Kaggleとは
Kaggle(カグル)とは、世界中のデータサイエンティストが参加するコミュニティサイトで、様々な機械学習コンペに取り組むことができます。
機械学習の勉強をし始め、実践的に手を動かしてトレーニングしたい方にとてもおすすめです!
Kaggleで機械学習のトレーニングをすることにはたくさんのメリットがありますが、私は特に以下の2点に魅力を感じています。
- コンペで使用するためのデータセットが無料で提供されているため、データ集めのフェーズをスキップして純粋に分析をどんどん行える。
- 他のユーザーのコーディングを閲覧できるため、スコアの高い人のモデルを参考にして学習できる。
たくさんコンペに参加してたくさんトレーニングしましょう!
本記事の概要と対象者
-
本記事ではKaggle初心者の方向けに、1番最初の無料会員登録をするところから、コンペに参加し回答を提出するまでの一連の流れを手順として記載します。
-
サイトのUIは頻繁に変わります。本記事のスクリーンショットは 2021/08/01 時点のものですので、ご了承ください。
-
今回使用する言語は「Python」、参加するコンペはKaggleがチュートリアルとして用意している「タイタニック号の生存者予測」ですが、その他の言語・コンペでやりたい方にも基本的な手順は参考になると思います。
-
本記事のゴールは「回答の提出」です。一応簡単に「k-最近傍法」でモデルを作成しますが、スコア向上などの参考にはならないと思いますのでご注意ください。
では、次セクションから手順となります。
全7ステップ!よしなに!
1. 無料会員登録
Kaggleのコンペに参加するためには、無料会員登録が必要となります。
-
Kaggleトップページにアクセスし、画面右上の「Register」をクリックします。
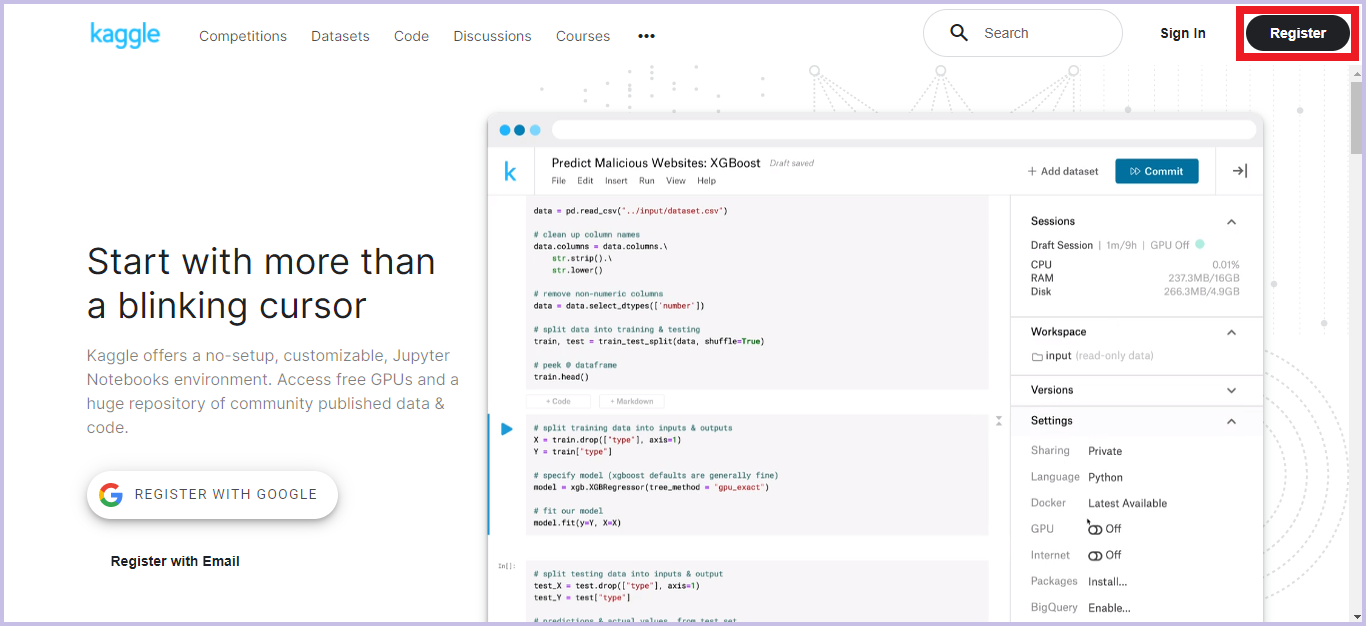
-
Googleアカウントや任意のメールアドレスと連携してアカウントを作成します。(今回はメールアドレスを選択します)
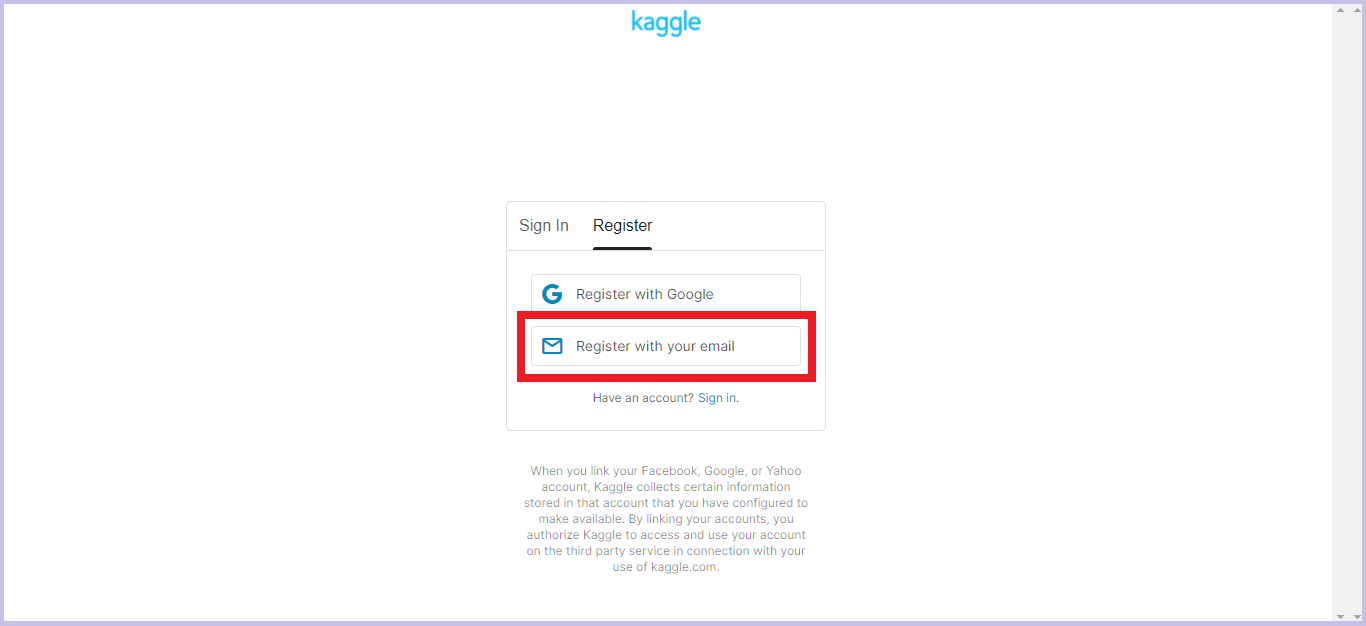
-
アドレス、パスワード、サイト上で表示する名前を入力し、「Next」をクリックします。
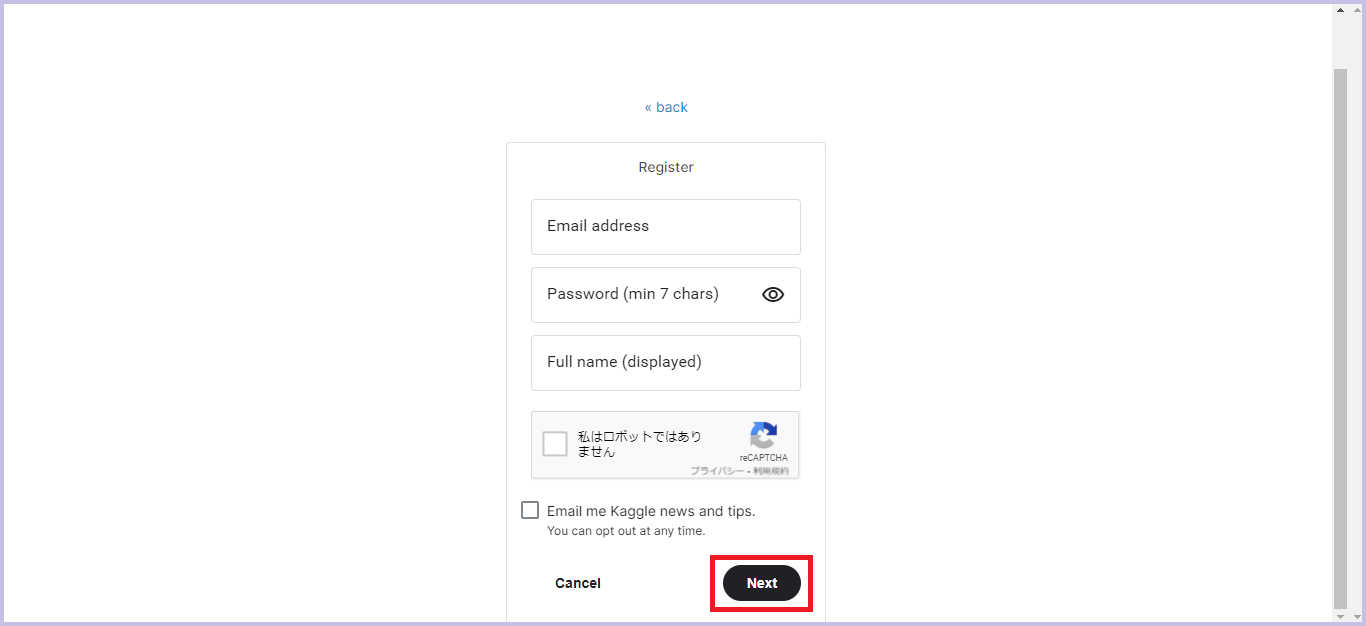
-
規約文を
スクロールで飛ばしよく読み、「I agree」をクリックします。
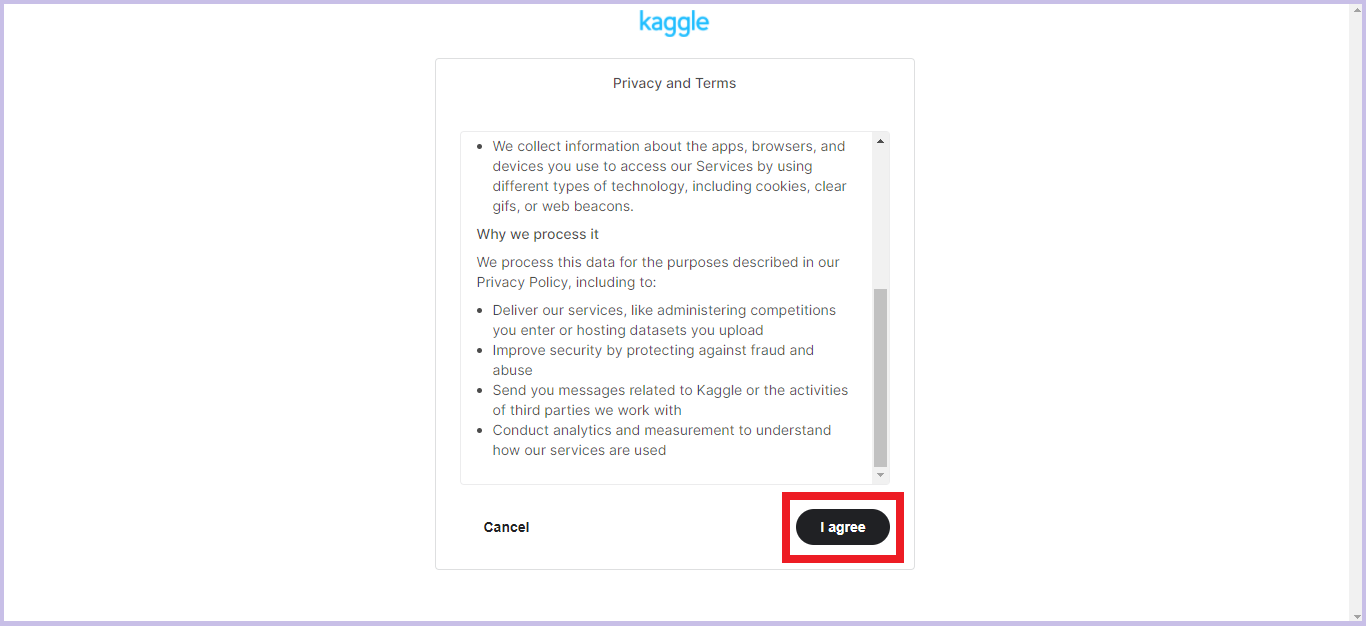
-
6桁のディジットコードがメールに届いているので、それを入力して「Next」をクリックします。
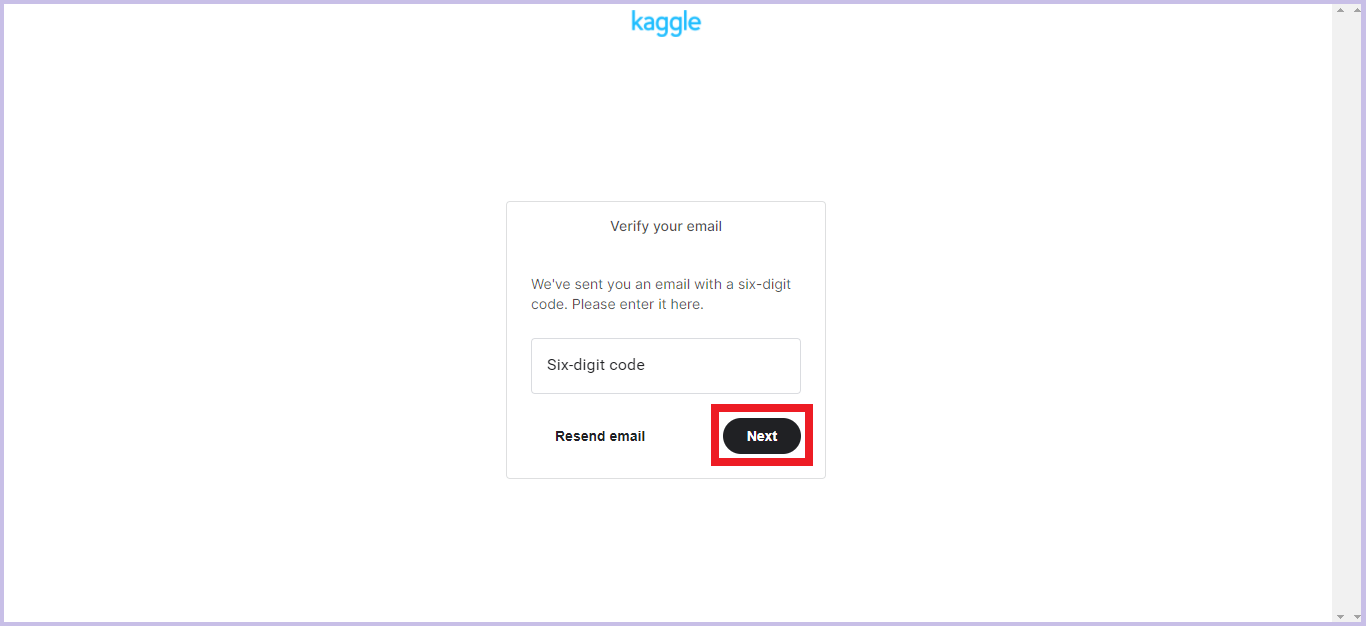
トップページに戻り、画面右上に自信のプロフィール画像が表示されていればアカウント作成は成功です!
2. コンペに参加
今回はKaggleのチュートリアルとして位置づけられている、「タイタニック号の生存者予測」という課題を題材にして説明していきます。
乗客にまつわる年齢や性別などのあらゆる情報をもとに、その乗客が生存できたか亡くなってしまったかを予測します。
データセットの内容が単純で、ファイルサイズも小さく扱いやすいため、初心者にピッタリです。
-
画面左の「Competitions」をクリックします。
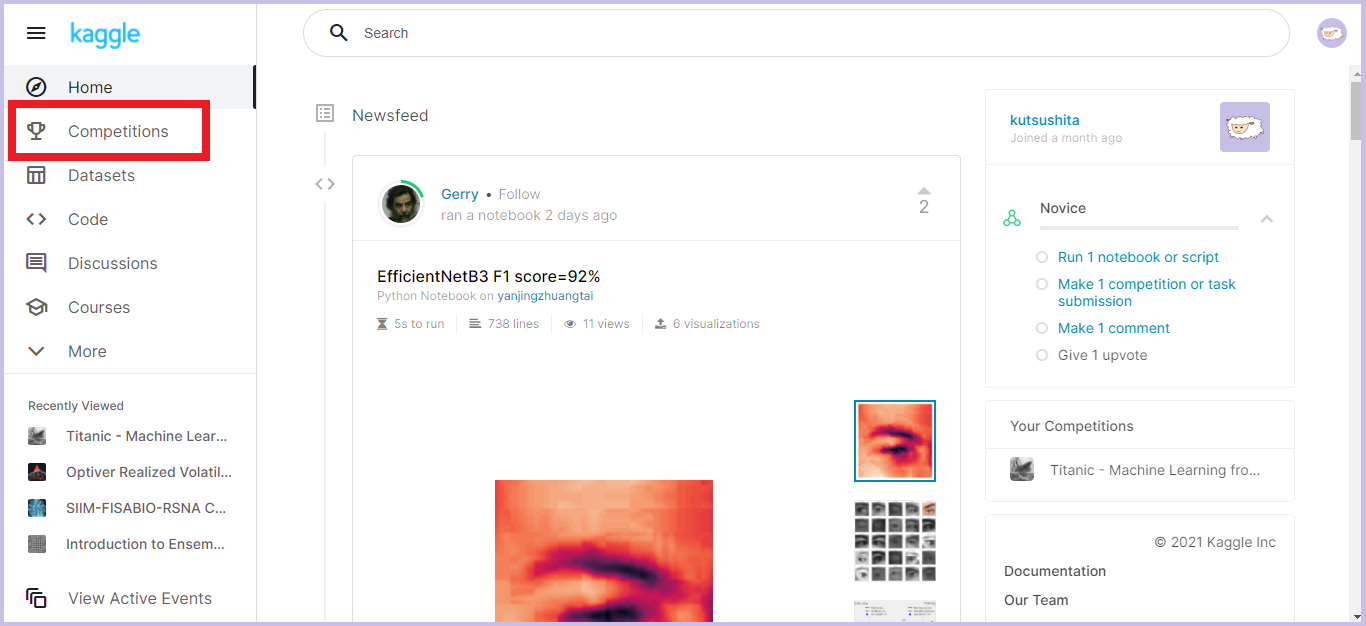
-
参加したいコンペ情報をクリックします。(今回は検索バーで「titanic」と入力し、「Titanic - Machine Learning from Disaster」というコンペをクリックします)
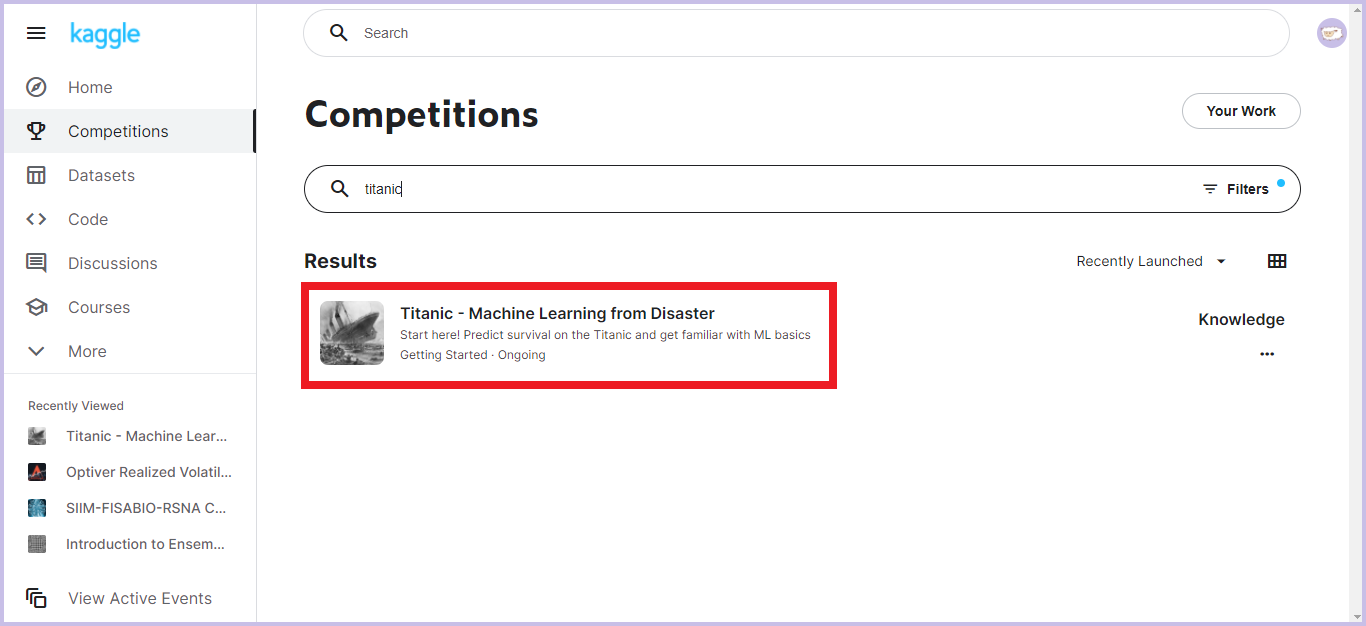
-
コンペタイトルの下の「Join Competition」をクリックします。
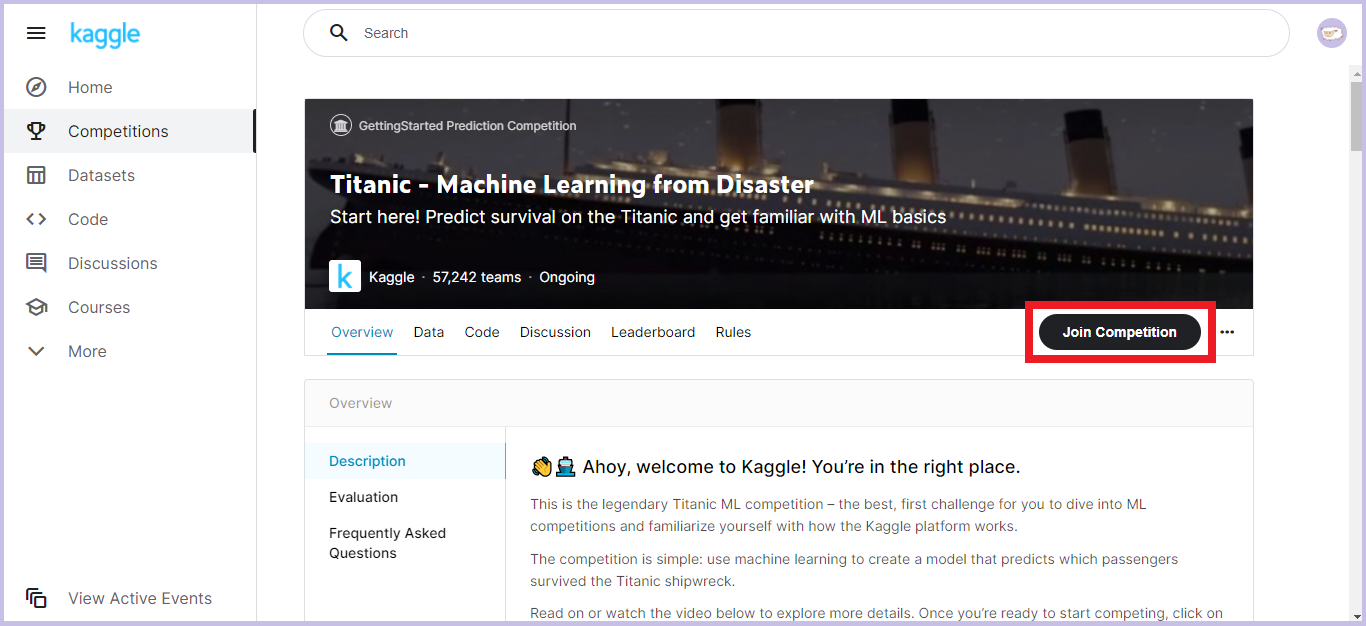
これで参加表明完了です!
3. データファイルの内容確認
Kaggleはブラウザ上でコードを書くことができます。
-
「Code」タブをクリックし、「New Notebook」をクリックします。
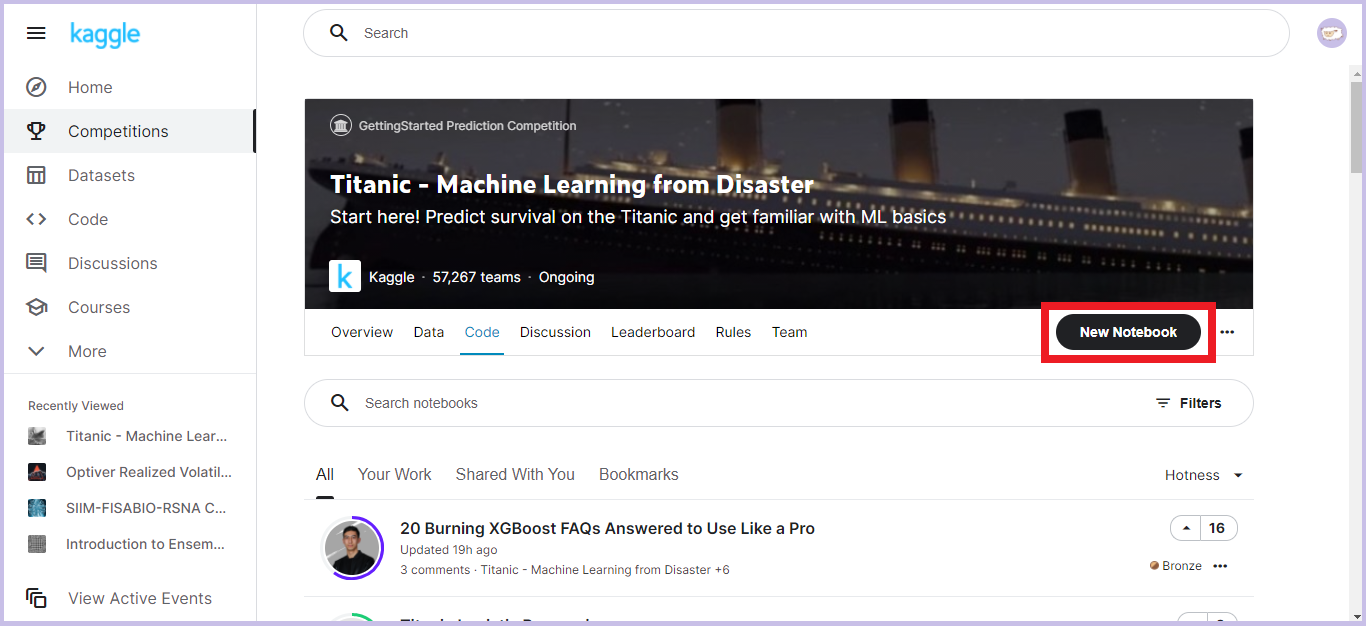
-
「+ Code」をクリックするとセルが増えるのでそこにコードを記述していきます。
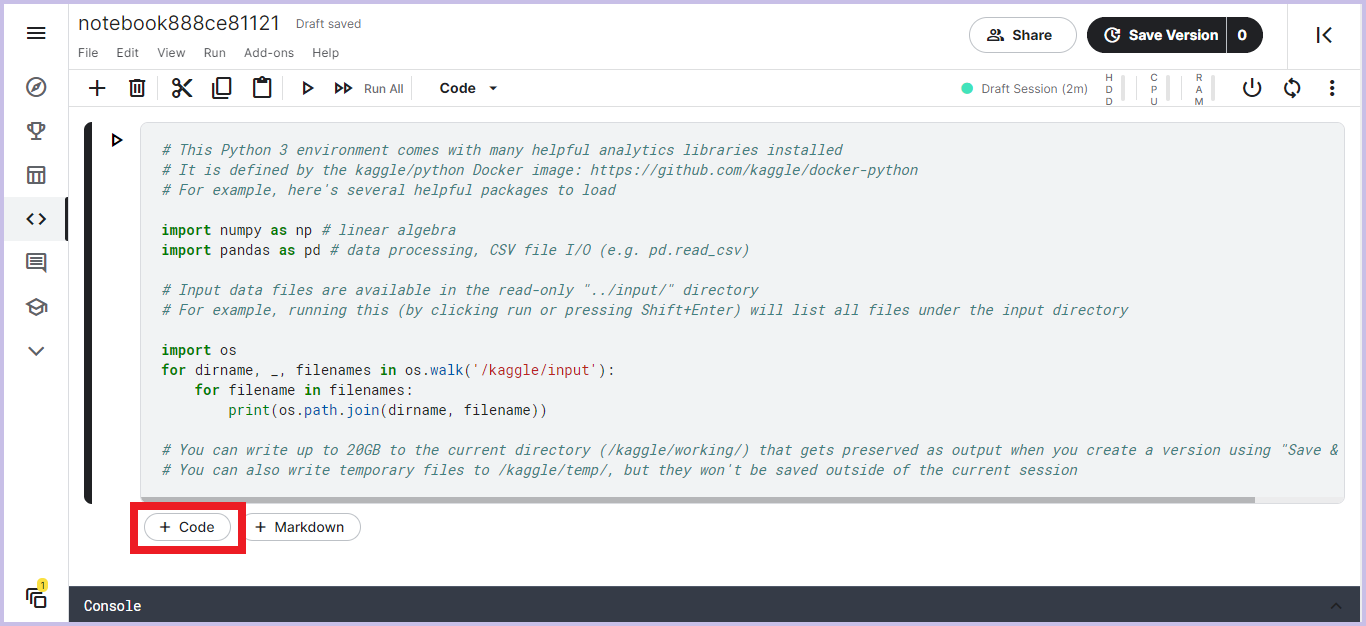
-
使用するデータファイルのパスは画面右上の「|<」で開いた先の「Data」に記載があります。(今回は「input / titanic」の3種類のcsvファイルを使用します)
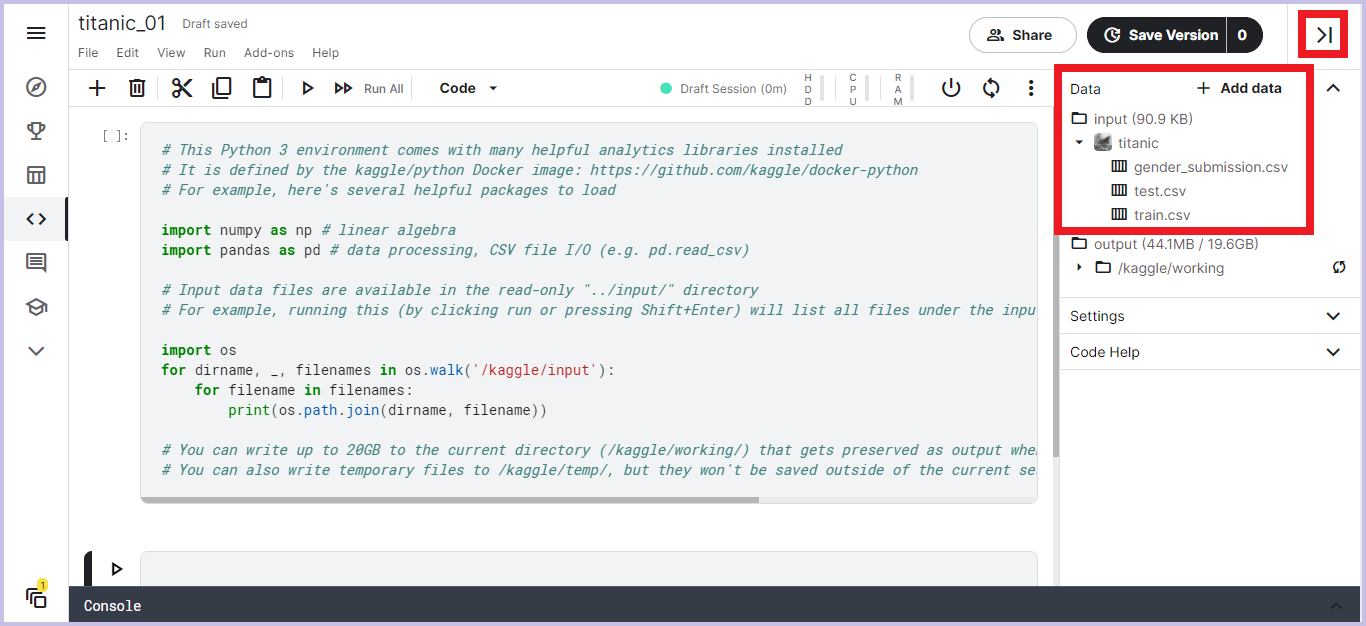
それではそれぞれのファイルについて内容を確認してみましょう。
- train.csv
- test.csv
- gender_submission.csv
の順で確認していきます。
3.1. train.csv
train.csv は機械学習モデル生成用のデータです。
ファイルを読み込んで内容を確認してみましょう。
train = pd.read_csv("../input/titanic/train.csv")
train.head()
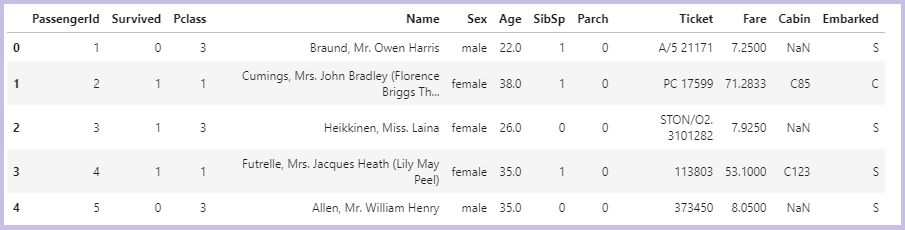
12種類のカラムで構成されていることが分かります。
それぞれのカラムの意味は以下です。
| カラム名 | 意味 | 備考 |
|---|---|---|
| PassengerId | 乗客ID | |
| Survived | 生存フラグ | 0=死亡、1=生存 |
| Pclass | チケットクラス | 1=富裕階級、2=一般階級、3=労働階級 |
| Name | 乗客の名前 | |
| Sex | 性別 | male=男性、female=女性 |
| Age | 年齢 | |
| SibSp | 同乗している兄弟・配偶者の数 | |
| Parch | 同乗している親・子供の数 | |
| Ticket | チケット番号 | |
| Fare | 料金 | |
| Cabin | 客室番号 | |
| Embarked | 出港地 | C=Cherbourg、Q=Queenstown、S=Southampton |
3.2. test.csv
test.csv は問題用のデータです。
こちらも同じようにファイルを読み込んで内容を確認してみましょう。
test = pd.read_csv("../input/titanic/test.csv")
test.head()
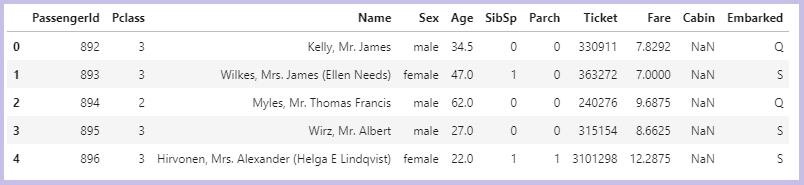
train.csv と比べると test.csv には「Survived」のみが無く、その他の11種類のカラムで構成されていることが分かります。
つまりこの課題は、train.csv の乗客情報をもとに機械学習モデルを生成し、test.csv に記載の各乗客について「Survived」を予想するというものです。
3.3. gender_submission.csv
gender_submission.csv は回答形式を示すファイルです。
内容を確認してみましょう。
gender_submission = pd.read_csv("../input/titanic/gender_submission.csv")
gender_submission.head()
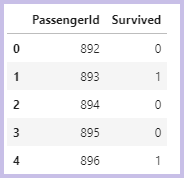
カラムは「PassengerId」と「Survived」のみです。
このように、1列目の「PassengerId」に test.csv の乗客IDを並べ、2列目の「Survived」にその乗客の生存予測結果(0=死亡、1=生存)を並べたcsvファイルを回答として提出します。
4. データの前処理
今回の前処理工程では、以下の2つのデータ加工を行います。
- 欠損項目を代理値で補完
- 文字列項目を数値へ変換
4.1. 欠損項目を代理値で補完
「3. データファイルの内容確認」でデータを出力すると、いくつかの項目に「NaN」と書かれていたと思います。
これはデータの欠損を表しています。この欠損を代理の値で補完していきます。
まずはデータ全体でどのくらいの欠損があるかを確認してみましょう。
- train.csv を確認
train.isnull().sum()
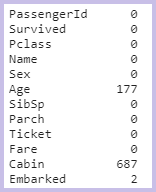
train.csv には「Age」、「Cabin」、「Embarked」に欠損があることが分かりました。
- test.csv を確認
test.isnull().sum()
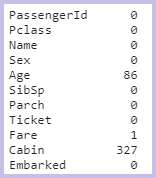
test.csv には「Age」、「Fare」、「Cabin」に欠損があることが分かりました。
これらの欠損箇所に代理のデータを埋めていきます。
代理のデータには、平均値が使われたり、中央値が使われたり、はたまた他のデータを材料に欠損値をも機械学習で予想したりと、工夫のしがいがあります。
今回は全て最頻値で埋めてしまいます!
train["Age"] = train["Age"].fillna(train["Age"].mode()[0])
train["Cabin"] = train["Cabin"].fillna(train["Cabin"].mode()[0])
train["Embarked"] = train["Embarked"].fillna(train["Embarked"].mode()[0])
test["Age"] = test["Age"].fillna(test["Age"].mode()[0])
test["Fare"] = test["Fare"].fillna(test["Fare"].mode()[0])
test["Cabin"] = test["Cabin"].fillna(test["Cabin"].mode()[0])
※ 最頻値を取得する.mode()ですが、平均値や中央値と違って複数の値が返ってくる可能性があるため、代入の際にはインデックスを明示的に指定する必要があります。
4.2. 文字列項目を数値へ変換
文字列のデータがあるとそのままでは機械学習には使用できないので、数値へ変換します。
今回は「Sex」と「Embarked」をダミー変数化という手法で数値化します。
(「Name」「Ticket」「Cabin」の3つは数値化が大変なので今回は省きます。)
ダミー変数化とはどういうものか、「Embarked」を例に簡単に説明します。
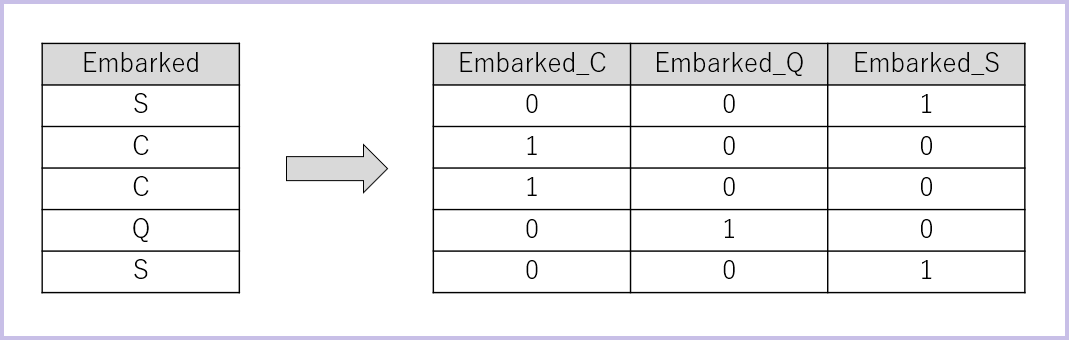
上のイメージ図のように、もともとの変数「Embarked」を値の種類ごとに「Embarked_C」「Embarked_Q」「Embarked_S」と分割し、該当する変数には「1」を、該当しない変数には「0」を入れます。
単純に「C → 0、 Q → 1、 S → 2」と変換すると、ただの港の名前なのに無意味な順序関係・大小関係が生まれてしまいます。
このような変換は決定木の分岐や回帰分析では良い結果が得られにくいことが多いので、それを避けるためにダミー変数化を行いました。
ダミー変数化はpandasで簡単に行えます。
train = pd.get_dummies(train, columns=['Sex', 'Embarked'])
test = pd.get_dummies(test, columns=['Sex', 'Embarked'])
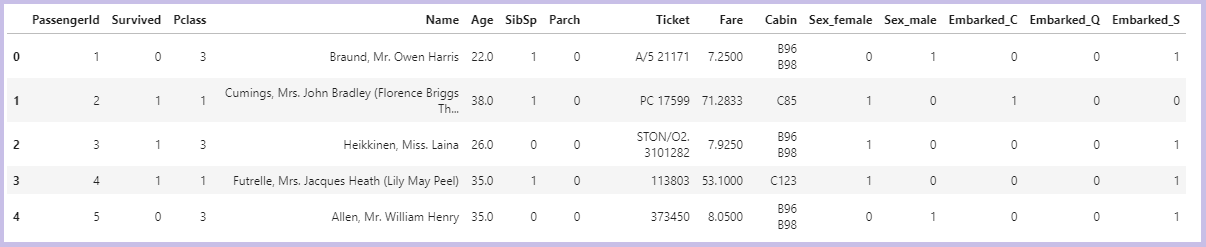
出力してみると、「Sex」と「Embarked」がダミー変数化できていることが分かります。
5. 生存者予測
前処理ができたので、いよいよ機械学習モデルを作成して生存者予測を行います。
前セクションで数値化しなかったカラムや、生存者予測に影響が無さそうなカラムを省いた以下の7つの変数を今回使用します。
- Pclass
- Sex
- Age
- SibSp
- Parch
- Fare
- Embarked
今回は「k-最近傍法」という方法で予測します。
ライブラリは「scikit-learn」を使用します。
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=1)
X_train = train[["Pclass", "Age", "SibSp", "Parch", "Fare", "Sex_female", "Sex_male", "Embarked_C", "Embarked_Q", "Embarked_S"]]
y_train = train["Survived"]
X_test = test[["Pclass", "Age", "SibSp", "Parch", "Fare", "Sex_female", "Sex_male", "Embarked_C", "Embarked_Q", "Embarked_S"]]
clf.fit(X_train, y_train)
# t_test に予測結果を格納
y_test = clf.predict(X_test)
6. 回答ファイルの作成・エクスポート
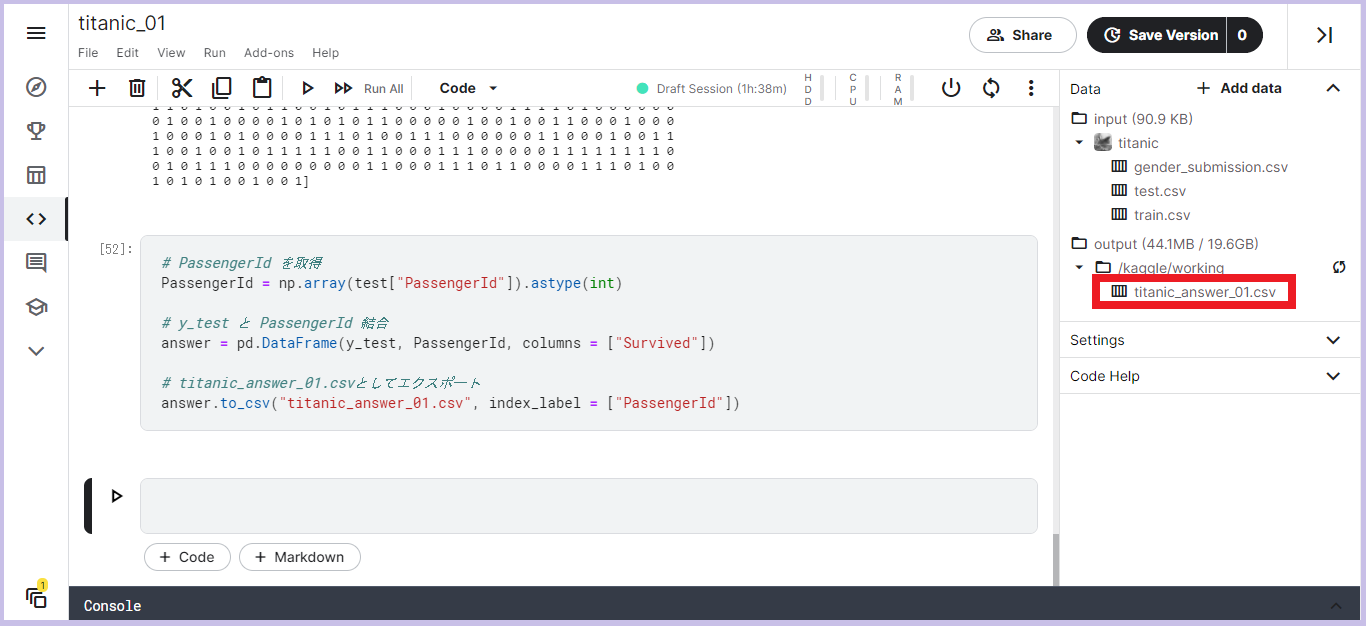
予測結果を使って回答ファイルの作成・エクスポートをしましょう!
# PassengerId を取得
PassengerId = np.array(test["PassengerId"]).astype(int)
# y_test と PassengerId を結合
answer = pd.DataFrame(y_test, PassengerId, columns = ["Survived"])
# titanic_answer_01.csv としてエクスポート
answer.to_csv("titanic_answer_01.csv", index_label = ["PassengerId"])
エクスポートした回答ファイルは画面右の「output」に表示され、三点メニューからダウンロードすることができます。
7. 回答ファイルの提出
最後に、回答ファイルを提出しましょう!
-
タイタニック課題の画面右上の「Submit Predictions」をクリックします。
-
「Step 1」のアップロードボタンをクリック、もしくはファイルのドラッグ&ドロップで回答ファイルをアップロードします。
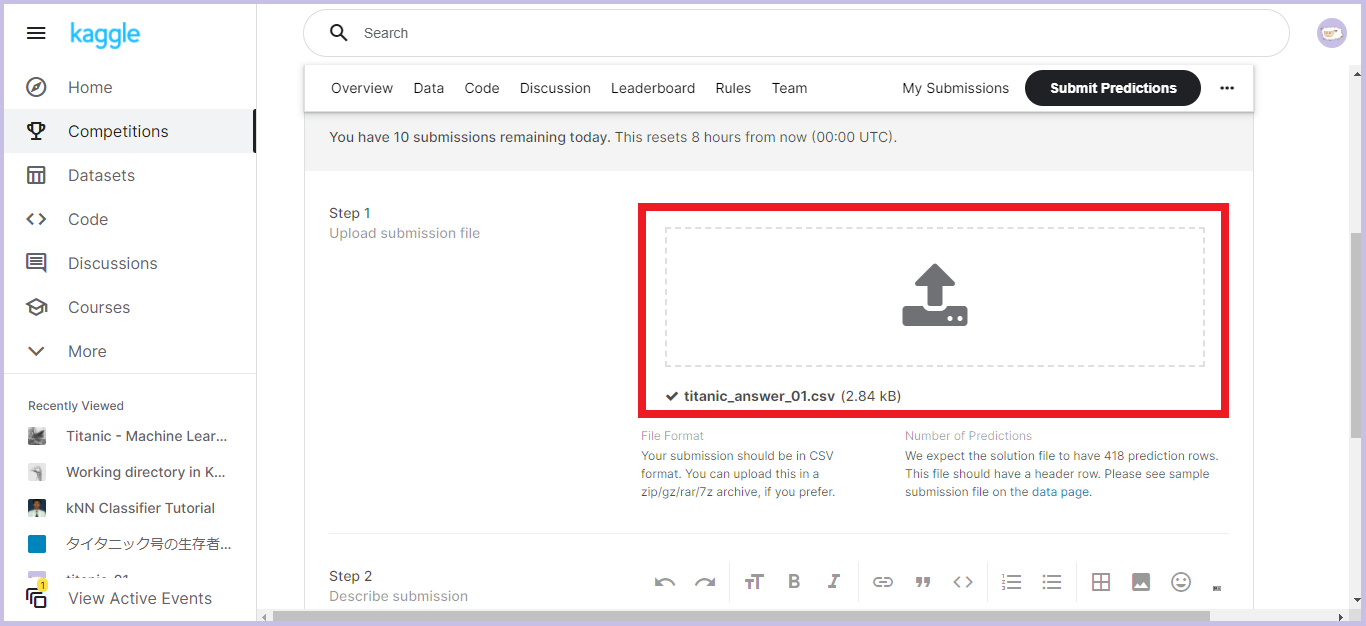
-
「Step 2」の「Describe submission」を書いて画面下の「Make Submission」をクリックします。
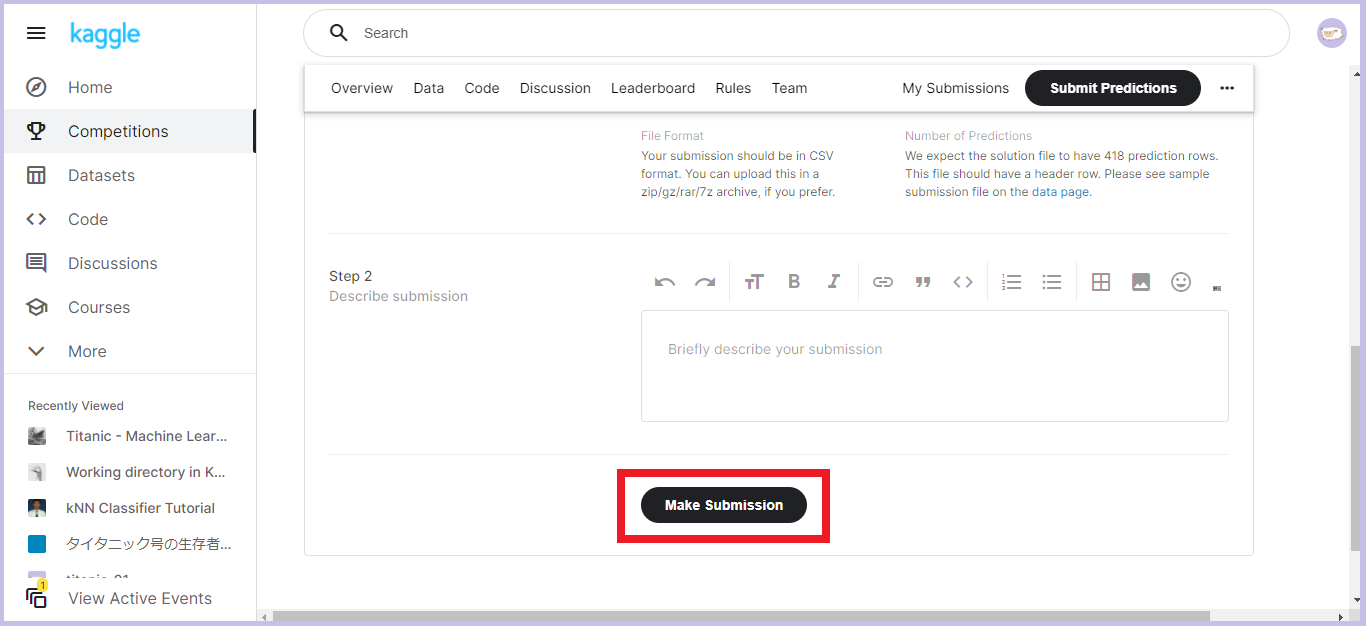
これで提出完了です!!
スコアは「Leaderboard」タブの「Jump to your position on the leaderboard」から確認できます。
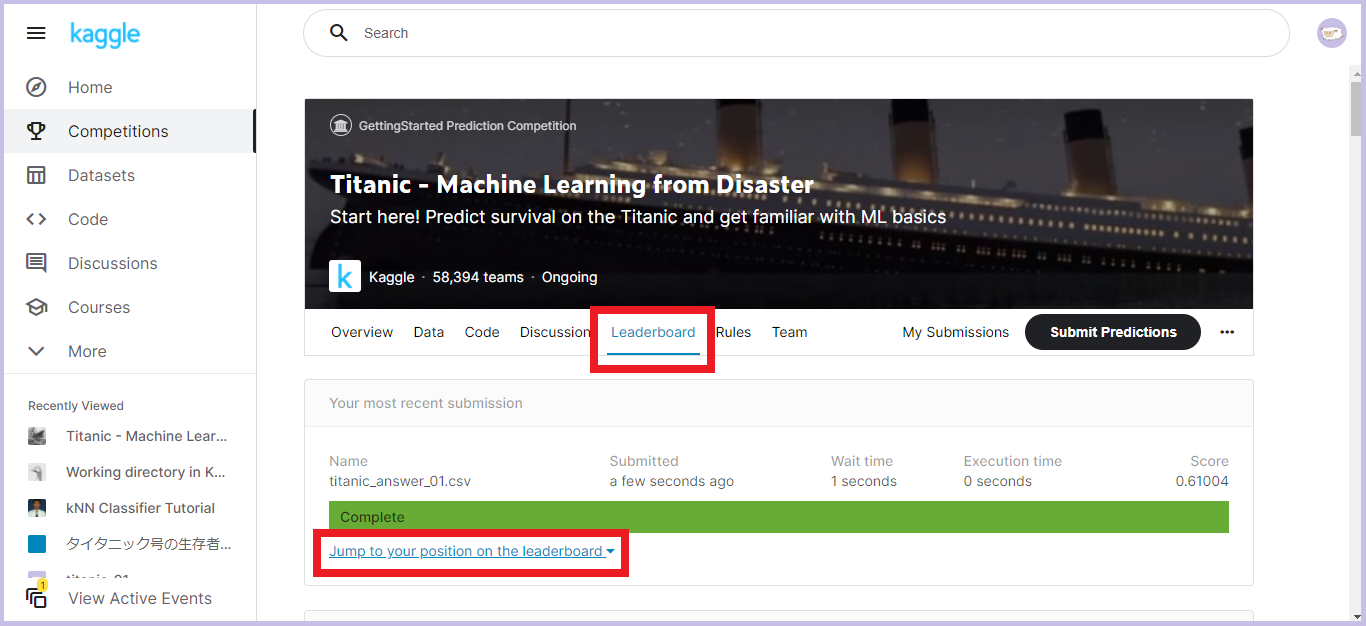
今回の私のスコアは61%でした。
うーーん、微妙ですが最初はこんなもんですね(^^;
お疲れ様でした!
おわりに
さてこれで回答提出までの一連の手順が身についたと思います。
このあとは、今回のタイタニック課題の精度を上げるも良し、他の課題に取り組んでみるのも良しです!
タイタニック課題の精度を上げる場合は、まずは正答率7割以上を目指してみてください。
7割以上にするにはデータの前処理や機械学習モデルのチューニングなどにけっこう工夫が必要で、意外と大変です!
他の課題に取り組む場合は、「House Prices - Advanced Regression Techniques」という住宅の価格予測を行う課題をおすすめします。
タイタニック課題とこの住宅価格予測の課題がKaggleのチュートリアルとされています。
是非自分のペースで楽しく機械学習のトレーニングに励んでください!
ちなみにKaggleに参加している人をKaggler(カグラー)と呼ぶそうです。
これであなたもカグラーですね♪