概要
本ブログは、アイドルマスター4シリーズ(本家はミリオンに含むものとする。理由は後述)において、ある特定1つのシリーズの担当をほかのシリーズの担当から推測し、プロデューサーに対してアイドルを推薦するシステムを考案・データ収集・実装した記録です。
結論から申し上げると、各シリーズの推薦システムの正答率は以下のようになりました。
- シャイニーカラーズ:80%
- SideM:49%
- ミリオンライブ:55%
- シンデレラ:37%
本ブログにて、データの構造、用いた手法、結果に対する考察を述べていきます。よろしくお願いします。
また、本ブログでは各シリーズを以下のように略記しております。
- シャイニーカラーズ:シャニ
- シンデレラガールズ:デレ
- ミリオンライブ :ミリ
正直もうちょっと精度の良いものができると思ってた
目次
背景
そもそもなんでこんなこと考えたのか
twitterで同じ担当のPや絵師の方をフォローしていますが、その人たちがリツイートする他のシリーズでの絵・漫画に傾向があると思ったのがきっかけですね。自分はデレでは高森藍子、シャニでは桑山千雪を担当しております。同じ担当のPをフォローしていると、ミリオンの歌織の絵や漫画がよく流れてきたり。
なので、各シリーズでの担当傾向は似かよるんじゃないか? という仮説が自分の中にありました。

ゆくゆくは他シリーズのPを引き込むきっかけに
僕は元々シンデレラのプロデューサーだったんですが、最近他のシリーズにも手をだすようになりました。その時に、どのキャラをとっかかりとするか知れたら嬉しいなあ、と思ったので、このようなシステムを作ってみようかと。大々的にデータ集めて分析すれば、ミリオンの担当情報だけからシャニの担当をレコメンドできるんじゃないかと。そのキャラきっかけで他シリーズに触り始められるんじゃないかと。自分の好きなものを布教したい方々にとって、布教のきっかけができるのは心強いのではないかと。
そんな風に思って、本案件に取り組み始めました。
前提
アンケート集計数 7,425件
データは google フォームのアンケートで集計しました。
告知方法はtwitterのみでしたが、計 7,425件もの回答をいただきました。
ご協力いただいた皆様、誠にありがとうございました。
現在も集計はしてるので、まだ答えていなければぜひご協力ください。
https://docs.google.com/forms/d/e/1FAIpQLSfPuQskKK6y1QGH8rgA1TzjVy6nQApgwC_JM3E5OBfNxJWKJQ/viewform?usp=sf_link
各シリーズごとに、担当アイドル全員とそのうち一人を選ぶならだれか、担当するきっかけになったのは何かを質問
質問項目は以下の通りです。
- あなたの性別を教えてください。
- あなたの年代を教えてください。
以下、各シリーズごとに、
- 本シリーズにおいて、自身が担当するアイドルはいらっしゃいますか?
- あなたが初めて本シリーズのアイドルを担当してから、どのくらい経ちましたか?
- 本シリーズのアイドルのうち、あなたの担当アイドルは誰ですか?(複数選択可能)
- 3.で選択したアイドルのうち、一人だけ担当を選ぶとしたら、誰ですか?
- 4.で選択した担当アイドルについてお聞きします。その担当アイドルを担当するにいたった、一番のきっかけはなんでしたか?
大事なのは 3,4 ですね。
「担当」という言葉の定義は人それぞれなので、「1人しか担当しません」という方もいれば「たくさん担当います」という方もいらっしゃいます。
なので、特に制約は定めず複数選択可能にし、その中でも1人選ぶならだれか、という質問形式にしました。
また、以下で3.で選択した担当アイドルと4.で選択した担当アイドルを区別するため、3.で選択された担当アイドルを「複数担当」、4.で選択された担当アイドルを「単一担当」と呼ぶことにします。
きっかけについても、同じきっかけでキャラを好きになったのならば類似性が生まれると思い追加しました。
きっかけに関する項目は以下の通りです。
- (キャラクターの)声
- (キャラクターの)容姿
- (キャラクターの)性格
- (声優さんの)ライブパフォーマンス
- (声優さんの)演技
- 好きな声優さんだった
- 持ち歌
- 二次創作
- よくわからない
- 覚えていない
- その他(自由記述)
対象は音ゲー版に出演済のアイドルのみ(シャニは原作、ストレイライトまで)
今回は、デレの韓国組、876プロのアイドル、およびシャニのノクチルは選択肢から外させていただきました。担当プロデューサーの方にはご不快な思いをさせてしまいます、申し訳ありません。理由は以下の通りです。
韓国組
『スターライトステージ』に未出演のため、サンプルに偏りが出る可能性を含む。
876プロ
3人のうち1人が担当だとわかったとして、そこから最低46人(SideM の315プロメンバー)のうちの1人を予測することは不可能に近いと考えたため。
ノクチル
アンケートを集計開始したのが2019年9月のため、対象とすることができなかった。
(初出から1年未満のストレイライトやデレ新規7人はサンプルに偏り出るんじゃないか、という話はややグレーな気がしますが...)
本家のアイドルはミリオンのメンバーとしてカウント
本家やミリオンについてあまり詳しくないのですが、本家の765メンバーとミリでのASメンバーとではおそらく異なるものだと判断しました。
本家での「如月千早」と、ミリでの「如月千早」ではおそらく性質が異なるのではないかと。
結果、本家から担当してきたPとミリオンから入って担当し始めたPとで、同じ千早の担当なのに性質が異なることが考えられました。
ならば一つにまとめてしまったほうが賢明かと判断し、上記のように扱いました。
データ
本当に傾向はあるのか調べてみた
上でレコメンドできそうとか語っていますが、本当にできるのでしょうか。
そもそも本当に他シリーズの担当に傾向がなければ難しいです。
という訳で、データを確認してみます。
まずはシリーズ単体。
人数の少ないシャニで、きっかけの分布の違いなどを見ていきます。

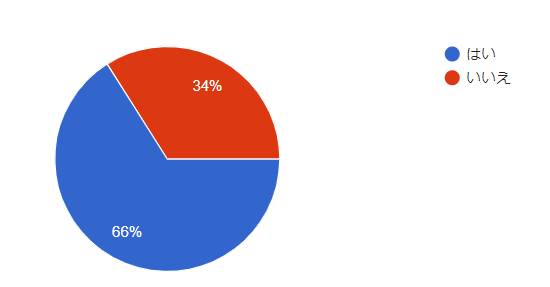
ちなみに、アンケート7,000件超のうち、シャニに担当がいると答えた方が66%, 約4,900人でした。
十分な数字が取れていると思います。
次にシリーズごとの組み合わせ。
こちらは人数の少ないシャニと、私が一番最初に触れたデレの組み合わせで、票数の分布を確認します。

シャニ単体での傾向:実際ありそう
単一担当Pの数
4.で選択されたアイドルの数が以下の通りです。
誰が何票なのかについてはセンシティブなので、特記事項が無ければ明記いたしません。
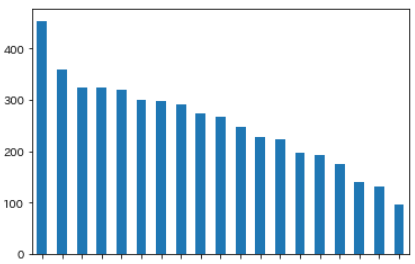
一番表を集めたのが三峰でした。その数450程度。2位と100票ほど切り離しての1位ですね。

複数担当Pの数
3.で選択されたアイドルの数が以下の通りです。
単一担当同様、上位3人についてのみ明記します。
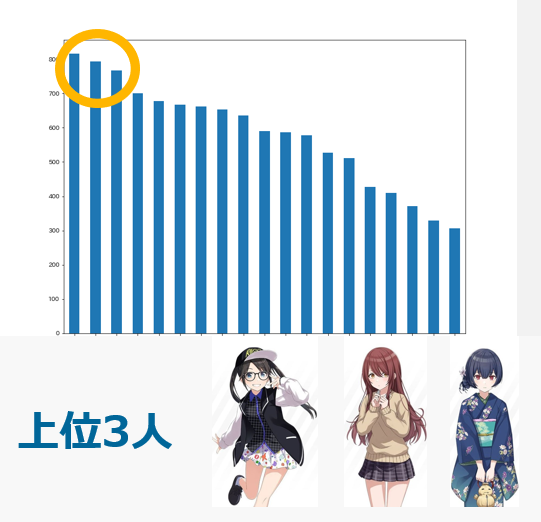
一番人気だったのが三峰、次いで甜花、凛世でした。票数にして800程度。
こちらは単一担当ほどぶっちぎってはいませんでした。
正直、票数を確認するだけでも結構面白いですね。
担当になったきっかけ
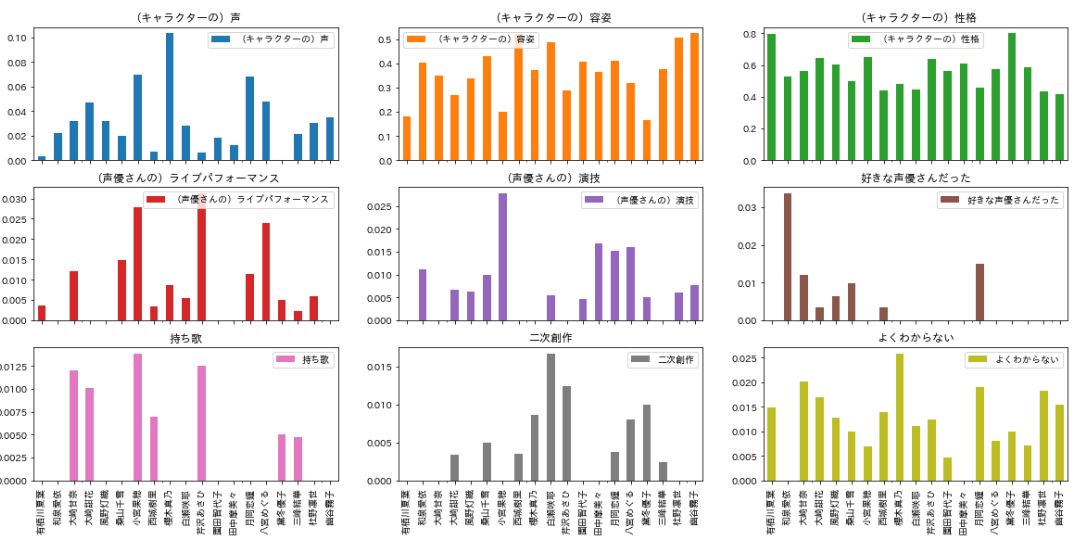
こちらは、きっかけごとの各アイドルの票数分布を表示しております。
縦軸は、各アイドルが集めた単一担当の票のうち、何%がそのきっかけで担当になったか、を表しています。
かなり分布に違いがあることが見てとれるかと思います。
中でも、以下が特徴的に感じられました。
- 真乃の「声」がきっかけで担当になるPがぶっちぎりで多い
- 「性格」で担当になったPが多いのは夏葉と冬優子
- 果穂は「演技」「ライブパフォーマンス」で惹かれた人が他に比べ多い
- 「ライブパフォーマンス」についてはあさひも同様
- 愛依に「好きな声優」で惹かれた人が他に比べぶっちぎり(北原紗弥香さん、元ハロプロメンバー)
ユニットごとの担当
どのユニットの担当ですか、という質問は集計しませんでしたが、せっかくなので疑似的に算出したいと思います。
ユニットメンバーの過半数を複数担当に選んだP(イルミネ、ストレイ、アルストロメリアは2人以上、放クラ、アンティーカは3人以上を複数担当として選んだP)をユニットへの1票として、票数を集計した結果が以下になります。
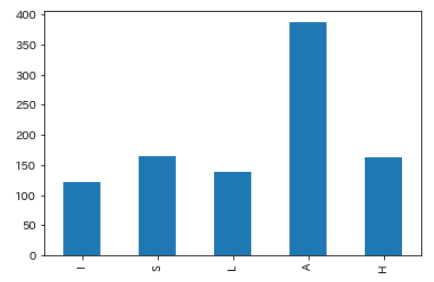
横軸のアルファベットは各ユニットの頭文字からとっています。アルストロメリア(A)がぶっちぎりで高いですね。算出方法的に双子の両方に投票すればユニットへの投票になるので、双子への投票が多いんですかね。と思って、また調べてみました。
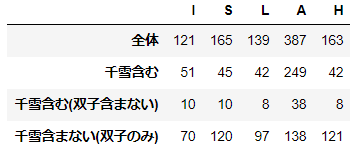
票の各要素がユニットへの票数です。「全体」行の値が上記のグラフの元になってます。
注目していただきたいのが「A」列(アルストロメリアへの票)です。「千雪含む」が桑山千雪を含めてアルストロメリアのメンバーの2人以上を複数担当にしたPの数、「千雪含む(双子含まない)」が千雪と双子の片方を複数担当として選んだ結果、アルストロメリアへの票になったPの数、「千雪含まない(双子のみ)」が、双子のみを複数担当として選んだ結果、アルストロメリアへの票になったPの数を表しています。
アルストロメリアへの387票のうち、249票が千雪を含めたアルストロメリアへの票、138票が双子両方への票なので、双子「だけ」への投票が多い結果アルストロメリアへの票が多くなった、というわけではなさそうですね。
以上から、きっかけだけでもある程度傾向が出ているんじゃないかと思われます。
シャニとデレの組み合わせ:こちらも傾向はありそう。
次に組み合わせ。デレとシャニで、単一担当の票数、きっかけの票数の分布を比較します。
とは言え、シャニの19人ならまだしも、デレは190人以上いますので、1:1の傾向なんて見ようとしていたら日が暮れてしまいます。
なので、関係性をみるアイドルを以下の3人に厳選しました。
- 速水奏
- 大槻唯
- 小日向美穂
丁度3属性そろい、かつ傾向が異なるアイドルかなと思います。
あと知り合いの担当だったので若干ひいきしました。

複数担当同士の傾向
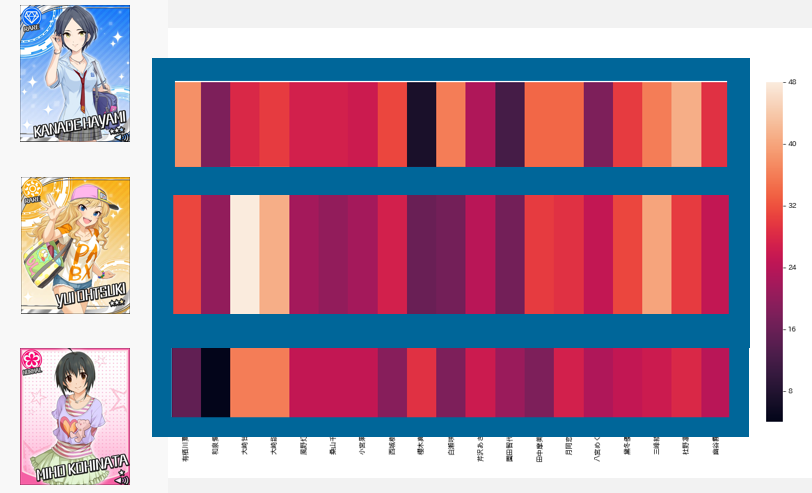
デレの3人を縦軸、シャニの19人を横軸にとり、両方を複数担当に選んだPの数が上記のヒートマップで表されています。
色が黒から白へ明るくなっているほど、票数が多いといえます。
名前が隠れてしまって見えづらいですが、以下の傾向が読み取れます。
- 奏と一緒に担当されている傾向にあるシャニアイドル :凛世、夏葉
- 唯と一緒に担当されている傾向にあるシャニアイドル :甘奈、甜花、三峰
- 美穂と一緒に担当されている傾向にあるシャニアイドル:甘奈、甜花
こっひと唯では双子が被りましたが、奏と唯で比較すると違いがあることが見て取れるかと思います。
きっかけと複数担当の関係
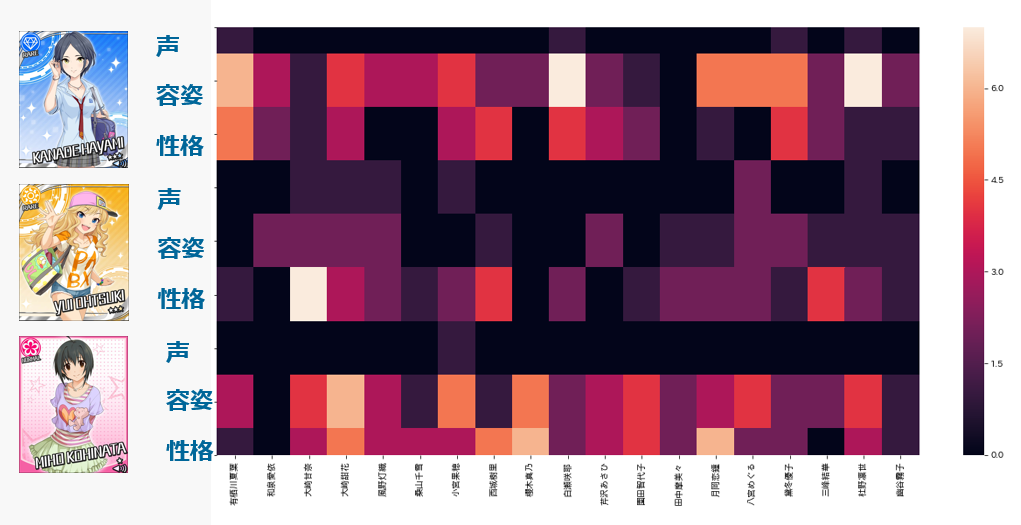
デレの3人と主要な3つのきっかけを縦軸、シャニの19人を横軸にとり、両方を複数担当に選んだPの数が上記のヒートマップで表されています。
読み取れるのは以下の通りです。
- 奏の容姿をきっかけに担当したPが担当傾向にあるシャニアイドル :咲耶、凛世
- 唯の性格をきっかけに担当したPが担当傾向にあるシャニアイドル :甘奈
- 美穂の容姿をきっかけに担当したPが担当傾向にあるシャニアイドル:甜花
- 美穂の性格をきっかけに担当したPが担当傾向にあるシャニアイドル:真乃、恋鐘
以上から、傾向が異なると言っていいのではないでしょうか。
手法
データを眺めるだけでも面白いので長くなってしまいましたが、「担当アイドルに傾向はある」ということがわかりましたので、ようやく本題に入ります。
どのようにレコメンドを実装するかについてです。
用いたのはベーシックな協調フィルタリング
今回用いたのは以下の2つの協調フィルタリング(以下 CFと略します)です。
- ユーザーベースCF
- アイテムベースCF
以下、各手法の簡単な説明を入れておきます。ご存知の方は実験結果まで飛んで大丈夫です。
ユーザーベースCF
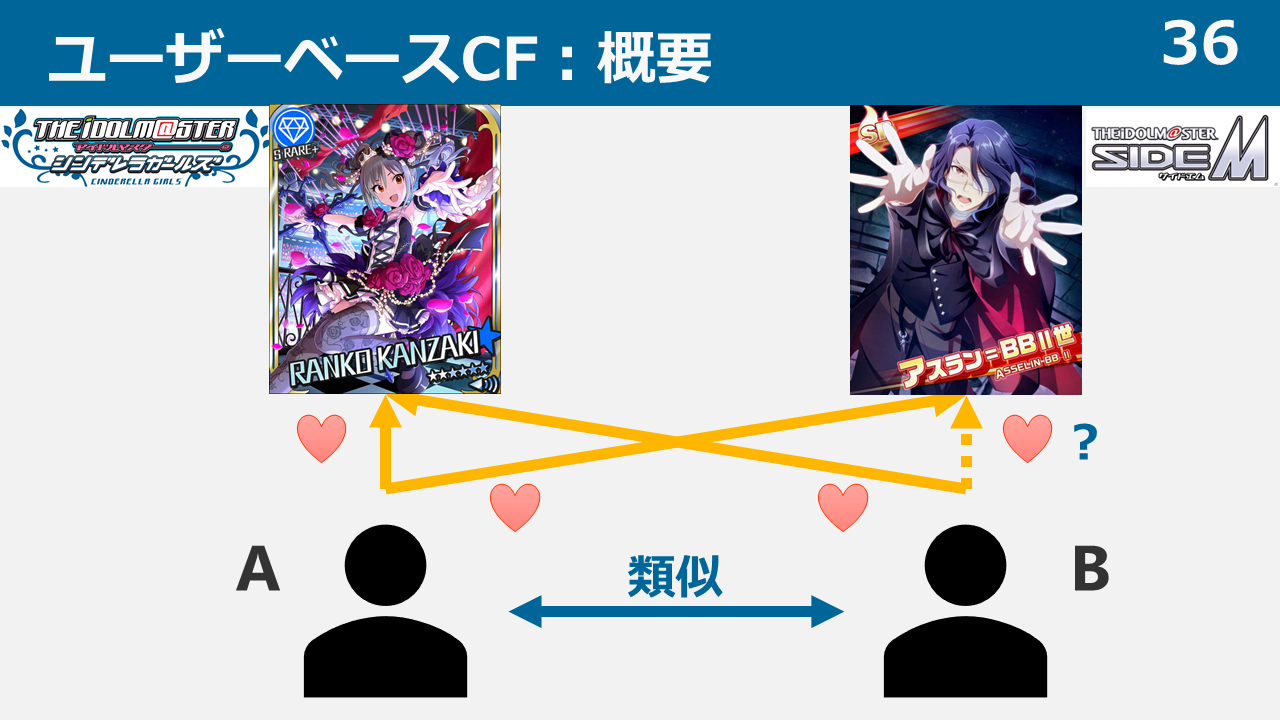
ユーザーベースCFは簡単に言うと、「同じアイドルを好きなPならば似ているだろう」という考えによるレコメンドです。
上記の例で言えば、「蘭子を担当しているA,Bは似ているから、Aが担当しているアスランをBも担当するのではないか」ということで、Bにアスランをレコメンドします。
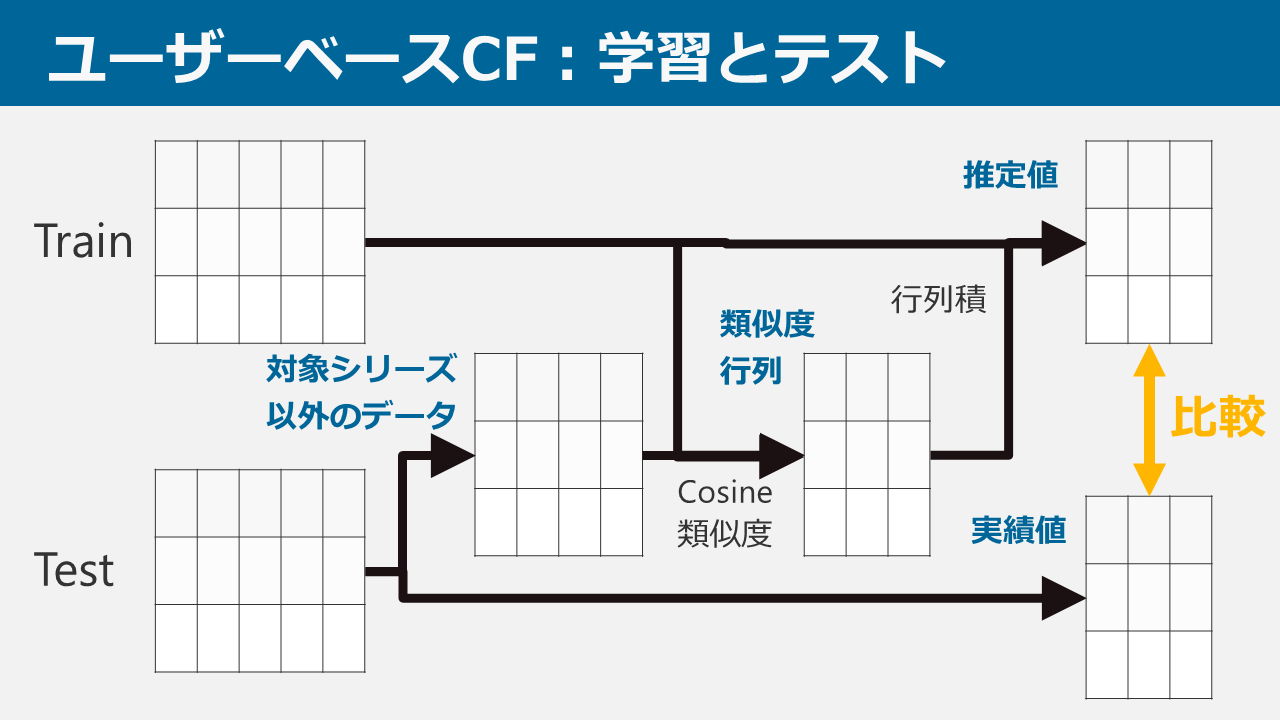
学習とテストの計算方法については上記の画像の通りです。テストを行う際は、テストの対象となるシリーズ以外のデータを取ってきて学習データとの類似度を計算し、類似度から得られたテスト対象シリーズの推定値を実際の値と比較します。
アイテムベースCF
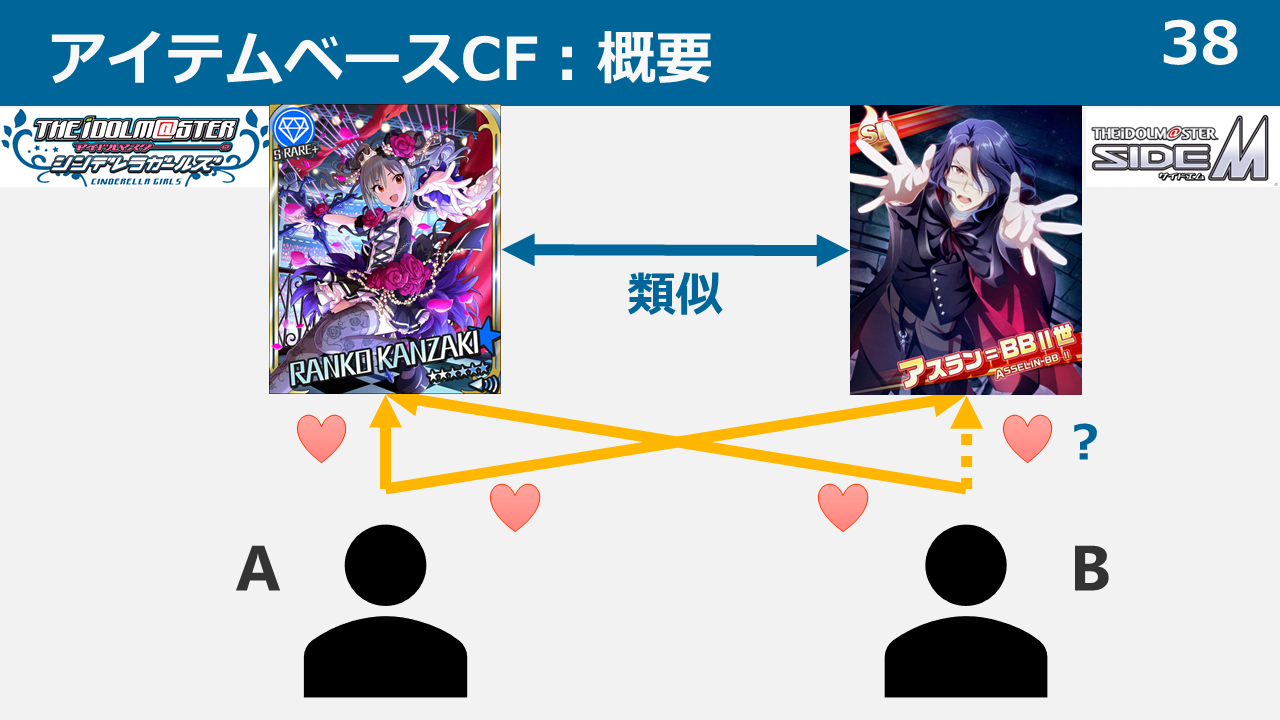
アイテムベースCFは簡単に言うと、「同じPから好かれているアイドルならば似ているだろう」という考えによるレコメンドです。
上記の例で言えば、「蘭子とアスランは同じAに担当されているので、蘭子とアスランは似ているはず。Bは蘭子を担当しているから、Bは蘭子と似ているアスランも担当するのではないか」ということで、Bにアスランをレコメンドします。
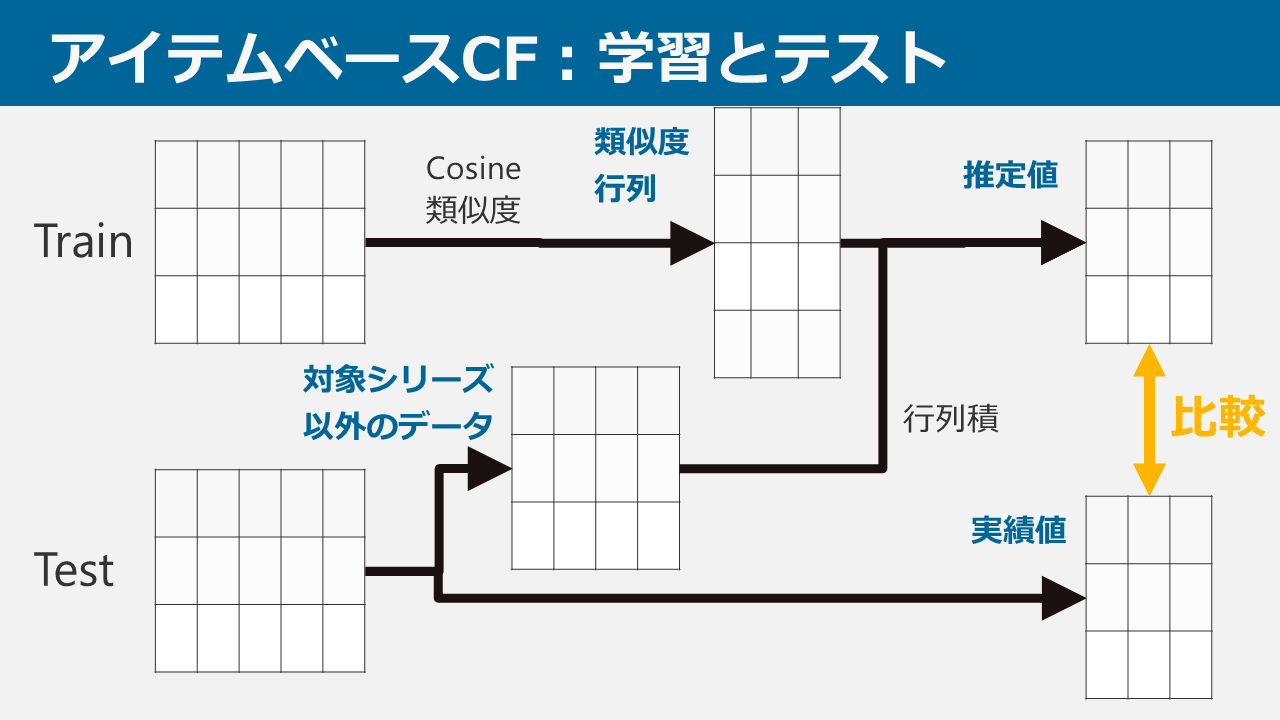
学習とテストの計算方法については上記の画像の通りです。ユーザーベースと大きく異なるのは、学習データから既に類似度が算出されているので、新しくテストを行う際に類似度を計算する必要がなく、計算時間が少なく済む点です。
実験結果
ではお待ちかね、実験結果について...の前に、評価の方法について言及いたします。
順位3位以内にレコメンドされていれば正解とする


レコメンドの結果は「お勧め度合い」といった数値で返されるので、その数値が上位3位以内に担当アイドルが存在すれば正解としました。
上記の例では、デレでの担当が未央、SideMでの担当が翼、シャニでの担当がめぐるのPに対して、「デレでは未央、SideMでは翼が担当だよ」という情報をレコメンドシステムに与えてシャニのアイドルをレコメンドしてもらった結果、上位3位までのレコメンドにめぐるが入っていれば正解、そうでなければ不正解、ということになります。
自分の担当データでやると、上位3人には入らないが、上位5人には入る
では、一番卑近な例として自分のデータでテストしてみます。
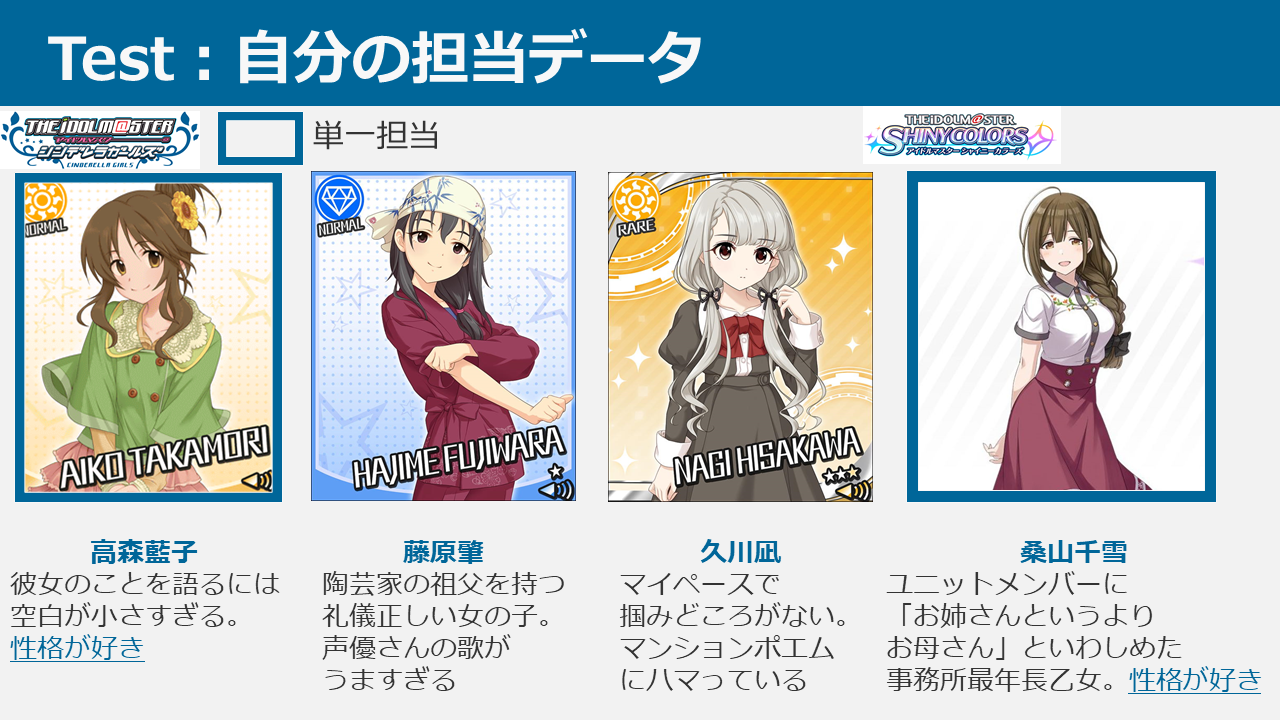
上記の画像に自分の担当データをまとめました。
ここで注意していただきたいのは、私のデータでシャニの担当をレコメンドしてもらう場合、デレの担当情報のみから予測するということです。「千雪が担当」という答えを知っていたらわざわざレコメンドしてもらう必要がないためです。同様に、デレの担当をレコメンドしてもらう場合、シャニの担当情報のみから予測します。千雪を性格きっかけで担当している、という情報だけで190人超の中から担当を予測するので難しそうであることがわかるかと思います。
以下、結果です。

当たりませんでしたね...。
興味深いのは、「シャニでの担当が千雪のみで、性格きっかけ」の場合はユーザーベースでもアイテムベースでも三船さんが一番担当すると思うよ、とレコメンドすることですね。
個人的には納得感がありました。
一応、5位までを確認した結果だと、当たっていることがわかりました。

自分の担当がいないシリーズでやると、1位にレコメンドされる
では、担当はいないけれど他のシリーズでテストしてみたらどうだろうか、ということで、ミリ、SideMでも計算してみました。

上記の通り、担当がいない他シリーズで気になっているアイドルを暫定の正解として設定しました。
先ほどとは異なり、入力としてデレとシャニの担当情報を入れることができています。
結果は以下の通りです。
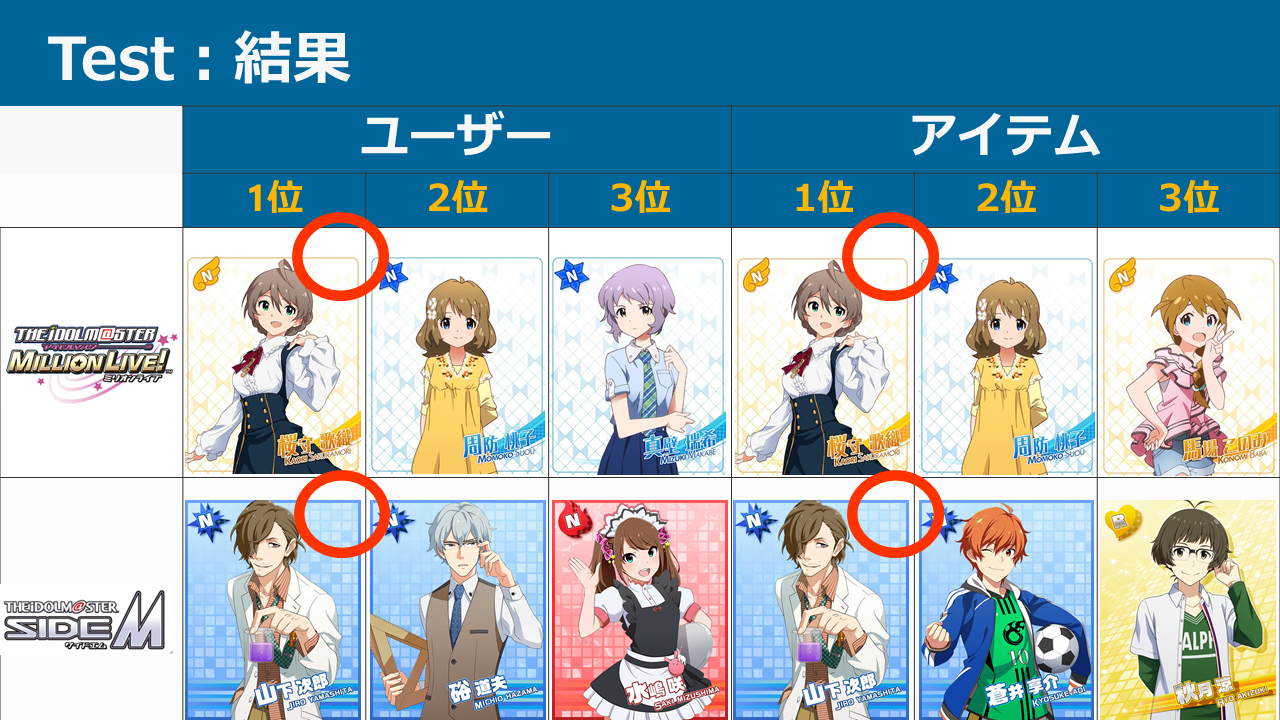
ユーザー、アイテム両方で1位に正解が来ました。
「気になる」程度なのであまり正確な結果ではありませんが、入力情報が多いと精度もあがりますね。
テストデータによる精度は概要通り
では、実際のデータを用いて精度を評価してみます。
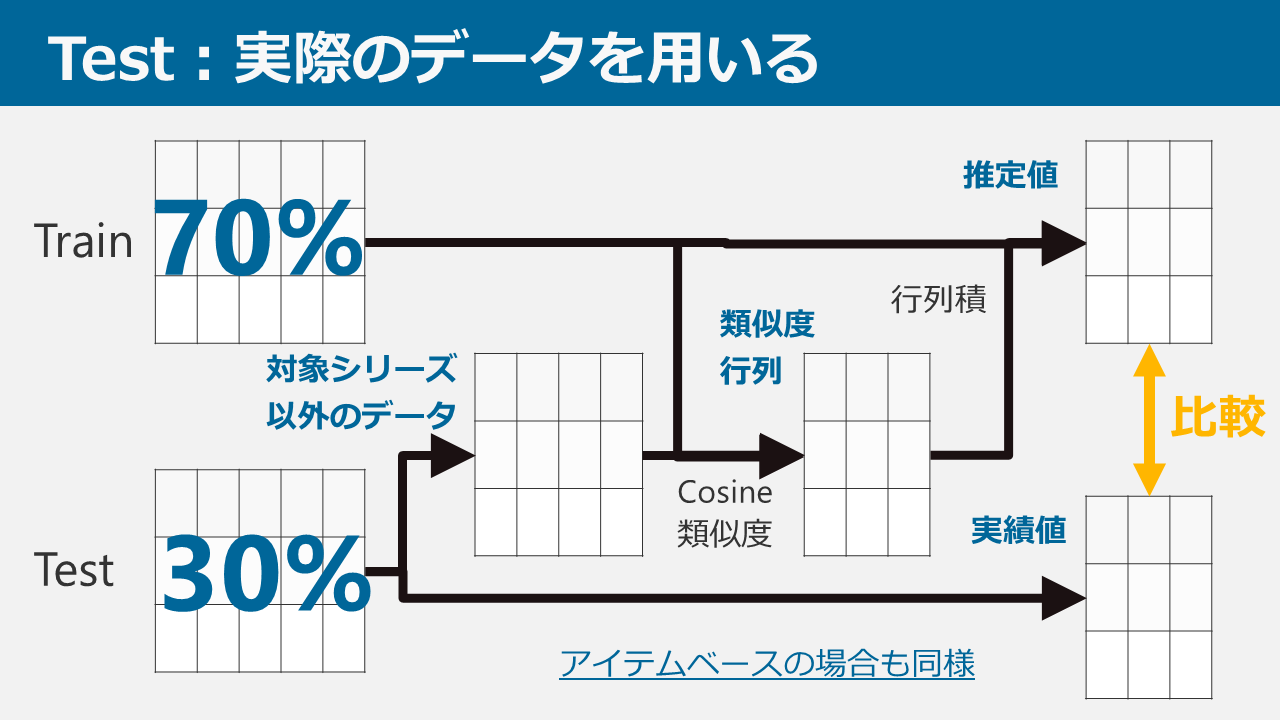
上記のようにアンケートデータを分割し、30%のテストデータで正解率を判定しました。
その結果が以下の通りです。
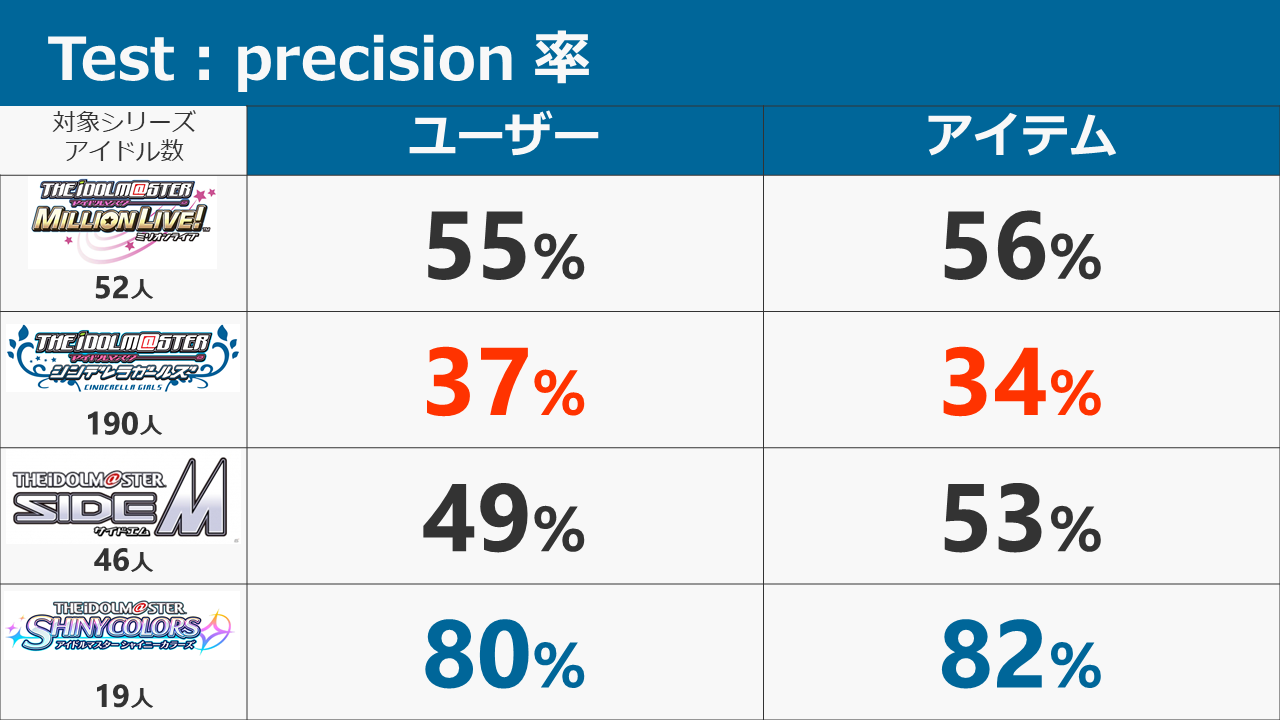
概要に載せた結果はユーザーベースのものです。
母数が大きくなるほど正解率が下がっているのは当然としても、**デレで40%満たないかぁ...**というのが第一印象でした。
考察
うまくいかなかったのは、人気に引っ張られる、手法が単純、データが足りないから?
以上の結果を踏まえて、もっと精度を上げるにはどうしたらいいか(特にデレ)を考えてみます。
原因は大きく3つあると思います。
- 人気に引っ張られてしまう
- 手法が単純
- データが足りない
以下、それぞれ解説していきます。
人気に引っ張られる
データを確認した際にも見ましたが、シャニでさえ担当数に差があるんですよね。本ブログでは説明しなかったんですが、デレでの担当数は顕著で、複数担当で一番多い投票数が496人だったのに対して、一番少ない投票数が3人でした(ちなみに一番多く複数担当に投票されたのは志希でした)。
担当数に差があると何が問題かというと、投票数の多かったアイドルをレコメンドしておけば大体当たるだろうとシステムが考えてしまうんですよね。結果、レコメンドから多様性が失われてしまいます。
デレの担当は多様性に富んでいるので、デレでのレコメンドの正解率が低いのも、その多様性を考慮できなかったことが原因の一つかと考えられます。
手法が単純
今回はベーシックな協調フィルタリングのみ実装したので、正直単純すぎると思います。
ただ、この件に関しては弁明がありまして。
lightfm という、python のレコメンドシステム用のパッケージがあります。
https://making.lyst.com/lightfm/docs/home.html
こちら、一応使ってみたのですが、今回紹介した計算結果ほどの精度を出せませんでした。
おそらく lightfm が扱うデータの意味合いが問題で、「担当でない」0を考慮すると、0に意味があると判断して、「同じレートつけてるから似てるやろ!」となってしまうようです。結果、大体みな同じ類似度になり、レコメンドも皆同じアイドルになってしまいます。
かといって0のデータを入れなければ、正しい類似度を測れなくなります。(0のデータを入れないと担当でないアイドルは「未観測のデータ」と扱われてしまうため、1人だけ担当のPと複数人担当がいてそのうちの1人がかぶったPが類似度1になる)
担当でない情報も加味しつつ、担当である情報をもとに推薦したかったので、それが可能だったのが協調フィルタリングでした。
ただ、それでも単純すぎるとは思います。
データが足りない
知り合いのPに計算結果を伝えたところ、「楽曲の好みも学習に含めたらいいんじゃない?」とアドバイスをいただきました。
確かにデータをいくらでも取れればそれも可能なのですが、「アンケート」という体裁でデータを集めるには、なるべく「答えやすく数分で終わる」ようにしなければならない、と思っていました。正確なデータが取れても、答えるのが面倒くさくなればデータ数が集まらなくなります。精度評価の観点で見ればデータ数が減ることは避けたかったので、今回は担当についてだけアンケートを取りました。
ただ、知り合いが言っていることももっともで、さらにデータがあれば精度を上げられると思います。公式でもなんでもない一介のPが収集できる情報としては、以下が挙げられるでしょうか。
- アイドルの画像
- アイドルのテキスト
これは...データ集めがとんでもなく面倒くさい大変だ...。
アイマスのテキストを集めるのに適したサイトやwebクローラーはないものでしょうか。
まとめ
アンケートにご協力いただいた皆様、本当にありがとうございました
レコメンドシステムに関する研究結果は以上となります。
冗長な文章にお付き合いいただきありがとうございました。
そして、アンケートにご協力くださった全Pの皆さまに、改めて格別の感謝を。本当にありがとうございました。
せっかく集計したデータですので、より精度を上げられたらまた報告させてください。
ご意見・ご感想あれば、本記事か以下のtwitterアカウントまでお願いします。