kaggleやデータ分析の入門といったら
kaggleやデータ分析に挑戦したい人がまずやることといえば、タイタニックチュートリアルでしょう。ありがたいことに、検索すると良質な日本語記事がたくさん出てきます。それら記事を読むうちに、データ分析の基礎がわかってくるはずです。複数の方法を見ることで、共通の手法や独自の手法を意識できます。タイタニックチュートリアルに様々な角度からアプローチすることで、初心者はより深い理解が得られるはずです。
そこで、この記事では、タイタニックチュートリアルの複数の解き方を比較・整理します。
この記事の対象読者
・データ分析の基礎を知りたい
・Kaggleに挑戦してみたい
・機械学習の基礎は分かってきたから、使ってみたい
こんな希望を持つ方々向けの記事になっています。新しい分野へ入門するときは、入門書を3冊読めと言われます。いくつかの視点から情報を入れることは、バランスの良い入門になるはずです。
実際のコードなどは、各記事にアクセスして確認してみてください。
データの確認
まずは、どんなデータを分析することになるのか、確認をしてみましょう。
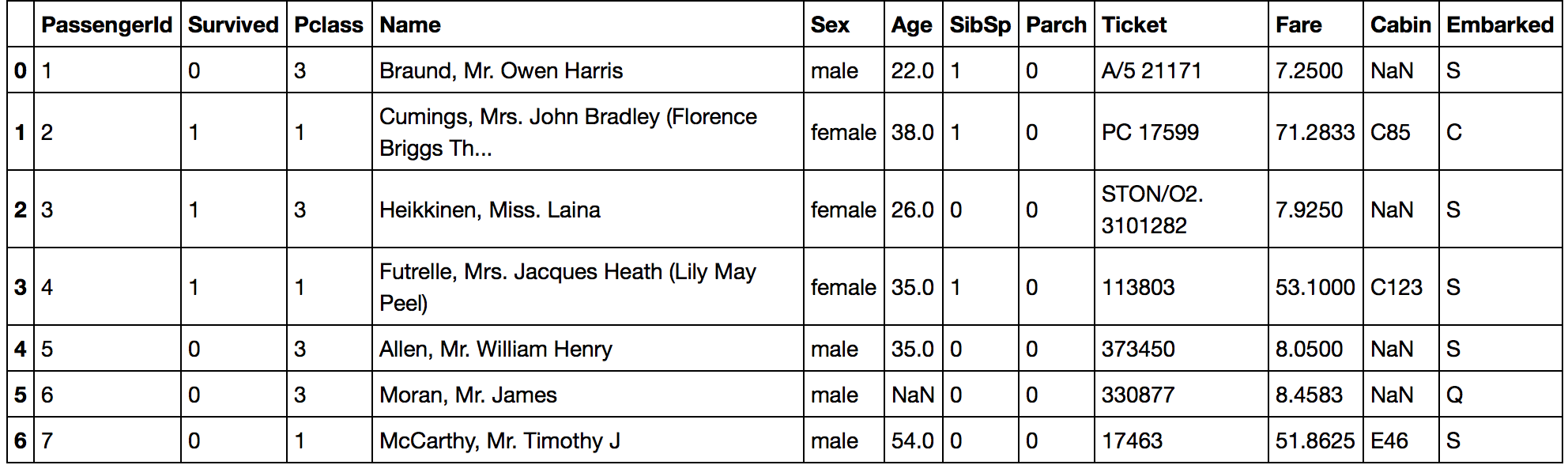
データを見ると、次のことがわかります。
- 数字ではなく文字列のデータがある
- データがかけている場所がある
精度が高い分析をするために、これらをどう処理していくかが重要になります。いくつかのチュートリアル記事を見ながら、
- 欠損値の扱い
- 文字列データの扱い
- 特徴量の扱い
- どんな機械学習アルゴリズムを使うか
などを比較しながら、勉強していきましょう。
1. 【Kaggle初心者入門編】タイタニック号で生き残るのは誰?
【Kaggle初心者入門編】タイタニック号で生き残るのは誰?
欠損値
- Ageには中央値を
- Embarkedには、一番多いSを
- Cabinは不使用
文字列から数値へ
- Sex 0、1
- Embarked 0、1、2
モデル作成
- "Pclass","Age","Sex","Fare", "SibSp", "Parch", “Embarked”を特徴量とし、決定木を使用。
2. Kaggleのtitanic問題で上位10%に入るまでのデータ解析と所感
Kaggleのtitanic問題で上位10%に入るまでのデータ解析と所感
欠損値
- 生存が、性別、年齢と相関が高いことに注目。敬称”mr”、”master”、”miss”、”mrs”と年齢との関係を使い、欠けている年齢を推定する。
モデル作成
- SVM
3. KaggleチュートリアルTitanicで上位3%以内に入るには。(0.82297)
KaggleチュートリアルTitanicで上位3%以内に入るには。(0.82297)
欠損値
- Ageには平均値を
- Embarkedには平均を
- Cabinは不使用
文字列から数値へ
- Name 敬称によって分類
- Ticket 先頭の文字、文字列の長さで分類
- Cabin 先頭の文字で分類
新しい特徴量の追加
- FamilySize 何人家族か
- IsAlone 一人かどうか
モデル作成
- ランダムフォレスト グリッドサーチによるパラメーターの最適化あり
まとめ
- 欠損値の扱い
- 文字列データの扱い
- 特徴量の扱い
- どんな機械学習アルゴリズムを使うか
これら注目ポイントを確認できたでしょうか?この流れに触れることが、データ分析への一歩になるはずです。