ちょうど二年前のアドベントカレンダーでこんな記事を書いていたようです。
現状はどうしてるのか当時を振り返りながらまとめようかなと思います ![]()
vendoringについて
依存管理は、depを使ってます。(depが出るまではglide使ってました)
2年前にくらべると色々と便利になって普通に使っていけるようになりました。
当時はまだGo1.5とかでしたね...
主に使ってるライブラリ
とりあえず以下使ってますという感じ
- goa
- gorm
詳細はこちら
https://qiita.com/kyokomi/items/dcd8384a0a042d72d22d
パッケージ構成とか
もともとDDD本に出てくるレイヤードアーキテクチャを意識してたんですが、いつの間にかオニオンアーキテクチャ風になっていたようです。
現時点では、この形が自分の中ではベストかなと思ってます。
├── application
├── domain
│ ├── file
│ ├── friendship
│ └── user
├── infrastructure
│ ├── adapter
│ │ ├── auth
│ │ ├── aws
│ │ ├── cache
│ │ ├── firebase
│ │ └── rdbms
│ └── repository
└── presentation
├── controller
├── middleware
└── view
| パッケージ名 | 対応するオニオンアーキテクチャでの名称 | 説明 |
|---|---|---|
| presentation/controller | User Interface | goaでgenerateしたcontroller(httpのHandler)。ここからapplication Serviceを呼び出す |
| presentation/middleware | requestHeaderのチェックとかいわゆるmiddleware | |
| presentation/view | User Interface | goaで定義したresponseへmappingを行って書き込む |
| application | Application Service | domain/xxxxのRepositoryインターフェース経由でドメインオブジェクトの取得や更新を行います |
| domain | Domain Model | ビジネスロジック。特定のinfrastructureやviewに依存しない純粋な仕様を定義 |
| infrastructure/adapter | Infrastructureから外に出ていく部分のadapter | RDBとかRedisなどのCache、外部のAPIなどとやり取りする |
| infrastructure/repository | Infrastructure | domain/xxxxのRepositoryインターフェースを実装したstruct |
呼び出しの流れ
図にするとこんな感じの呼び出しの流れになります。(気がむいたら清書します ![]() )
)
friendShip(フレンド関連)の機能を例にしてます。(字が汚い...)
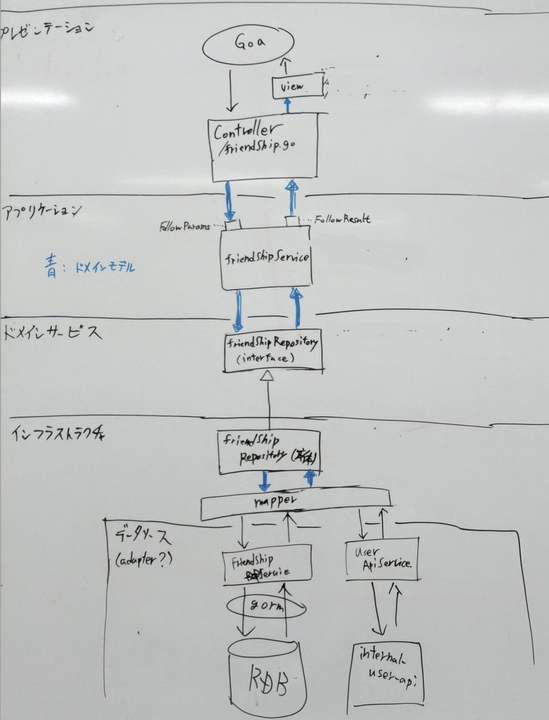
※図は雰囲気で書いた図なのでUMLとかみたいなちゃんとしたやつではないです
矢印は基本的にデータの流れですが、インフラストラクチャのfriendShipRepositoryからドメインサービスのfriendShipRepositoryのインターフェースに向かってる矢印だけ継承を示しています
ポイント
- domain/xxxxのRepositoryがinterfaceになることで、中身の実装を意識しないで呼び出せるようになってる(依存関係の逆転)
- RDBでは、テーブルが2つあるので2つobjectを渡す〜みたいなことがないようにRepositoryのI/Fの設計をしていくのが大事
- goaでgenerateするControllerはApplicationServiceを呼び出して結果をviewに渡すだけに務めることでほぼコードを見なくていい
- RDBの設計や過去の負債などの都合で変なデータ含まれるけど〜みたいなのは、Repositoryのインターフェースを実装したとこに定義するmapperで吸収する(腐敗防止層的な)
mapperについて
各層でのデータのやり取りで変換するコードをガリガリ書いちゃうと可読性が下がるので適宜mapperを書いている(こんなやつ)
globalなメソッドにすると利用範囲が曖昧になるので空のstruct作ってメソッド生やして整理してます。(別パッケージにするまでもない系)
type friendShipConvert struct {
}
var friendShipConverter = friendShipConvert{}
func (cnv friendShipConvert) toFollowTables(userID user.Identifier, followUsers friendship.Users) []*rdbms.UserFollowTable {
result := make([]*rdbms.UserFollowTable, len(followUsers))
for i := range followUsers {
result[i] = &rdbms.UserFollowTable{
UserID: userID.String(),
FollowUserID: followUsers[i].ID.String(),
}
}
return result
}
func (cnv friendShipConvert) toBlockTables(userID user.Identifier, blockUsers friendship.Users) []*rdbms.UserBlockTable {
result := make([]*rdbms.UserBlockTable, len(blockUsers))
for i := range blockUsers {
result[i] = &rdbms.UserBlockTable{
UserID: userID.String(),
BlockUserID: blockUsers[i].ID.String(),
}
}
return result
}
社内共通ライブラリ
普通に ClusterVR/go みたいなリポジトリを作ってそれをdepでvendoringしてます。
念のため rdbms/v1 みたいなバージョン切り替えできるディレクトリ掘ってpackage名を rdbms にするとかやってるんですが、v2が作られる目処がないのでいまのところ本当に必要だったのかは謎です ![]()
├── goa
│ └── middleware
│ └── v1
├── kvs
│ └── v1
├── mqtt
│ └── v1
├── rdbms
│ └── v1
└── sentry
└── v1
あえて不満をあげるなら
各レイヤー間でのデータのmappingで毎回for文とか筋肉で書くのがちょっと面倒なくらいです ![]()
![]()
おまけ
CIについて
CircleCI -> Wercker -> CircleCI 2.0という感じの歴史を辿ってます。
Werckerは高いわりに結構とまるのでストレスが結構溜まってたんですが、CircleCI 2.0でDockerイメージが使えるようになっていい感じになり移行しました。
今は平和です ![]()
ローカル開発
docker-composeで必要infrastructureやマイクロサービス化したinternal-apiなどをまとめて起動して動作確認する感じでやってます。
ずっと起動してるとPCのバッテリーが急速に減るのが悩み...
所感
ずっと書こう書こうと思って書いてなかったので、2年越しにようやくというお気持ち...
実装時に考えるのはdomain/xxxxをどういう粒度でつくるべきか?とかがメインであとは単純作業なのでサクサクと実装が進んで良い感じです。
一旦あまり考えずにパパッと作って違和感がでてきたら整理してリファクタリングという流れをやっていていい感じにワークしてます。
以上、来年?はどうなってるか楽しみですね。