はじめに
AWS公式のハンズオンシリーズの中から、AWS Lambda と AWS の各種 AI サービスを組み合わせて、“音声ファイルがアップロードされると文字起こしと感情分析を自動的に行う” パイプラインを構築するハンズオンを実施しました。
本記事は自身のハンズオン学習メモとして投稿します。
目次
ハンズオンの目的
- 音声の文字起こし、およびその感情分析を行うパイプラインをサーバーレスアーキテクチャで構築する
- S3トリガーでLambdaを非同期に呼び出す方法を理解する
- AWSのAI Servicesの特徴と使い方を理解する
AWS Hands-on for Beginners - AWS Lambda と AWS AI Services を組み合わせて作る音声文字起こし & 感情分析パイプライン では、AWS Lambda と AWS の各種 AI サービスを組み合わせて、“音声ファイルがアップロードされると文字起こしと感情分析を自動的に行う” パイプラインを構築していきます。これまでのハンズオンでは、Amazon API Gateway と AWS Lambda との組み合わせを試してきましたが、AWS Lambda は他にも多くの AWS サービスと連携できます。このハンズオンでは、Amazon S3 へのファイルアップロードをトリガーに Lambda Function を実行する機能を利用し、パイプラインを構築します。また、AWS には多くの AI サービスがあり、このハンズオンをきっかけに、皆様のプロダクト開発に活かせる AI サービス群を知っていただければと考えています。
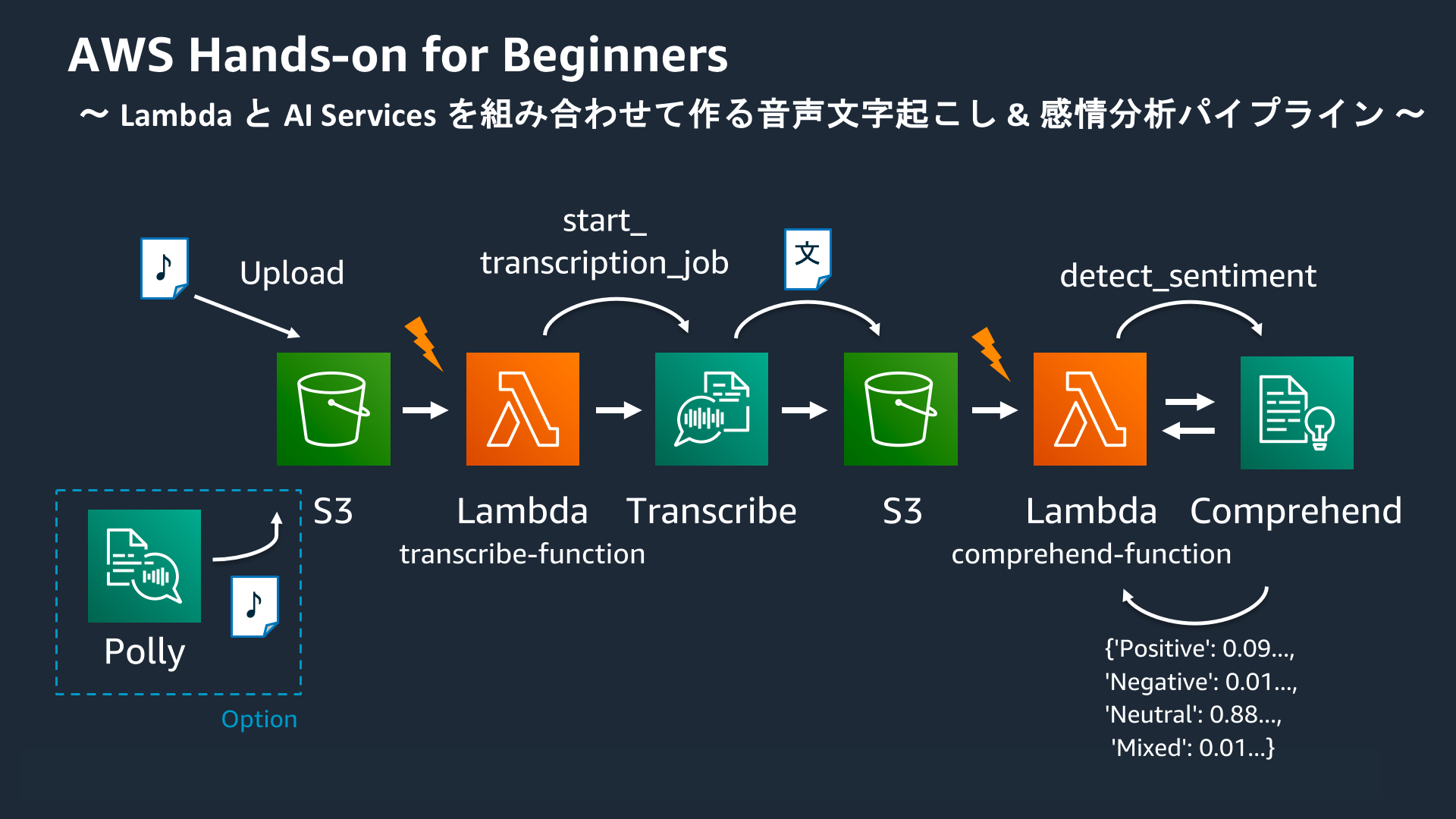
(https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-hands-on/ より引用)
本編
S3 トリガーで Lambda ファンクションを起動する
- S3作成
- Lambda関数作成
- S3にファイルをアップロードし、Lambdaが処理をする事を確認
Amazon Transcribe を使って文字起こしを試してみる
Amazon Transcribeとは
音声をテキストに変換する文字起こしサービス。
- S3作成(結果出力用)
- Amazon TranscribeでJobを作成し、Inputデータをアップロード
- S3に結果出力
{"jobName":"Test-Job","accountId":"996770387061","results":{"transcripts":[{"transcript":"ハンズオン 順調 です か 手 を 動かす の 楽しい です よ ね"}],"items":[{"start_time":"0.04","end_time":"0.71","alternatives":[{"confidence":"0.9967","content":"ハンズオン"}],"type":"pronunciation"},{"start_time":"0.71","end_time":"1.23","alternatives":[{"confidence":"1.0","content":"順調"}],"type":"pronunciation"},{"start_time":"1.23","end_time":"1.5","alternatives":[{"confidence":"1.0","content":"です"}],"type":"pronunciation"},{"start_time":"1.5","end_time":"1.74","alternatives":[{"confidence":"0.9985","content":"か"}],"type":"pronunciation"},{"start_time":"2.16","end_time":"2.32","alternatives":[{"confidence":"0.9958","content":"手"}],"type":"pronunciation"},{"start_time":"2.32","end_time":"2.51","alternatives":[{"confidence":"1.0","content":"を"}],"type":"pronunciation"},{"start_time":"2.51","end_time":"3.02","alternatives":[{"confidence":"1.0","content":"動かす"}],"type":"pronunciation"},{"start_time":"3.02","end_time":"3.21","alternatives":[{"confidence":"1.0","content":"の"}],"type":"pronunciation"},{"start_time":"3.4","end_time":"3.94","alternatives":[{"confidence":"0.999","content":"楽しい"}],"type":"pronunciation"},{"start_time":"3.94","end_time":"4.22","alternatives":[{"confidence":"1.0","content":"です"}],"type":"pronunciation"},{"start_time":"4.22","end_time":"4.39","alternatives":[{"confidence":"1.0","content":"よ"}],"type":"pronunciation"},{"start_time":"4.39","end_time":"4.64","alternatives":[{"confidence":"1.0","content":"ね"}],"type":"pronunciation"}]},"status":"COMPLETED"}
S3 への音声ファイルアップロードをトリガに Lambda を起動し Transcribe するパイプラインを作る
- LambdaにアタッチされているIAMロールのポリシーを修正(TranscribeとS3への権限を追加)
- Lambda関数を修正
import json
import urllib.parse
import boto3
import datetime
s3 = boto3.client('s3')
transcribe = boto3.client('transcribe')
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
transcribe.start_transcription_job(
TranscriptionJobName= datetime.datetime.now().strftime("%Y%m%d%H%M%S") + '_Transcription',
LanguageCode='ja-JP',
Media={
'MediaFileUri': 'https://s3.ap-northeast-1.amazonaws.com/' + bucket + '/' + key
},
OutputBucketName='handson-serverless-3-072518-output'
)
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e
以下のような流れで処理が実行される。
- S3にファイルをアップロード
- Lamndaに連携
- Transcribeのジョブ作成・実行
- ジョブ実行結果をLambdaに返却
- OutputのjsonをS3にアップロード
パイプラインで文字起こししたテキストを Comprehend で感情分析する
Amozon Comprehendとは
Amozon Comprehendは、機械学習を利用した自然言語処理サービス。
テキストの中の有用な情報を発見・分析したり、キーフレーズやエンティティの取得、感情分析をする事が出来るサービスである。
以下は、感情分析の例。
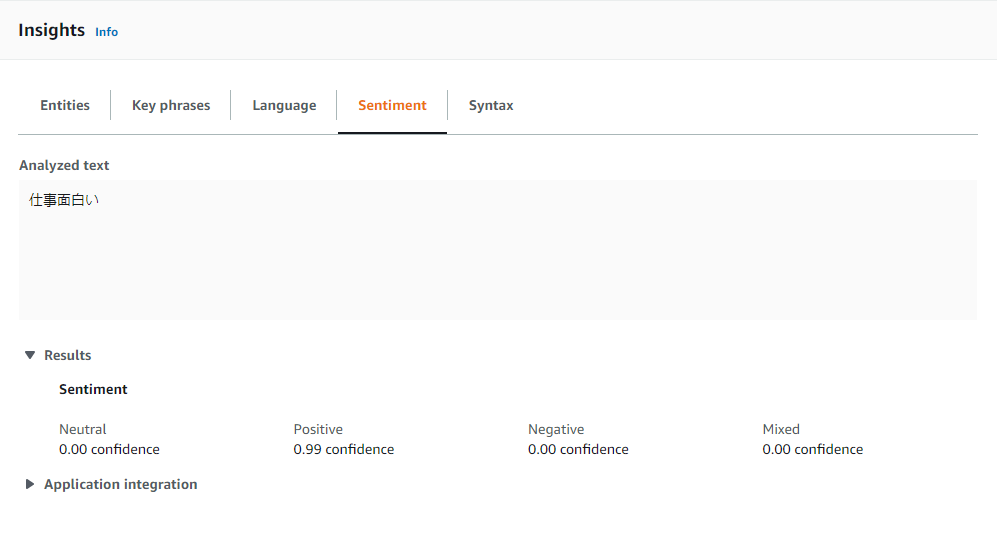
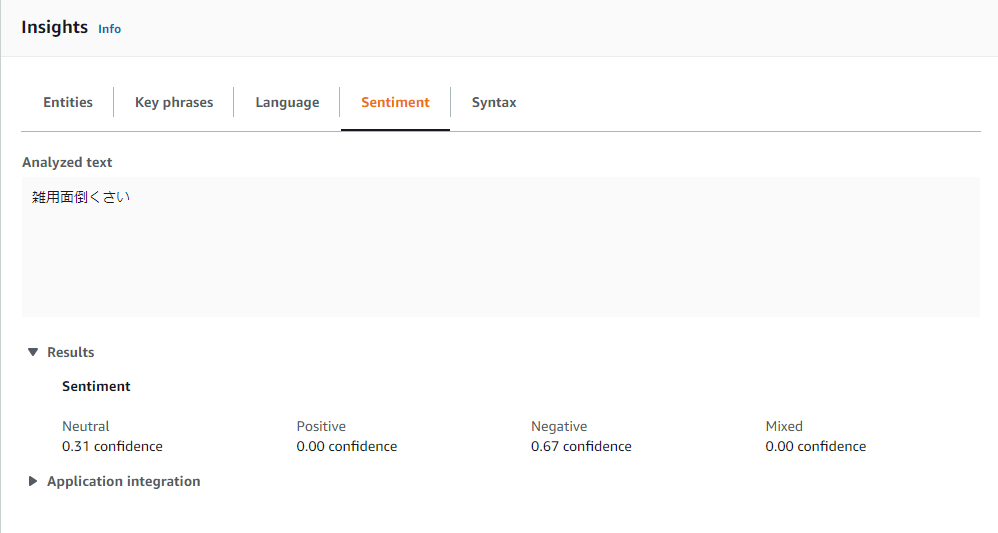
- Lambda関数を作成
import json
import urllib.parse
import boto3
s3 = boto3.client('s3')
comprehend = boto3.client('comprehend')
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
response = s3.get_object(Bucket=bucket, Key=key)
body = json.load(response['Body'])
transcript = body['results']['transcripts'][0]['transcript']
sentiment_response = comprehend.detect_sentiment(
Text=transcript,
LanguageCode='ja'
)
sentiment_score = sentiment_response.get('SentimentScore')
print(sentiment_score)
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e
実行すると、以下のように感情分析がCloudWatch Logsに表示される。

まとめると、以下のような流れになる。
- S3にファイルをアップロード
- Lamnda(Transcribe用)に連携
- Transcribeのジョブが作成・実行され、文字起こしが行われる
- 結果をLambdaに返却
- 文字起こし結果のjsonをS3にアップロード
- Lamnda(Comprehend用)に連携
- Comprehendを呼び出し、感情分析を実行
- 感情分析結果を出力
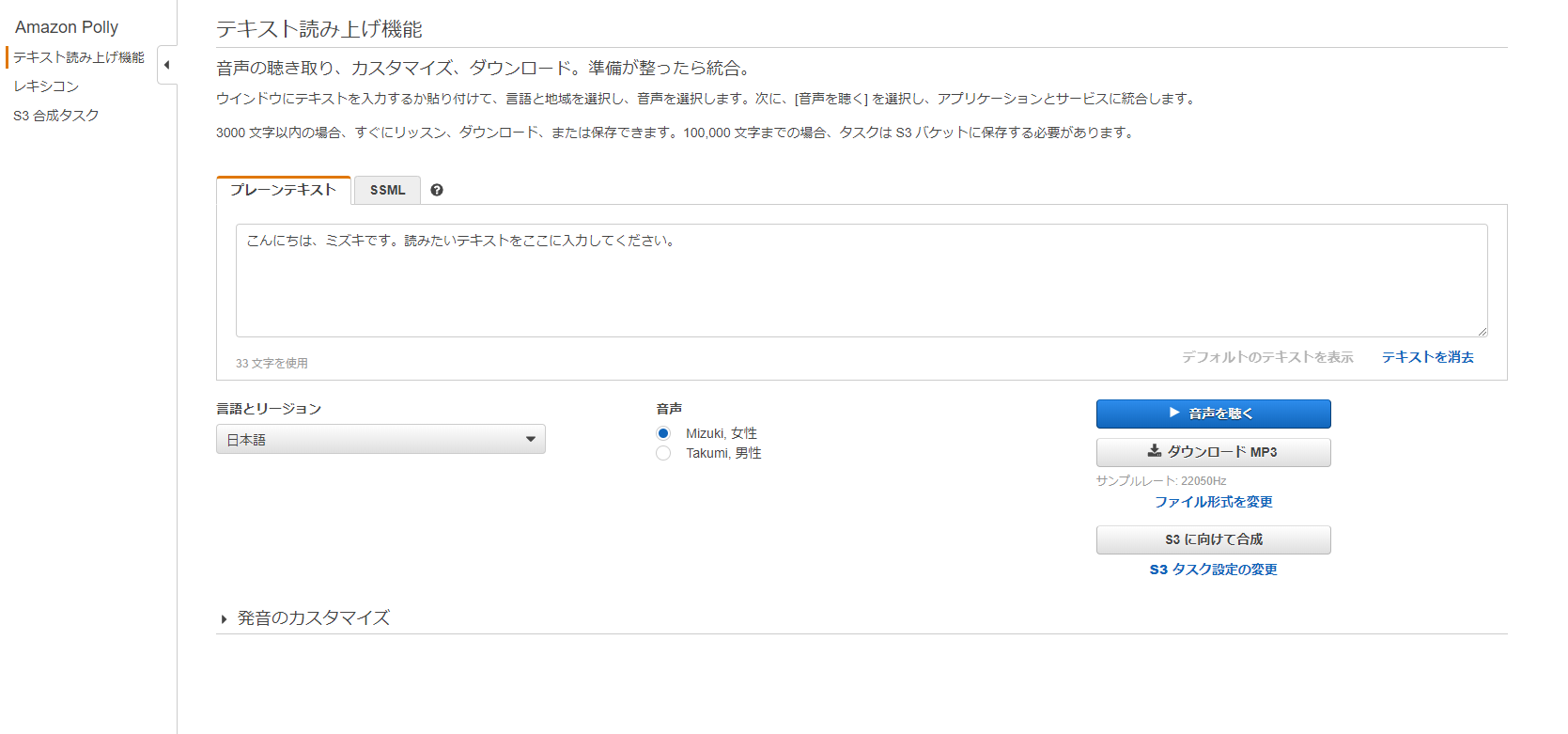
Amazon Pollyを試してみる
Amazon Pollyとは
テキストを音声に変換するサービス。
作成した AWS リソースの削除
粛々と削除。特筆すべき事はなし。
おわりに
今回はAWSのAIサービスを利用したハンズオンを実施した。
実際に触ってみると、想像以上に簡単に各種サービスを使う事ができた。
また今回利用したサービスは全てマネージドサービスであり、サーバーをたてる事なく手軽に利用でき、かつ料金も使った分だけであるのが有難いと感じた。
AWS以外のパブリッククラウドに同様の機能はあるのか、もしくは同じような事をしようとしたらどのように実装する必要があるのか、等を学習する事で理解を深めていきたい。
また、今回AIサービスに触れたが、AWSのSageMakerはまだ触った事がないので、実際に動かす機会を設けたいと思う。