はじめに
Qiita初投稿です。
GoogleScholarで読んだ論文を整理したかったので、論文の基本情報をpythonを
使ってスクレイピングしてみました。
環境について
今回はAnaconda仮想環境内の以下のモジュールを使用しました。
・BeautifulSoup: 取得したHTMLを操作する
・pandas: 取得したデータをCSVに変換する
・requests: Webからデータをダウンロードする
・re: 正規表現の操作をする
取得する基本情報
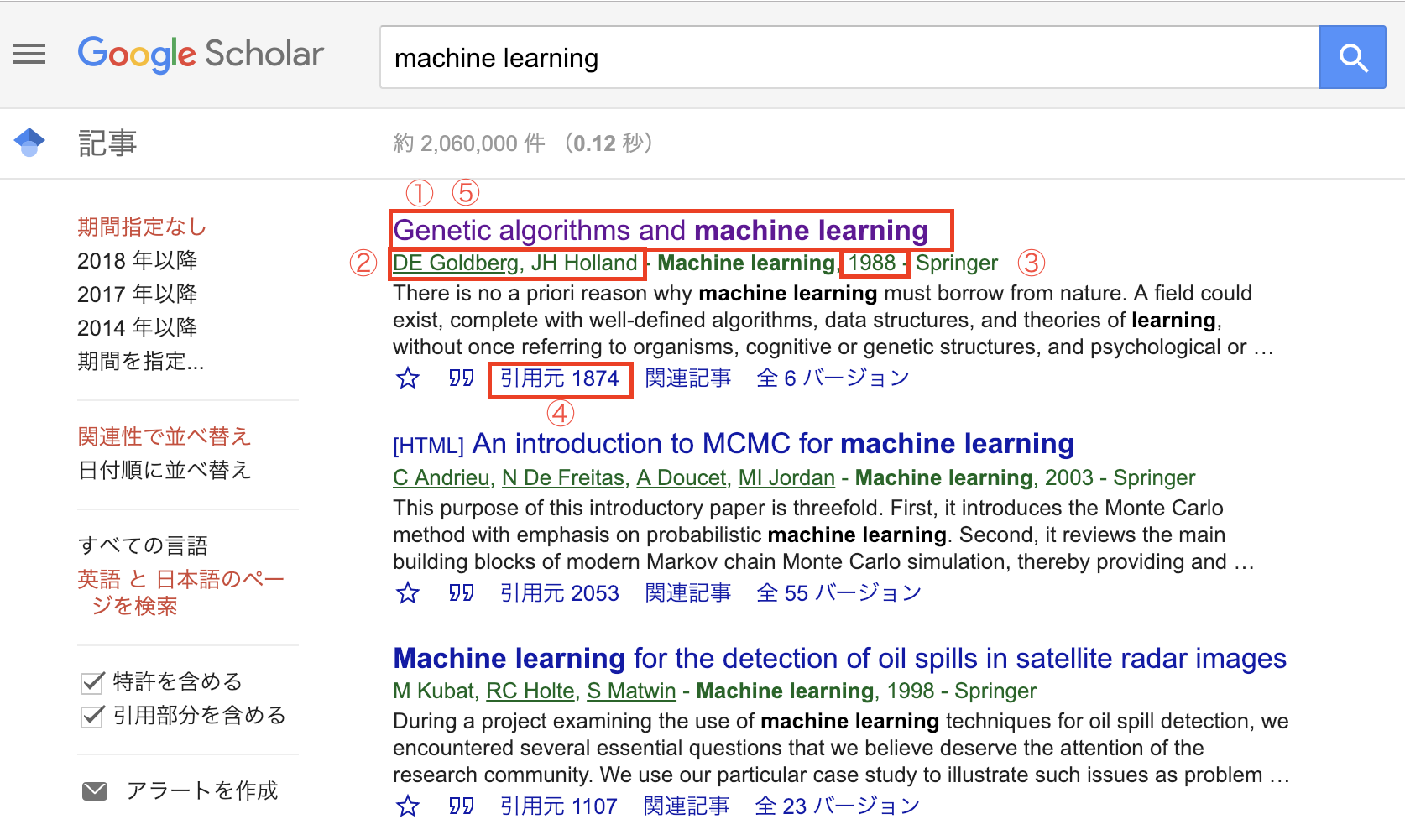
①タイトル ②著者 ③公開年 ④被引用数 ⑤URLの5つです。
モジュールのimport
from bs4 import BeautifulSoup
import requests
import pandas as pd
import re
まず上記のモジュールをimportします。
関数の定義
def get_search_results_df(keyword,number):
columns = ["rank", "title", "writer", "year", "citations", "url"]
df = pd.DataFrame(columns=columns) #表の作成
html_doc = requests.get("https://scholar.google.co.jp/scholar?hl=ja&as_sdt=0%2C5&num=" + str(number) + "&q=" + keyword).text
soup = BeautifulSoup(html_doc, "html.parser") # BeautifulSoupの初期化
tags1 = soup.find_all("h3", {"class": "gs_rt"}) # title&url
tags2 = soup.find_all("div", {"class": "gs_a"}) # writer&year
tags3 = soup.find_all(text=re.compile("引用元")) # citation
rank = 1
for tag1, tag2, tag3 in zip(tags1, tags2, tags3):
title = tag1.text.replace("[HTML]","")
url = tag1.select("a")[0].get("href")
writer = tag2.text
writer = re.sub(r'\d', '', writer)
year = tag2.text
year = re.sub(r'\D', '', year)
citations = tag3.replace("引用元","")
se = pd.Series([rank, title, writer, year, citations, url], columns)
df = df.append(se, columns)
rank += 1
return df
目的の関数を上記のように作成しました。
それでは関数内を部分的に見ていきます。
キーワードの検索結果をHTML形式で取得
html_doc = requests.get("https://scholar.google.co.jp/scholar?hl=ja&as_sdt=0%2C5&num=" + str(number) + "&q=" + keyword).text
上記URLはGoogleScholarで検索を行った時のURLを示しています。
関数の引数であるnumberに取得する論文の数、keywordに検索する単語が入ります。
HTMLから必要なタグのみ取得
tags1 = soup.find_all("h3", {"class": "gs_rt"}) # title&url
tags2 = soup.find_all("div", {"class": "gs_a"}) # writer&year
tags3 = soup.find_all(text=re.compile("引用元")) # citation
検証ツールでGoogleScholarのページのHTMLを確認したところ、
・論文のタイトルとURL→h3タグのclass名が"gs_rt"
・著者名と公開年→divタグのclass名が"gs_a"
・被引用数→"引用元"というテキストを含むタグ
にそれぞれ記載があったので上記のように取得しました。
基本情報の取得
for tag1, tag2, tag3 in zip(tags1, tags2, tags3):
title = tag1.text.replace("[HTML]","")
url = tag1.select("a")[0].get("href")
writer = tag2.text
writer = re.sub(r'\d', '', writer)
year = tag2.text
year = re.sub(r'\D', '', year)
citations = tag3.replace("引用元","")
se = pd.Series([rank, title, writer, year, citations, url], columns)
df = df.append(se, columns)
rank += 1
for文で1つずつ基本情報の項目を取得していきます。
replace()で取得した文字列に含まれている不要な文字列を削除しています。
またwriterとyearの情報を含んでいるtags2には、1つの文字列内に著者名と公開年が記入されていました。そこでre.sub()を用いて文字列から文字のみ、数値のみを取得しています。
以上で関数の説明は終了です。
プログラムの実行
keyword = "machine learning"
number = 10
search_results_df = get_search_results_df(keyword,number)
filename = "Google_Scholar.csv"
search_results_df.to_csv(filename, encoding="utf-8")
keywordには検索する単語、numberには取得する論文数を記入します。
今回は例で"machine learning"と記入しています。
csvファイル取得結果
 上記のようにcsvファイルで取得できました。
上記のようにcsvファイルで取得できました。
おわりに
今回は初めてのスクレイピング&Qiita投稿でした。
アウトプットすることで調べる、考える、整理することを意識できたし、
何より成果が出ると純粋に嬉しいということに気づくことができました。
これからも続けていきます。
参考にしたサイト
・python ドキュメント 6.2. re — 正規表現操作
・Pythonによるスクレイピング①入門編 ブログの記事をCSVにエクスポートする(Note)