この記事はBrainPad Advent Calendar2021 17日目の記事となります。
初めまして。デジタルソリューションサービス部の村上です。
今年の7月からデータサイエンティストになった駆け出しデータサイエンティストです。
私は趣味でコントラバスという楽器を弾いているので、コントラバス×機械学習で何かやろうと思います。
はじめに
みなさんはコントラバスという楽器をご存じでしょうか。オーケストラの端っこにいる一番大きい弦楽器がコントラバスです。写真は僕のコントラバスです。1畳より少し大きい。

こんなに大きいと運ぶのも弾くのも一苦労です。少しでも楽をしたい、少しでも動きたくないと考えるのがコントラバス・シンキングです。
コントラバスを弾く際に一番最初に考えなければならないことは「ボウイング」と「運指」です。「ボウイング」は弓の動かす方向(右手)、「運指」は指の動かし方(左手)です。
この運指が非常に重要で、楽器が大きいため効率的な運指で最小限に動くということが求められます。しかし、運指の組み合わせはなかなか多いため、特に初心者には難しく、ある程度コントラバスをやっていても運指を決めるのはめんどくさいです。
そこでコントラバス・シンキングです。楽をしたい。このめんどくさい運指を機械学習を使って推定しようというのが今回の試みです。(ここから本題です)
全体の流れ
推定は以下の流れで行います。
- 楽譜のpdfをMusicXMLに変換する
- MusicXMLを学習データ用の形式に変換する
- 学習データを作成する
- 前処理
- 予測モデルの作成・評価
1. 楽譜のpdfをMusicXMLに変換する
MusicXMLとは
楽譜をXMLのように構造化して表現する形式。musescoreなどの作曲ツールも内部的にはこれを用いているっぽい。公式リファレンスは[こちら]
(https://www.w3.org/2021/06/musicxml40/musicxml-reference/element-tree/)。
今回必要なデータとしては音程と拍くらいなので詳細は後ほど記載します。
Audiverisを使ってpdfをMusicXMLに変換する
画像データから文字認識する技術はOCR(Optical Character Recognition)といって割と有名ですが、楽譜の画像データを認識する技術のことをOMR(Optical Music Recognition)というらしいです。今回はAudiverisというOMRツールを使って楽譜のpdfからMusicXMLに変換してみます。
ツールのインストールはこちらの記事を参考にさせてもらいました。
公式ドキュメントはこちら。
みんな大好きブラームスの悲劇的序曲をAudiverisを使って変換してみます。
ツール上でファイルを開き、赤丸の実行ボタンを押すだけで変換ができる。めちゃくちゃ簡単。
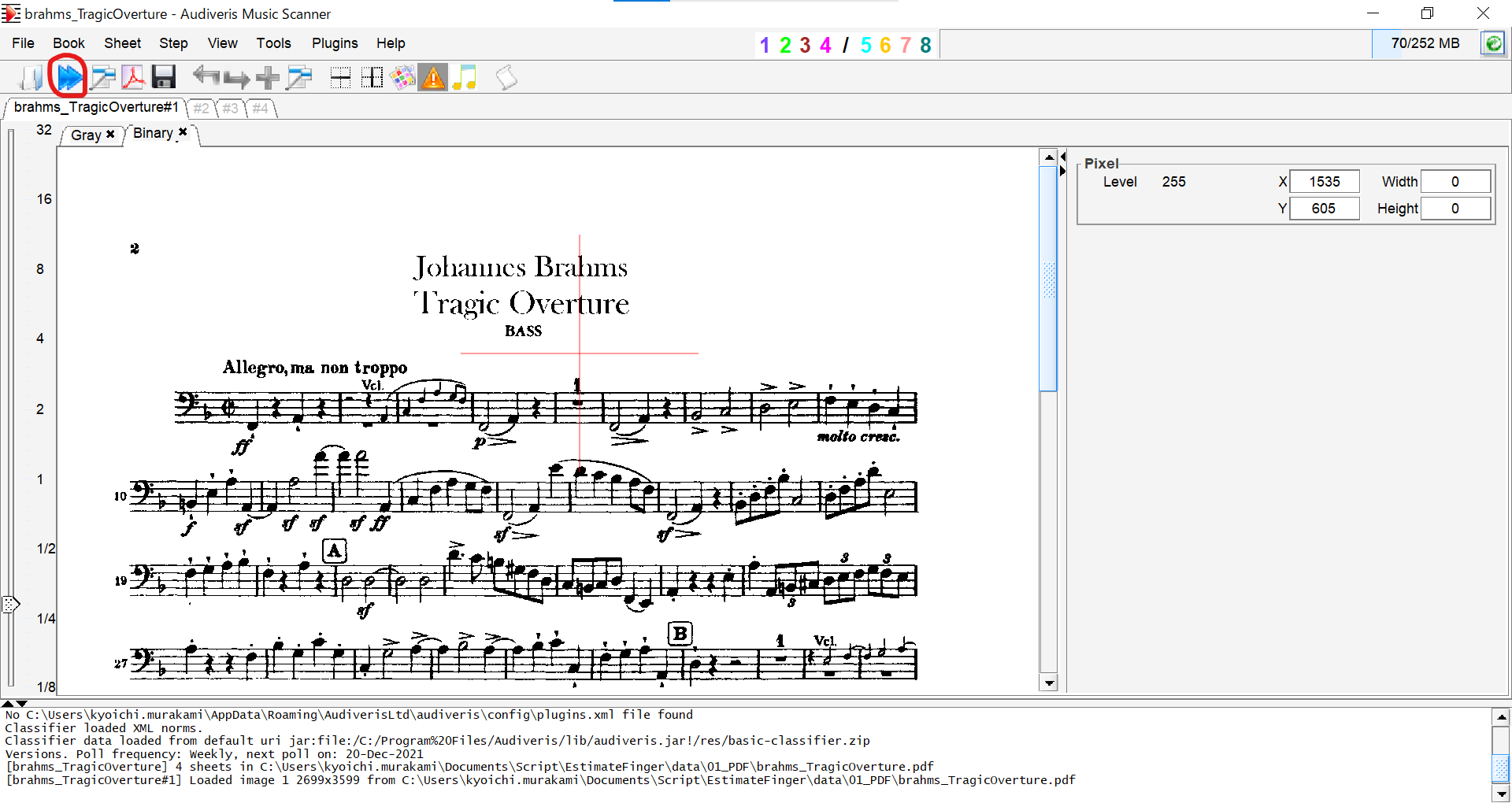
変換すると認識された音符が緑色に変化する。下の画像だと豆譜を実音だと誤認識したり、赤く変化している部分は8分音符を4分音符に誤認識しています。音符の削除はデリートキー、修正は画像右のShapeをドラッグ&ドロップで行えます。
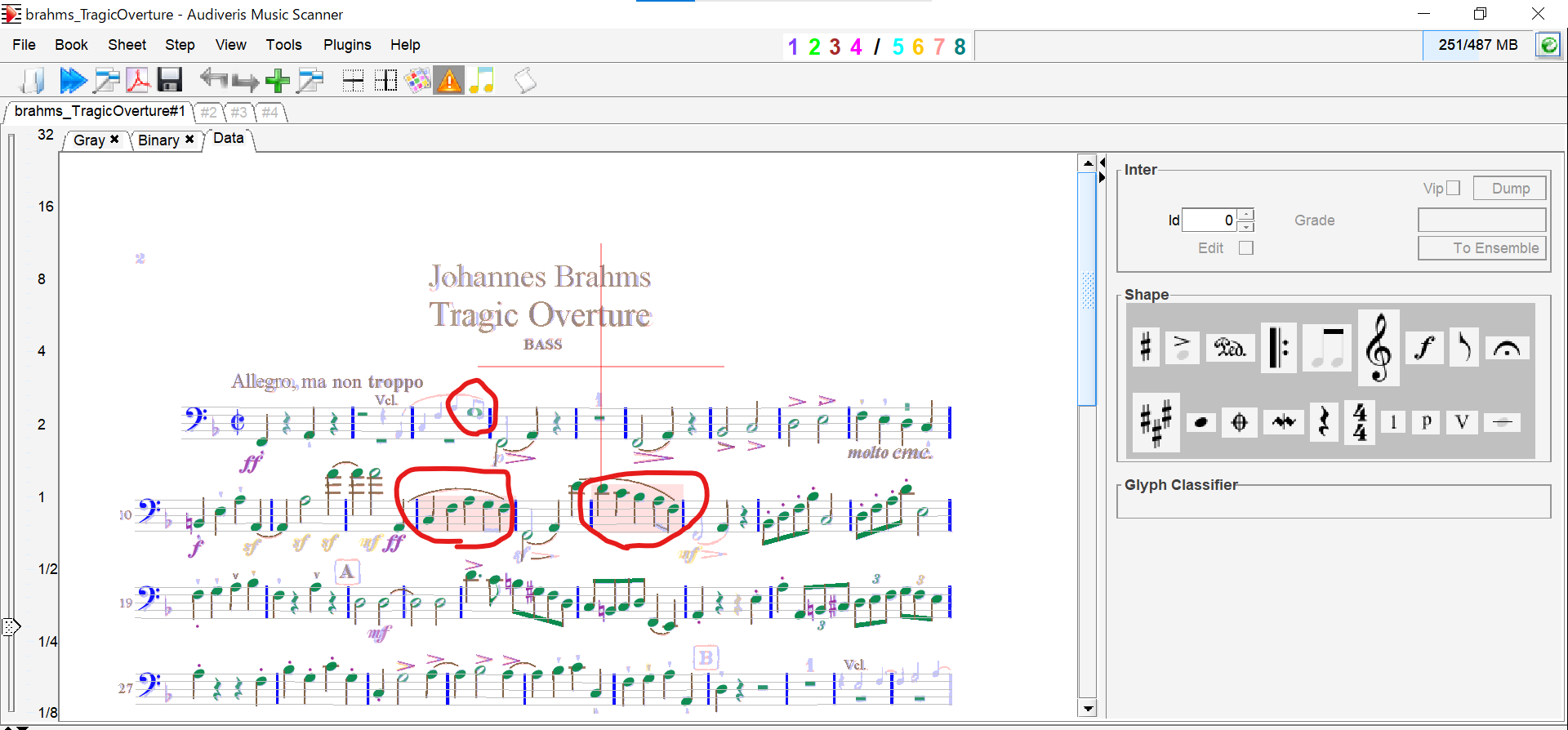
修正も思ったほど多くなく認識精度は良さげ。修正がすべて終わったらExport Bookで拡張子.mxlとして保存します。
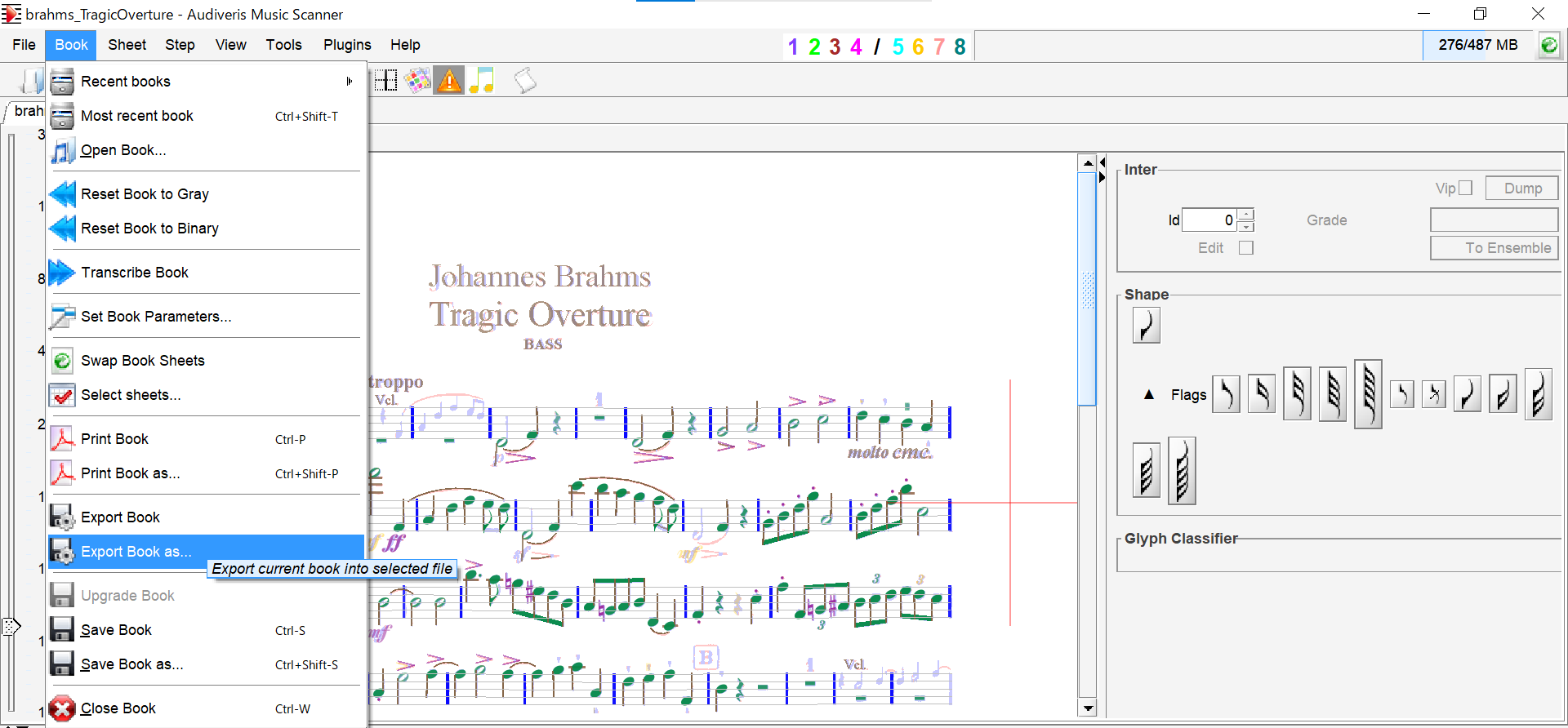
さて、これで楽譜のpdfをMusicXML形式に変換することができました。
続いて学習データ作成用に取得したMusicXMLから音程・拍などの必要な情報を取得します。
2. MusicXMLを学習データ用の形式に変換する
このフローでは、MusicXMLファイルを学習データとして活用するためcsv形式に変換していきます。
MusicXMLのパーサーはmusic21というpython用のライブラリを用います。
公式リファレンスはこちら。
今回は、音程・休符・拍(長さ)の情報を取得するため下記コードを実装しました。
import music21 as m21
import pandas as pd
# 選択したMXLファイル読み込み
score_name = "brahms_AcademicFestivalOverture"
read_file = score_name + ".mxl"
try:
piece = m21.converter.parse(read_file)
#初期状態をrestとする
list_pitch = ["rest"]
list_duration = [4]
#音またはrestをlist_noteに、長さをlist_durationに格納する
for n in piece.flat.notesAndRests:
if type(n) == m21.note.Note:
list_pitch.append(str(n.pitch))
list_duration.append(str(n.duration.quarterLength))
elif type(n) == m21.note.Rest:
list_pitch.append(str(n.name))
list_duration.append(str(n.duration.quarterLength))
else:
pass
#データフレームに変換する
df_score = pd.DataFrame({"pitch":list_pitch, "duration":list_duration})
#csvとして出力する
df_score.to_csv(score_name + ".csv", header=True, index=False)
except ZeroDivisionError:
print('Zero Division Error')
なぜかZeroDivisionErrorで実行できない場合があったが、基本的には問題なく変換できました。(原因分かる方いれば教えてください・・・)
変換結果の例は以下のようになります。
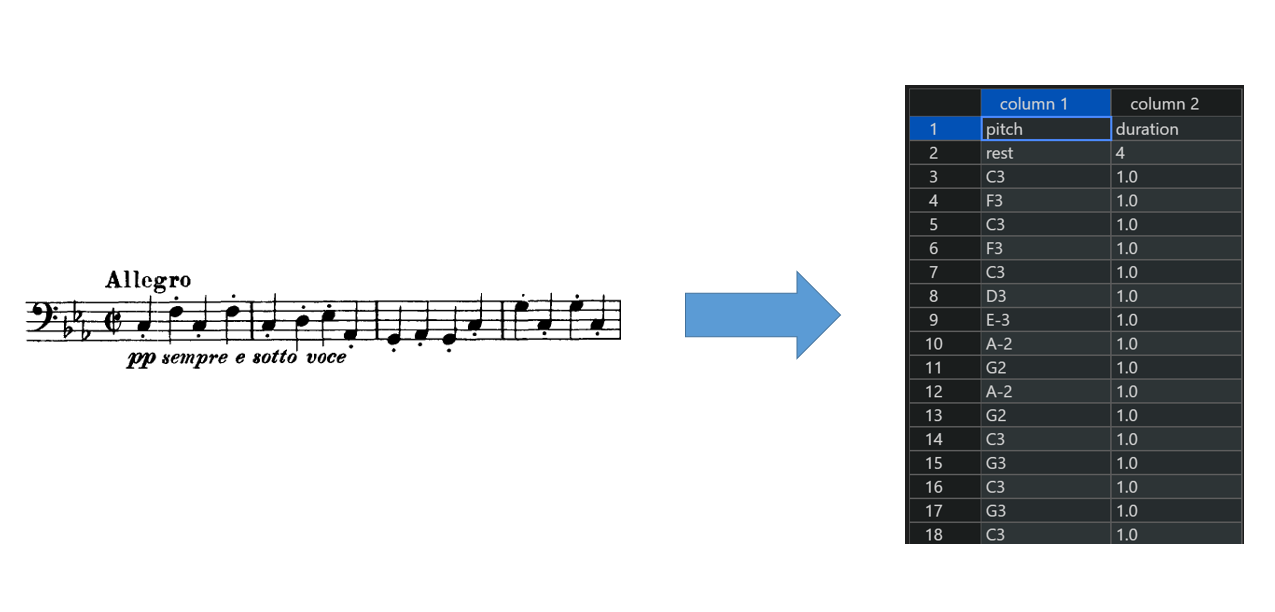
pitch列に音程または休符、duration列に拍の長さが入ります。(初期状態とするため最初の行に4拍分の休符を入れている)
pitchは音の名前+高さで表現され、例の最初のドの音はC3となります。例えば1オクターブ高いドの音はC4となります。また、シャープは#、フラットは-を付けて表現されます。
ざっと見たところ、多少シャープやフラットの音間違えはあるがかなり正確に認識できていました。(ちなみにド:C、レ:D、ミ:E、ファ:F、ソ:G、ラ:A、シ:Bと対応しています)
ついでに悲劇的序曲の音の分布を可視化してみました。左から音を低い順に並べています。
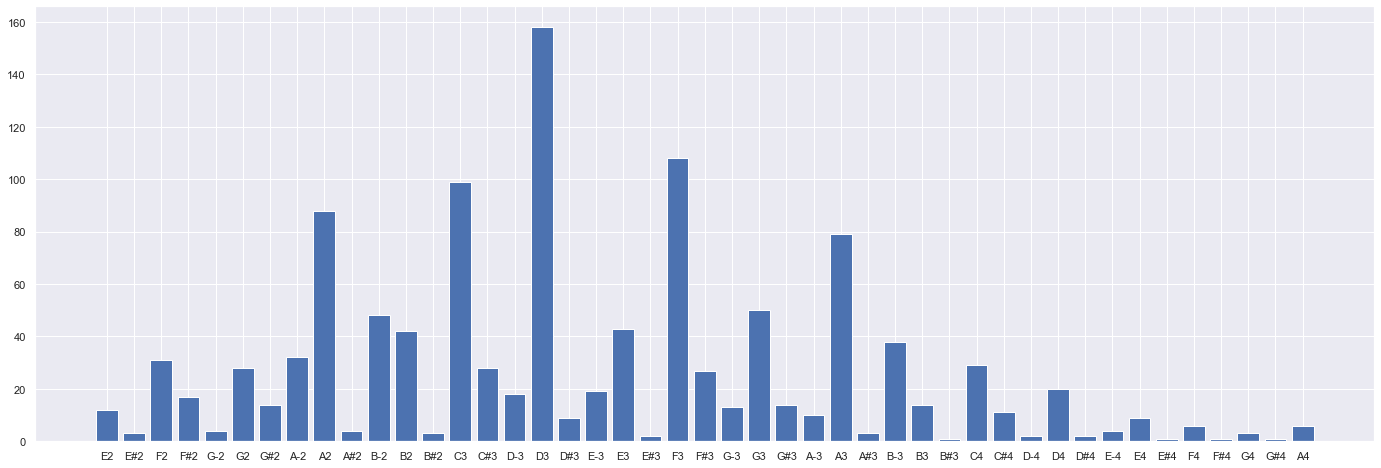
D3音が一番多く出現していますが、この音は開放弦なので押さえなくても音が出るためコントラバス的には嬉しい音です。また、A2も比較的多く出現しています。これも開放弦で弾けるため嬉しい。ブラームスさん、ありがとう。
3. 学習データを作成する
機械学習を使ってコントラバスの運指を推定するためには、学習するためのデータが必要となります。つまり、先ほど作成したcsvファイルの音1つ1つに正解の運指を付けていかなければならなりません。
コントラバスの運指を構成する要素は次の3つです。
1. どの弦で弾くか
2. どのポジションで弾くか
3. どの指で弾くか
それぞれ簡単に説明します。
1. どの弦で弾くか
コントラバスには全部で4本の弦が張ってあり、低い方から「E, A, D, G」の音に調弦します。今回は「E, A, D, G」を「1, 2, 3, 4」とラベリングします。
(ちなみに5弦コントラバスもあります)
2. どのポジションで弾くか
コントラバスはギターのようにフレットがないため、左手の位置がポジションとして決まっており、各ポジションで弦を押さえることで異なる音を出します。実は適当に弾いているわけではないんですね。
ポジションは低い方から「ハーフポジション, 第1ポジション, 第2ポジション, 第2と第3の中間ポジション, 第3ポジション, 第3と第4の中間ポジション, 第4ポジション, 第5ポジション, 第5と第6の中間ポジション, 第6ポジション, 第6と第7の中間ポジション, 第7ポジション」が存在します。
中間ポジションとは・・・?考えてはいけません。決まっているものは仕方ありません。
今回はポジションをそれぞれ「0.5, 1, 2, 2.5, 3, 3.5, 4, 5, 5.5, 6, 6.5, 7」とします。
もっと上のポジションも存在しますが基本的なオーケストラの曲ではここまで使えれば十分です。
3. どの指で弾くか
指番号は「人差し指が1, 中指が2, 薬指が3, 小指が4」と決まっています。また、開放弦(押さえないで出る音)は0と表記します。
今回は指番号を「0, 1, 2, 3, 4」とします。
親指を使うこともありますが今回は考えないようにします。
さて、そうすると例えば赤丸Cの音を出すために考えられる組み合わせは下記6つとなります。
(弦, ポジション, 指番号) = (1, 3.5, 4), (1, 4, 2), (1, 5, 1), (2, 0.5, 4), (2, 1, 2), (2, 2, 1)

つまり楽譜に記載された音に対して、(弦, ポジション, 指番号)のどの組み合わせを選ぶかという問題を解けば良いことになります。
今回は、学習データとしてブラームスの悲劇的序曲と大学祝典序曲の2曲について自分の指番号を付けました。
データ数としては1995個と若干少ない気もしますが勘弁してください。
4. 前処理
予測モデル作成の前に少しだけ前処理を行います。
楽譜には「異名同音」が存在します。例えば下の2つは違う表記ですが同じ音です。

運指を決める際に大事なのは何の音が出るかなので、異名同音はどちらかに統一します。
音を統一したところで、学習データではどのような運指を使っているのかを確認してみます。
下記ヒートマップは、各音に対して各運指の出現回数を可視化した図です。縦に上から音を低い順に並べ、横に(弦, ポジション, 指番号)を並べています。
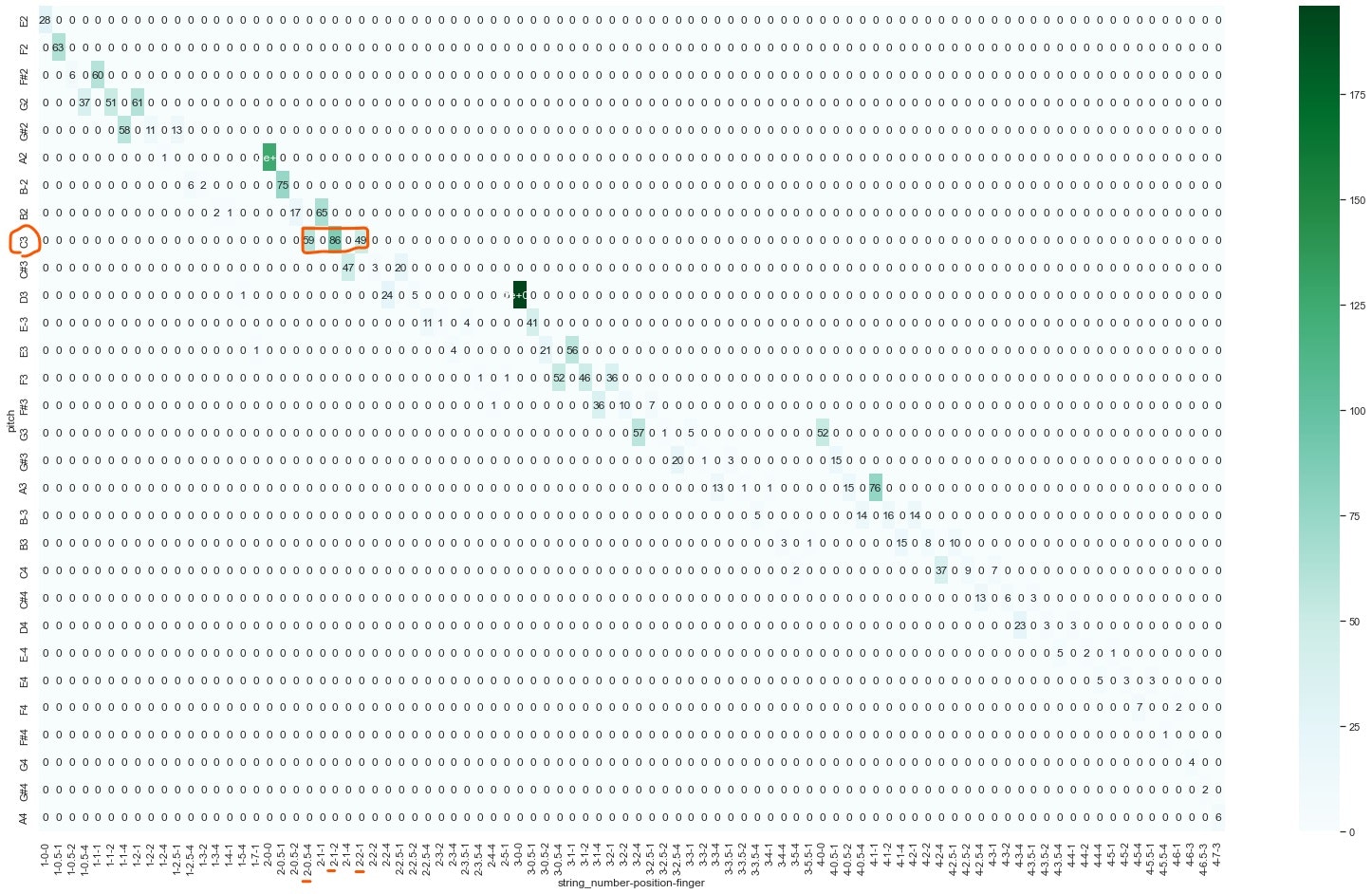
例えば、先ほど例に出したC3の音だと、(2, 0.5, 4)の組は59回、(2, 1, 2)の組は86回、(2, 2, 1)の組は49回出現しています。
C3の音に対して、考えられる組は6つでしたが実際にはこの3組をよく使っているということが確認できます。
こうすると自分の癖のようなものが見えてきて面白いですね。
6. 予測モデル作成
いよいよ予測モデルを作成していきます。
ベンチマークモデルとして、単純に各音で一番発生率が高い運指を採用した場合の正解率を用います。例えば、C3の音だと(2, 1, 2)が86回と一番多く出現しているためこれを当てはめます。
ベンチマークモデルの正解率は約49%でした。
これを超える予測モデルを作りたいですね。
楽譜は一種の時系列データと考えることができ、運指は前の状態の影響を大きく受けます。
今回は時系列データを表現できるニューラルネットワークとしてRNN(Recurrent Neural Network)を使ってみました。
入力は楽譜、出力は運指となるようにモデルを作成します。
楽譜、運指はともにカテゴリ変数なので今回はそれぞれダミー変数に変換してベクトルっぽく表現することにしました。運指についても同様の処理を行います。
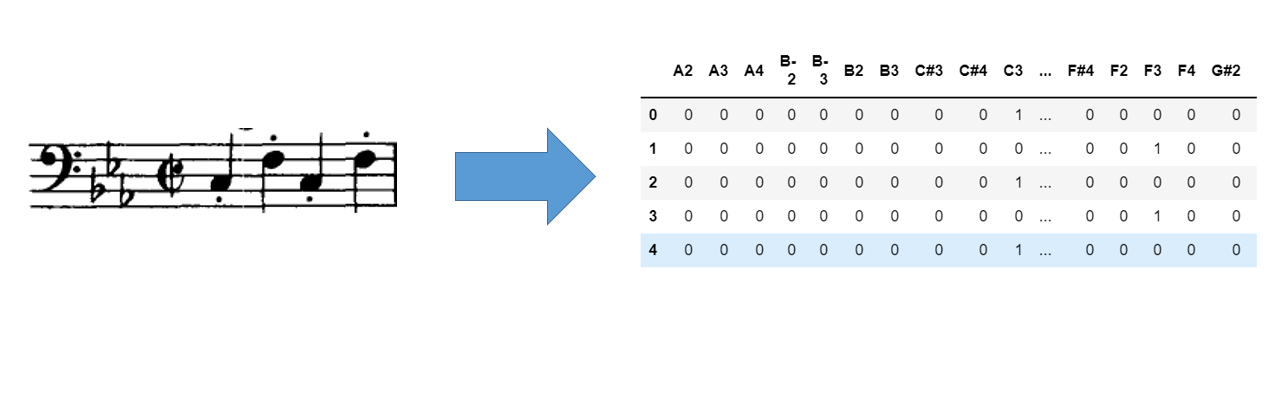
kerasのRNNライブラリを使って予測モデルを作成します。
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 学習させる
batch_size = 128
# 音の種類
input_dim = len(vec_pitch.columns)
units = 16
# string-position-fingerのベクトル
output_size = len(vec_spf.columns)
def build_model():
lstm_layer = keras.layers.LSTM(units, input_shape=(None, input_dim), return_sequences=True)
model = keras.models.Sequential(
[
lstm_layer,
keras.layers.BatchNormalization(),
keras.layers.Dense(output_size),
keras.layers.Activation('relu')
]
)
return model
# モデル作成
model = build_model()
model.compile(
loss='categorical_crossentropy',
optimizer="sgd",
metrics=["accuracy"],
)
model.fit(
X_train, y_train, validation_data=(X_test, y_test), batch_size=batch_size, epochs=1
)
predict = model.predict(X_test)
これでブラームスの悲劇的序曲、大学祝典序曲の運指を学習したモデルが作成できました。
ブラームスの交響曲第1番の最終ページに対して、また自分の運指を付けたのでこのデータに対して予測を行ってみます。
出力は下記のようになります。
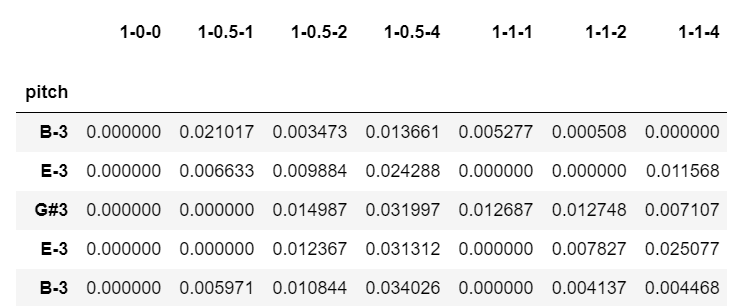
これをそのまま使おうとするのはちょっと無理があるので、今回は少し手を加えます。
上述したように、各音に対して考えられる運指の組み合わせは多くても7通りほどなので、各音で考えられる運指のうち、一番値が大きい予測値を採用することにします。
結果としてRNNでの正解率は35%でした。
苦労した割にはなんだかなあ・・・という結果です。
ためしに予測した運指で弾いてみましたが無駄にバタバタ動くだけで、隣で弾く人に怒られるかもしれません。
精度を向上させるために、たとえば指や移弦の移動距離で重みづけするなどしても良いかもしれません。
というかここまで書いて気づいたのですが拍の長さと休符の情報を入れるのを忘れていました。まあ、それはまた次回やってみようと思います。
まとめ
今回は機械学習を使ってコントラバスの運指を推定してみました。
個人的にはmusicXML, OMR, music21などこれまで知らなかった音楽関係の知識やツールを活用できて楽しくできました。
RNNも今回初めて使ってみましたがまだまだ理解が足りないのでもっと勉強して活用できるようになりたいですね。
また、楽器の指番号の推定は研究分野としてもあるようで、隠れマルコフモデルや最適化を使って予測するというアプローチのようです。
https://archives.ismir.net/ismir2021/paper/000013.pdf
https://orsj.org/wp-content/corsj/or53-1/or53_1_39.pdf
まだまだまだ改善の余地はありそうですので、コツコツやってみようと思います。
それでは、ここまでお付き合いいただきありがとうございました。
良いお年を!