使った統計分析手法
- Q-Qプロット
- シャピロウィルク検定
- マンホイットニーのU検定
参考にしたコラム
著者はドラフトに関連付けて、人材を補充する上で各ポジション別年齢別の人数から各チームの穴を分析していました。そこから着想を得て、チーム内の年齢構成は成績と関連があるのかということを検証をしてみました。
なんとなくですが、年齢構成のバランスがいいというのはチームにプラスの影響を及ぼしそうな気がします。例えば、「ベテランと若手のバランス」という言葉をよく耳にしますが、それはそういうことだと思います。
ですので、以下の仮説を考えてみました。
- Bクラスの平均年齢はAクラスに比べて若すぎる、もしくは年取りすぎなのではないか?≒AクラスとBクラスで平均年齢に差はあるか。
ということで、ニアイコールの方を検証していきます。ニアイコールにした理由は、最後の結果を見ればわかります。
データソースはNPBの公式ホームページです。
http://npb.jp/
データの範囲は二リーグ制が始まった1950〜2017です。
データは一軍登録のあった選手に限定されます。
まずは、全期間における一軍登録選手の満年齢の分布の確認をします。
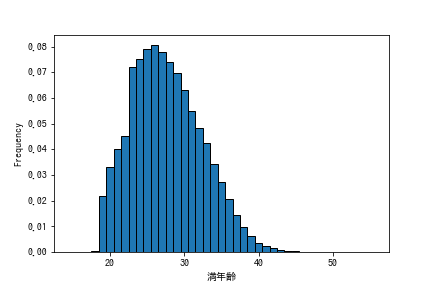
23歳の選手で一軍登録の選手がぐっと増えていますが、これは大学からドラフトで入った選手が即戦力として登録されたということを表しているのだと思います。26歳がピークになっていて、以降は選手数は減っていくようです。
これをどう読み取るかというのは難しいところですが、このあたりから選別(解雇)が本格的に始まっていくのかなと思います。だとすれば、ここまでの年齢で十分に稼いでいるということは考えにくいので、本当に厳しい世界なんだなーと思います。
なお、あくまで登録のあった選手ということで一軍に一試合でも出場した記録があれば一人としてカウントしています。
チーム年齢構成について調べて行きますが、「年齢バランスが良い」と考えたときそれはあくまで「主力級の選手で」という暗黙の前提があると思うので、その前提に従って分析をしていきます。
主力選手のですが、投手の場合は20、80の法則で決めました。投球回数がチーム内で上位20%、もしくは、登板回数が上位20%としました。
野手についても同じ法則でやりたかったのですが、代打の切り札とか守備要因とか代走要因とかそういった人たちを取りこぼしたくなかったので、出場試合数が20試合以上としました。20試合は分布を見て決めました。
全選手と主力選手の年来分布を比較したのが下の図です。
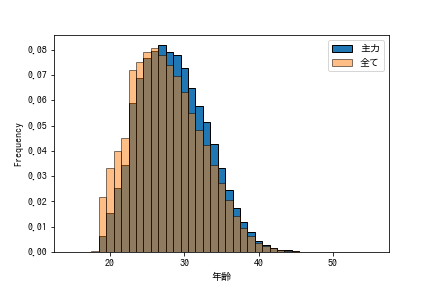
主力の分布は全体の分布を右にシフトさせたような感じになります。最瀕値は27歳でした。20代前半については主力と全選手で頻度に差が出ていることがわかります。
次に主力とバックアップ(全体から主力を除いた集合)を比較した結果です。
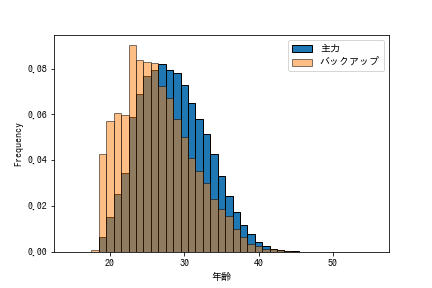
差がより顕著に出ています。バックアップの最瀕値は23歳ですね。主力選手が怪我などで欠場している間に一軍から若手が上がってきて、主力選手の復帰とともに二軍に戻るということはよく見かけますが、そういったことを反映できていそうです。
というわけで、粗いですが青の分布を主力の選手の集合として扱っても良さそうですね。それでは、検証に入っていきたいと思います。
主力選手に限定したチームごとの平均年齢の分布(AクラスとBクラス)を見ます。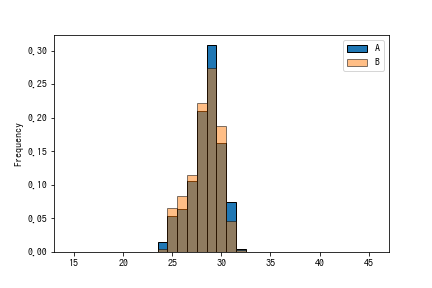
ほとんど変わらないということが視覚的にわかりました。この分布を見て、平均年齢に違いがあるというのはちょっと無理がありそうだということはわかりますが、一応練習ということで検定したいとと思います。
平均年齢の分布は正規分布はしていないかなと思うので、正規性の検定からしていきたいと思います。
まずはQ-Qプロットで視覚的な確認をします。Q-Qプロットは理論上の分位点と実際のデータの分位点を散布図としたグラフですね。データが100個あれば1%ずつ100個の分位点が得られます。一方、正規分布の%点を使えば、理論上の分位点が得られます。理論上の分位点と実際のデータの分位点を求め、両者を比較することでデータが正規分布に近いかどうかを視覚的に判断できます。
import scipy.stats
import matplotlib.pyplot as plt
# AにはAクラスの平均年齢データ、BはBクラスの平均データ
fig, ax = plt.subplots(1, 2, figsize=(12,4))
x = scipy.stats.probplot(A, plot=ax[0])
x = scipy.stats.probplot(B, plot=ax[1])
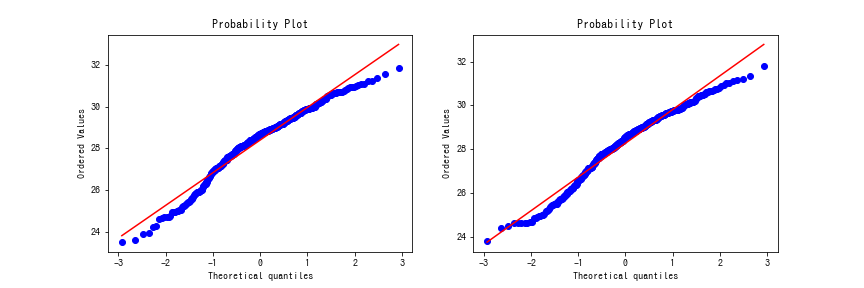
どうやら正規分布には従っていないようです。しつこいですが、正規性を検定してみましょう。シャピロウィルク検定を使います。シャピロウィルク検定の帰無仮説は標本が正規分布に従うです。なので、棄却されればそのデータは正規分布に従っていないと結論付けられます。
import scipy.stats
# 返り値は統計検定量とP値
p_value_A = scipy.stats.shapiro(A)[1]
p_value_B = scipy.stats.shapiro(B)[1]
Aクラスの満年齢の平均値に対してシャピロウィルク検定を実施したらp値は2.2187512271898413e-08でした
Bクラスの満年齢の平均値に対してシャピロウィルク検定を実施したらp値は1.1780491604440613e-07でした
検定の結果、帰無仮説は棄却されました。
うるおぼえですが、棄却されないからといって正規性があると積極的には言えないそうです。ただ、これを持って正規分布に従っている考えるのは妥当であるとか、なんか大人な言い回しをしている記述を見たこともあります。Q-Qプロットも一緒に見ておけば、非難されるようなことはないかなと個人的には思います。
というわけで、ここまで長かったですが2群間の比較としては、ノンパラメットリックなマンホイットニーのU検定を使うのが妥当ということがわかりました。
ちなみに正規性が確認できれば、二群間のt検定を使うほうが検出力が高くて良いです。
import scipy.stats
scipy.stats.mannwhitneyu(A, B, use_continuity=True, alternative='tow-sided')
MannwhitneyuResult(statistic=87797.5, pvalue=0.1746589762040579)
ということで5%水準で帰無仮説を棄却することはできず、当初立てた仮説
- Bクラスの平均年齢はAクラスに比べて若すぎる、もしくは年取りすぎなのではないか?≒AクラスとBクラスで平均年齢に差はあるか。
は支持されないことが確認できました。
「何も言えねー」という結果になりました。まぁ、シーズンは毎年あるわけで平均年齢が若すぎたり、高齢化したりというのが起こらないように頑張っている人がいるということでしょうか。主力選手の相次ぐ怪我などで一時的にそういった自体は訪れるかもしれませんが、すぐに手が打たれると考えるのが自然でしょう。次回は、野手と投手に分けて同様の分析をしてみたいと思います。