロットして視覚的に確認します。
# データのプロット
stock_data.plot()
plt.show()
8. 特徴量とターゲットの設定
モデルの訓練に使用する特徴量(X)とターゲット(Y)を設定します。
# 特徴量とターゲットを設定
x = stock_data[['Open', 'High', 'Low', 'Dow_Close', 'Nasdaq_Close', 'SP500_Close']].values
y = stock_data[['Close']].values
9. データの分割
データを訓練用とテスト用に分割します。テスト用データの割合は20% (test_size=0.2)としました。
# データを分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
10. モデルの訓練
線形回帰モデルを訓練します。
今回は比較的シンプルで解釈しやすい線形回帰モデルを採用してみました。
線形回帰モデルは説明変数(特徴量)と目的変数の間の線形関係をモデル化するために使用され、各特徴量が目的変数にどのような影響を与えるかを理解できます。
線形回帰モデルは計算量が少なくてすみ、モデルの訓練が非常に高速に行われるのも特長です。
株価予測には線形回帰以外にもLSTM(Long Short-Term Memory) モデルが利用されているようです。
# 線形回帰モデルのインスタンス化
model = LinearRegression()
# モデルの訓練
model.fit(x_train, y_train)
11. 予測と評価
テストデータを用いて予測し、実際の値と比較します。
# テストデータで予測
prediction = model.predict(x_test)
# 実際の値と予測値を比較
comparison = pd.DataFrame({'Actual': y_test.flatten(), 'Predicted': prediction.flatten()})
print(comparison.head(20))
12. 結果の可視化
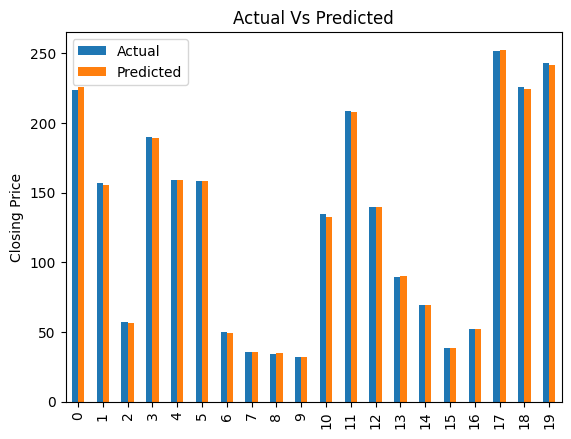
上記の予測結果(実際の値との比較)を視覚化してみましょう。
実際の株価と、予測された株価の誤差が極めて小さいことが確認できます。
# 結果の可視化
cGraph = comparison.head(20)
cGraph.plot(kind='bar')
plt.title('Actual Vs Predicted')
plt.ylabel('Closing Price')
plt.show()
13. モデルの評価
最後にモデルの性能を定量的に評価しましょう。
モデルスコア (model.score())は0 - 1間の値を出力しますが、1に近いほど優秀なモデルといえます。
今回構築したモデルのスコアは0.9998177731998098なのでかなり優秀なモデルを構築できたと言えます。
# モデルのスコアリング
model_score = model.score(x_test, y_test)
print(f'Model Score: {model_score}')
Model Score: 0.9998177731998098
おわりに
この記事ではPythonライブラリと公開データ(Yahoo! Finance)を利用して株価予測モデルを構築する手順を整理しました。
株価の予測は今回とりあげたような特徴量以外にも様々な変数やイベント(病気の蔓延や紛争など)があるので完璧なモデルを構築することは難しいと思いますが、ここで説明したような手法、考え方を取り入れることである程度は予測が可能と考えます。
最も重要なのは、株価(目的変数)に影響を与えそうな様々な変数(過去の株価、NYダウ、NASDAQ、S&P500、RSI含むそれ以外のテクニカル指標。為替、労働人口推移、金利、紛争有無、疫病有無、などなど)が有効な特徴量になりうるのかどうかをしっかり見極めたうえで学習モデルを構築することだと個人的には学びました。
最後になりますが、一投資家として株価予測は引き続き興味深い領域なので、今後は別のモデル(LSTMなど)やそれ以外の有力な特徴量なども組み込んだうえで予測モデルの構築にチャレンジしてみようと思います。
この記事に関するフィードバックがあればコメント欄でお知らせください。