Python学習の一環で、スクレイピングに今回トライしました。実際の不動産サイトにアクセスし、実践形式で学ぶためです。今回自分のメモ用として記載しています。
環境: Window10
参考情報:YouTube はやたす / Pythonチャンネル
今回Suumoから不動産情報をスクレイピングし、CSVファイルにまとめるまでトライしてみました。
スクレイピングする上で先ずやらなければならないのが、スクレイピングすることが禁止になっているサイトがあるので要注意です。
SUUMOはスクレイピングはスクレイピング禁止の該当事項ありませんでしたので大丈夫でした。
ただ、高負荷をかけてしまうと利用規約にあたる「(6) 本サイトの運営を妨げる行為」に該当しますので注意したいと思います。
スクレイピングの流れ
①RequestsでHTMLを取得する
②取得したHTMLを解析する(BeautifulSoup)
③自分が欲しい情報をwebの「検証」から確認し、取得する
では先ずは、ライブラリーのインポートから
from time import sleep
from bs4 import BeautifulSoup
import requests
SUUMOのurlより変数urlに代入。RequestsにアクセスしてHTMLをBeautifulSoupで解析する
urlの後ろに?page={]を付けてますが、あとからformat()使ってURLを作成。ページ毎に変更になる際、forループでページを回すようにする為です。
url = 'https://suumo.jp/chintai/tokyo/sc_shinjuku/?page={}'
target_url = url.format(1)
r = requests.get(target_url)
soup = BeautifulSoup(r.text)
soupから情報を抽出する。
情報がどのような形で格納されているか確認
Webページで右クリック「検証」を開き、HTMLの構造を閲覧する。
HTMLを確認すると、それぞれの賃貸情報はdivタグの中のclass="cassetteitem~"に格納されていることが分かる。
全ての各賃貸情報を取り、その後でそれぞれのブロックから情報を抽出。

すべてのタグ情報をクラス付きで指定法は、前回やったfind_all(タグ名, class_='')で取得。
contents = soup.find_all('div',class_= 'cassetteitem')
ここで1ページ当たり何件の情報が格納されているか調べてみる。要素数確認する為、len関数を使う。
len(contents)
content=contents[0]
次に最初のブロックに入っている賃貸情報から、欲しい情報を取得します。
ほしい情報を細かく設定
物件情報
物件名
住所
アクセス
築年数
部屋情報
物件の回数
物件の賃料/管理費
物件の敷金・礼金
物件の間取り・面積
物件・建物情報を変数detail に格納するには、検証で確認すると、このブロックに入っています。指定タグが見つかったので、content_findで取得し、detailに格納。

```python
detail = content.find('div', class_='cassetteitem_content')
各部屋の情報をは、変数tableにこのようにあり、tableタグにあるので、指定タグ記載し、content_findで取得し、tableに格納。
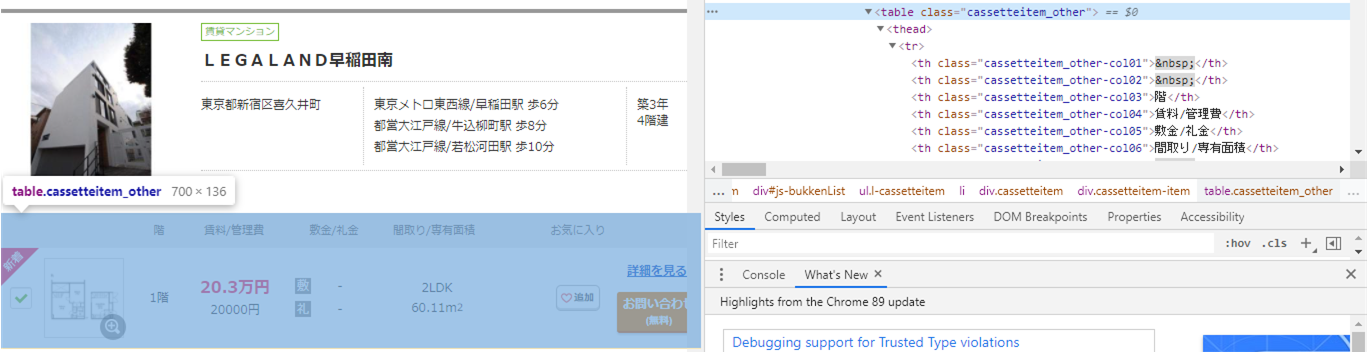
table = content.find('table', class_='cassetteitem_other')
以上のように物件名、住所、アクセス情報、築年数を上記にように取得していく。
変数titleに、物件名を格納する
title = detail.find('div', class_='cassetteitem_content-title').text
変数addressに住所を格納する
address = detail.find('li', class_='cassetteitem_detail-col1').text
変数accessにアクセス情報を格納する
access = detail.find('li', class_='cassetteitem_detail-col2').text
変数ageに築年数を格納する
age = detail.find('li', class_='cassetteitem_detail-col3').text
取得結果を格納できたら、実際に中身を確認する。
title, address, access,age
下記で情報取得確認できました。
('リーガランド早稲田南',
'東京都新宿区喜久井町',
'\n東京メトロ東西線/早稲田駅 歩6分\n都営大江戸線/牛込柳町駅 歩10分\n東京メトロ東西線/神楽坂駅 歩15分\n',
'\n築3年\n4階建\n')
次は各部屋の情報を取得していきます。
取得する情報は下記になります。trタグに入っていることからタグ指定して、情報を取得。

物件の階数
物件の賃料/管理費
物件の敷金・礼金
物件の間取り・面積
# 変数tableからすべてのtrタグを取得して変数tr_tagsに格納
tr_tags = table.find_all('tr', class_='js-cassette_link')
# tr_tagsの中から最初の一つだけtr_tagに格納
tr_tag = tr_tags[0]
tr_tagから取得した情報からアンパックで4つの情報に格納。取得したいのは、階数:floor, 賃料:price, 敷金・礼金:first_fee, 間取り・面積:capacity。
取得したいのは、2番目から5番目までの階数、賃料、敷金、面積の4つで[2:6]と指定。

# 変数floor,price,first_fee, capacityに4つの情報を格納
floor, price, first_fee, capacity = tr_tag.find_all('td')[2:6]
floor, price, first_fee, capacityの中身を表す。
(<td>
1階</td>, <td>
<ul>
<li><span class="cassetteitem_price cassetteitem_price--rent"><span class="cassetteitem_other-emphasis ui-text--bold">20.3万円</span></span></li>
<li><span class="cassetteitem_price cassetteitem_price--administration">20000円</span></li>
</ul>
</td>, <td>
<ul>
<li><span class="cassetteitem_price cassetteitem_price--deposit">-</span></li>
<li><span class="cassetteitem_price cassetteitem_price--gratuity">-</span></li>
</ul>
</td>, <td>
<ul>
<li><span class="cassetteitem_madori">2LDK</span></li>
<li><span class="cassetteitem_menseki">60.11m<sup>2</sup></span></li>
</ul>
</td>)
price : 「賃料」と「管理費」
first_fee : 「敷金」と「礼金」
capacity : 「間取り」と「専有面積」
これらの複数入っている要素を分けたいので、さらにfind_all()を使って情報の抽出を更に細かく取得します。

賃料は、priceのliタグ指定して細かく取得していく。他の情報も同じように取得。
# 変数feeとmanagement_feeに賃料と管理費格納する
fee, management_fee = price.find_all('li')
# 変数depositとgratuityに、敷金と礼金を格納する
deposit, gratuity = first_fee.find_all('li')
# 変数madoriとmensekiに間取りと面積を格納する
madori, menseki = capacity.find_all('li')
解析した結果を辞書型として格納する。後でcsvファイルにする際、取扱いやすいから。
d = {
'title':title,
'address':address,
'access':access,
'age':age,
'floor':floor.text,
'fee':fee.text,
'management_fee':management_fee.text,
'deposit':deposit.text,
'gratuity':gratuity.text,
'madori':madori.text,
'menseki':menseki.text
}
細かな設定はこれでok. 後は1ページ目の情報を全て取得する。
# 変数d_listに空のリスト作成する
d_list = []
# すべての物件情報20件を取得する
contents = soup.find_all('div',class_= 'cassetteitem')
# 各物件情報をループで取得する
for content in contents:
#物件情報と部屋情報を取得しておく
detail = content.find('div', class_='cassetteitem_content')
table = content.find('table', class_='cassetteitem_other')
#物件情報から必要な情報を取得する
title = detail.find('div', class_='cassetteitem_content-title').text
address = detail.find('li', class_='cassetteitem_detail-col1').text
access = detail.find('li', class_='cassetteitem_detail-col2').text
age = detail.find('li', class_='cassetteitem_detail-col3').text
tr_tags = table.find_all('tr', class_='js-cassette_link')
for tr_tag in tr_tags:
floor, price, first_fee, capacity = tr_tag.find_all('td')[2:6]
fee, management_fee = price.find_all('li')
deposit, gratuity = first_fee.find_all('li')
madori, menseki = capacity.find_all('li')
d = {
'title':title,
'address':address,
'access':access,
'age':age,
'floor':floor.text,
'fee':fee.text,
'management_fee':management_fee.text,
'deposit':deposit.text,
'gratuity':gratuity.text,
'madori':madori.text,
'menseki':menseki.text
}
# 取得した辞書をd_listに格納する
d_list.append(d)
なお、普通にprint()を使うと、辞書が見辛い形になってしまいますが、体裁を綺麗にしたままにしたいのでpprintを使います。
from pprint import pprint
pprint(d_list[0])
print()
pprint(d_list[1])
{'access': '\n東京メトロ東西線/早稲田駅 歩6分\n都営大江戸線/牛込柳町駅 歩10分\n東京メトロ東西線/神楽坂駅 歩15分\n',
'address': '東京都新宿区喜久井町',
'age': '\n築3年\n4階建\n',
'deposit': <li><span class="cassetteitem_price cassetteitem_price--deposit">-</span></li>,
'fee': <li><span class="cassetteitem_price cassetteitem_price--rent"><span class="cassetteitem_other-emphasis ui-text--bold">20.3万円</span></span></li>,
'floor': <td>
1階</td>,
'gratuity': <li><span class="cassetteitem_price cassetteitem_price--gratuity">-</span></li>,
'madori': <li><span class="cassetteitem_madori">2LDK</span></li>,
'management_fee': <li><span class="cassetteitem_price cassetteitem_price--administration">20000円</span></li>,
'menseki': <li><span class="cassetteitem_menseki">60.11m<sup>2</sup></span></li>,
'title': 'リーガランド早稲田南'}
{'access': '\nJR中央線/大久保駅 歩5分\nJR山手線/新大久保駅 歩8分\n東京メトロ丸ノ内線/西新宿駅 歩15分\n',
'address': '東京都新宿区北新宿3',
'age': '\n築4年\n2階建\n',
'deposit': <li><span class="cassetteitem_price cassetteitem_price--deposit">13.2万円</span></li>,
'fee': <li><span class="cassetteitem_price cassetteitem_price--rent"><span class="cassetteitem_other-emphasis ui-text--bold">13.2万円</span></span></li>,
'floor': <td>
1階</td>,
'gratuity': <li><span class="cassetteitem_price cassetteitem_price--gratuity">13.2万円</span></li>,
'madori': <li><span class="cassetteitem_madori">2LDK</span></li>,
'management_fee': <li><span class="cassetteitem_price cassetteitem_price--administration">3000円</span></li>,
'menseki': <li><span class="cassetteitem_menseki">60.11m<sup>2</sup></span></li>,
'title': 'ソレイユ'}