概要
この記事では、AAAI2022のニューラルネットワークのモデル軽量化論文をまとめます。1
Improved Gradient based Adversarial Attacks for Quantized Networks
概要:量子化ネットワークへの敵対的攻撃
研究機関:Amazon
新規性:従来のFGSMやPGDよりも攻撃の精度が高い。
キモ:計算する時のLogitsにスケーリング係数$\beta$を掛けて、勾配をこのように計算する。


NJS (Network Jacobian Scaling) では、$\beta$はヤコビアンの特異値の逆数とする。
HNS (Hessian Norm Scaling) での$\beta$の決め方は
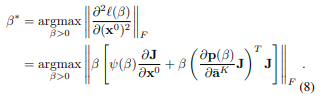
評価:ResNet, VGG等で、従来のFGSMやPGDと比較した。
From Dense to Sparse: Contrastive Pruning for Better Pre-trained Language Model Compression
概要:CAP (ContrAstive Pruning). タスク非依存の知識も入れながら枝刈りする方法。
研究機関:Alibaba
新規性:従来の枝刈りは特定タスクで解いていたので、catastrophic forgettingの課題があるのに対して、task-agonisticな知識も入れて学習することで、汎化性能を上げる。
キモ:学習済みモデル、枝刈り途中のスナップショット、ファインチューニングしたモデルそれぞれに対して、contrastive lossを求め(それぞれPrC, SnC, FiC)、全体を合算したロスを使う。


評価:BERTから刈ってMNLIで評価した。
Prune and Tune Ensembles: Low-Cost Ensemble Learning With Sparse Independent Subnetworks
概要:低コストアンサンブル学習で、1つの親ネットワークから刈って、子ネットワークを作る方法。
新規性:他の低コストアンサンブル学習よりも精度が良い。
キモ:Anti-Random Sampling. 1つの枝刈り結果からの距離が最大のネットワークを選ぶ。

評価:Wide-ResNetベースのアンサンブルで、他の枝刈り手法と比較した。
Prior Gradient Mask Guided Pruning-Aware Fine-Tuning
概要:PGMPF。枝刈りしながらFine-tuningする方法。
新規性:Fine-tuningしながら枝刈りする。
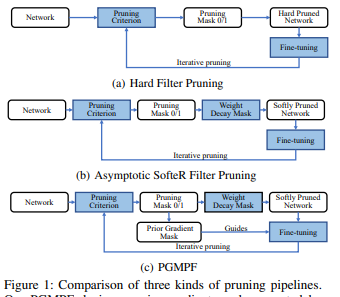
キモ:枝刈りを連続マスクとみなして、勾配法でマスクを適用する。


評価:VGGやResNetに適用して実験した。
-
画像や数式は論文から引用しています。 ↩