はじめに
機械学習などのために大量のツイートが欲しいと思ったとき、通常はTwitter APIを使用して収集するかと思います。収集の作業自体はあまり本質的な作業でないにも関わらず、エラー処理やRate Limitへの対応、収集したツイートの管理方法など考えることが多く、個人的にはやや億劫に感じる部分でした。
そこで本記事では、
- 収集にLogstashのTwitterプラグインを使用
- データ管理にElasticsearchを使用
- Dockerを使用して簡単に環境構築
によって手軽にツイートを収集する環境を構築します。
構成
本記事では少ない設定ファイルでツイート収集環境を構築したいので、Logstashの設定ファイルのみ作成します。
本当はElasticsearchで日本語を扱うために形態素解析のプラグインを使用するべきだと思いますが、最終的には任意のプログラミング言語で処理することを考えているため本記事では割愛します。
ディレクトリ構成
前述の通り、docker-compose.ymlファイルとLogstashのログファイルのみです。
$ tree .
.
├── docker-compose.yml
└── logstash
├── config
│ ├── logstash.yml
│ └── pipelines.yml
└── pipeline
└── twitter.conf
DockerComposeファイル
今回はLogstash, Elasticsearch, Kibanaの構成です。
Elasticsearchはsingle-nodeで動かしており、どのコンテナも公式イメージを使用しています。
Elasticsearchで形態素解析プラグインを使用する場合には、別途Dockerfileを書く必要があるかと思います。
また、今回はKibanaからデータを確認するためElasticsearchのポートを開けていませんが、ホストOSのプログラムからアクセスする場合には9200と9300を開けると良いようです。
参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html
version: '3.7'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.10.1
environment:
- discovery.type=single-node
volumes:
- elasticsearch_data:/usr/share/elasticsearch/data
kibana:
image: docker.elastic.co/kibana/kibana:7.10.1
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
ports:
- 5601:5601
depends_on:
- elasticsearch
logstash:
image: docker.elastic.co/logstash/logstash:7.10.1
volumes:
- ./logstash/pipeline/:/usr/share/logstash/pipeline/
- ./logstash/config/:/usr/share/logstash/config/
depends_on:
- elasticsearch
volumes:
elasticsearch_data:
driver: local
Logstashの設定
残念ながら本題のLogstashの設定はイマイチよくわかっていません。
大まかな理解では
- logstash.yml : Logstash自体の動作に関わる設定。コマンドライン引数で代用可能。
- pipelines.yml : Multiple Pipelinesという動作のために必要?要らないかもしれない。
- twitter.conf : Twitterから収集してElasticsearchに保存する、という処理が表現される。
という感じです。
logstash.ymlはほぼ定型文で、必要に応じてtwitter.confを書き換えると欲しいデータが手に入る、と考えています。
参考:https://www.elastic.co/guide/en/logstash/current/config-setting-files.html
pipeline.ordered: auto
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: ["http://elasticsearch:9200"]
- pipeline.id: twitter_pipeline
path.config: "/usr/share/logstash/pipeline/twitter.conf"
queue.type: persisted
以下が本記事の本題です。Twitter input pluginというものを使用します。
このプラグインはTwitter Streaming APIを使用してツイートを収集します。キーワードで検索をする場合はuse_samplesをfalseに、ランダムサンプリングするならばtrueに設定します。
詳細はプラグインのドキュメントが詳しいのでそちらをご参照ください。
参考:https://www.elastic.co/guide/en/logstash/current/plugins-inputs-twitter.html
input {
twitter {
consumer_key => 検索に使用するTwitterアプリのConsumer Key
consumer_secret => 検索に使用するTwitterアプリのConsumer Secret
oauth_token => Access Token
oauth_token_secret => Access Token Secret
use_samples => true
ignore_retweets => true
full_tweet => true
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch:9200/"]
index => "tweets"
}
}
起動方法
DockerComposeを起動するだけでツイートの収集が始まります。
$ docker-compose up -d
今回の構成では、Kibanaで収集したデータを確認することが出来ます。
1. localhost:5601にアクセス
2. サイドバーのOverviewをクリック
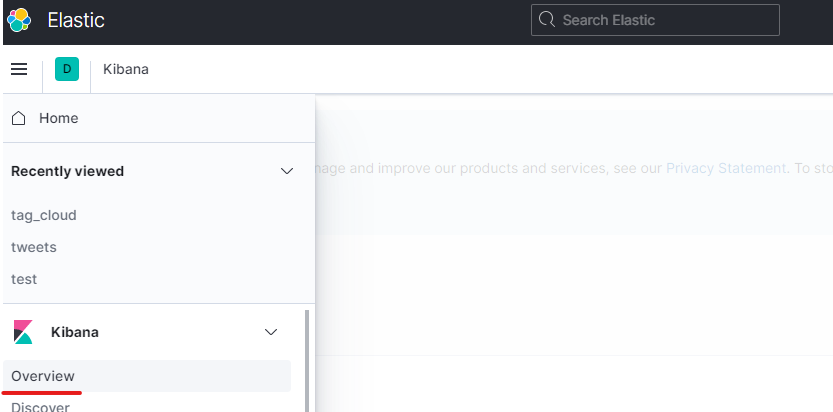
3. Add your dataをクリック
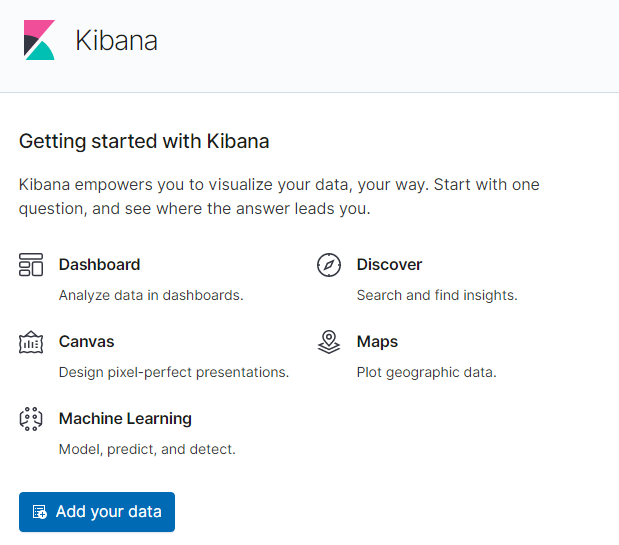
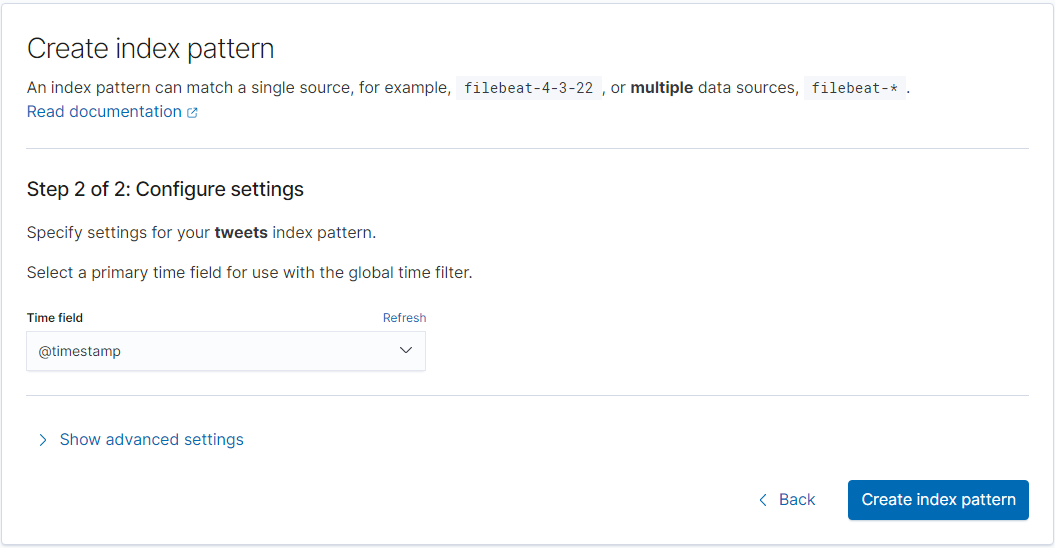
4. Create index patternをクリック
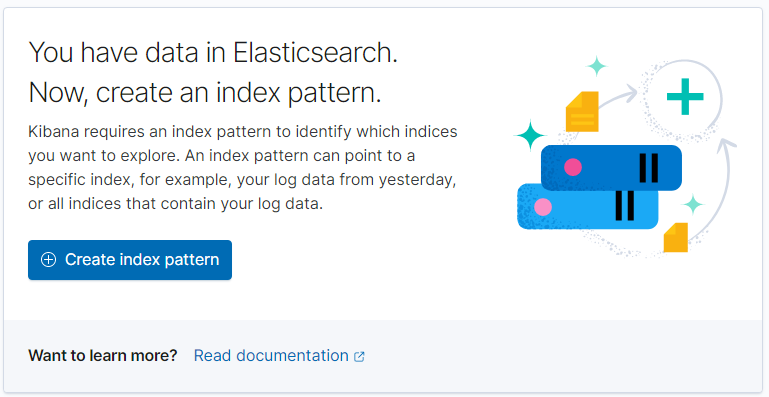
5. index pattern nameにtweetsと入力し、Next stepをクリック
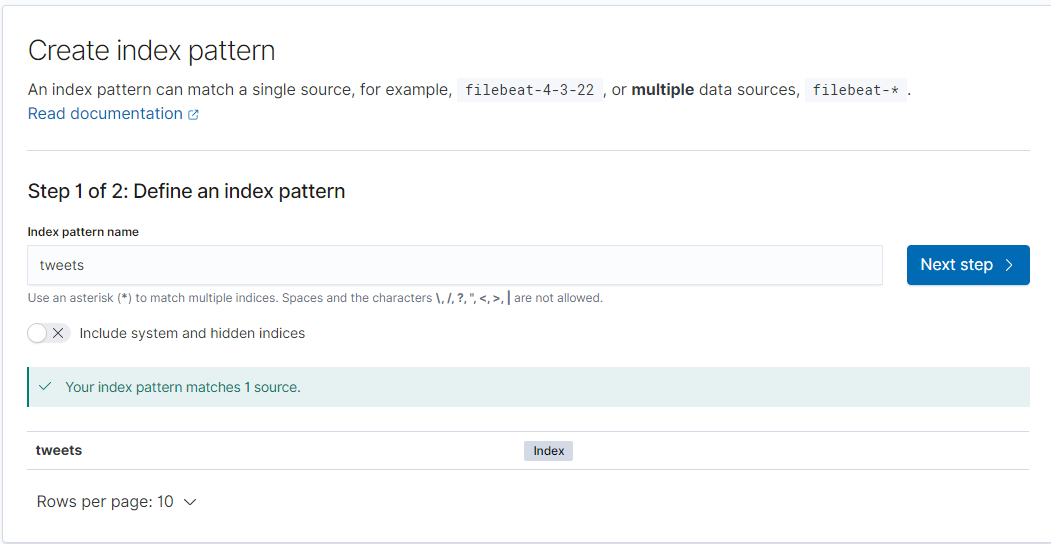
6. Time fieldに@timestampを選択し、Create indexをクリック
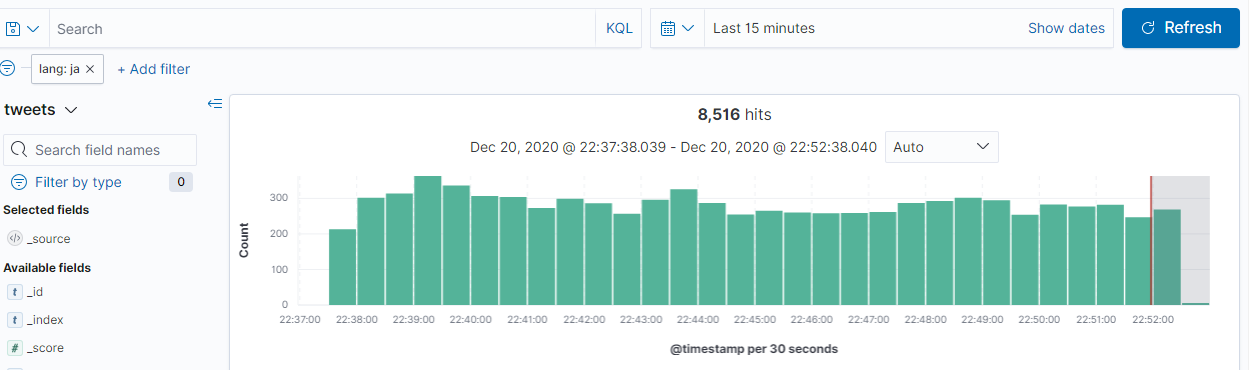
7. サイドバーのDiscoverをクリックすると、収集したツイートが確認できます
フィルターを使用して日本語だけを絞り込むことも出来ます。
まとめ
LogstashとElasticsearchをDockerで動かすことで簡単にツイートを収集する環境を作ることが出来ました。より良い設定が当然あるとは思いますが、まずはこれでツイートを収集してみようと思います。